目录
1. 告警系统原理概述
2. 配置prometheus规则
2.1 配置告警规则目录
2.2 告警规则
3. 查看效果
1. 告警系统原理概述
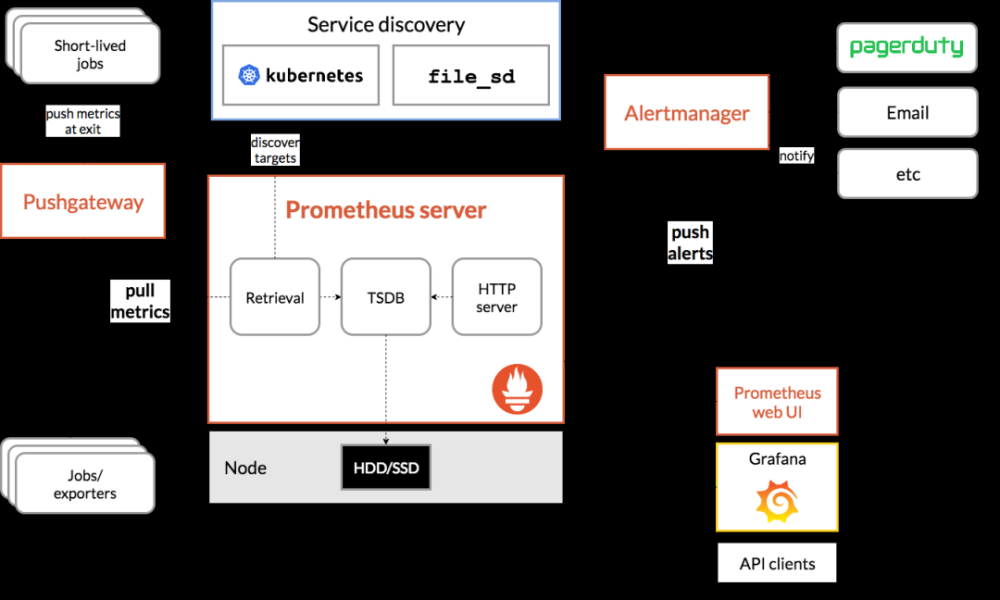
在开始之前,需要了解下prometheus和altermanger之间的关系是什么?从prometheus的架构及生态系统组件来看

Prometheus从targets中抓取指标(metric)并存储,通过对指标进行分析生成告警(alert),并将告警(alert)推送(push)到Alertmanger,Alertmanger对告警进行分组、聚合等处理后,通过邮件、Slack、webhook等方式对用户进行发送告警信息。
总结整个告警系统工作流程:
1)制定prometheus告警规则,当监控指标触发告警规则时,向altermanger发送告警;
2)altermanger接收prometheus发送的告警,管理告警信息,通过分组、静默、抑制、聚合等处理,将告警通过路由发送到对应的接收器上,按不同的规则发送给不同的模块负责人,支持邮件、salck及webhook(对接企业微信/钉钉/飞书)方式发送告警通知。
2. 配置prometheus规则
prometheus告警规则主要依赖于采集指标(metric),通过对指标进行分析设置阀值来达到告警的目的
- node监控指标可参考:node_exporter监控项说明https://lnsyyj.github.io/2019/05/27/prometheus-node-exporter-%E7%9B%91%E6%8E%A7%E9%A1%B9/
- mysql exporter指标可参考:
- GitHub - prometheus/mysqld_exporter: Exporter for MySQL server metricshttps://github.com/prometheus/mysqld_exporter
2.1 配置告警规则目录
创建rules目录,用于统一存放告警规则
# 在prometheus根目录下创建rules目录
mkdir -p /usr/local/prometheus/rules
# 配置prometheus.yml rule_files路径
# vim /usr/local/prometheus/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting: # 增加alertmanager配置
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files: # 配置告警规则目录
- rules/*.yml
重启prometheus生效规则
# 热重载
curl -X POST http://127.0.0.1:9090/-/reload
2.2 告警规则
告警规则示例以服务器资源监控指标为准,包括主机CPU/内存/硬盘/网络/TCP等告警规则,所有告警规则以*.yml的后缀存放到/usr/local/prometheus/rules目录下,目录可自定义(详看2.1配置告警规则目录)
2.2.1 主机存活
groups:
- name: 主机存活告警 # 命名
rules:
- alert: 主机存活告警 # 命名
expr: up == 0 # 表达式,分析指标判定告警
for: 60s # 触发告警持续时间
labels: # 自定义告警标签
severity: warning
annotations: # 告警内容注释,根据需要制定
summary: "{{ $labels.instance }} 宕机超过1分钟!"
2.2.2 内存利用
groups:
- name: 主机内存使用率告警
rules:
- alert: 主机内存使用率告警
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80
for: 15m
labels:
severity: warning
annotations:
summary: "内存利用率大于80%, 实例: {{ $labels.instance }},当前值:{{ $value }}%"
2.2..3 cpu利用
groups:
- name: 主机CPU使用率告警
rules:
- alert: 主机CPU使用率告警
expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[1m]) )) * 100 > 80
for: 15m
labels:
severity: warning
annotations:
summary: "CPU近15分钟使用率大于80%, 实例: {{ $labels.instance }},当前值:{{ $value }}%"
2.2..4 磁盘利用
# 磁盘利用>80%
groups:
- name: 主机磁盘使用率告警
rules:
- alert: 主机磁盘使用率告警
expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 80
for: 15m
labels:
severity: warning
annotations:
summary: "磁盘使用率大于80%, 实例: {{ $labels.instance }},当前值:{{ $value }}%"
2.2.5 tcp time_wait
groups:
- name: 主机Tcp TimeWait数量过多告警
rules:
- alert: 主机Tcp TimeWait数量过多告警
expr: node_sockstat_TCP_tw >= 5000
for: 1m
labels:
severity: warning
annotations:
summary: "Tcp TimeWait数量大于5000, 实例: {{ $labels.instance }},当前值:{{ $value }}%"
2.2.6 iowait
groups:
- name: 主机iowait较高
rules:
- alert: 主机iowait较高
expr: (sum(increase(node_cpu_seconds_total{mode='iowait'}[5m]))by(instance)) / (sum(increase(node_cpu_seconds_total[5m]))by(instance)) *100 >= 10
for: 5m
labels:
severity: warning
annotations:
summary: "CPU ioWait近5分钟占比大于等于10%, 实例: {{ $labels.instance }},当前值:{{ $value }}%"
2.2.7 磁盘读过大
groups:
- name: 主机磁盘读过大
rules:
- alert: 主机磁盘读过大
expr: sum by (instance) (rate(node_disk_read_bytes_total[2m])) > 50*1024 *1024
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘读过大, 实例: {{$labels.instance}},当前值: {{ $value | humanize1024 }}。"
2.2.8 磁盘写过大
# 写入 > 50MB/s
groups:
- name: 主机磁盘写过大
rules:
- alert: 主机磁盘写过大
expr: sum by (instance) (rate(node_disk_written_bytes_total[2m])) > 50 * 1024 * 1024
for: 5m
labels:
severity: warning
annotations:
summary: "磁盘写过大, 实例: {{$labels.instance}},当前值: {{ $value | humanize1024 }}。"
2.2.9 重启prometheus生效规则
# 热重载
curl -X POST http://127.0.0.1:9090/-/reload
3. 查看效果
查看:http://127.0.0.1:9090/alerts?search=
Prometheus Alert 告警状态有三种状态:Inactive、Pending、Firing。
- Inactive:非活动状态,表示正在监控,但是还未有任何警报触发。
- Pending:表示这个警报必须被触发。由于警报可以被分组、压抑/抑制或静默/静音,所以等待验证,一旦所有的验证都通过,则将转到 Firing 状态。
- Firing:将警报发送到 AlertManager,它将按照配置将警报的发送给所有接收者。一旦警报解除,则将状态转到 Inactive,如此循环。

至此,prometheus告警系统告警规则部分就完成了,其它告警规则根据需要自行添加,这里就不做分享了文章来源:https://www.toymoban.com/news/detail-641461.html
觉得好用就点个收藏 吧~文章来源地址https://www.toymoban.com/news/detail-641461.html
到了这里,关于玩转prometheus告警 alertmanger(一)之prometheus告警规则的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!