目录
一.yolov5的运行环境配置(Windows系统)
1、NVIDIA驱动安装与更新
2、Anaconda 的安装
3、Pytorch环境安装
4、pycharm安装
二.yolov5训练数据集,得到best.pt(Windows系统)
1.下载YOLO项目代码
2.环境安装
3. 数据集下载:
三.best.pt转为onnx模型(Windows系统)
四.best.onnx转为best.rknn模型(Linux系统)
1.环境准备和工具包安装
2.onnx转换为rknn
五.RK3568板子上运行demo(RK3568)
1.通电,联网
2.在RK3568板子上运行yolov5_demo
六.将自己训练过且转换后的best.rknn传送到RK3568板子上,并运行(RK3568)
1.通过WinSCP传输文件
2.RK3568平台部署best.rknn
一.yolov5的运行环境配置(Windows系统)
1、NVIDIA驱动安装与更新
首先查看电脑的显卡版本,直接搜索设备管理器–>显示适配器。就可以看到电脑显卡的版本了。如图,可以看到我的是一块NVDIA GeForce RTX3060显卡

显卡驱动的下载地址
安装(更新)好了显卡驱动以后。我们按下win+R组合键,打开cmd命令窗口。输入如下的命令。
nvidia-smi 得到CUDA Version的最高适配版本,为12.0,比它低的版本都可以下载。
2、Anaconda 的安装
打开网址,下载,这里选择对应的anaconda版本是支持python3.9的。

双击下载好的anaconda安装包,just me是说只供当前用户使用。all user 是供使用这台电脑的所有用户使用,是权限问题。对空间影响不大。如果你的电脑上只有建了一个用户,all users和just me 的作用是一样的。所以点击just me就好了。
然后点击next,当让你选择安装安装路径的时候,一定不要选择默认安装位置,因为默认位置是c盘,以后要在anaconda里面创建环境的时候会很占内存,最好在D盘中创建一个文件夹来放anaconda。
和图中一样将图中的√勾上,虽然出现红色的警告,但是要勾上,将anaconda添加到环境变量中去。然后点击完成就好了。

安装完成以后,按下开始键(win键)在左边就会出现anaconda3这个文件夹,可以发现anaconda已经安装好了。

3、Pytorch环境安装
按下开始键(win键),打开anaconda的终端。
创建虚拟环境conda create -n 环境名字(英文) python=x.x(python版本),如下,我就是创建了一个名字叫pytorch,python是3.8版本的环境。
conda create -n pytorch python=3.8在base环境中执行如上的命令,就会创建一个新的虚拟环境,这个虚拟环境会安装一些基础的包,如下图所示。询问是否安装的时候,输入y。就可以创建环境了。

当安装好了以后,执行conda env list这个命令,就可以看到比一开始多了一个pytorch这个环境。现在我们可以在这个环境里面安装深度学习框架和一些Python包了。
conda env list 
执行如下命令,激活这个环境。conda activate 虚拟环境名称。
conda activate pytorch安装pytorch-gup版的环境,由于pytorch的官网在国外,下载相关的环境包是比较慢的,所以我们给环境换源。在pytorch环境下执行如下的命名给环境换清华源。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes然后打开pytorch的官网,由于开头我们通过驱动检测到我的显卡为 NVDIA GeForce RTX3060,最高支持cuda12.0版本,为了稳定,我们选择cuda11.3版本的cuda,然后将下面红色框框中的内容复制下来。
conda install pytorch torchvision torchaudio pytorch-cuda=11.3 -c pytorch -c nvidia如果由于网络原因,conda没有成功,就试下pip安装。
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113还是不行的话,就将torch,torchvision,torchaudio的包分别下载下来。Ctrl+F可以搜索


放到安装环境下,执行安装
pip install torch-1.10.1+cu113-cp38-cp38-win_amd64.whl在虚拟环境下,执行
conda list查看安装的包,主要出现 torch 后面跟着的1.10.1+cu113。torchvision,torchaudio也是。

在虚拟环境下打开python,import torch,后输入
print(torch.cuda.is_available())打印True,即为成功。

4、pycharm安装
打开这个pycharm网址,可以发现一共有两个版本一个是专业版(Professional),一个是社区版(Community),专业版是需要花钱的,好几百美元一年。而社区版是免费的,但是也够用了,所以就下载安装社区版就好了。

将下载好的pycharm安装包,双击。安装的地址最好不要放在C盘。
将所有的√都勾上,

安装好了点击第二个框框,然后点完成就好了

创建一个工程,这时候我们就要选择我们在anaconda里面安装的环境,在界面的右下角

二.yolov5训练数据集,得到best.pt(Windows系统)
1.下载YOLO项目代码
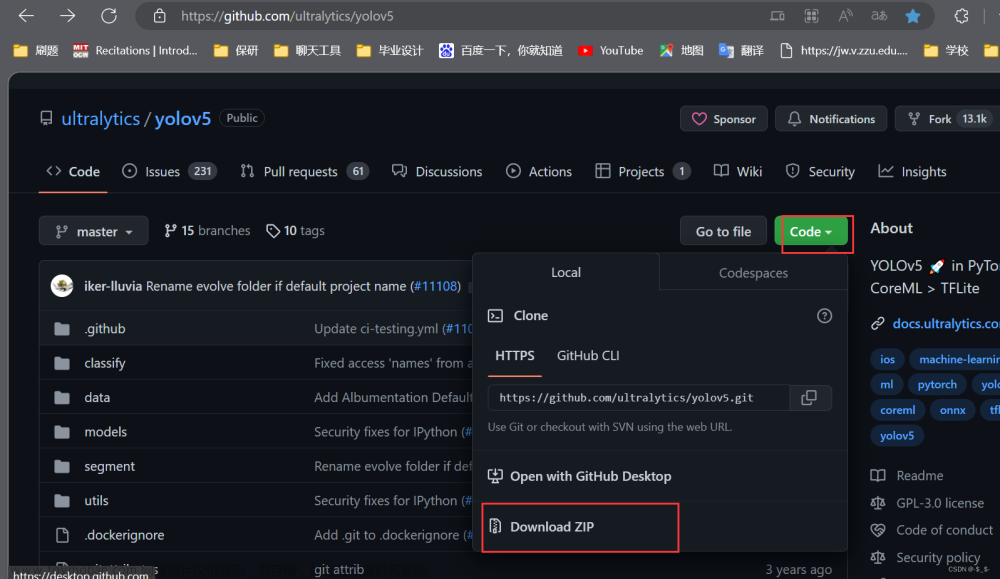
点击这里下载并解压YOLO的官方代码:GitHub - ultralytics/yolov5 at v5.0
2.环境安装
将requirements.txt放到相应的环境文件夹下,在anconda命令窗中输入
pip install -r requirements.txt3. 数据集下载:
使用百度飞桨提供的3种水果检测的小数据集,百度网盘链接:https://pan.baidu.com/s/1XM1xdM6E7JcIm7EU8J0uMw
提取码:m9h6
下载后解压好,放入刚刚下载的YOLO项目的文件夹里边(注意:小白一定要放,跟着走就不会报错,如果是大神的话那就随意了)
参考:https://blog.csdn.net/weixin_45941288/article/details/124286924
三.best.pt转为onnx模型(Windows系统)
请看官方教程:
rknn-toolkit/examples/pytorch/yolov5 at master · rockchip-linux/rknn-toolkit · GitHub
需要指出的是,虽然我们后面要使用的是rknn-toolkit2工具进行模型转换,但教程却在rknn-toolkit工程中,github二者的父目录如图:


上面的
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x[i](bs,self.no * self.na,20,20) to x[i](bs,self.na,20,20,self.no)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid() # (tensor): (b, self.na, h, w, self.no)
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no)) # z (list[P3_pred]): Torch.Size(b, n_anchors, self.no)
return x if self.training else (torch.cat(z, 1), x)v5.5.0的
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)v5.6的
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
if isinstance(self, Segment): # (boxes + masks)
xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)
xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf.sigmoid(), mask), 4)
else: # Detect (boxes only)
xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, self.na * nx * ny, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)改为
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
return x注意:在训练时不要修改yolo.py的这段代码,训练完成后使用export.py进行模型导出转换时一定要进行修改,不然会导致后面的rknn模型转换失败!
在export.py文件的最开始添加以下代码
import sys
#里面替换为自己项目目录下的文件路径
sys.path.insert(0, '/yolov5_ccj_alage/')修改后将export.py移动至best.pt同一文件夹下,在命令行调用以下命令:

python export.py --weights best.pt --img 640 --batch 1 
我们便可以得到成功转换的模型best.onnx。

四.best.onnx转为best.rknn模型(Linux系统)
1.环境准备和工具包安装
有了以上的best.onnx模型作为基础,现在可以正式开始rknn模型的转换了。此处的转换工具rknn-toolkit2只能在Linux系统上运行,这里我使用的是PC上的Ubuntu虚拟机。首先安装rknn-toolkit2的环境, 其环境要求在./doc/requirements_cp38-1.4.0.txt中,这里我使用的是conda创建的python3.8虚拟环境,和windows下anaconda使用方法类似,推荐大家在管理python环境时使用。创建环境并命名为rknn,使用pip安装requirements_cp38-1.4.0.txt中的包。
conda activate rknnpip install -r requirements_cp38-1.4.0.txt如果因为网络原因未安装成功,可以换源。
pip install xxxxx -i https://pypi.tuna.tsinghua.edu.cn/simple环境满足需求后便可以安装rknn-toolkit2工具包了,浏览至./packages中,输入以下命令:
pip install rknn_toolkit2-1.4.0_22dcfef4-cp38-cp38-linux_x86_64.whl提示安装完成后我们可以检查是否安装成功,在终端中运行python,输入:
from rknn.api import RKNN若不报错说明我们的工具包已经安装成功,之后便可进行rknn模型的转换了
2.onnx转换为rknn
在rknn-toolkit2工程文件夹中浏览至./examples/onnx/yolov5,将我们在2.2中转换得到的best.onnx复制到该文件夹下,修改该文件夹下的test.py中的内容为自己模型的名字,要修改的地方如下:

修改模型和待预测图片,以及自定义的类别。

如果板子是RK3568,即换成RK3568,后面用的板子是RK3568的。
在这个test.py的main函数中(在第239行附近)可以了解到这个python文件的作用:
【 配置——加载onnx模型—导出rknn模型——rknn模型推理——后处理——输出结果】
在test.py的最后,取消注释,添加cv.imwrite。

运行test.py,开始转换
python test.py


result.jpg

五.RK3568板子上运行demo(RK3568)
1.通电,联网



绿灯即运行成功
打开桌面的LXTerminal,输入ifconfig,查看网络状态和地址,
依次输入
systemctl status NetworkManager
systemctl enable NetworkManager
systemctl restart NetworkManager
nmcli c add type ethernet con-name conn-eth1 ifname eth1 ipv4.method auto

执行下面命令
nmcli c show 
nmcli c delete xxxxxxxxxxxxxxxxxxxxxxxxxxxx(uuid)把所有查出来的uuid都删除掉,然后就可以去图形界面编辑,联网了。

2.在RK3568板子上运行yolov5_demo
下载好rknpu2_1.3.0,放到了/home/data/ 目录下,安装好编译环境所需要的,如Cmake,gcc,g++等,可以先执行.sh文件,看缺什么安什么。打开LXTerminal。
cd /home/data/rknpu2_1.3.0/examples/rknn_yolov5_demo/install/rknn_yolov5_demo_Linux./rknn_yolov5_demo model/RK356X/yolov5s-640-640.rknn model/bus.jpg 

47.763500 ms
运行结果在上一级文件里

resize_input.jpg是resize后的输入图片,像素大小为640*640,out.jpg是输出的图片


可以多用几张coco数据集里面的照片进行测试,像素大小调整为640*640
例如斑马,可以通过U盘将文件导入RK3568板子里去
./rknn_yolov5_demo model/RK356X/yolov5s-640-640.rknn model/horse.jpg 


用时47.656 ms
六.将自己训练过且转换后的best.rknn传送到RK3568板子上,并运行(RK3568)
1.通过WinSCP传输文件
通过插拔U盘比较费时,且有时候接触不良,rk3568板子不能识别,所以通过WinSCP传输,WinSCP :: Official Site :: Free SFTP and FTP client for Windows官网下载,在RK3568的板子,输入
ifconfig查询板子的ip地址,

ip地址为172.25.177.28。打开WinSCP,写入主机名,端口号改为22,用户名为root

点击登录后,输入密码,即可相互传输文件。

2.RK3568平台部署best.rknn
cd /home/data/rknpu2_1.3.0/examples/rknn_yolov5_demo
进入include文件夹,找到头文件postprocess.h,
vim操作命令:i 插入,esc退出操作命令,:wq保存并退出。
#define OBJ_CLASS_NUM 3 #这里的数字修改为数据集的类的个数修改rknn_yolov5_demo/model目录下的coco_80_labels_list.txt文件, 改为自己的类并保存
apple
banana
orange并将待检测的图片defect_det.jpg放到目录下

将转换后的best.rknn文件通过WinSCP放在rknn_yolov5_demo/model/RK356X目录下
在rknn_yolov5_demo目录下编译,运行shell
bash ./build-linux_RK356X.sh
成功后生成install目录
cd install/rknn_yolov5_demo_Linux
运行(这里是将Linux系统下生成的best.rknn的名称改为了best-640-640.rknn,其实是没变的,所以下面要用best-640-640.rknn)
./rknn_yolov5_demo model/RK356X/best-640-640.rknn model/defect_det.jpg在rknn_yolov5_demo_Linux获取到结果

用时48607.371000 ms,用时过长,需要改进,且不能退出执行命令了



参考:
(103条消息) 一分钟教会您使用Yolov5训练自己的数据集并测试_yolov5测试_DK数据工作室的博客-CSDN博客
(99条消息) yolov5训练pt模型并转换为rknn模型,部署在RK3588开发板上——从训练到部署全过程_rknn yolov5_Billy_zz的博客-CSDN博客文章来源:https://www.toymoban.com/news/detail-641730.html
(104条消息) Yolov5的配置+训练(超级详细!!!)_小学生玩编程的博客-CSDN博客_yolov5训练文章来源地址https://www.toymoban.com/news/detail-641730.html
到了这里,关于yolov5的运行环境配置、参数修改和训练命令,并将训练的pt模型转换为rknn模型,并推理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!