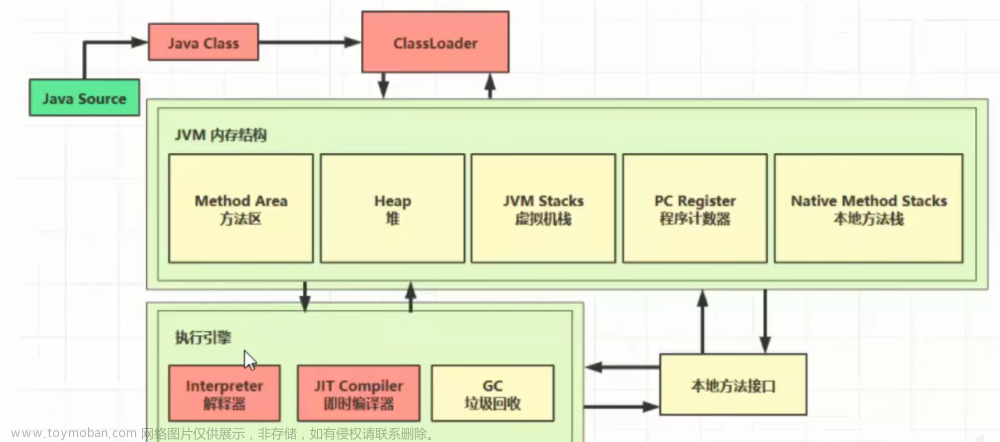
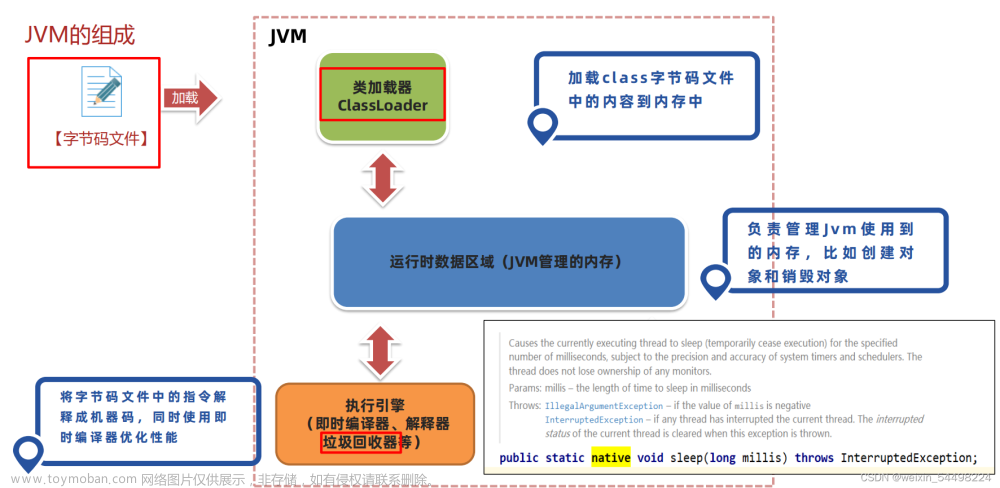
一.类的生命周期
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段::加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。其中,验证、准备和解析这三个阶段可以统称为连接(Linking)。这 7 个阶段的顺序如下图所示。类的生命周期的前五个阶段属于类加载过程。也就是说,类的生命周期包含了类加载过程。

二.类加载过程
Class 文件需要加载到虚拟机中之后才能运行和使用,也就是将类的字节码载入方法区中,那么虚拟机是如何加载这些 Class 文件呢?系统加载 Class 类型的文件主要三步:加载->连接->初始化。连接过程又可分为三步:验证->准备->解析。

在Java中,类加载过程可以在以下情况下被触发:
-
创建类的对象:当我们创建一个类的实例时,首先需要加载该类的定义。如果该类尚未被加载,JVM将触发类加载过程。
-
调用静态成员:当我们访问或调用一个类的静态成员时,会触发类加载。因为这些静态成员的存在依赖于类的定义,所以在使用它们之前,JVM需要确保类已经被加载。
-
调用反射API:使用 Java 的反射机制,我们可以在运行时动态地加载和使用类。当我们使用反射 API 加载一个类时,会触发类加载过程。
-
子类在进行类加载过程之前,父类会先被触发:如果子类尚未被加载,那么在创建子类的实例或访问子类的静态成员时,会先触发父类的加载。
类加载是按需进行的。即当需要使用某个类时,JVM 才会触发该类的加载过程。同时,JVM 还具有类加载的缓存机制,已加载的类会被缓存,避免重复加载。
加载该类对应的字节码时,静态属性和静态方法会一起被加载,普通成员方法的字节码指令只有在被用到的时候才会被加载。
2.1 加载
类加载阶段主要完成下面 3 件事情:
-
通过全类名获取类的二进制字节流。
-
将字节流所代表的静态存储结构转换为方法区的运行时数据结构。
-
在堆内存中生成一个代表该类的 Class 对象,作为方法区里这些数据的访问入口。
需要注意的是:
-
虚拟机规范的上面这 3 点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取,怎样获取,获取的地方可以是 JAR、WAR、ZIP、EAR、网络、动态代理技术运行时动态生成。
-
加载这一步主要是通过后面要讲到的 类加载器 完成的。
-
一个非数组类的加载阶段,也就是加载阶段获取类的二进制字节流的动作是可控性最强的阶段,这一步我们可以去完成还可以自定义类加载器去控制字节流的获取方式,也就是重写一个类加载器的 loadClass 方法。
-
加载阶段与连接阶段的部分动作是交叉进行的,比如一部分字节码文件格式验证动作,加载阶段尚未结束,连接阶段可能就已经开始了。
Class 对象也是由对象头和实例数据组成的。对象头用于存储一些元数据信息,比如对象的哈希码、GC标记等,实例数据存储的是:
类的名称、修饰符、父类、接口等基本信息。
类的构造器信息,包括构造器的参数类型、访问修饰符等。
类的方法信息,包括方法的名称、参数类型、返回值类型、访问修饰符等。
类的字段信息,包括字段的名称、类型、访问修饰符等。
这些引用指向方法区中的类元数据,即类的描述信息。当我们通过类对象进行反射操作时,实际上是通过这些引用来获取方法区中类的元数据,进而访问和操作类的属性和方法。因此,类对象是一种访问方法区中类元数据的桥梁,它提供了一种动态访问和操作类信息的机制。
2.2 连接
2.2.1 验证
验证阶段是用来确保字节码文件中包含的信息是否符合《Java 虚拟机规范》的约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。验证阶段主要由下图所示的四种验证组成,除了文件格式验证之外,其余三个验证阶段都是基于方法区的存储结构上进行的,不会再直接读取、操作字节流了。

可以用 UE 等支持二进制的编辑器修改 HelloWorld.class 的魔数检查其修改后是否能够通过安全性检查,在控制台运行。修改完 HelloWorld.class 的魔数后,报错信息如上图所示,说明验证没有通过
E:\git\jvm\out\production\jvm>java cn.itcast.jvm.t5.HelloWorld
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.ClassFormatError: Incompatible magic value
3405691578 in class file cn/itcast/jvm/t5/HelloWorld
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:763)
at
java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:467)
at java.net.URLClassLoader.access$100(URLClassLoader.java:73)
at java.net.URLClassLoader$1.run(URLClassLoader.java:368)
at java.net.URLClassLoader$1.run(URLClassLoader.java:362)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:361)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:495)2.2.2 准备
准备阶段是用来为类变量分配内存并设置初始值。对于该阶段有以下几点需要注意:
-
从概念上讲,类变量所使用的内存都应当在方法区中进行分配。需要注意的是:JDK 7 之前,HotSpot 使用永久代来实现方法区的时候,是完全符合这种概念的;而在 JDK 7 及之后,HotSpot 已经把原本放在永久代的字符串常量池、静态变量等移动到堆中,这个时候类变量随着 Class 对象被一起存放在了 Java 堆中。
-
这里所设置的初始值"通常情况"下是数据类型默认的零值,比如我们定义了public static int value=111 ,那么 value 变量在准备阶段的初始值就是 0 而不是 111,初始化阶段才会将value赋值为111。但是,如果给 value 变量加上了 final 关键字 public static final int value=111 ,那么准备阶段 value 的值就被赋值为 111。
基本数据类型的零值:

2.2.3 解析
解析阶段是用来将常量池内的一部分符号引用替换为直接引用,存储在常量池中。 解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符 7 类符号引用进行。
在解析阶段,虚拟机会将一部分符号引用解析为直接引用,并将这些直接引用存储在常量池中。这样做的目的是为了提高程序的执行效率和运行时的性能。所以并非所有的符号引用都会在解析阶段被解析为直接引用。有些符号引用等到运行时,需要使用到具体的直接引用时才会进行解析。这种延迟解析的机制可以提供更好的性能和灵活性。
package cn.itcast.jvm.t3.load;
/**
* 解析的含义
*/
public class Load2 {
public static void main(String[] args) throws ClassNotFoundException,
IOException {
ClassLoader classloader = Load2.class.getClassLoader();
// loadClass 方法不会导致类的解析和初始化
Class<?> c = classloader.loadClass("cn.itcast.jvm.t3.load.C");
new C();
System.in.read();
}
}
class C {
D d = new D();
}
class D {
}2.3 初始化
初始化阶段是用来执行类变量的赋值和静态代码块,是类加载过程的最后一步。在Java中,类的初始化由虚拟机在下面这 6 种情况下自动触发,确保类的静态成员在首次使用前被正确地初始化。
1.当遇到 new、 getstatic、putstatic 或 invokestatic 这 4 条字节码指令时,比如 new 一个类,读取一个静态属性或调用一个类的静态方法时。
-
当 jvm 执行 new 指令时会初始化类。即当程序创建一个类的实例对象。
-
当 jvm 执行 getstatic 指令时会初始化类。即程序访问类的静态变量。注意不是静态常量,常量会被加载到运行时常量池。
-
当 jvm 执行 putstatic 指令时会初始化类。即程序给类的静态变量赋值。
-
当 jvm 执行 invokestatic 指令时会初始化类。即程序调用类的静态方法。
2.使用 java.lang.reflect 包的方法对类进行反射调用时如 Class.forname("...")、newInstance() 等。如果类没初始化,需要触发其初始化。
3.初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
4.当虚拟机启动时,main 方法所在的类,总会被首先初始化
5.MethodHandle 和 VarHandle 可以看作是轻量级的反射调用机制,而要想使用这 2 个调用, 就必须先使用 findStaticVarHandle 来初始化要调用的类。
6.当一个接口中定义了 JDK8 新加入的默认方法时,也就是被 default 关键字修饰的接口方法,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
初始化阶段是执行初始化方法 <clinit> () 方法的过程,类初始化方法 <clinit>() 是由编译器自动收集类中所有的静态变量赋值语句和静态代码块中的语句合并产生的,在类加载阶段此方法会被加载到方法区。
三.类卸载
类卸载是指从方法区中移除一个已经加载的类。卸载类需要满足 3 个条件:
-
这个类的所有实例对象都已被垃圾回收,也就是说堆不存在该类的实例对象。
-
没有任何地方引用该类对应的 Class 对象。
-
这个类的类加载器已被垃圾回收。
所以,在 JVM 生命周期内,由 jvm 自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
四.类加载器
4.1 类加载器概述
什么是类加载器
类加载器是用来将字节码加载到 JVM 中的对象。类加载过程中的加载这一步就是靠类加载器来实现的。
类加载器加载规则:根据需要去动态加载。
Note:
当一个类被加载时,类加载器会将该类的字节码文件读取到内存中,然后创建一个表示该类的Class对象,并将这个Class对象与加载它的类加载器关联起来。所以说,已经加载的类会被放在对应的类加载器中,类加载器负责管理和维护这些已加载的类及其相关信息。
给定类的二进制名称,类加载器会尝试定位或生成构成类定义的数据。典型的策略是将名称转换为文件名,然后从文件系统中读取该名称的“类文件”。
4.2 类加载器的种类
以 JDK 8 为例,类加载器的种类如下所示:
-
BootstrapClassLoader(启动类加载器):由 C++ 实现的顶层类加载器,主要用来加载 Java 核心类库中的类,以及被 -Xbootclasspath 参数所指定的路径下的所有类。
-
ExtensionClassLoader(扩展类加载器):主要负责加载 Java 扩展类库中的类,以及被 java.ext.dirs 系统变量指定的路径下的所有类。
-
AppClassLoader(应用程序类加载器):负责加载 ClassPath 下的类。

扩展类加载器由启动类加载器加载,应用程序类加载器由扩展类加载器加载。
除了 BootstrapClassLoader 外,其它类加载器均由 Java 实现且全部继承自 java.lang.ClassLoader。
核心类库是 %JAVA_HOME%/jre/lib 目录下 jar 包和类。
扩展类库是 %JAVA_HOME%/jre/lib/ext 目录下的 jar 包和类
4.3 自定义类加载器
自定义类加载器是我们自己定义的类加载器,必须继承 ClassLoader 类,用来加载一些非标准的类库或者一些特殊的类。ClassLoader 类有两个关键的方法:
-
protected Class loadClass(String name, boolean resolve):加载指定二进制名称的类,实现了双亲委派机制。name 为类的二进制名称,resolve 如果为 true,在加载时会调用 resolveClass(Class<?> c) 方法解析该类。resolveClass(Class<?> c) 方法对应类加载过程中的解析阶段,但在解析阶段之前,仍然会依次执行验证和准备阶段。
-
protected Class findClass(String name):自定义类加载器通过实现 findClass 方法来查找并加载类文件。在该方法中,你可以根据需要访问本地文件系统、网络或数据库等来源,以查找并加载类文件。
为什么不用AppClassLoader加载非标准的类库或者一些特殊的类?
默认的应用程序类加载器只能加载位于类路径下的类,如果类不在类路径下,则无法找到该类。
如果需要保护某些类的安全性,防止被恶意代码替换或篡改,可以通过自定义类加载器实现类的隔离和保护。
4.4 双亲委派机制
4.4.1 什么是双亲委派机制
双亲委派机制是指当类加载器接收到类加载请求之后,它会先将请求转发给父类加载器。如果父类加载器在自己的搜索范围内能够找到这个类,就由自己来加载这个类;如果父类加载器没有找到这个类,则由子类加载器尝试去加载。
4.4.2 双亲委派机制的好处
双亲委派机制可以避免类的重复加载,并保证了 Java 的核心 API 不被篡改。
如果没有使用双亲委派机制,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现两个不同的 Object 类。双亲委派模型可以保证加载的是 JRE 里的那个 Object 类,而不是你写的 Object 类。这是因为 AppClassLoader 在加载你的 Object 类时,会委托给 ExtClassLoader 去加载,而 ExtClassLoader 又会委托给 BootstrapClassLoader,BootstrapClassLoader 发现自己已经加载过了 Object 类,会直接返回,不会去加载你写的 Object 类。
我们在项目中如果创建了一个类,这个类的包名和类名跟核心类库中的某个类重复了,那么这个类不会被执行类加载,并且在启动项目的时候会报错。
JVM 如何判断是否是同一个类的呢:JVM 区分不同类的方式不仅仅根据全类名,相同的类文件被不同的类加载器加载产生的是两个不同的类

4.4.3 双亲委派机制的执行流程
双亲委派机制的实现代码非常简单,逻辑非常清晰,都集中在 java.lang.ClassLoader 的 loadClass() 中,相关代码如下所示。根据下面的源码,双亲委派模型的执行流程如下所示:
-
在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接结束加载,否则才会尝试加载,每个父类加载器都会走一遍这个流程。
-
类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是通过调用父加载器的 loadClass() 方法把这个请求委派给父类加载器去完成。这样的话,所有的请求最终都会传送到顶层的启动类加载器 BootstrapClassLoader 中。
-
当父加载器在它的搜索范围中没有找到所需的类时,子加载器才会尝试调用自己的 findClass() 方法去加载。
-
如果子类加载器也无法加载这个类,那么它会抛出一个 ClassNotFoundException 异常。
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
//首先,检查该类是否已经加载过
Class c = findLoadedClass(name);
if (c == null) {
//如果 c 为 null,则说明该类没有被加载过
long t0 = System.nanoTime();
try {
if (parent != null) {
//当父类的加载器不为空,则通过父类的loadClass来加载该类
c = parent.loadClass(name, false);
} else {
//当父类的加载器为空,则调用启动类加载器来加载该类
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
//非空父类的类加载器无法找到相应的类,则抛出异常
}
if (c == null) {
//当父类加载器无法加载时,则调用findClass方法来加载该类
//用户可通过覆写该方法,来自定义类加载器
long t1 = System.nanoTime();
c = findClass(name);
//用于统计类加载器相关的信息
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
//对类进行link操作
resolveClass(c);
}
return c;
}
}
4.4.4 打破双亲委派机制的方法
打破双亲委派机制需要使用自定义加载器打破。
-
如果想打破双亲委派机制,只需重写 loadClass() 方法。重写 loadClass() 方法之后,我们就可以改变双亲委派机制的执行流程。例如,子类加载器在委派父类加载器加载之前,先自己尝试加载这个类。具体的规则由我们自己实现,根据项目需求定制化。
-
如果我们不想打破双亲委派机制,就重写 ClassLoader 类中的 findClass() 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。
五.运行期优化
5.1 即时编译
5.1.1 分层编译
先看一个例子,外层循环打印的是第几次循环,内层循环打印的是创建1000次Object对象花费了多长时间。通过运行这段代码可知,前期创建创建1000次Object对象一般花费几万毫秒,后期创建1000次Object对象一般花费几百毫秒。
public class JIT1 {
public static void main(String[] args) {
//外层循环打印的是第几次循环
for (int i = 0; i < 200; i++) {
//创建1000次Object对象花费了多长时间
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
new Object();
}
long end = System.nanoTime();
System.out.printf("%d\t%d\n",i,(end - start));
}
}
}
0 96426
1 52907
2 44800
3 119040
4 65280
5 47360
6 45226
7 47786
8 48640
9 60586
10 42667
11 48640
12 70400
13 49920
14 49493
15 45227
16 45653
17 60160
18 58880
19 46080
20 47787
21 49920
22 54187
23 57173
24 50346
25 52906
26 50346
27 47786
28 49920
29 64000
30 49067
31 63574
32 63147
33 56746
34 49494
35 64853
36 107520
37 46933
38 51627
39 45653
40 103680
41 51626
42 60160
43 49067
44 45653
45 49493
46 51626
47 49066
48 47360
49 50774
50 70827
51 64000
52 72107
53 49066
54 46080
55 44800
56 46507
57 73813
58 61013
59 57600
60 83200
61 7024204
62 49493
63 20907
64 20907
65 20053
66 20906
67 20907
68 21333
69 22187
70 20480
71 21760
72 19200
73 15360
74 18347
75 19627
76 17067
77 34134
78 19200
79 18347
80 17493
81 15360
82 18774
83 17067
84 21760
85 23467
86 17920
87 17920
88 18774
89 18773
90 19200
91 20053
92 18347
93 22187
94 17920
95 18774
96 19626
97 33280
98 20480
99 20480
100 18773
101 47786
102 17493
103 22614
104 64427
105 18347
106 19200
107 26027
108 21333
109 20480
110 24747
111 32426
112 21333
113 17920
114 17920
115 19200
116 18346
117 15360
118 24320
119 19200
120 20053
121 17920
122 18773
123 20053
124 18347
125 18347
126 22613
127 18773
128 19627
129 20053
130 20480
131 19627
132 20053
133 15360
134 136533
135 43093
136 853
137 853
138 853
139 853
140 854
141 853
142 853
143 853
144 853
145 853
146 853
147 854
148 853
149 853
150 854
151 853
152 853
153 853
154 1280
155 853
156 853
157 854
158 853
159 853
160 854
161 854
162 853
163 854
164 854
165 854
166 854
167 853
168 853
169 854
170 853
171 853
172 853
173 1280
174 853
175 1280
176 853
177 854
178 854
179 427
180 853
181 854
182 854
183 854
184 853
185 853
186 854
187 853
188 853
189 854
190 1280
191 853
192 853
193 853
194 853
195 854
196 853
197 853
198 853
199 854
即时编译器(JIT)与解释器的区别
- 解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
- JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
- 解释器是将字节码解释为针对所有平台都通用的机器码
- JIT 会根据平台类型,生成平台特定的机器码
JVM 将执行状态分成了 5 个层次:
profiling:是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的 回边次数】等。
- 0 层,解释执行(Interpreter)
- 1 层,使用 C1 即时编译器编译执行(不带 profiling)
- 2 层,使用 C1 即时编译器编译执行(带基本的 profiling)
- 3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
- 4 层,使用 C2 即时编译器编译执行
相同代码前期速度慢,后期速度快原因剖析
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由来),这种优化手段称之为【逃逸分析】,发现新建的对象是否逃逸。可以使用 -XX:- DoEscapeAnalysis 关闭逃逸分析,再运行刚才的示例观察结果
5.1.2 方法内联
什么是方法内联
通过下面的例子来说明。比如有下面这么一段Java代码:
private static int square(final int i) {
return i * i;
}
System.out.println(square(9));如果发现 square 是热点方法,并且长度不太长时,会进行内联,所谓的内联就是把方法内代码拷贝、 粘贴到调用者的位置:
System.out.println(9 * 9);
还能够进行常量折叠的优化
System.out.println(81);方法内联实验
public class JIT2 {
// 打印当前项目的内联(inlining)信息。也就是哪些方法进行了内联
// -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
// 禁止某个方法内联(inlining)。*是通配符,匹配包名,JIT2是类名,square是类中的方法
// -XX:CompileCommand=dontinline,*JIT2.square
// 打印编译信息
// -XX:+PrintCompilation
public static void main(String[] args) {
int x = 0;
for (int i = 0; i < 500; i++) {
long start = System.nanoTime();
for (int j = 0; j < 1000; j++) {
x = square(9);
}
long end = System.nanoTime();
System.out.printf("%d\t%d\t%d\n",i,x,(end - start));
}
}
private static int square(final int i) {
return i * i;
}
}5.1.3 字段优化
创建 maven 工程,添加依赖如下
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>provided</scope>
</dependency>
编写基准测试代码:
package test;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 5, time = 1)
@State(Scope.Benchmark)
public class Benchmark1 {
int[] elements = randomInts(1_000);
private static int[] randomInts(int size) {
Random random = ThreadLocalRandom.current();
int[] values = new int[size];
for (int i = 0; i < size; i++) {
values[i] = random.nextInt();
}
return values;
}
@Benchmark
public void test1() {
for (int i = 0; i < elements.length; i++) {
doSum(elements[i]);
}
}
@Benchmark
public void test2() {
int[] local = this.elements;
for (int i = 0; i < local.length; i++) {
doSum(local[i]);
}
}
@Benchmark
public void test3() {
for (int element : elements) {
doSum(element);
}
}
static int sum = 0;
@CompilerControl(CompilerControl.Mode.INLINE)
static void doSum(int x) {
sum += x;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(Benchmark1.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}
首先启用 doSum 的方法内联,测试结果如下(每秒吞吐量,分数越高的更好):
Benchmark Mode Samples Score Score error Units
t.Benchmark1.test1 thrpt 5 2420286.539 390747.467 ops/s
t.Benchmark1.test2 thrpt 5 2544313.594 91304.136 ops/s
t.Benchmark1.test3 thrpt 5 2469176.697 450570.647 ops/s接下来禁用 doSum 方法内联
@CompilerControl(CompilerControl.Mode.DONT_INLINE)
static void doSum(int x) {
sum += x;
}测试结果如下:
Benchmark Mode Samples Score Score error Units
t.Benchmark1.test1 thrpt 5 296141.478 63649.220 ops/s
t.Benchmark1.test2 thrpt 5 371262.351 83890.984 ops/s
t.Benchmark1.test3 thrpt 5 368960.847 60163.391 ops/s分析:
在刚才的示例中,doSum 方法是否内联会影响 elements 成员变量读取的优化:
如果 doSum 方法内联了,以刚才的 test1 为例,test1 方法会被优化成下面的样子(伪代码):
@Benchmark
public void test1() {
// elements.length 首次读取会缓存起来 -> int[] local
for (int i = 0; i < elements.length; i++) { // 后续 999 次 求长度 <- local
sum += elements[i]; // 1000 次取下标 i 的元素 <- local
}
}可以节省 1999 次 Field 读取操作。但如果 doSum 方法没有内联,则不会进行上面的优化
5.2 反射优化
package cn.itcast.jvm.t3.reflect;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class Reflect1 {
public static void foo() {
System.out.println("foo...");
}
public static void main(String[] args) throws Exception {
Method foo = Reflect1.class.getMethod("foo");
for (int i = 0; i <= 16; i++) {
System.out.printf("%d\t", i);
foo.invoke(null);
}
System.in.read();
}
}foo.invoke 前面 0 ~ 15 次调用使用的是 MethodAccessor 的 NativeMethodAccessorImpl 实现
package sun.reflect;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import sun.reflect.misc.ReflectUtil;
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method method) {
this.method = method;
}
public Object invoke(Object target, Object[] args)
throws IllegalArgumentException, InvocationTargetException {
// inflationThreshold 膨胀阈值,默认 15
if (++this.numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(this.method.getDeclaringClass()))
{
// 使用 ASM 动态生成的新实现代替本地实现,速度较本地实现快 20 倍左右
MethodAccessorImpl generatedMethodAccessor =
(MethodAccessorImpl)
(new MethodAccessorGenerator())
.generateMethod(
this.method.getDeclaringClass(),
this.method.getName(),
this.method.getParameterTypes(),
this.method.getReturnType(),
this.method.getExceptionTypes(),
this.method.getModifiers()
);
this.parent.setDelegate(generatedMethodAccessor);
}
// 调用本地实现
return invoke0(this.method, target, args);
}
void setParent(DelegatingMethodAccessorImpl parent) {
this.parent = parent;
}
private static native Object invoke0(Method method, Object target, Object[], args);
}当调用到第 16 次(从0开始算)时,会采用运行时生成的类代替掉最初的实现,可以通过 debug 得到 类名为 sun.reflect.GeneratedMethodAccessor1
可以使用阿里的 arthas 工具:
java -jar arthas-boot.jar
[INFO] arthas-boot version: 3.1.1
[INFO] Found existing java process, please choose one and hit RETURN.
* [1]: 13065 cn.itcast.jvm.t3.reflect.Reflect1
选择 1 回车表示分析该进程
1
[INFO] arthas home: /root/.arthas/lib/3.1.1/arthas
[INFO] Try to attach process 13065
[INFO] Attach process 13065 success.
[INFO] arthas-client connect 127.0.0.1 3658
,---. ,------. ,--------.,--. ,--. ,---. ,---.
/ O \ | .--. ''--. .--'| '--' | / O \ ' .-'
| .-. || '--'.' | | | .--. || .-. |`. `-.
| | | || |\ \ | | | | | || | | |.-' |
`--' `--'`--' '--' `--' `--' `--'`--' `--'`-----'
wiki https://alibaba.github.io/arthas
tutorials https://alibaba.github.io/arthas/arthas-tutorials
version 3.1.1
pid 13065
time 2019-06-10 12:23:54再输入【jad + 类名】来进行反编译
$ jad sun.reflect.GeneratedMethodAccessor1
ClassLoader:
+-sun.reflect.DelegatingClassLoader@15db9742
+-sun.misc.Launcher$AppClassLoader@4e0e2f2a
+-sun.misc.Launcher$ExtClassLoader@2fdb006e
Location:
/*
* Decompiled with CFR 0_132.
*
* Could not load the following classes:
* cn.itcast.jvm.t3.reflect.Reflect1
*/
package sun.reflect;
import cn.itcast.jvm.t3.reflect.Reflect1;
import java.lang.reflect.InvocationTargetException;
import sun.reflect.MethodAccessorImpl;
public class GeneratedMethodAccessor1
extends MethodAccessorImpl {
/*
* Loose catch block
* Enabled aggressive block sorting
* Enabled unnecessary exception pruning
* Enabled aggressive exception aggregation
* Lifted jumps to return sites
*/
public Object invoke(Object object, Object[] arrobject) throws
InvocationTargetException {
// 比较奇葩的做法,如果有参数,那么抛非法参数异常
block4 : {
if (arrobject == null || arrobject.length == 0) break block4;
throw new IllegalArgumentException();
}
try {
// 可以看到,已经是直接调用了😱😱😱
Reflect1.foo();
// 因为没有返回值
return null;
}
catch (Throwable throwable) {
throw new InvocationTargetException(throwable);
}
catch (ClassCastException | NullPointerException runtimeException) {
throw new IllegalArgumentException(Object.super.toString());
}
}
}
Affect(row-cnt:1) cost in 1540 ms.
注意
通过查看 ReflectionFactory 源码可知
-
sun.reflect.noInflation 可以用来禁用膨胀(直接生成 GeneratedMethodAccessor1,但首 次生成比较耗时,如果仅反射调用一次,不划算)文章来源:https://www.toymoban.com/news/detail-640173.html
-
sun.reflect.inflationThreshold 可以修改膨胀阈值文章来源地址https://www.toymoban.com/news/detail-640173.html
到了这里,关于JVM之类加载与字节码(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!