1、缓冲区溢出概述
什么是缓冲区?它是指程序运行期间,在内存中分配的一个连续的区域,用于保存包括字符数组在内的各种数据类型。所谓溢出,其实就是所填充的数据超出了原有的缓冲区边界,并非法占据了另一段内存区域。
两者结合进来,所谓缓冲区溢出,就是由于填充数据越界而导致原有流程的改变,黑客借此精心构造填充数据,让程序转而执行特殊的代码,最终获取控制权。
2、堆
堆(Heap),用于存储程序运行过程中动态分配的数据块。
堆的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
随着系统动态分配给进程的内存数量的增加,Heap(堆) 一般来说是向内存的高地址方向增长的。
3、栈
函数被调用的时候,栈中的压入情况如下:

4、缓冲区溢出的原理
如果在堆栈中压入的数据超过预先给堆栈分配的容量时,就会出现堆栈溢出,从而使得程序运行失败;如果发生栈溢出的是大型程序还有可能会导致系统崩溃。
5、代码植入技术
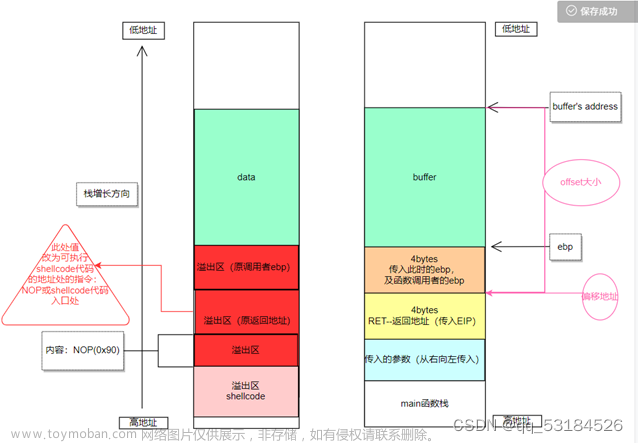
所植入的代码一般由shellcode、返回地址、填充数据这三种元素按照一定的结构和构造类型组成
5.1什么是shellcode
-是植入代码的核心组成部分,是一段能完成特殊任务的自包含的二进制代码。
-由于它最初是用来生成一个高权限的shell,因此而得名。虽然现在人们已经远远不满足于生成一个shell,但shellcode的“美名”一直延用至今。
-攻击者通过巧妙的编写和设置,利用系统的漏洞将shellcode送入系统中使其得以执行,从而获取特殊权限的执行环境,或给自己设立有特权的帐户,取得目标机器的控制权。
除了经典的利用exec()系统调用执行/bin/sh获取shell之外,下表列出了Unix/Linux系统中的shellcode经常用到的一些其它系统调用。

在linux中,为了获得一个交互式shell,一般需要执行代码execve(“/bin/sh”, “/bin/sh”, NULL);
对此代码进行编译后得到机器码。
char shellcode[] = “\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd\x80\xe8\xdc\xff\xff\xff/bin/sh”;
注意:不同的操作系统、不同的机器硬件产生系统调用的方法和参数传递的方法也不尽相同。
网络安全学习资源分享:
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
同时每个成长路线对应的板块都有配套的视频提供:


这份完整版的网络安全(嘿客)全套学习资料已经上传至CSDN官方,朋友们如果需要点击下方链接也可扫描下方微信二v码获取网络工程师全套资料【保证100%免费】
 文章来源地址https://www.toymoban.com/news/detail-642717.html
文章来源地址https://www.toymoban.com/news/detail-642717.html
5.2 返回地址
返回地址是指shellcode的入口地址。攻击者如果希望目标程序改变其原来的执行流程,转而执行shellcode,则必须设法用shellcode的入口地址覆盖某个跳转指令。
由于所植入的代码是被复制到目标机器的缓冲区中,攻击者无法知道其进入到缓冲区后的确切地址。不过,内存的分配是有规律的,如Linux系统,当用户程序运行时,栈是从0xbfffffff开始向内存低端生长的。如果攻击者想通过改写函数返回地址的方式使程序指令发生跳转,则程序指令跳转后的指向也应该在0xbfffffff附近。
事实上,虽然不同的缓冲区溢出漏洞,其植入代码的返回地址都不同,但均处于某个较小的地址区间内。另外,为了提高覆盖函数返回地址的成功率,往往在植入代码中安排一段由重复的返回地址组成的内容。
5.3 填充数据
由于攻击者不能准确地判断shellcode的入口地址,因此为了提高shellcode的命中率,往往在shellcode的前面安排一定数量的填充数据。
填充数据必须对植入代码的功能完成没有影响,这样只要返回地址指向填充数据中的任何一个位置,均可以确保shellcode顺利执行。
填充数据还可以起到一个作用,就是当植入代码的长度够不着覆盖目标如函数返回地址时,可以通过增加填充数据的数量,使植入代码的返回地址能够覆盖函数返回地址。
6、植入代码的构造类型
所植入的代码是由黑客精心构造的,而由于缓冲区溢出自身的特性,它的结构和构造类型有一定的特性:NSR模式、RNS模式、AR模式
其中:S代表shellcode,R代表返回地址,N代表填充数据,A表示环境变量。
NSR模式

在shellcode的后面安排一定数量的返回地址,在前面安排一定数量的填充数据,这种结构称为NSR型,或前端同步型。
原理是:只要全部的N和S都处于缓冲区内,并且不覆盖RET,而使R正好覆盖存放RET的栈空间,这样只要将R的值设置为指向N区中任一位置,就必然可以成功地跳转到我们预先编写的shellcode处执行。
这是一种经典结构,适合于溢出缓冲区较大、足够放下我们的shellcode的情况。
这是一种非精确定位的方法,N元素越多成功率越大,其缺点是缓冲区必须足够大,否则shellcode放不下或者N元素数量太少都会造成失败。
RNS模式

其原理是:只要把整个缓冲区全部用大量的返回地址填满,并且保证会覆盖存放RET的栈空间,再在后面紧接N元素和shellcode,这样就可以很容易地确定返回地址R的值,并在植入代码中进行设置。
这里填充的R的数目必须能够覆盖ret,R的值必须指向大量N中的任何一个。
这种方法对大的和小的缓冲区都有效。而且RET地址较容易计算。
AR模式

又称环境变量型。这种构造类型不同于NSR型和RNS型,它必须事先将shellcode放置在环境变量中,然后将shellcode的入口地址和填充数据构成植入代码进行溢出攻击。
这种构造类型对于大、小溢出缓冲区都适合。但由于必须事先将shellcode放置到环境变量中,故其应用受到了限制,只能用于本地而不能用于远程攻击。
缓冲区溢出攻击的三步曲
从上面的分析可知,不管哪种类型的缓冲区溢出攻击,一般都存在下面三个步骤:
①构造需要执行的代码shellcode,并将其放到目标系统的内存。
②获得缓冲区的大小和定位溢出点ret的位置。
③ 控制程序跳转,改变程序流程。
7、缓冲区溢出攻击的防御技术
基于软件的防御技术:类型安全的编程语言、相对安全的函数库、修改的编译器、内核补丁、静态分析方法、动态检测方法。
基于硬件的防御技术:处理器结构方面的改进
类型安全的编程语言
安全的编程语言:Java, C#, Visual Basic,Pascal, Ada, Lisp, ML属于类型安全的编程语言。
缺点:
-性能代价。
-类型安全的编程语言自身的实现可能存在缓冲区溢出问题。
相对安全的函数库
相对安全的标准库函数:例如在使用C的标准库函数时,做如下替换
strcpy -> strncpy strcat -> strncat gets -> fgets
缺点
-使用不当仍然会造成缓冲区溢出问题。
修改的编译器
-增强边界检查能力的C/C++编译器:例如针对GNU C编译器扩展数组和指针的边界检查。Windows Visual C++ .NET的GS 选项也提供动态检测缓冲区溢出的能力。
-返回地址的完整性保护:①将堆栈上的返回地址备份到另一个内存空间;在函数执行返回指令前,将备份的返回地址重新写回堆栈。
②许多高性能超标量微处理器具有一个返回地址栈,用于指令分支预测。返回地址栈保存了返回地址的备份,可用于返回地址的完整性保护
缺点
-性能代价
-检查方法仍不完善
内核补丁
-将堆栈标志为不可执行来阻止缓冲区溢出攻击;
-将堆或者数据段标志为不可执行。
-例如Linux的内核补丁Openwall 、 RSX、 kNoX、ExecShield和PaX等实现了不可执行堆栈,并且RSX、 kNoX、ExecShield、PaX还支持不可执行堆。另外,为了抵制return-to-libc这类的攻击,PaX增加了一个特性,将函数库映射到随机的内存空间
-缺点:对于一些需要堆栈/堆/数据段为可执行状态的应用程序不合适;需要重新编译原来的程序,如果没有源代码,就不能获得这种保护。 =
静态分析方法
字典检查法
-遍历源程序查找其中使用到的不安全的库函数和系统调用。
-例如静态分析工具ITS4、RATS (Rough Auditing Tool for Security)等。其中RATS提供对C, C++, Perl, PHP以及Python语言的扫描检测。
-缺点:误报率很高,需要配合大量的人工检查工作。
程序注解法
-包括缓冲区的大小,指针是否可以为空,输入的有效约定等等。
-例如静态分析工具LCLINT、SPLINT (Secure Programming Lint)。
-缺点:依赖注释的质量
整数分析法
-将字符串形式化为一对整数,表明字符串长度(以字节数为单位)以及目前已经使用缓冲区的字节数。通过这样的形式化处理,将缓冲区溢出的检测转化为整数计算。
-例如静态分析工具BOON (Buffer Overrun detectiON)。
-缺点:仅检查C中进行字符串操作的标准库函数。检查范围很有限。
控制流程分析法
-将源程序中的每个函数抽象成语法树,然后再把语法树转换为调用图/控制流程图来检查函数参数和缓冲区的范围。
-例如静态分析工具ARCHER (ARray CHeckER)、UNO、PREfast和Coverity等。
-缺点:对于运行时才会显露的问题无法进行分析 ;存在误报的可能。
动态检测方法:输入检测方法
-向运行程序提供不同的输入,检查在这些输入条件下程序是否出现缓冲区溢出问题。不仅能检测缓冲区溢出问题,还可以检测其它内存越界问题。
-采用输入检测方法的工具有Purify、Fuzz和FIST(Fault Injection Security Tool)。
-缺点:系统性能明显降低。输入检测方法的检测效果取决于输入能否激发缓冲区溢出等安全问题的出现。
基于硬件的防御技术
64位处理器的支持
-Intel/AMD 64位处理器引入称为NX(No Execute)或者AVP(Advanced Virus Protection)的新特性,将以前的CPU合为一个状态存在的“数据页只读”和“数据页可执行”分成两个独立的状态。
-ELF64 SystemV ABI通过寄存器传递函数参数而不再放置在堆栈上,使得64位处理器不仅-可以抵制需要注入攻击代码的缓冲区溢出攻击还可以抵制return-to-libc这类的攻击。
-缺点:无法抵制“borrowed code chunks”这类的攻击。文章来源:https://www.toymoban.com/news/detail-642717.html
这份完整版的网络安全(嘿客)全套学习资料已经上传至CSDN官方,朋友们如果需要点击下方链接也可扫描下方微信二v码获取网络工程师全套资料【保证100%免费】
如果你有需要可以点击👉CSDN大礼包:《嘿客&网络安全入门&进阶学习资源包》免费分享
到了这里,关于网络安全——缓冲区溢出攻击的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[操作系统安全]缓冲区溢出](https://imgs.yssmx.com/Uploads/2024/02/780476-1.png)








