目录
1.Encoder
1.1简单理解Attention
1.2.什么是self-attention
1.3.怎么计算self-attention
1.4.multi-headed(q,k,v不区分大小写)
1.5.位置信息表达
2.Decoder(待补充)
3.BERT
参考文献
1.Encoder
1.1简单理解Attention
比方说,下图中的热度图中我们希望专注于小鸟,而不关注背景信息。那么如何关注文本和图像中的重点呢。
具体而言,下面的文本为she is eating a green,用不同的颜色表示每一个单词的向量,然后对每一个向量进行重构,比方说she本来由红色向量表示,重构之后,其向量包含上下文其他向量的部分(下图只管看就是按照相关程度,颜色比重各不相同,然后重新构成一个向量),其实这一块就是算出权值,每个词对其他词的贡献,再根据这个权值整合每个词自身的向量。

1.2.什么是self-attention
如下图所示,两句话中的it根据上下文语句不同,指代前面的名词也不同,所以希望用注意力机制,来专注他们之间的关系。
自注意力机制:如下图所示,两句话中,以it为例只计算本句中每个词和自己的关系
注意力机制:如下图所示,it会计算其他句和自己的关系。
同样如下图右侧所示,以it为例,线条越深和自身关系越强

1.3.怎么计算self-attention
如下图所示,有两个文本Thinking,Machines,在进行计算时,我们要知道每一个词和自己的关系以及和其他词的关系,也就是说要计算Thinking和自身的关系,以及和Machines的关系,以及Machines和自身的关系,以及和Thinking的关系然后将其向量化表示为x1和x2。接下来为了实现注意力机制,我们提供了三个向量,q,k,v,以Thinking为例,当Thinking想要寻找和自己的关系以及和Machines的关系时,必须要知道它要查什么,所以需要一个查找对象也就是q,同样Thinking和Machines自身作为被查找的单位,当被查询时,也需要提供我有或者没有被查东西的证据,也就是k,具象化理解,可以理解为,古代官府追查杀手,必然会拿着杀手画像q,那么每家每户都要提供自己的身份信息k,证明自己是不是杀手。v后面补充。

再看一下q,k,v是咋来的,对于单词向量x1和x2用一个权重矩阵w分别得到q,k,v。

再看一下词与词之间的匹配程度如何确定,先说一个概念,内积相乘越大两者关系越近,所以当计算Thinking和自己的匹配程度时,用q1*k1=112,计算Thinking和Machines匹配程度时用q1*k2=96计算,很明显和自己的匹配程度更高。

再进一步计算
首先看softmax(Q*K/)*V,其中这样理解,当高维Q*K的结果必然比低维相乘大,但在实际应用中,维数并不应该对结果产生影响,所以用消除维度影响。对照下图左侧的公式,来看下图右侧,在得到112和96之后,进行维度消除操作,得到14和12,然后得到彼此的影响概率,0.88和0.12,再利用v对x重构得到z。


流程如下图所示,Q和每一个K相乘再结合相应的V最后加权得到Attention Value

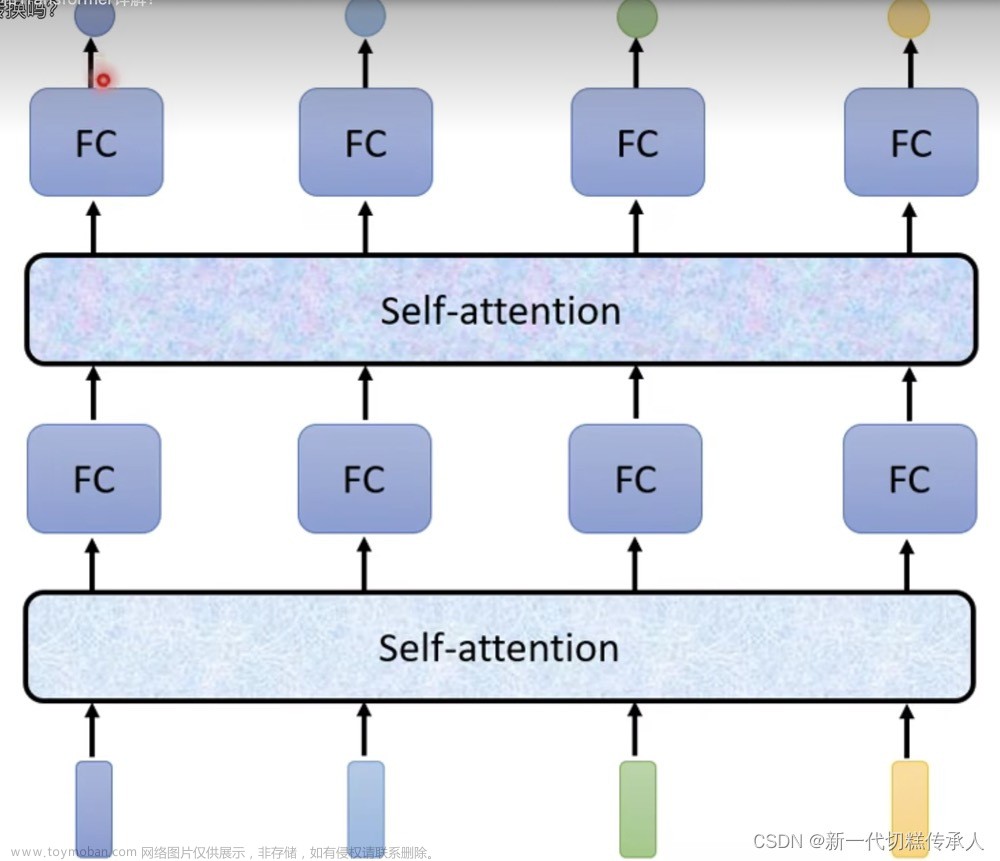
1.4.multi-headed(q,k,v不区分大小写)
上面我们发现一个x只能得到一个z,现在希望一个x可以得到不同z,所以用不同的w得到不同的q,k,v。假设一个x最后得到8个不同的z,将其拼接在一起太大了,所以用全连接层再对其降维。


举个例子

1.5.位置信息表达
前面我们发现计算时会对每一个单词进行计算,所以没考虑位置因素,但在这里希望把位置因素考虑进去,位置用p表示,最后加入到重构后的z中。

2.Decoder(待补充)
前面是用encoder处理输入得到不同的组合z,这回需要对z进行输出操作。 此时decoder提供q,查询模型需要啥。k和v由输入提供。具体我们可以看下图右侧流程图,左为Encoder输入K,V。右下为decoder输入Q。


再说一下MASK机制,简单理解,此时标签出了I am a,那么对于a可以利用前三个词,但对于第四个没出的不能使用,所以要给它掩盖起来。

3.BERT
替代encoder

参考文献
1.Transformer原理精讲_哔哩哔哩_bilibili
2.67 自注意力【动手学深度学习v2】_哔哩哔哩_bilibili
3. 68 Transformer【动手学深度学习v2】_哔哩哔哩_bilibili文章来源:https://www.toymoban.com/news/detail-641575.html
4.(重点)2023年AI爆火方向:基于Transformer模型的计算机视觉实战集锦【医疗图像分割、VIT算法、swintransformer、DETR目标检测...】_哔哩哔哩_bilibili 文章来源地址https://www.toymoban.com/news/detail-641575.html
到了这里,关于Transformer(一)简述(注意力机制,NLP,CV通用模型)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!