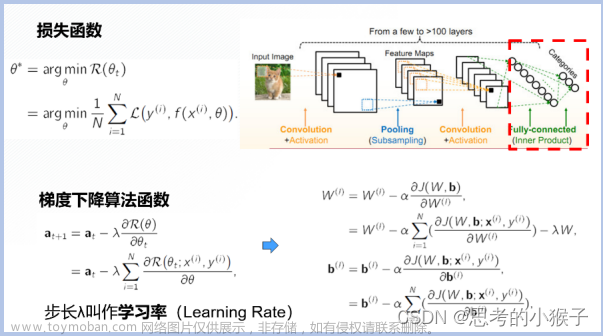
在上篇博客《锚框【目标检测】》中,我们以输入图像的每个像素为中心,生成多个锚框。基本而言,这些锚框代表了图像不同区域的样本。然而如果以每个像素都生成的锚框,最后可能会得到太多需要计算的锚框。想象一个561×728的输入图像,如果以每个像素为中心生成五个形状不同的锚框,就需要在图像上标记和预测超过200万个锚框(561×728×5)。
多尺度锚框
减少图像上的锚框数量并不困难,比如可以在输入图像中均匀采样一小部分像素,并以它们为中心生成锚框。直观地说,比起较大的目标,较小的目标在图像上出现的可能性更多样。例如1×1、1×2和2×2的目标可以分别以4、2和1种可能的方式出现在2×2的图像上。因此当使用较小的锚框检测较小的物体时,我们可以采样更多的区域,而对于较大的物体,我们可以采样较少的区域。
我们将卷积图层的二维数组输出称为特征图。通过定义特征图的形状,我们可以确定任何图像上均匀采样锚框的中心。文章来源:https://www.toymoban.com/news/detail-642275.html
display_anchor函数定义如下,我们在特征图(fmap)上生成锚框(anchors),每个单位像素作为锚框的中心。然后将特征图中的锚框后向映射至输入图像。文章来源地址https://www.toymoban.com/news/detail-642275.html
import torch as t
import matplotlib.pyplot as plt
img = plt.imread('catdog.jpg')
h,w = img.shape[:2]
def display_anchors(fmap_w, fmap_h, s):
# 前两个维度的值不影响输出
fmap = t.zeros((1,10,fmap_h, fmap_w), dtype=t.float32)
an到了这里,关于多尺度目标检测【动手学深度学习】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!