参考:文章来源:https://www.toymoban.com/news/detail-642081.html
Apache Flink学习网文章来源地址https://www.toymoban.com/news/detail-642081.html
到了这里,关于Flink-网络流控及反压剖析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了Flink-网络流控及反压剖析。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
参考:文章来源:https://www.toymoban.com/news/detail-642081.html
Apache Flink学习网文章来源地址https://www.toymoban.com/news/detail-642081.html
到了这里,关于Flink-网络流控及反压剖析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!
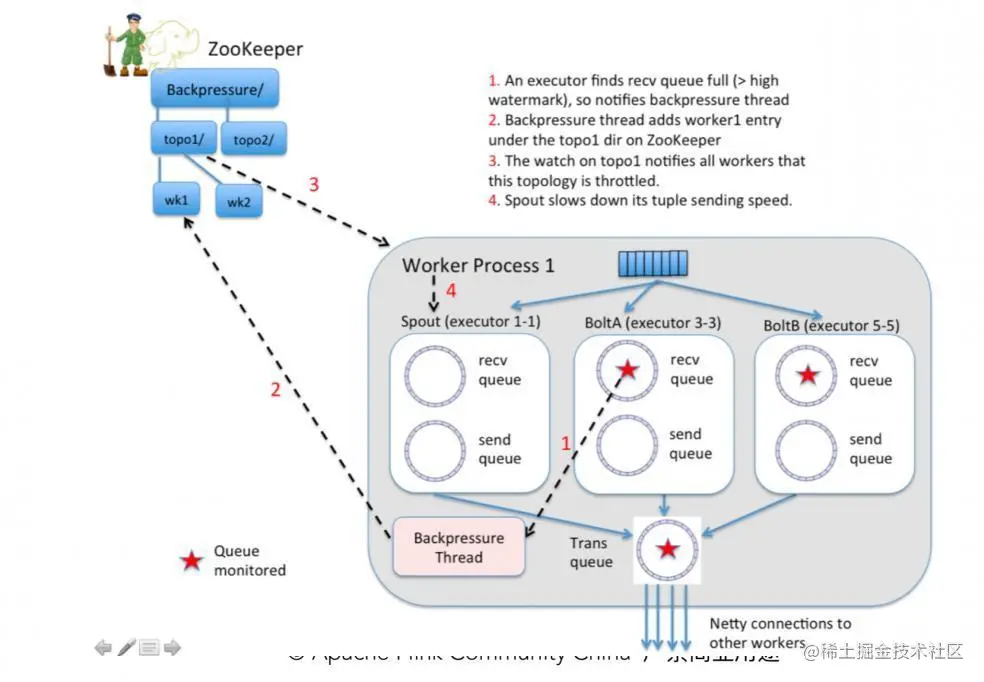
Flink 反压机制 Flink 如何处理反压? Storm 反压机制 Storm反压机制 Storm 在每一个 Bolt 都会有一个监测反压的线程(Backpressure Thread),这个线程一但检测到 Bolt 里的接收队列(recv queue)出现了严重阻塞就会把这个情况写到 ZooKeeper 里,ZooKeeper 会一直被 Spout 监听,监听到有反压的

首先说明,偶然看了个论文,发现 flink优化原来比我想象中的更简单,得到了一些启发,所以写下这篇帖子,供大家共同学习。 看到的论文是《计算机科学与应用》21年11月的一篇 名字就叫做 : 一种基于动态水位值的Flink调度优化算法。感兴趣的小伙伴可以自己看一下 ,很

前面我们分别介绍了大数据计算框架Hadoop与Spark,虽然他们有的有着良好的分布式文件系统和分布式计算引擎,有的有着分布式数据集和基于内存的分布式计算引擎,但是却不能对无边界数据流进行有效处理,今天我们就分享一个第四代大数据分布式计算框架Flink简介与架构剖

前面我也有提到,发现flink运行一段时间后,不再继续消费的问题。这个问题困扰了我非常久,一开始也很迷茫。又因为比较忙,所以一直没有时间能够去寻找答案,只是通过每天重启的方式去解决。经过分析,其实这个问题也很容易找到根源,有兴趣就和我一起看下叭 首先
深入理解 Flink 系列文章已完结,总共八篇文章,直达链接: 深入理解 Flink (一)Flink 架构设计原理 深入理解 Flink (二)Flink StateBackend 和 Checkpoint 容错深入分析 深入理解 Flink (三)Flink 内核基础设施源码级原理详解 深入理解 Flink (四)Flink Time+WaterMark+Window 深入分析 深入

title: Flink系列 StateBackend 定义了状态是如何存储的,不同的 State Backend 会采用不同的方式来存储状态,核心入口是: StateBackend, Flink 提供了三种不同形式的存储后端,分别是 MemoryStateBackend, FsStateBackend 和 RocksDBStateBackend。 MemoryStateBackend 会将工作状态(Task State)存储在 T

Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。 Flink最适合的应用场景是低时延的数据处理(Data Processing)场景:高并发pipeline处理数据,时延毫秒级

累加器是实现了 加法运算 功能和 合并运算 (合并多个累加器的结果)功能的一种数据结构,在作业结束后,可以获取所有部分(各个 operator 的各个 subtask)合并后的最终结果并发送到客户端。 Flink 的累加器均实现了 Accumulator 接口,包括如下 2 个方法用于支持加法运算和合

每个并行的实例都会包含一个 RuntimeContext 。 RuntimeContext 接口包含函数执行的上下文信息,提供了如下功能: 访问静态上下文信息(例如当前并行度) 添加及访问累加器 访问外部资源信息 访问广播变量和分布式缓存 访问并编辑状态 下面,我们逐类介绍 RuntimeContext 接口的方

在 Flink 中有如下 5 种键控状态(Keyed State),这些状态仅能在键控数据流(Keyed Stream)的算子(operator)上使用。键控流使用键(key)对数据流中的记录进行分区,同时也会对状态进行分区。要创建键控流,只需要在 DataStream 上使用 keyBy() 方法指定键即可。 具体地,这 5 种键



