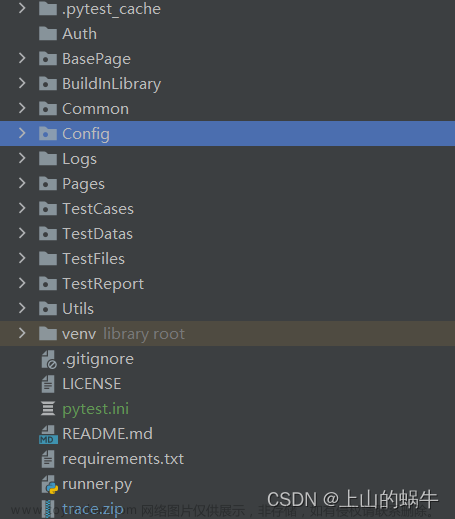
目录
框架介绍
框架结构
框架功能讲解
common # 配置
config.yaml # 公共配置
setting.py # 环境路径存放区域
data # 测试用例数据
Files # 上传文件接口所需的文件存放区域
logs # 日志层
report # 测试报告层
test_case # 测试用例代码
__init__.py # 读取测试用例文件,并将测试用例数据写入缓存池
conftest.py # 工具函数集合
utils # 工具类
assertion # 测试断言模块
assert_control.py # 断言
assert_type.py # 断言类型
cache_process # 缓存处理模块 cache_control.py # 缓存文件处理
redis_control.py # redis缓存操作封装
logging_tool # 日志处理模块
log_control.py # 日志封装,可设置不同等级的日志颜色
log_decorator.py # 日志装饰器
run_time_decorator.py # 统计用例执行时长装饰器
mysql_tool # 数据库模块
mysql_control.py # mysql封装
notify # 通知模块
ding_talk.py # 钉钉通知
lark.py # 飞书通知
send_mail.py # 邮箱通知
wechat_send.py # 企业微信通知
other_tools # 其他工具类
allure_data # allure封装
allure_report_data.py # allure报告数据清洗
allure_tools.py # allure 方法封装
error_case_excel.p # 收集allure异常用例,生成excel测试报告
install_tool # 安装工具
install_requirements.py # 自动识别安装最新的依赖库
version_library_comparisons.txt # 依赖
exceptions.py # 自定义异常类
get_local_ip.py # 获取本地IP
jsonpath_date_replace.py # 处理jsonpath数据
models.py # 定义类和枚举变量
thread_tool.py # 定时器类
read_files_tools # 读取文件工具
case_automatic_control.py # 自动生成测试代码
clean_files.py # 清理文件
excel_control.py # 读写excel
get_all_files_path.py # 获取所有文件路径
get_yaml_data_analysis.py # yaml用例数据清洗
regular_control.py # 正则
swagger_for_yaml.py # Swagger文档转换,生成YAML用例
testcase_template.py # 测试用例模板
yaml_control.py # yaml文件读写
recording # 代理录制
mitmproxy_control.py # mitmproxy库拦截获取网络请求
requests_tool # 请求数据模块
dependent_case.py # 数据依赖处理
encryption_algorithm_control.py # 加密算法
request_control.py # 请求封装
set_current_request_cache.py # 缓存设置
teardown_control.py # 请求处理
times_tool # 时间模块
time_control.py # 时间设置
Readme.md # 自述文件
pytest.ini # Pytest 的配置文件
run.py # 运行入口
框架介绍
这个接口自动化框架使用Python语言开发,采用pytest测试框架结合allure测试报告、log日志记录、yaml数据驱动、mysql、redis数据库操作、钉钉通知以及Jenkins集成自动构建等功能,实现了自动化接口测试的全流程。
该框架实现了数据驱动,支持将测试用例保存在yaml文件中,通过读取yaml文件来进行测试数据的驱动,并且支持针对不同环境的测试数据配置。而且,框架集成了mysql和redis数据库,可以对相关的数据进行操作,提高测试的覆盖范围和精度。
在测试过程中,框架支持记录测试日志以及生成allure测试报告,方便开发人员进行测试结果的查看和分析。如果测试失败,框架还支持发送钉钉通知,及时通知相关人员进行处理。另外,框架还集成了Jenkins自动化构建,可以进行持续集成和持续测试,提高测试效率和稳定性。
框架结构
├── common // 配置
│ ├── config.yaml // 公共配置
│ ├── setting.py // 环境路径存放区域
├── data // 测试用例数据
├── Files // 上传文件接口所需的文件存放区域
├── logs // 日志层
├── report // 测试报告层
├── test_case // 测试用例代码
│ ├── __init__.py // 读取测试用例文件,并将测试用例数据写入缓存池
│ ├── conftest.py // 工具函数集合
├── utils // 工具类
│ └── assertion // 测试断言模块
│ └── assert_control.py // 断言
│ └── assert_type.py // 断言类型
│ └── cache_process // 缓存处理模块
│ └── cache_control.py // 缓存文件处理
│ └── redis_control.py // redis缓存操作封装
│ └── logging_tool // 日志处理模块
│ └── log_control.py // 日志封装,可设置不同等级的日志颜色
│ └── log_decorator.py // 日志装饰器
│ └── run_time_decorator.py // 统计用例执行时长装饰器
│ └── mysql_tool // 数据库模块
│ └── mysql_control.py // mysql封装
│ └── notify // 通知模块
│ └── ding_talk.py // 钉钉通知
│ └── lark.py // 飞书通知
│ └── send_mail.py // 邮箱通知
│ └── wechat_send.py // 企业微信通知
│ └── other_tools // 其他工具类
│ └── allure_data // allure封装
│ └── allure_report_data.py // allure报告数据清洗
│ └── allure_tools.py // allure 方法封装
│ └── error_case_excel.p // 收集allure异常用例,生成excel测试报告
│ └── install_tool // 安装工具
│ └── install_requirements.py // 自动识别安装最新的依赖库
│ └── version_library_comparisons.txt // 依赖
│ └── exceptions.py // 自定义异常类
│ └── get_local_ip.py // 获取本地IP
│ └── jsonpath_date_replace.py // 处理jsonpath数据
│ └── models.py // 定义类和枚举变量
│ └── thread_tool.py // 定时器类
│ └── read_files_tools // 读取文件工具
│ └── case_automatic_control.py // 自动生成测试代码
│ └── clean_files.py // 清理文件
│ └── excel_control.py // 读写excel
│ └── get_all_files_path.py // 获取所有文件路径
│ └── get_yaml_data_analysis.py // yaml用例数据清洗
│ └── regular_control.py // 正则
│ └── swagger_for_yaml.py // Swagger文档转换,生成YAML用例
│ └── testcase_template.py // 测试用例模板
│ └── yaml_control.py // yaml文件读写
│ └── recording // 代理录制
│ └── mitmproxy_control.py // mitmproxy库拦截获取网络请求
│ └── requests_tool // 请求数据模块
│ └── dependent_case.py // 数据依赖处理
│ └── encryption_algorithm_control.py // 加密算法
│ └── request_control.py // 请求封装
│ └── set_current_request_cache.py // 缓存设置
│ └── teardown_control.py // 请求处理
│ └── times_tool // 时间模块
│ └── time_control.py // 时间设置
├── Readme.md // 自述文件
├── pytest.ini // Pytest 的配置文件
├── run.py // 运行入口 框架功能讲解
common # 配置
config.yaml # 公共配置
setting.py # 环境路径存放区域
详细讲解
import os
from typing import Text
# 定义一个函数`root_path()`,用于获取根路径。
def root_path():
""" 获取 根路径 """
# 使用`os`模块的三个函数,分别获取当前文件所在目录的上两级目录的绝对路径,并将其赋值给变量`path`,也就是获取根路径。
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# 将获得的根路径返回。
return path
# 定义一个名为`ensure_path_sep()`的函数,接收一个字符串类型的参数`path`,并指定该函数返回一个字符串类型的值。
def ensure_path_sep(path: Text) -> Text:
"""兼容 windows 和 linux 不同环境的操作系统路径 """
# 如果`path`中含有`/`这个字符。
if "/" in path:
# # 将`path`按照`/`拆分成一个列表,并使用`os.sep`将其拼接成一个路径,将拼接好的路径赋给变量`path`。`os.sep`用来获取当前操作系统的路径分隔符,以便在不同操作系统中正确地处理路径。
path = os.sep.join(path.split("/"))
# 如果`path`中含有`\\`这个字符。
if "\\" in path:
# 将`path`按照`\\`拆分成一个列表,并使用`os.sep`将其拼接成一个路径,将拼接好的路径赋给变量`path`。
path = os.sep.join(path.split("\\"))
# 返回根路径和拼接好的路径,组成完整的路径。可以看出,该函数的作用是将路径中的所有`/`和`\\`都替换成当前操作系统的路径分隔符,以免在不同操作系统中出现路径错误。
return root_path() + path
以上代码主要是关于路径处理的相关函数。
总的来说,以上代码是一个比较通用的路径处理函数集合,可以在不同的操作系统中兼容地处理路径问题。
data # 测试用例数据
Files # 上传文件接口所需的文件存放区域
logs # 日志层
report # 测试报告层
test_case # 测试用例代码
__init__.py # 读取测试用例文件,并将测试用例数据写入缓存池
详细讲解
from common.setting import ensure_path_sep
from utils.read_files_tools.get_yaml_data_analysis import CaseData
from utils.read_files_tools.get_all_files_path import get_all_files
from utils.cache_process.cache_control import CacheHandler, _cache_config
# 定义一个名为`write_case_process`的函数。
def write_case_process():
"""
获取所有用例,写入用例池中
:return:
"""
# 循环获取所有存放用例的文件路径,并将解析yaml格式的数据存到`case_process`中。
for i in get_all_files(file_path=ensure_path_sep("\\data"), yaml_data_switch=True):
# 利用`CaseData`类读取`i`文件的yaml格式数据,并调用`case_process`方法,将测试用例数据处理后返回到`case_process`数组中。
case_process = CaseData(i).case_process(case_id_switch=True)
# 判断`case_process`的值是否为`None`。
if case_process is not None:
# 如果`case_process`的值不为`None`,则遍历其中的每个测试用例数据。
for case in case_process:
# 遍历当前测试用例下的每个键值对,其中`k`为测试用例ID,`v`为测试用例数据。
for k, v in case.items():
# 判断当前测试用例ID是否已经存在于缓存池中。
case_id_exit = k in _cache_config.keys()
# 如果当前测试用例ID不存在于缓存池中,则通过`CacheHandler`类中的`update_cache`方法,将当前测试用例数据写入缓存池中。
if case_id_exit is False:
# 是一个成员方法,用于向一个名为cache_name的缓存对象中写入一个键值对。其中,k代表键名,v代表该键对应的值。
CacheHandler.update_cache(cache_name=k, value=v)
# 如果当前测试用例ID已经存在于缓存池中,则抛出一个异常。
elif case_id_exit is True:
# 抛出`ValueError`异常,并提示当前测试用例ID存在重复项,需要进行修改,同时展示文件路径。
raise ValueError(f"case_id: {k} 存在重复项, 请修改case_id\n"
f"文件路径: {i}")
# 调用`write_case_process`函数开始执行代码
write_case_process()
以上代码是一个用于读取测试用例文件,并将测试用例数据写入缓存池的函数。
总的来说,以上代码的功能就是将所有配置好的测试用例数据,读取后写入到缓存池中,以便后面的测试用例运行时能够实时获取并使用数据。conftest.py # 工具函数集合
详细讲解
import pytest
import time
import allure
import requests
import ast
import json
from common.setting import ensure_path_sep
from utils.requests_tool.request_control import cache_regular
from utils.logging_tool.log_control import INFO, ERROR, WARNING
from utils.other_tools.models import TestCase
from utils.read_files_tools.clean_files import del_file
from utils.other_tools.allure_data.allure_tools import allure_step, allure_step_no
from utils.cache_process.cache_control import CacheHandler
from utils import config
# @pytest.fixture是Pytest测试框架中使用的装饰器,用于标识一个函数为Pytest用例的fixture函数。通过fixture函数,我们可以在测试用例执行前或执行后,为测试用例提供一些前置条件或后置操作,比如初始化数据库连接、生成测试数据、删除临时文件等等。函数参数中的socpe参数和autouse参数是fixture函数的两个重要参数,分别用于指定fixture函数的作用域和自动调用情况。scope参数用于指定fixture函数的作用范围。常用的值包括:function(默认值)表示仅在当前测试用例中使用,每个测试用例都会重新创建;module表示在当前测试模块中使用,多个测试用例共用,每个测试模块执行前创建;session表示在整个测试session中使用,多个测试模块共用,整个测试会话只创建一次。autouse参数用于指定fixture函数是否自动调用。当autouse=True时,fixture函数会自动被执行;当autouse=False时,需要通过测试用例的参数显式调用才会执行。默认值为False。
@pytest.fixture(scope="session", autouse=False)
# 定义了一个名为clear_report的函数,主要功能是删除测试报告文件。
def clear_report():
"""如clean命名无法删除报告,这里手动删除"""
# 这行代码调用了一个 del_file() 函数,用于删除给定文件或文件夹。在本例中,该函数会删除当前工作目录下的 report 文件夹。这里的 ensure_path_sep() 函数用于确保路径分隔符是正确的。在 Windows 系统中,路径分隔符通常是反斜杠 \,而在 Unix/Linux 系统中,路径分隔符通常是正斜杠 /。为了保证代码的可移植性,我们通常需要使用 os.path.join() 或 os.path.sep 来获取系统默认的路径分隔符。在本例中,ensure_path_sep() 函数会将输入的路径字符串中的分隔符替换为系统默认的分隔符。
del_file(ensure_path_sep("\\report"))
# 总的来说,这个函数的作用就是清理测试报告,避免测试结果的污染和影响。
@pytest.fixture(scope="session", autouse=True)
# 定义了一个函数 init_info_accessToken,用于获取访问令牌。
def init_info_accessToken():
"""
获取AccessToken
:return:
"""
# 定义了一个请求的 URL,该 URL 是由 config.host 配置文件中的地址和请求路径 /init/info 拼接而成的。
url = str(config.host) + "/init/info"
payload = {}
headers = {
'Country': 'USD',
'Lang': 'en',
'Currency': 'US',
}
# 这里使用 requests 库发送了一个 GET 请求,并将响应结果转换为 JSON 格式。在本例中,该请求会向指定的 URL 发送一个 GET 请求,获取访问令牌。
response = requests.request("GET", url, headers=headers, data=payload).json()
# 这行代码从响应结果中获取到访问令牌,并赋值给一个变量 AccessToken。
AccessToken = response['data']['accessToken']
# 这行代码将获取到的访问令牌更新到一个缓存中。在本例中,使用的缓存是 CacheHandler 类中的 update_cache() 方法。
CacheHandler.update_cache(cache_name='Access_Token', value=AccessToken)
# 总的来说,这个函数的主要功能就是请求指定 URL,获取访问令牌,并将访问令牌保存到缓存中,以供后续使用。
# 这是一个 Pytest 的 hook 函数,用于修改测试用例集合。
def pytest_collection_modifyitems(items):
for item in items:
# 将测试用例名称从 Unicode 编码转换为原始字符。
item.name = item.name.encode("utf-8").decode("unicode_escape")
# 将测试用例的 nodeid 从 Unicode 编码转换为原始字符,nodeid 是在测试用例运行时将其与测试用例的名称和参数等信息进行组合而得到的唯一标识符。
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
# 这两行代码使用 Python 中的字符串编码和解码函数 encode() 和 decode(),将 item 对象中的名称和节点 ID 转换为中文,以便于控制台的显示。
# 这里指定要运行的测试用例的名称。
appoint_items = ["test_Register", "test_LOGIN"]
# 定义一个空列表来接收筛选出来的测试用例。
run_items = []
# 对于要运行的每个测试用例名称,遍历所有测试用例。
for i in appoint_items:
for item in items:
# 获取测试用例名称中的模块名称部分,这个部分是测试用例名称中的第一个 "[]" 内的内容,用于唯一标识所属模块。
module_item = item.name.split("[")[0]
# 如果当前测试用例的模块名称与要运行的测试用例名称一致,则将其添加到 run_items 列表中。
if i == module_item:
run_items.append(item)
# 遍历要运行的测试用例列表,以及所有测试用例的列表,获取当前测试用例在两个列表中的索引值。
for i in run_items:
run_index = run_items.index(i)
items_index = items.index(i)
# 如果当前测试用例不在要运行的测试用例列表的最前面,就将它调整到最前面位置。首先从 items 中找到当前测试用例应该在的位置(即:run_index),然后使用 python 的交换变量值的语法将当前测试用例的位置与 run_index 位置的测试用例交换,从而达到把当前测试用例放到最前面的目的。
if run_index != items_index:
n_data = items[run_index]
run_index = items.index(n_data)
items[items_index], items[run_index] = items[run_index], items[items_index]
# 总之,这段代码主要是解决pytest测试用例的名称显示和测试用例的执行顺序问题,从而为自动化测试提供更好的支持。
# 定义了一个Pytest的测试用例配置函数,用于对测试用例进行标记和配置相关信息。
def pytest_configure(config):
# 这段代码中使用了 config.addinivalue_line() 方法,来向 pytest 的配置文件添加标记。它的第一个参数是一个字符串 "markers",表示添加标记。第二个参数是添加的标记名称,这里我们添加了两个标记,分别为 "smoke" 和 "回归测试"。
添加标记后,在写测试用例时,就可以使用 @pytest.mark.<marker_name> 的方式对测试用例进行标记。例如,可以使用 @pytest.mark.smoke 标记专注于快速测试且需要经常运行的测试用例,以便在快速运行中先执行。然后,我们可以运行 pytest -m smoke 命令,只运行带有 @pytest.mark.smoke 标记的测试用例。
同样,我们可以使用 @pytest.mark.回归测试 标记需要从以前版本迁移或重构的测试用例。然后,我们可以运行 pytest -m 回归测试 命令,只运行带有 @pytest.mark.回归测试 标记的测试用例。这使得我们可以轻松地在测试套件中分出不同的测试类别,从而更好地管理测试用例。
config.addinivalue_line("markers", 'smoke')
config.addinivalue_line("markers", '回归测试')
@pytest.fixture(scope="function", autouse=True)
# 自定义函数case_skip,它接受一个参数 in_data,表示输入的测试用例对象。
def case_skip(in_data):
# 这里的意思是将输入参数 in_data 转换为一个 TestCase 类对象,并将其赋值给 in_data 变量。该类对象用于存储测试用例的相关信息,例如 URL、请求方式、请求头、请求数据、依赖数据和预期数据等信息。
in_data = TestCase(**in_data)
# 这行代码用于判断测试用例是否需要跳过。in_data.is_run 表示测试用例是否被标记为执行,这个标记通常是用于控制测试用例的执行。如果该标记为 False,则说明该测试用例被标记为跳过,因此函数会调用 pytest 的 skip() 方法来跳过该测试用例的执行。
if ast.literal_eval(cache_regular(str(in_data.is_run))) is False:
# 这行代码用于添加更详细的测试用例名称。allure.dynamic.title() 方法可以用于添加 Allure 报告的测试用例名称,并支持一些动态的参数,例如本例中的 in_data.detail,该参数代表测试用例的详细描述信息。这样,可以在 Allure 报告中看到更详细的测试用例的名称。
allure.dynamic.title(in_data.detail)
# 这几行代码使用 Allure Test Report 库的 allure_step() 和 allure_step_no() 方法,用于添加更详细的测试用例的报告信息。例如,该函数调用了多次 allure_step_no() 方法,用于展示测试用例中的操作步骤,并且将测试用例的请求 URL 和请求方式作为展示的参数。此外,该函数还将测试用例的请求头、请求数据、依赖数据和预期数据等信息,通过调用 allure_step() 方法添加到了 Allure 报告中。
allure_step_no(f"请求URL: {in_data.is_run}")
allure_step_no(f"请求方式: {in_data.method}")
allure_step("请求头: ", in_data.headers)
allure_step("请求数据: ", in_data.data)
allure_step("依赖数据: ", in_data.dependence_case_data)
allure_step("预期数据: ", in_data.assert_data)
# 这行代码用于调用 pytest 的 skip() 方法,来跳过该测试用例的执行。如果测试用例被标记为跳过,则会直接执行该行代码,并跳过该测试用例的执行。
pytest.skip()
# 总的来说,这个函数的作用是用于处理 pytest 测试套件中的跳过用例,并添加更详细的测试用例名称和报告信息。其中,函数调用了 Allure Test Report 库的方法,使得测试用例结果更加详尽、易读和易于维护。
# 定义了一个Pytest的测试用例收尾函数,用于生成测试报告并收集测试结果。
def pytest_terminal_summary(terminalreporter):
# 这几行代码用于统计测试结果的各项指标。其中,terminalreporter.stats 属性是一个字典对象,存储了测试用例的各项状态,例如 'passed'、'failed'、'error'、'skipped' 等,这些属性的值是一个列表,其中每个元素都表示一个测试用例对象。这里的代码使用列表解析式和 len() 函数来计算各个状态的测试用例数。另外,_TOTAL 变量表示测试套件中全部测试用例的数量,_TIMES 记录了测试用例的执行时长。
_PASSED = len([i for i in terminalreporter.stats.get('passed', []) if i.when != 'teardown'])
_ERROR = len([i for i in terminalreporter.stats.get('error', []) if i.when != 'teardown'])
_FAILED = len([i for i in terminalreporter.stats.get('failed', []) if i.when != 'teardown'])
_SKIPPED = len([i for i in terminalreporter.stats.get('skipped', []) if i.when != 'teardown'])
_TOTAL = terminalreporter._numcollected
_TIMES = time.time() - terminalreporter._sessionstarttime
# 这里的代码使用日志记录了测试结果的统计信息。其中,INFO.logger.error() 方法用于记录用例总数和异常用例数,ERROR.logger.error() 方法用于记录失败用例数,WARNING.logger.warning() 方法用于记录跳过用例数,INFO.logger.info() 方法用于记录用例执行时长。
INFO.logger.error(f"用例总数: {_TOTAL}")
INFO.logger.error(f"异常用例数: {_ERROR}")
ERROR.logger.error(f"失败用例数: {_FAILED}")
WARNING.logger.warning(f"跳过用例数: {_SKIPPED}")
INFO.logger.info("用例执行时长: %.2f" % _TIMES + " s")
# 这里的代码是为了计算测试用例的成功率,并且将其记录到日志中。如果测试用例总数为 0,会触发 ZeroDivisionError 异常,此时依然需要将成功率记录为 0。
try:
_RATE = _PASSED / _TOTAL * 100
INFO.logger.info("用例成功率: %.2f" % _RATE + " %")
except ZeroDivisionError:
INFO.logger.info("用例成功率: 0.00 %")
# 总的来说,这段代码的作用是在 pytest 测试运行结束后,统计各个状态的测试用例数和用例成功率,然后将这些信息记录到日志中,方便开发人员查看和分析测试结果。
utils # 工具类
assertion # 测试断言模块
assert_control.py # 断言
详细讲解
"""
断言类型封装,支持json响应断言、数据库断言
"""
import ast
import json
from typing import Text, Any
from jsonpath import jsonpath
from utils.other_tools.models import AssertMethod
from utils.logging_tool.log_control import WARNING
from utils.read_files_tools.regular_control import cache_regular
from utils.other_tools.models import load_module_functions
from utils.assertion import assert_type
from utils.other_tools.exceptions import AssertTypeError
from utils import config
# 一个名为 AssertUtil 的类,用于封装测试用例中的断言操作。
class AssertUtil:
# 这是 AssertUtil 类的构造方法,用于初始化该类的各种属性。
def __init__(self, assert_data, sql_data, request_data, response_data, status_code):
"""
:param response_data:请求的响应数据。
:param request_data:请求的请求数据。
:param sql_data:SQL 语句执行的结果。
:param assert_data:测试用例中的断言部分数据。
:param sql_switch:MySQL 数据库的开关,默认从配置文件中获取。
:param status_code:请求的响应状态码。
"""
# 将传入的参数分别作为对象属性进行了初始化,并从配置文件中获取了 MySQL 数据库的开关状态。
self.response_data = response_data
self.request_data = request_data
self.sql_data = sql_data
self.assert_data = assert_data
self.sql_switch = config.mysql_db.switch
self.status_code = status_code
# @staticmethod 是 Python 中的一个装饰器,用于将一个方法定义为静态方法。在 Python 中,静态方法是属于类的,而不是属于实例的。因此在静态方法中,不能使用 self 关键字来访问实例属性和方法,而是要使用类属性和方法。
@staticmethod
# 定义了一个名为literal_eval()的静态方法。这个方法接收一个参数attr,对该参数执行了cache_regular(str(attr))方法后,再使用Python内置的ast模块的literal_eval()方法对其进行转换,并返回转换后的结果。
def literal_eval(attr):
# ast.literal_eval()方法帮助我们将一个字符串表达式解析为Python数据类型,比如将字符串'["a", 1, {"key": "value"}]'解析为List类型["a", 1, {"key": "value"}]。在cache_regular()方法中,它的主要功能是在字符串中寻找形如$cache{xxx}的字符串,并从缓存中获取与xxx相关的数据,再进行替换。这样在literal_eval()方法中,我们传递给它的是一个字符串,我们需要对这个字符串中嵌入的缓存变量进行处理后再进行转换。
return ast.literal_eval(cache_regular(str(attr)))
# 总之,这段代码提供了一种从缓存中获取数据并将其与外部程序进行交互的机制,并对字符串表达式进行操作和转换。这对于处理数据表达式和进行数据序列化非常有用。
# @property是一个Python内置的装饰器,用于将一个方法转换为属性。当我们将@property应用于一个类的方法时,它会将该方法转换为只读属性,这意味着我们可以像访问属性一样使用该方法,而不是函数。
@property
# 定义了一个名为get_assert_data()的属性方法,该方法返回实例的assert_data属性,并调用cache_regular()方法将assert_data属性中包含的缓存字符串转换成实际数据类型后返回。
def get_assert_data(self):
# 该代码段使用Python中的assert语句检查self.assert_data是否为None。如果self.assert_data为None,则会触发一条异常,该异常描述了所在类及其缺失的属性。代码中使用%运算符连接字符串,%s表示需要被替换的格式化字符串。由于self.__class__.__name__表示当前实例所属的类名,因此,当检查失败时,错误消息将会包含所属类的名称。
assert self.assert_data is not None, (
"'%s' should either include a `assert_data` attribute, "
% self.__class__.__name__
)
# 该代码行通过调用ast.literal_eval()方法将cache_regular()方法解析后的字符串转换为Python字典或列表对象,并将其作为属性方法的返回值返回。
return ast.literal_eval(cache_regular(str(self.assert_data)))
@property
# 定义了一个名为get_type()的属性方法,该方法返回实例的assert_data字典中的type属性对应的枚举值
def get_type(self):
# 该代码段使用Python中的assert语句检查assert_data字典中是否包含type属性。如果不包含,则会触发一条异常,该异常描述了所缺少的属性,并包含assert_data字典作为错误消息。
assert 'type' in self.get_assert_data.keys(), (
" 断言数据: '%s' 中缺少 `type` 属性 " % self.get_assert_data
)
# 该代码行使用self.get_assert_data.get("type")来获取assert_data字典中的type属性对应的值,并传递给AssertMethod枚举类来获取枚举值。返回值name为枚举值的名称。
name = AssertMethod(self.get_assert_data.get("type")).name
# 返回枚举值的名称
return name
@property
# 定义了一个名为get_value()的属性方法,该方法返回实例的assert_data字典中的value属性对应的值。
def get_value(self):
# 该代码段使用Python中的assert语句检查assert_data字典中是否包含value属性。如果不包含,则会触发一条异常,该异常描述了所缺少的属性,并包含assert_data字典作为错误消息。
assert 'value' in self.get_assert_data.keys(), (
" 断言数据: '%s' 中缺少 `value` 属性 " % self.get_assert_data
)
# 该代码行使用self.get_assert_data.get("value")来获取assert_data字典中的value属性对应的值,并将其作为该属性方法的返回值返回。
return self.get_assert_data.get("value")
@property
# 定义了一个名为get_jsonpath()的属性方法,该方法返回实例的assert_data字典中的jsonpath属性对应的值。
def get_jsonpath(self):
# 该代码段使用Python中的assert语句检查assert_data字典中是否包含jsonpath属性。如果不包含,则会触发一条异常,该异常描述了所缺少的属性,并包含assert_data字典作为错误消息。
assert 'jsonpath' in self.get_assert_data.keys(), (
" 断言数据: '%s' 中缺少 `jsonpath` 属性 " % self.get_assert_data
)
# 该代码行使用self.get_assert_data.get("jsonpath")来获取assert_data字典中的jsonpath属性对应的值,并将其作为该属性方法的返回值返回。
return self.get_assert_data.get("jsonpath")
@property
# 定义了一个名为get_assert_type()的属性方法,该方法返回实例的assert_data字典中的AssertType属性对应的值。
def get_assert_type(self):
# 该代码段使用Python中的assert语句检查assert_data字典中是否包含AssertType属性。如果不包含,则会触发一条异常,该异常描述了所缺少的属性,并包含assert_data字典作为错误消息。
assert 'AssertType' in self.get_assert_data.keys(), (
" 断言数据: '%s' 中缺少 `AssertType` 属性 " % self.get_assert_data
)
# 该代码行使用self.get_assert_data.get("AssertType")来获取assert_data字典中的AssertType属性对应的值,并将其作为该属性方法的返回值返回。
return self.get_assert_data.get("AssertType")
@property
# 定义了一个名为get_message()的属性方法,该方法返回实例的assert_data字典中的message属性对应的值。如果message属性不存在,则返回None。
def get_message(self):
"""
获取断言描述,如果未填写,则返回 `None`
:return:
"""
# 该代码行使用self.get_assert_data.get("message", None)来获取assert_data字典中的message属性对应的值。如果message属性不存在,get()方法会返回None,作为该属性方法的返回值返回。
return self.get_assert_data.get("message", None)
@property
# 定义了一个名为get_sql_data()的属性方法。该方法的作用是从实例的sql_data中提取数据,如果需要,将字节类型转换为字符串类型,并返回提取的数据。方法中还包含一些判断和异常的处理。
def get_sql_data(self):
# 如果sql_switch_handle为True,且sql_data为空,则会触发一条异常,该异常说明在需要数据库断言的情况下,未填写要查询的SQL语句。判断数据库开关为开启,并需要数据库断言的情况下,未编写sql,则抛异常。
if self.sql_switch_handle:
assert self.sql_data != {'sql': None}, (
"请在用例中添加您要查询的SQL语句。"
)
# 如果sql_data是字节类型,则使用decode()方法将其转换为字符串类型并返回。处理 mysql查询出来的数据类型如果是bytes类型,转换成str类型
if isinstance(self.sql_data, bytes):
return self.sql_data.decode('utf=8')
# 该代码行使用jsonpath库从sql_data中提取数据,并将结果赋值给sql_data变量。如果提取失败,则会触发一条异常,该异常说明在当前语法下无法提取数据。
sql_data = jsonpath(self.sql_data, self.get_value)
assert sql_data is not False, (
f"数据库断言数据提取失败,提取对象: {self.sql_data} , 当前语法: {self.get_value}"
)
# 如果sql_data包含多个值,则返回所有值;否则,只返回第一个值。
if len(sql_data) > 1:
return sql_data
return sql_data[0]
@staticmethod
# 定义了一个名为functions_mapping()的静态方法。该方法调用了load_module_functions()函数并将其结果返回。具体来说,该方法返回了一个名为assert_type模块中所有函数的字典,该字典的键为函数名,值为函数的内存地址。
def functions_mapping():
# 该代码行调用load_module_functions()函数,并将返回的字典作为该方法的返回值。该字典中包含了assert_type模块中所有函数的名称和内存地址。
return load_module_functions(assert_type)
@property
# 定义了get_response_data方法,它有一个self参数。self表示实例本身,在这里,它的作用是让方法可以访问对象的其他属性和方法。
def get_response_data(self):
# 我们使用json.loads这个函数将response_data这个字符串转换为Python对象。
return json.loads(self.response_data)
@property
# 定义了sql_switch_handle方法。该方法的作用是用于处理数据库开关的状态,并判断是否要打印断言数据。
def sql_switch_handle(self):
"""
判断数据库开关,如果未开启,则打印断言部分的数据
:return:
"""
# 这里使用了一个条件语句,如果self.sql_switch属性的值为False,则说明数据库开关未开启。此时会打印一条警告日志(利用日志框架WARNING.logger.warning)并给出相应的提示信息,提示信息中包括了%s占位符,它会在日志中动态地显示当前测试案例的断言数据值。该断言数据的值由self.get_assert_data属性返回。
if self.sql_switch is False:
WARNING.logger.warning(
"检测到数据库状态为关闭状态,程序已为您跳过此断言,断言值:%s" % self.get_assert_data
)
# 最后返回self.sql_switch属性的值。如果它的值是True,则意味着数据库开关处于开启状态。对于这种情况,sql_switch_handle方法没有其他作用,只是作为属性在代码中被访问。如果它的值是False,则说明数据库开关被关闭,那么我们就要根据该情况,进行相应的处理(即打印警告消息)。
return self.sql_switch
# 定义了一个名为_assert的方法,它有三个参数:check_value,expect_value和message。这个方法的作用是进行断言操作。check_value参数是我们要检查的值,expect_value参数是我们期待的值,而message参数则是一个可选的字符串,用来存放错误信息。
def _assert(self, check_value: Any, expect_value: Any, message: Text = ""):
# 先通过self.functions_mapping()方法得到一个字典,这个字典存储了不同类型的断言函数。self.functions_mapping()的定义可以在之前提到过的assert_type.py模块中找到。然后使用self.get_type属性来确定要使用哪个断言函数。get_type属性是在调用Parser对象的parse方法后赋值的。最后传递check_value、expect_value和message这三个参数,调用相应的断言函数进行断言检查。如果检查失败,我们就会使用message参数中的错误信息进行提示。
self.functions_mapping()[self.get_type](check_value, expect_value, str(message))
@property
# 定义了一个名为_assert_resp_data的属性装饰器,表示这是一个只读属性。这个属性的作用是从响应数据中提取出指定路径(jsonpath),返回提取的结果。
def _assert_resp_data(self):
# 首先,我们使用jsonpath模块的jsonpath函数,传入响应数据和jsonpath路径,提取出对应路径的数据。
resp_data = jsonpath(self.get_response_data, self.get_jsonpath)
# 进行断言检查,确保提取的数据不为False。如果断言失败,会抛出一个错误,提示提取失败。
assert resp_data is not False, (
f"jsonpath数据提取失败,提取对象: {self.get_response_data} , 当前语法: {self.get_jsonpath}"
)
# 如果提取到的数据有多个值,我们返回一个列表,否则直接返回这个值。
if len(resp_data) > 1:
return resp_data
return resp_data[0]
@property
def _assert_request_data(self):
# 在这里,self.request_data是发送HTTP请求时的参数(payload)。jsonpath接受两个参数,第一个参数是待检索的元素,第二个参数是用来检索数据的语法。jsonpath函数返回满足语法的所有值列表。在这里,req_data是一个列表或空列表。
req_data = jsonpath(self.request_data, self.get_jsonpath)
# 这段代码确保了我们从请求参数中成功提取到了指定字段的值。如果提取失败,则抛出异常,其中包含错误信息。
assert req_data is not False, (
f"jsonpath数据提取失败,提取对象: {self.request_data} , 当前语法: {self.get_jsonpath}"
)
# 这里根据请求参数提取结果的情况,返回对应的值或值列表。如果提取的是单值,则直接返回该值。如果提取的是多个值,则返回所有值的列表。
if len(req_data) > 1:
return req_data
return req_data[0]
# 定义一个实例方法 assert_type_handle,该方法用来根据不同的断言类型调用对应的断言方法。
def assert_type_handle(self):
# 如果断言类型是 R_SQL,则调用 _assert_request_data 方法获取请求参数中的字段值,调用 get_sql_data 获取期望的值,然后通过 _assert 方法进行断言校验。
if self.get_assert_type == "R_SQL":
self._assert(self._assert_request_data, self.get_sql_data, self.get_message)
# 如果断言类型是 SQL 或 D_SQL,则调用 _assert_resp_data 方法获取响应参数中的字段值,调用 get_sql_data 获取期望的值,然后通过 _assert 方法进行断言校验。
elif self.get_assert_type == "SQL" or self.get_assert_type == "D_SQL":
self._assert(self._assert_resp_data, self.get_sql_data, self.get_message)
# 如果断言类型为 None,则调用 _assert_resp_data 方法获取响应参数中的字段值,调用 get_value 获取期望的值,然后通过 _assert 方法进行值比较的断言校验。
elif self.get_assert_type is None:
self._assert(self._assert_resp_data, self.get_value, self.get_message)
# 如果断言类型不符合以上三种情况,则抛出一个自定义的异常 AssertTypeError,提醒用户该断言类型不被支持。
else:
raise AssertTypeError("断言失败,目前只支持数据库断言和响应断言")
# 定义了一个名为 Assert 的类,该类继承了 AssertUtil 类,即该类继承了 AssertUtil 类中的所有属性和方法。
class Assert(AssertUtil):
# 定义名为 assert_data_list 的方法。
def assert_data_list(self):
# 初始化一个空列表 assert_list,用于存储每一项测试数据的断言结果。
assert_list = []
# 遍历 assert_data 字典中的键值对,assert_data 是 AssertUtil 类中的一个数据成员,存储了当前测试用例所需要验证的数据。
for k, v in self.assert_data.items():
# 根据键 k 是不是 "status_code" 来判断当前项是不是用于验证响应状态码。
if k == "status_code":
# 如果当前项用于验证响应状态码,那么使用断言方法 assert 判断 self.status_code 是否等于 v,如果不等于,则抛出异常信息 "响应状态码断言失败"。
assert self.status_code == v, "响应状态码断言失败"
# 如果当前项不是用于验证响应状态码,那么将其对应的值 v 添加到 assert_list 中。
else:
assert_list.append(v)
# 遍历结束后返回 assert_list 列表,其中包含了每一项测试数据所对应的断言结果。
return assert_list
# 定义了名为 assert_type_handle 的方法。
def assert_type_handle(self):
# 使用 for 循环遍历 self.assert_data_list() 方法返回的每一项测试数据的断言结果,并将其赋值给变量 i。
for i in self.assert_data_list():
# 将变量 i 赋值给 self.assert_data 成员变量,这样的话,在后面的方法中就能使用 self.assert_data 来引用当前遍历到的测试数据了。
self.assert_data = i
使用 super() 调用继承自 AssertUtil 类的 assert_type_handle 方法,该方法的作用是根据当前测试数据的类型,进行对应的验证。这里使用 super() 目的是将具体的实现交给父类去处理,而当前方法只负责调用,以达到代码的重用性。
super().assert_type_handle()
# 这个类提供了一种便利的方式来进行多个断言的校验,只需要传入一个断言数据字典,该类就会按照断言类型和断言数值进行校验,并抛出校验失败的异常信息。
assert_type.py # 断言类型
详细讲解
"""
Assert 断言类型
"""
from typing import Any, Union, Text
from collections import *
# 定义了名为 equals 的函数,使用 Any 类型注解表示该函数的参数类型可以是任意类型。具体来说,check_value 和 expect_value 参数表示要比较的两个值,message 参数为可选参数,用于在断言失败时输出自定义的错误信息。
def equals(
check_value: Any, expect_value: Any, message: Text = ""
):
"""判断是否相等"""
# 使用 Python 自带的 assert 语句进行比较,如果 check_value 等于 expect_value,则不做处理;如果不等,则抛出 AssertionError 异常,其中的错误消息为 message。
assert check_value == expect_value, message
# 定义了一个名为 less_than 的函数,该函数有三个参数:check_value 表示要检查的实际值,必须为 int 或 float 类型;expect_value 表示预期结果,也必须为 int 或 float 类型。这两个参数都使用了类型注解,用于指定参数的类型,从而提高代码的可读性和可理解性。第三个参数 message 是可选参数,可以用来在断言失败时输出自定义的错误信息。这个函数的功能是判断实际结果是否小于预期结果。
def less_than(
check_value: Union[int, float], expect_value: Union[int, float], message: Text = ""
):
"""判断实际结果小于预期结果"""
# 使用 assert 语句对实际值和预期值进行比较。如果实际结果小于预期结果,则 assert 语句不做任何事情,程序会继续执行;否则,assert 语句抛出一个 AssertionError 异常,其中的错误消息是参数 message。在测试代码中,如果出现了异常,测试框架会记录该测试用例失败。这种方式可以方便地验证代码是否按照预期执行。
assert check_value < expect_value, message
def less_than_or_equals(
check_value: Union[int, float], expect_value: Union[int, float], message: Text = ""):
"""判断实际结果小于等于预期结果"""
assert check_value <= expect_value, message
def greater_than(
check_value: Union[int, float], expect_value: Union[int, float], message: Text = ""
):
"""判断实际结果大于预期结果"""
assert check_value > expect_value, message
def greater_than_or_equals(
check_value: Union[int, float], expect_value: Union[int, float], message: Text = ""
):
"""判断实际结果大于等于预期结果"""
assert check_value >= expect_value, message
def not_equals(
check_value: Any, expect_value: Any, message: Text = ""
):
"""判断实际结果不等于预期结果"""
assert check_value != expect_value, message
def string_equals(
check_value: Text, expect_value: Any, message: Text = ""
):
"""判断字符串是否相等"""
assert check_value == expect_value, message
# 定义了一个名为 length_equals 的函数,该函数有三个参数:check_value 表示要检查的值,必须为字符串类型;expect_value 表示期望长度,必须是整数类型。第三个参数 message 是可选参数,用于在断言失败时输出自定义的错误信息。该函数的功能是判断输入字符串的长度是否等于期望长度。
def length_equals(
check_value: Text, expect_value: int, message: Text = ""
):
"""判断长度是否相等"""
# 用于检查传入的 expect_value 是否是 int 类型。如果不是,则抛出一个异常,告诉我该值需要是整数类型。
assert isinstance(
expect_value, int
), "expect_value 需要为 int 类型"
# 用于比较输入字符串的长度是否等于期望长度。如果两个长度相等,则这个 assert 语句不会做任何事情,程序会继续执行。否则,assert 语句会抛出一个 AssertionError 异常,并且错误信息为参数 message。在测试代码中,如果出现异常,测试框架将记录该测试用例失败。
assert len(check_value) == expect_value, message
def length_greater_than(
check_value: Text, expect_value: Union[int, float], message: Text = ""
):
"""判断长度大于"""
assert isinstance(
expect_value, (float, int)
), "expect_value 需要为 float/int 类型"
assert len(str(check_value)) > expect_value, message
def length_greater_than_or_equals(
check_value: Text, expect_value: Union[int, float], message: Text = ""
):
"""判断长度大于等于"""
assert isinstance(
expect_value, (int, float)
), "expect_value 需要为 float/int 类型"
assert len(check_value) >= expect_value, message
def length_less_than(
check_value: Text, expect_value: Union[int, float], message: Text = ""
):
"""判断长度小于"""
assert isinstance(
expect_value, (int, float)
), "expect_value 需要为 float/int 类型"
assert len(check_value) < expect_value, message
def length_less_than_or_equals(
check_value: Text, expect_value: Union[int, float], message: Text = ""
):
"""判断长度小于等于"""
assert isinstance(
expect_value, (int, float)
), "expect_value 需要为 float/int 类型"
assert len(check_value) <= expect_value, message
def contains(check_value: Any, expect_value: Any, message: Text = ""):
"""判断期望结果内容包含在实际结果中"""
assert isinstance(
check_value, (list, tuple, dict, str, bytes)
), "expect_value 需要为 list/tuple/dict/str/bytes 类型"
assert expect_value in check_value, message
def contained_by(check_value: Any, expect_value: Any, message: Text = ""):
"""判断实际结果包含在期望结果中"""
assert isinstance(
expect_value, (list, tuple, dict, str, bytes)
), "expect_value 需要为 list/tuple/dict/str/bytes 类型"
assert check_value in expect_value, message
def startswith(
check_value: Any, expect_value: Any, message: Text = ""
):
"""检查响应内容的开头是否和预期结果内容的开头相等"""
assert str(check_value).startswith(str(expect_value)), message
def endswith(
check_value: Any, expect_value: Any, message: Text = ""
):
"""检查响应内容的结尾是否和预期结果内容相等"""
assert str(check_value).endswith(str(expect_value)), message
def setlist(
check_value: Any, expect_value: Any, message: Text = ""
):
"""检查去重后的响应内容是否和预期结果内容相等"""
assert check_value == expect_value, message
def str_set(
check_value: Any, expect_value: Any, message: Text = ""
):
"""list转换str 去重无序判断是否相等"""
list_check_value = str(check_value)
list_expect_value = str(expect_value)
assert set(list_check_value) == set(list_expect_value), message
def counter(
check_value: Any, expect_value: Any, message: Text = ""
):
"""O(n):Counter()方法是最好的(如果你的对象是可散列的)"""
list_check_value = str(check_value)
list_expect_value = str(expect_value)
assert Counter(list_check_value) == Counter(list_expect_value), message
这段代码定义了多个断言类型的实现函数,比如 `equals` 函数用于判断两个值是否相等,`less_than` 函数用于判断实际结果是否小于预期结果,等等。这些函数将会在 `AssertUtil` 类的 `_assert` 方法中进行调用,用于完成对应的断言操作。
这些函数的参数和返回值分别如下:
- 参数 `check_value`:需要进行断言检查的值;
- 参数 `expect_value`:期望的值;
- 参数 `message`(可选):当断言检查失败时,返回的自定义错误信息;
- 返回值:当断言检查失败时,会抛出 `AssertionError` 异常。
这些函数的实现方式非常简单,只需要调用 Python 中的 `assert` 语句即可。例如 `equals` 函数的实现如下:
```
def equals(
check_value: Any, expect_value: Any, message: Text = ""
):
"""判断是否相等"""
assert check_value == expect_value, message
```
这个函数的作用是判断 `check_value` 是否等于 `expect_value`,如果不相等,抛出断言错误,并输出自定义错误信息 `message`(如果提供了的话)。
cache_process # 缓存处理模块 cache_control.py # 缓存文件处理
详细讲解
"""
缓存文件处理
"""
import os
from typing import Any, Text, Union
from common.setting import ensure_path_sep
from utils.other_tools.exceptions import ValueNotFoundError
# 定义了 Cache 类,用于读写缓存文件。
class Cache:
""" 设置、读取缓存 """
# 类的初始化函数 __init__(self, filename: Union[Text, None]) -> None。__init__ 函数在类实例化时被调用,self 参数指向实例化的对象。filename 是一个可选参数,用于指定缓存文件的名称。函数定义中,Union[Text, None] 表示 filename 可以为字符串或者 None。
def __init__(self, filename: Union[Text, None]) -> None:
# 如果filename不为空,则操作指定文件内容
if filename:
self.path = ensure_path_sep("\\cache" + filename)
# 如果filename为None,则操作所有文件内容
else:
self.path = ensure_path_sep("\\cache")
# 定义了一个名为 set_cache 的函数,它是一个类的方法,所以第一个参数 self 代表类的实例。该函数有两个参数:key 和 value,分别表示键和值,它们将被存在缓存中。指定的数据类型和值是用于提供多个键值对的支持,给缓存系统添加更多的值。这些键值对可以被序列化,即转换成字符串形式,并被写入到缓存文件系统中。函数的返回类型是 None,这意味着该函数不返回任何值。这是因为该函数的作用是设置缓存并将其写入到文件中,而不是返回数据。
def set_cache(self, key: Text, value: Any) -> None:
# 使用open()函数打开指定路径的缓存文件,并以“写入”模式('w')打开文件。接着,将要写入的键值对转换成一个字典类型,并使用str()函数将其转换成一个字符串。最后,使用write()函数将转换后的字符串写入打开的文件中。这个方法仅适用于设置单个键值对的字典类型缓存数据。如果缓存文件之前已经存在,则会被新缓存内容替换。
with open(self.path, 'w', encoding='utf-8') as file:
file.write(str({key: value}))
# 定义了一个名为set_caches()的方法,它接受一个任意类型的参数value,并且没有返回值。该方法的作用是将参数value保存到缓存文件中。
def set_caches(self, value: Any) -> None:
"""
设置多组缓存数据
:param value: 缓存内容
:return:
"""
# 这行代码使用with语句以写入模式('w')打开指定路径的缓存文件,并将文件对象赋值给变量file。这将会清空文件并写入新的数据。
with open(self.path, 'w', encoding='utf-8') as file:
# 这行代码将参数value转换成字符串并写入到缓存文件中。注意,这个方法并没有做任何格式化或序列化数据的操作,因此需要在调用该方法的地方确保传入的数据是可以被转换成字符串的。
file.write(str(value))
# 定义了一个名为get_cache()的方法,它没有任何参数,且返回一个任意类型的对象。
def get_cache(self) -> Any:
"""
获取缓存数据
:return:
"""
# 这行代码使用with语句以只读模式('r')打开指定路径的缓存文件,并将文件对象赋值给变量file。with语句会自动关闭文件,并确保在文件操作出现异常时做出正确的清理操作。
try:
with open(self.path, 'r', encoding='utf-8') as file:
# 这行代码读取打开的文件中的所有内容,并将其作为一个字符串返回。如果文件为空,则会返回一个空字符串。
return file.read()
# 这行代码表示当try块中的代码抛出FileNotFoundError异常时,跳过这个异常,并继续执行下去。这样做是为了确保程序不会因为缓存文件不存在而崩溃。
except FileNotFoundError:
pass
# 定义了一个名为clean_cache()的方法,它没有接受参数,也没有返回值。该方法的作用是删除指定的缓存文件。
def clean_cache(self) -> None:
"""删除所有缓存文件"""
# 这行代码使用os.path模块中的exists()函数检查指定路径的文件或目录是否存在。如果文件不存在,就会抛出FileNotFoundError异常,提示用户该文件不存在。
if not os.path.exists(self.path):
raise FileNotFoundError(f"您要删除的缓存文件不存在 {self.path}")
# 这行代码使用os模块中的remove()函数删除指定文件。在这里,我们使用self.path属性指定要删除的缓存文件路径。
os.remove(self.path)
# @classmethod是一个装饰器,它用于定义一个类方法。类方法属于类本身而非类的实例,因此可以在不创建类实例的情况下调用它们。类方法的第一个参数始终是类本身,通常被命名为cls。通过cls参数,我们可以访问和修改类属性,或者调用其他类方法。如果没有@classmethod装饰器,那么定义的方法将是实例方法,只能由实例调用。
@classmethod
# 定义了一个名为clean_all_cache()的方法,该方法没有接收参数,也没有返回值。该方法的作用是清除目标目录下所有的缓存文件。
def clean_all_cache(cls) -> None:
"""
清除所有缓存文件
:return:
"""
# 这行代码调用了之前定义的辅助函数ensure_path_sep(),用于确保缓存目录路径以目录分隔符结尾,避免后续拼接路径时出现错误。
cache_path = ensure_path_sep("\\cache")
# 这行代码使用os模块中的listdir()函数获取指定目录下的文件列表,并将其存储在list_dir变量中。
list_dir = os.listdir(cache_path)
# 这个循环遍历所有文件,并使用os模块中的remove()函数将每个文件从磁盘上删除。在这里,我们使用cache_path指定缓存文件的路径。每个文件的名称由listdir()函数返回的列表中的元素提供。
for i in list_dir:
os.remove(cache_path + i)
# 定义了一个空字典_cache_config,用于存储缓存数据。在该变量中,缓存数据以键值对的形式存储,其中键是缓存名称,值是任何Python对象,表示缓存数据。
_cache_config = {}
# 定义了一个名为CacheHandler的类。
class CacheHandler:
@staticmethod
# 这个get_cache()静态方法接收一个参数cache_data,该参数是缓存名称。该方法从_cache_config中获取指定缓存数据,并返回它。如果缓存数据不存在,则会引发ValueNotFoundError异常,提示缓存数据未找到。
def get_cache(cache_data):
try:
return _cache_config[cache_data]
except KeyError:
raise ValueNotFoundError(f"{cache_data}的缓存数据未找到,请检查是否将该数据存入缓存中")
@staticmethod
# 这个update_cache()静态方法接收两个参数,cache_name和value。它将value添加或更新到_cache_config字典中指定cache_name的键。
def update_cache(*, cache_name, value):
_cache_config[cache_name] = value
redis_control.py # redis缓存操作封装
详细讲解
"""
redis 缓存操作封装
"""
from typing import Text, Any
import redis
# 定义了一个名为 RedisHandler 的类。这个类用于封装redis缓存的读取,方便其他地方进行调用。__init__ 方法是一个特殊的方法,在创建类的实例时被调用。
class RedisHandler:
""" redis 缓存读取封装 """
def __init__(self):
# 初始化了五个属性,分别是 host、port、database、password、charset。在本例中,这些属性存储了 Redis 的连接信息,包括主机名或 IP 地址、端口号、数据库编号、密码和字符集等。
self.host = '127.0.0.0'
self.port = 6000
self.database = 0
self.password = 123456
self.charset = 'UTF-8'
# 创建了与 Redis 服务器的连接。这里使用了 redis.Redis 类,它是 Redis 的官方 Python 客户端之一,提供了与 Redis 进行通信的接口。在这里,我们把 Redis 的连接信息作为参数传给 redis.Redis(),然后创建一个 Redis 连接实例,保存在 RedisHandler 对象的 redis 属性中。其中,decode_responses=True 的作用是将 Redis 匹配的值自动转换为 Python 字符串,避免了手动编码/解码的繁琐过程。
self.redis = redis.Redis(
self.host,
port=self.port,
password=self.password,
decode_responses=True,
db=self.database
)
# 函数set_string,用来将一个字符串存储到 Redis 缓存中。它有 6 个参数,其中第一个参数 name 是必需的,表示要写入缓存的名称。第二个参数 value 是必需的,表示要写入缓存的值。第三个参数 exp_time 是可选的,表示设置缓存的过期时间(以秒为单位)。第四个参数 exp_milliseconds 是可选的,表示设置缓存的过期时间(以毫秒为单位)。第五个参数 name_not_exist 是可选的,如果设置为 True,则仅在缓存中没有该名称时才执行写入操作。第六个参数 name_exit 是可选的,如果设置为 True,则仅在缓存中存在该名称时才执行写入操作。
def set_string(
self, name: Text,
value, exp_time=None,
exp_milliseconds=None,
name_not_exist=False,
name_exit=False) -> None:
"""
缓存中写入 str(单个)
:param name: 缓存名称
:param value: 缓存值
:param exp_time: 过期时间(秒)
:param exp_milliseconds: 过期时间(毫秒)
:param name_not_exist: 如果设置为True,则只有name不存在时,当前set操作才执行(新增)
:param name_exit: 如果设置为True,则只有name存在时,当前set操作才执行(修改)
:return:
"""
# 使用 redis.set() 方法来写入字符串到 Redis 缓存中。redis 是 RedisHandler 类的一个属性,它保存了连接到 Redis 的客户端实例。在这里,我们为 redis.set() 方法传递了 name 和 value 参数。ex 参数表示设置缓存的过期时间(以秒为单位),px 参数表示设置缓存的过期时间(以毫秒为单位),nx 参数表示只有在缓存中没有该名称时才执行写入操作,xx 参数表示仅在缓存中存在该名称时才执行写入操作。
self.redis.set(
name,
value,
ex=exp_time,
px=exp_milliseconds,
nx=name_not_exist,
xx=name_exit
)
# 函数key_exit,用于判断 Redis 缓存中的一个键是否存在。它只有一个参数 key,表示要检查的键名称。
def key_exit(self, key: Text):
"""
判断redis中的key是否存在
:param key:
:return:
"""
# 返回布尔值(True 或 False),表示指定的键是否存在于 Redis 缓存中。在这里,我们使用了 self.redis.exists() 方法,它是 Redis 提供的一个方法,用于检查指定的 key 是否存在于 Redis 缓存中。
return self.redis.exists(key)
# 函数incr,用于递增 Redis 缓存中的一个键的值。它只有一个参数 key,表示要递增值的键名称。
def incr(self, key: Text):
"""
使用 incr 方法,处理并发问题
当 key 不存在时,则会先初始为 0, 每次调用,则会 +1
:return:
"""
# 使用 incr() 方法来增加一个 Redis 缓存中的键的值。在这里,我们使用 self.redis.incr() 方法,它是 Redis 提供的一个方法,自动增加指定 key 中的值,如果该 key 不存在,则会先创建并初始化为 0,然后再递增。
self.redis.incr(key)
# 这是一个返回类型注解,以内联注释代码的形式表示返回值类型为 Text。
函数get_key,用于获取 Redis 缓存中指定键名的值。它只有一个参数 name,表示要获取值的键名称。
def get_key(self, name: Any) -> Text:
"""
读取缓存
:param name:
:return:
"""
# 使用 get() 函数来获取 Redis 缓存中指定 name 的值。在这里,我们使用了 self.redis.get() 方法,它是 Redis 提供的一个函数,用于获取指定键名称 name 的值。
return self.redis.get(name)
# 函数set_many,用于批量设置 Redis 缓存中的多个键值对。它支持两种方式来设置缓存,即列表方式和关键字参数方式。使用 *args 和 **kwargs 可以接收这两种方式传入的值。
def set_many(self, *args, **kwargs):
"""
批量设置
支持如下方式批量设置缓存
eg: set_many({'k1': 'v1', 'k2': 'v2'})
set_many(k1="v1", k2="v2")
:return:
"""
# 使用 mset() 方法来批量设置 Redis 缓存中的多个键值对。在这里,我们使用了 self.redis.mset() 方法,它是 Redis 提供的一个方法,用于设置多个键值对。
self.redis.mset(*args, **kwargs)
# 函数get_many,用于获取 Redis 缓存中多个键的值。它只有一个参数 *args,表示要获取值的键名称列表或元组,支持传入多个键。使用 *args 可以接收任意数量的参数。
def get_many(self, *args):
"""获取多个值"""
# 使用 mget() 方法来获取 Redis 缓存中多个键的值,然后返回获取的结果。在这里,我们使用了 self.redis.mget() 方法,它是 Redis 提供的一个方法,用于获取多个键的值。
results = self.redis.mget(*args)
return results
# 函数del_all_cache,用于清除 Redis 缓存中所有的数据。
def del_all_cache(self):
"""清理所有现在的数据"""
# 使用 keys() 方法获取 Redis 缓存中所有的键的列表,然后使用 del_cache() 方法来依次清除每一个键对应的数据。self.redis.keys() 方法返回一个列表,包含了 Redis 缓存中所有的键。
for key in self.redis.keys():
self.del_cache(key)
# 函数del_cache,用于删除 Redis 缓存中指定键的数据。
def del_cache(self, name):
"""
删除缓存
:param name:
:return:
"""
# 使用 delete() 方法来删除 Redis 缓存中指定 name 键的数据。self.redis.delete() 方法是 Redis 提供的一个方法,用于删除指定的键。
self.redis.delete(name)
logging_tool # 日志处理模块
log_control.py # 日志封装,可设置不同等级的日志颜色
详细讲解
"""
日志封装,可设置不同等级的日志颜色
"""
import logging
from logging import handlers
from typing import Text
import colorlog
import time
from common.setting import ensure_path_sep
# 定义了一个名为LogHandler的类,用来封装日志的打印。
class LogHandler:
# 日志级别关系映射
# 这个类属性定义了日志级别关系映射。这个映射是一个字典,将日志级别名称映射到对应的 Python 标准库 logging 中定义的日志级别常量。
level_relations = {
'debug': logging.DEBUG,
'info': logging.INFO,
'warning': logging.WARNING,
'error': logging.ERROR,
'critical': logging.CRITICAL
}
# 这个方法名叫做 __init__,用于初始化 LogHandler 实例。
这个方法定义了四个参数:filename:日志文件名,类型为字符串,用于指定日志文件的名称。level:日志记录的级别,类型为字符串,默认值为 info,表示只记录 info 以上的日志等级。when:日志文件切割时间,类型为字符串,表示日志文件按照什么样的时间长度进行切割,默认值为 D,表示按照天进行切割。fmt:日志输出格式,类型为字符串,表示记录日志时使用的格式化输出字符串。
def __init__(
self,
filename: Text,
level: Text = "info",
when: Text = "D",
fmt: Text = "%(levelname)-8s%(asctime)s%(name)s:%(filename)s:%(lineno)d %(message)s"
):
# 这里调用了logging.getLogger()方法,并使用filename作为参数获得了一个logger对象,用来记录日志。
self.logger = logging.getLogger(filename)
# 这里调用了类中定义的log_color()方法,并将返回的格式对象赋给了formatter变量。
formatter = self.log_color()
# 设置日志格式
format_str = logging.Formatter(fmt)
# 设置日志级别
self.logger.setLevel(self.level_relations.get(level))
# 往屏幕上输出
screen_output = logging.StreamHandler()
# 设置屏幕上显示的格式
screen_output.setFormatter(formatter)
# 往文件里写入#指定间隔时间自动生成文件的处理器。构造函数中的参数 filename 表示日志文件的完整路径,when 表示日志轮转的时间间隔,backupCount 表示日志文件的备份个数(即保留多少个历史日志文件),encoding 表示日志文件的编码方式。
time_rotating = handlers.TimedRotatingFileHandler(
filename=filename,
when=when,
backupCount=3,
encoding='utf-8'
)
# 设置文件里写入的格式
time_rotating.setFormatter(format_str)
# 把对象加到logger里
self.logger.addHandler(screen_output)
self.logger.addHandler(time_rotating)
self.log_path = ensure_path_sep('\\logs\\log.log')
# @classmethod 装饰器用于将一个普通的方法转换为类方法,使其能够访问类属性,而不仅仅是实例属性。在类方法中,我们可以通过 cls 参数来直接访问类属性,而不需要创建类的实例对象。
@classmethod
def log_color(cls):
""" 设置日志颜色 """
# 定义了一个字典 log_colors_config,它包含了五个不同级别的日志消息,以及对应的颜色。
log_colors_config = {
'DEBUG': 'cyan',
'INFO': 'green',
'WARNING': 'yellow',
'ERROR': 'red',
'CRITICAL': 'red',
}
# 创建了一个基于颜色的日志格式化器对象 formatter。该对象的格式与前面提到的方法相同,不同之处仅在于我们将其定义为一个类方法,而非函数。
formatter = colorlog.ColoredFormatter(
'%(log_color)s[%(asctime)s] [%(name)s] [%(levelname)s]: %(message)s',
log_colors=log_colors_config
)
# 将 formatter 对象返回,以便其他方法或者类使用它来格式化日志消息。
return formatter
# 用 time.strftime() 函数获取当前系统时间,并将其转换为 %Y-%m-%d 格式的日期字符串,赋值给 now_time_day 变量。
now_time_day = time.strftime("%Y-%m-%d", time.localtime())
# 定义一个 INFO 变量,使用 LogHandler 类初始化一个 LogHandler 对象,并指定日志文件路径和日志级别参数。ensure_path_sep() 函数用于确保日志文件路径中使用的是正确的路径分隔符,“/” 或 “\”。
INFO = LogHandler(ensure_path_sep(f"\\logs\\info-{now_time_day}.log"), level='info')
# 定义一个 ERROR 变量,使用 LogHandler 类初始化一个 LogHandler 对象,并指定日志文件路径和日志级别参数。
ERROR = LogHandler(ensure_path_sep(f"\\logs\\error-{now_time_day}.log"), level='error')
# 定义一个 WARNING 变量,使用 LogHandler 类初始化一个 LogHandler 对象,并指定日志文件路径但未指定日志级别参数,此时默认记录 WARNING 级别及以上的日志消息。
WARNING = LogHandler(ensure_path_sep(f'\\logs\\warning-{now_time_day}.log'))
log_decorator.py # 日志装饰器
详细讲解
"""
日志装饰器,控制程序日志输入,默认为 True
如设置 False,则程序不会打印日志
"""
import ast
from functools import wraps
from utils.read_files_tools.regular_control import cache_regular
from utils.logging_tool.log_control import INFO, ERROR
# 定义了一个装饰器函数log_decorator(),并对参数switch进行了注释。
def log_decorator(switch: bool):
"""
封装日志装饰器, 打印请求信息
:param switch: 定义日志开关
:return:
"""
# 这里使用了Python的高级特性——装饰器。首先定义了一个内层函数(swapper),并将其作为参数返回。swapper函数将用来替代被装饰的原函数(func)进行执行。
def decorator(func):
# 保留原函数的一些属性,如函数名和帮助文档
@wraps(func)
def swapper(*args, **kwargs):
# 判断日志为开启状态,才打印日志,这里调用了原函数,并将其返回值赋给了res变量。
res = func(*args, **kwargs)
# 判断日志开关为开启状态,这里判断日志开关switch是否为True(即是否需要打印日志)。
if switch:
# 这里定义了一个日志信息的字符串_log_msg,用于记录请求的详细信息。使用多个格式化字符串(以斜杠\连接)将请求的各个方面(如请求路径、请求方式等)格式化成字符串,并用换行符连接在一起。具体内容可以根据需要进行增删改。
_log_msg = f"\n======================================================\n" \
f"用例标题: {res.detail}\n" \
f"请求路径: {res.url}\n" \
f"请求方式: {res.method}\n" \
f"请求头: {res.headers}\n" \
f"请求内容: {res.request_body}\n" \
f"接口响应内容: {res.response_data}\n" \
f"接口响应时长: {res.res_time} ms\n" \
f"Http状态码: {res.status_code}\n" \
"====================================================="
# 这里的cache_regular()是一个缓存函数的调用,它的作用是将res.is_run转换成字符串并加密缓存,具体实现过程可以简单理解成它用于优化性能。ast.literal_eval()函数可以安全地解析成Python字面量的字符串,并将其转换成相应的数据类型。因为res.is_run可能是一个bool值或None,所以这里需要将解析后的数据赋值给变量_is_run。
_is_run = ast.literal_eval(cache_regular(str(res.is_run)))
# 这里判断应该将日志信息记录在哪个日志文件中。如果用例执行成功且res.is_run为True或None,则将日志信息记录到INFO日志文件中并进行绿色输出。
if _is_run in (True, None) and res.status_code == 200:
INFO.logger.info(_log_msg)
# 如果用例执行失败,则将日志信息记录到ERROR日志文件中,并进行红色输出。
else:
ERROR.logger.error(_log_msg)
# 将原函数(func)的返回值返回给外层函数使用。
return res
# 返回内部函数swapper
return swapper
# 返回嵌套函数decorator
return decorator
run_time_decorator.py # 统计用例执行时长装饰器
详细讲解
"""
统计请求运行时长装饰器,如请求响应时间超时
程序中会输入红色日志,提示时间 http 请求超时,默认时长为 3000ms
"""
from utils.logging_tool.log_control import ERROR
# 这是装饰器函数的定义,接收一个整数参数number表示函数预期运行时间,单位为毫秒。参数类型注解int表示该参数应为整数类型。
def execution_duration(number: int):
"""
封装统计函数执行时间装饰器
:param number: 函数预计运行时长
:return:
"""
# 装饰器的内部函数decorator,接收一个函数作为参数,并返回一个新函数swapper。
def decorator(func):
# 这里定义了新函数swapper,它接收任意数量的位置参数(*args)和关键字参数(**kwargs)。这些参数将在被装饰的函数调用时被传递给它。
def swapper(*args, **kwargs):
# 这里调用了被装饰的函数func,并传入了之前定义的位置和关键字参数。函数调用的返回结果保存在一个变量res中。
res = func(*args, **kwargs)
# 在调用完被装饰的函数后,从返回结果res中获取该函数的时间戳属性,用于后续计算函数的运行时间。
run_time = res.res_time
# 这里用获取的运行时间和预期时间number比较,如果运行时间超时了number,就打印错误信息。具体来说,输出一条警告日志,其中包含了运行时间、测试用例数据以及一些分隔符,易于查看和定位问题。
if run_time > number:
ERROR.logger.error(
"\n==============================================\n"
"测试用例执行时间较长,请关注.\n"
"函数运行时间: %s ms\n"
"测试用例相关数据: %s\n"
"================================================="
, run_time, res)
# 将函数的返回值res返回回去。
return res
# 将新的函数swapper返回回去,以便在后续的函数中调用。
return swapper
# 将内部函数decorator返回,作为最终的装饰器函数。这个函数用于封装待装饰的函数,以统计其运行时间。
return decorator
mysql_tool # 数据库模块
mysql_control.py # mysql封装
详细讲解
"""
mysql 封装,支持 增、删、改、查
"""
import ast
import datetime
import decimal
from warnings import filterwarnings
import pymysql
from typing import List, Union, Text, Dict
from utils import config
from utils.logging_tool.log_control import ERROR
from utils.read_files_tools.regular_control import sql_regular
from utils.read_files_tools.regular_control import cache_regular
from utils.other_tools.exceptions import DataAcquisitionFailed, ValueTypeError
# 用于设置在连接 MySQL 服务器时忽略掉一些 MySQL 数据库发出的警告信息。
filterwarnings("ignore", category=pymysql.Warning)
# 定义一个MysqlDB类,在此类中,我们封装了一些操作MySQL数据库的方法。
class MysqlDB:
""" mysql 封装 """
# 当config.mysql_db.switch为True时,才会执行类定义的代码。这里的意思是如果配置文件中开启了MySQL开关,才会继续连接MySQL。
if config.mysql_db.switch:
# 定义类的初始化方法。
def __init__(self):
# try语句块用来捕获抛出的异常。
try:
# 使用pymysql库建立数据库连接。
self.conn = pymysql.connect(
# 连接数据库的主机地址。
host=config.mysql_db.host,
# 连接数据库的用户名。
user=config.mysql_db.user,
# 连接数据库的密码。
password=config.mysql_db.password,
# 连接数据库的端口号。
port=config.mysql_db.port
)
# 通过连接对象self.conn的cursor()方法来获取游标self.cur,并指定返回结果为字典格式。
self.cur = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
# 捕捉到异常时执行的语句,这里是打印连接失败的日志信息。
except AttributeError as error:
# 将错误信息输出到日志文件中,以便后续查找错误原因。
ERROR.logger.error("数据库连接失败,失败原因 %s", error)
# 定义了一个特殊方法__del__,在对象销毁时自动调用,用于释放该类所有的资源,如关闭数据库连接等。
def __del__(self):
# try语句用于异常处理,尝试关闭游标和连接。
try:
# 关闭游标
self.cur.close()
# 关闭连接
self.conn.close()
# 捕捉到异常时执行的语句,这里是打印连接失败的日志信息。
except AttributeError as error:
# 记录日志信息,记录连接失败的原因。
ERROR.logger.error("数据库连接失败,失败原因 %s", error)
# 总之,该方法是一个析构函数,用于在对象销毁时释放数据库连接和游标。为了避免未释放资源的错误,像在这里这样释放资源是一个好的编程习惯。
# 定义了一个名为query的方法,用于执行查询语句。sql表示要执行的查询语句。tate="all"表示查询的类型,默认为all,即查询所有数据。
def query(self, sql, state="all"):
"""
查询
:param sql:
:param state: all 是默认查询全部
:return:
"""
# try语句用于异常处理,尝试执行查询语句。
try:
# 执行传入的SQL查询语句。
self.cur.execute(sql)
# 如果查询的类型是all,即查询所有数据。
if state == "all":
# 使用fetchall方法获取全部查询结果。
data = self.cur.fetchall()
# 否则即查询单条。
else:
# 使用fetchone方法获取单条查询结果。
data = self.cur.fetchone()
# 返回查询结果。
return data
# 捕捉到异常时执行的语句,这里是打印连接失败的日志信息。
except AttributeError as error_data:
# 记录日志信息,记录连接失败的原因。
ERROR.logger.error("数据库连接失败,失败原因 %s", error_data)
# 将异常继续向上抛出,让函数调用者来处理异常。
raise
# 总之,这个方法是一个查询类的方法,用于执行SQL查询语句,并且返回查询结果。在查询语句中,使用了fetchall和fetchone方法获取查询结果。
# 定义了一个名为execute的方法,用于执行更新、删除和新增操作。sql表示要执行的SQL语句。
def execute(self, sql: Text):
"""
更新 、 删除、 新增
:param sql:
:return:
"""
try:
# 执行传入的SQL更新、删除和新增语句,并返回受影响行数。
rows = self.cur.execute(sql)
# 执行提交事务,将更改提交到数据库中。
self.conn.commit()
# 返回受影响的行数。
return rows
# 捕捉到异常时执行的语句,这里是打印连接失败的日志信息。
except AttributeError as error:
# 记录日志信息,记录连接失败的原因。
ERROR.logger.error("数据库连接失败,失败原因 %s", error)
# 执行回滚操作,撤销刚才执行的更改。
self.conn.rollback()
# 将异常继续向上抛出,让函数调用者来处理异常。
raise
# 总之,这个方法是一个更新、删除和新增类的方法,用于执行SQL更新、删除和新增语句,并返回受影响的行数。在执行SQL语句后,使用commit方法提交更改,并使用rollback方法回滚事务。
# 这个装饰器用于将方法声明为类方法,而不是实例方法,即使没有实例仍然可以调用
@classmethod
# 定义了一个名为sql_data_handler的类方法,用于处理部分类型的SQL查询返回的数据。query_data:表示查询出来的数据。data:表示要处理的数据类型。
def sql_data_handler(cls, query_data, data):
"""
处理部分类型sql查询出来的数据格式
@param query_data: 查询出来的sql数据
@param data: 数据池
@return:
"""
# 遍历查询出来的数据。
for key, value in query_data.items():
# 判断查询出来的数据类型是否为decimal.Decimal类型。
if isinstance(value, decimal.Decimal):
# 如果是,则将它转换为浮点型。
data[key] = float(value)
# 判断查询出来的数据类型是否为datetime.datetime类型。
elif isinstance(value, datetime.datetime):
# 如果是,则将它转换为字符串。
data[key] = str(value)
# 否则即是其他数据类型。
else:
# 直接将查询出来的数据放入返回值数据池中。
data[key] = value
# 返回处理后的数据结果。
return data
# 总之,这个方法是一个用于处理部分类型SQL查询返回的数据的类方法,用于保证返回值数据格式的正确性。方法内部使用了for循环遍历查询出来的数据,并根据数据类型进行相应的转换或赋值操作,最后将结果放入返回值数据池中。
# 定义了一个名为SetUpMySQL的类,继承自MysqlDB类。
class SetUpMySQL(MysqlDB):
""" 处理前置sql """
# 定义了一个名为setup_sql_data的实例方法,它接收一个sql参数,可以是一个字符串列表或空值,并返回一个含有处理后数据的字典对象。
def setup_sql_data(self, sql: Union[List, None]) -> Dict:
"""
处理前置请求sql
:param sql:
:return:
"""
# 将sql转换成字符串类型,并移除前面所有的空白字符,并将其作为参数传递给ast.literal_eval函数,用于转换sql成Python语法的对象。
sql = ast.literal_eval(cache_regular(str(sql)))
# try语句用于异常处理。
try:
# 声明一个空字典,用于存储SQL查询返回结果。
data = {}
# 当传入的SQL请求不是空值时执行。
if sql is not None:
# 遍历sql列表,将每一组SQL请求语句执行。
for i in sql:
# 如果查询是select类型。
if i[0:6].upper() == 'SELECT':
# 使用query方法执行SQL查询,并将返回数据的第一项赋值给变量sql_date。
sql_date = self.query(sql=i)[0]
# 遍历sql_date的键值对。
for key, value in sql_date.items():
# 将查询到的value值赋给data的key键。
data[key] = value
# 如果查询不是select类型。
else:
# 使用execute方法直接执行SQL请求。
self.execute(sql=i)
# 返回处理好的数据结果。
return data
# 捕捉到异常时执行的语句,这里是抛出一个DataAcquisitionFailed异常。
except IndexError as exc:
# 抛出一个DataAcquisitionFailed异常,提示SQL数据查询失败,请检查是否正确,将捕获到的异常作为其原因。
raise DataAcquisitionFailed("sql 数据查询失败,请检查setup_sql语句是否正确") from exc
总之,这个SetUpMySQL类继承了MysqlDB类,并覆盖了父类中的setup_sql_data方法,该方法用于处理前置的SQL请求。在该方法内部,先将传入的SQL请求转换成Python语法对象,并进行遍历执行。如果是select类型的查询,在遍历结果的同时将查询到的数据存放在字典对象中并返回。如果是其他类型的请求,则直接调用方法执行,并将返回值赋值给data字典。如果执行失败,则会抛出异常提示查询失败。
# 定义了一个名为AssertExecution的类,继承自MysqlDB类。
class AssertExecution(MysqlDB):
""" 处理断言sql数据 """
# 定义了一个名为assert_execution的实例方法,它接收两个参数,一个是sql,一个是resp,并返回一个字典。
def assert_execution(self, sql: list, resp) -> dict:
"""
执行 sql, 负责处理 yaml 文件中的断言需要执行多条 sql 的场景,最终会将所有数据以对象形式返回
:param resp: 接口响应数据
:param sql: sql
:return:
"""
try:
# 判断传入的sql参数是否为列表类型。
if isinstance(sql, list):
# 声明一个空字典,用于存储SQL查询返回结果。
data = {}
# 声明变量_sql_type,这里存放SQL执行语句的关键字。
_sql_type = ['UPDATE', 'update', 'DELETE', 'delete', 'INSERT', 'insert']
# 如果查询的SQL语句不包含_sql_type中的关键字语句就执行。
if any(i in sql for i in _sql_type) is False:
for i in sql:
# 对每个i关键字SQL执行正则匹配操作。并将resp作为参数传递给sql_regular方法。
sql = sql_regular(i, resp)
# 如果sql不为空。
if sql is not None:
# 使用query方法执行SQL查询,并将返回结果的第一项赋值给query_data。
query_data = self.query(sql)[0]
# 使用sql_data_handler方法,处理查询出来的数据,并将其存入data字典。
data = self.sql_data_handler(query_data, data)
# 如果sql为空,就抛出异常。
else:
# 抛出DataAcquisitionFailed异常,提示未查询到数据。
raise DataAcquisitionFailed(f"该条sql未查询出任何数据, {sql}")
else:
# 如果对sql中_sql_type中的关键字类型中的语句进行断言,即不符合处理条件时抛出异常。
raise DataAcquisitionFailed("断言的 sql 必须是查询的 sql")
# 如果sql不属于列表类型,就抛出异常
else:
# 抛出ValueTypeError异常,提示sql数据类型不正确,接收的参数类型为列表类型。
raise ValueTypeError("sql数据类型不正确,接受的是list")
# 返回处理好的数据结果。
return data
# 捕捉可能出现的任何异常。
except Exception as error_data:
# 输出相关异常错误日志信息。
ERROR.logger.error("数据库连接失败,失败原因 %s", error_data)
# 抛出捕捉到的异常。
raise error_data
总之,这个AssertExecution类继承了MysqlDB类,并覆盖了父类中的assert_execution方法,该方法用于处理SQL断言。在该方法内部,首先判断sql是否为列表类型,然后遍历并处理每个SQL语句。如果是查询语句,就使用query方法执行,并使用sql_data_handler方法将处理后的结果存储到data字典中。如果有其他情况,则抛出相关异常信息。
notify # 通知模块
ding_talk.py # 钉钉通知
详细讲解
"""
钉钉通知封装
"""
import base64
import hashlib
import hmac
import time
import urllib.parse
from typing import Any, Text
from dingtalkchatbot.chatbot import DingtalkChatbot, FeedLink
from utils.other_tools.get_local_ip import get_host_ip
from utils.other_tools.allure_data.allure_report_data import AllureFileClean, TestMetrics
from utils import config
# 定义了一个名为DingTalkSendMsg的类。
class DingTalkSendMsg:
""" 发送钉钉通知 """
# 定义了一个实例化方法__init__,方法的第一个参数metrics是一个类型为TestMetrics的对象。
def __init__(self, metrics: TestMetrics):
# 将传入的metrics对象赋值给self.metrics。
self.metrics = metrics
# 生成一个时间戳,将其转换成字符串类型,并将其赋值给self.timeStamp。
self.timeStamp = str(round(time.time() * 1000))
# 总之,在DingTalkSendMsg类中,定义了一个实例化方法,在实例化时需要传入一个TestMetrics对象,并且在初始化的时候生成一个时间戳字符串存储在self.timeStamp中。
# 这是一个函数定义的语句,函数名为xiao_ding,函数的第一个参数为self。
def xiao_ding(self):
# 这一行调用了该类中的get_sign方法,获取签名信息。将其赋值给变量sign。
sign = self.get_sign()
# 这一行从yaml文件中获取钉钉机器人的webhook,然后将时间戳、签名等参数拼接成一个完整的URL,并将其赋值给变量webhook。
webhook = config.ding_talk.webhook + "×tamp=" + self.timeStamp + "&sign=" + sign
# 这一行用拼接好的URL调用DingtalkChatbot类的构造函数,创建一个聊天机器人实例对象,并将其返回。
return DingtalkChatbot(webhook)
# 综上所述,这是一个用于根据钉钉机器人的webhook、时间戳、签名等参数,创建一个DingTalk的发送机器人实例对象,并返回该对象的函数。
# 这是一个方法定义语句,方法名为get_sign,第一个参数为self,返回一个字符串类型的密钥sign。
def get_sign(self) -> Text:
"""
根据时间戳 + "sign" 生成密钥
:return:
"""
# 这一行将self.timeStamp和钉钉配置中的密钥secret按照固定格式拼接成待加密的字符串string_to_sign,使用utf-8进行编码,并将结果赋值给变量string_to_sign。
string_to_sign = f'{self.timeStamp}\n{config.ding_talk.secret}'.encode('utf-8')
# 这一行使用加密模块hmac对待加密的字符串string_to_sign进行加密,使用config.ding_talk.secret作为密钥,加密算法使用SHA256,并将结果赋值给变量hmac_code。
hmac_code = hmac.new(
config.ding_talk.secret.encode('utf-8'),
string_to_sign,
digestmod=hashlib.sha256).digest()
# 这一行对加密后的结果进行进一步处理,首先将其进行Base64编码,再进行URL转义,并将结果赋值给变量sign。
sign = urllib.parse.quote_plus(base64.b64encode(hmac_code))
# 这一行返回生成的密钥sign。
return sign
# 综上所述,代码的作用是根据时间戳和配置中的密钥生成一个密钥字符串,并对其进行加密和处理,生成最终的密钥返回。
# 这是一个方法定义语句,方法名为send_text,第一个参数为msg,表示需要发送的文本内容,第二个参数为可选参数mobiles,表示需要艾特的用户的电话号码,返回值为None。
def send_text(
self,
msg: Text,
mobiles=None
) -> None:
"""
发送文本信息
:param msg: 文本内容
:param mobiles: 艾特用户电话
:return:
"""
# 这是一个条件语句,判断mobiles是否为空,如果为空则表示@所有人,执行下一步操作;如果不为空则执行其他操作。
if not mobiles:
# 这一行创建一个钉钉聊天机器人对象,并调用send_text方法向钉钉机器人发送文本消息,文本内容为msg,是否艾特所有人为True。
self.xiao_ding().send_text(msg=msg, is_at_all=True)
else:
# 这是一个条件语句,判断mobiles是否为列表类型的数据,如果是,则执行下一步操作;如果不是,则执行下一步操作。
if isinstance(mobiles, list):
# 这一行调用钉钉聊天机器人对象的send_text方法,向钉钉机器人发送文本消息,并且@指定电话号码的用户,电话号码信息存储在参数at_mobiles中。
self.xiao_ding().send_text(msg=msg, at_mobiles=mobiles)
else:
# 这一行抛出一个异常,提示mobiles的类型不正确。
raise TypeError("mobiles类型错误 不是list类型.")
# 综上所述,这段代码的作用是向指定的钉钉机器人发送文本信息,并@指定电话号码的用户。如果mobiles为Empty或None,则@所有人,否则@指定电话号码的用户。
# 这是一个方法定义语句,方法名为send_link,它接收四个参数:title表示链接的标题,text表示链接的内容描述,message_url表示要发送的链接地址,pic_url表示链接的图片地址。该方法返回值为None。
def send_link(
self,
title: Text,
text: Text,
message_url: Text,
pic_url: Text
) -> None:
"""
发送link通知
:return:
"""
# 这一行代码创建一个钉钉聊天机器人对象,通过调用钉钉聊天机器人对象的send_link方法来发送指定的链接信息。title参数表示链接的标题,text参数表示链接的内容描述,message_url参数表示要发送的链接地址,pic_url参数表示链接的图片地址。
self.xiao_ding().send_link(
title=title,
text=text,
message_url=message_url,
pic_url=pic_url
)
# 综上,该方法的作用是以指定的格式,在钉钉聊天机器人上发送链接信息。
# 这是一个方法定义语句,参数包括title表示消息的标题,msg表示消息的内容,mobiles表示提醒的对象(可以为空),is_at_all表示是否提醒全部对象(默认为False),该方法无返回值。
def send_markdown(
self,
title: Text,
msg: Text,
mobiles=None,
is_at_all=False
) -> None:
"""
:param is_at_all:
:param mobiles:
:param title:
:param msg:
markdown 格式
"""
# 这一行代码检查mobiles参数是否为空,如果为空则向is_at_all参数提到的@人员发送消息。
if mobiles is None:
# 如果mobiles参数为空,则调用self.xiao_ding().send_markdown方法,发送Markdown格式的消息,包括标题title和文本部分text,可以选择是否提醒所有人。
self.xiao_ding().send_markdown(title=title, text=msg, is_at_all=is_at_all)
else:
# 这一行代码检查mobiles参数是否为列表类型,如果是,则向列表中的电话号码发送消息。
if isinstance(mobiles, list):
# 如果mobiles参数为列表类型,则调用self.xiao_ding().send_markdown方法,并在发出的消息中@指定号码。
self.xiao_ding().send_markdown(title=title, text=msg, at_mobiles=mobiles)
else:
# 抛出错误
raise TypeError("mobiles类型错误 不是list类型.")
# 综上,该方法的作用是将指定的Markdown格式的内容发送到钉钉聊天机器人,如果没有指定对象则@所有人,否则@指定的列表内的号码。
# 这是一个Python中的装饰器,用于表明该方法为静态方法,可以通过类名来调用,而不必实例化对象。
@staticmethod
# 这是一个静态方法定义语句,接收三个参数:title表示链接的标题,message_url表示要发送的链接地址,pic_url表示链接中的图片地址。该方法返回一个FeedLink对象。
def feed_link(
title: Text,
message_url: Text,
pic_url: Text
) -> Any:
""" FeedLink 二次封装 """
# 该行代码创建了一个FeedLink对象并将其返回。FeedLink对象包括title表示链接的标题,message_url表示要发送的链接地址,pic_url表示链接的图片地址。
return FeedLink(
title=title,
message_url=message_url,
pic_url=pic_url
)
# 综上,该方法的作用是将链接信息封装为FeedLink类型的对象,并返回此对象。
# 这是一个方法定义语句,参数为*arg,表示参数个数不定,可以传入任意个数的参数;该方法返回值为空。
def send_feed_link(self, *arg) -> None:
"""发送 feed_lik """
# 该行代码调用了xiao_ding方法,并调用该方法的send_feed_card方法,将所有传入的FeedLink对象作为一个列表传递给send_feed_card方法。
self.xiao_ding().send_feed_card(list(arg))
# 综上,该方法的作用是将传入的多个FeedLink类型的对象列表一起发送给钉钉机器人,以展示多个链接预览信息
# 定义了一个方法send_ding_notification,用于向钉钉机器人发送测试报告。
def send_ding_notification(self):
""" 发送钉钉报告通知 """
# 定义了一个 bool 类型的变量is_at_all,初始化为 False。
is_at_all = False
# 如果有测试用例失败或异常情况,将变量is_at_all的值改为 True。
if self.metrics.failed + self.metrics.broken > 0:
is_at_all = True
# 这是一个长的文本字符串,用于组合测试报告的各种信息,包括测试执行的项目名称、执行环境、执行人、执行结果等。
text = f"#### {config.project_name}通知 " \
f"\n\n>Python脚本任务: {config.project_name}" \
f"\n\n>环境: {config.host}\n\n>" \
f"执行人: {config.tester_name}" \
f"\n\n>执行结果: {self.metrics.pass_rate}% " \
f"\n\n>总用例数: {self.metrics.total} " \
f"\n\n>成功用例数: {self.metrics.passed}" \
f" \n\n>失败用例数: {self.metrics.failed} " \
f" \n\n>异常用例数: {self.metrics.broken} " \
f"\n\n>跳过用例数: {self.metrics.skipped}" \
f" \n" \
f" > ###### 测试报告 [详情](http://{get_host_ip()}:8000/index.html) \n"
# 这行代码实例化了一个DingTalkSendMsg对象,并调用该对象的send_markdown方法,将测试报告信息以 Markdown 格式发送给钉钉机器人。
DingTalkSendMsg(AllureFileClean().get_case_count()).send_markdown(
title="【接口自动化通知】",
msg=text,
is_at_all=is_at_all
)
# 综上,该方法的作用是生成测试报告信息,并将其以 Markdown 格式的文本发送给钉钉机器人。lark.py # 飞书通知
详细讲解
"""
发送飞书通知
"""
import json
import logging
import time
import datetime
import requests
import urllib3
from utils.other_tools.allure_data.allure_report_data import TestMetrics
from utils import config
# 这行代码是用来关闭urllib3模块的警告提示,如果不加这行代码,当我们使用requests向HTTPS网站发起请求时,会提示警告信息。
urllib3.disable_warnings()
# 这是Python异常处理语法,在try的代码块中尝试执行代码,如果执行出现异常,则执行except中的异常处理代码块。
try:
# 这行代码的作用是定义一个JSONDecodeError对象,用来处理在JSON解码过程中出现的异常。如果当前Python版本的标准库中不存在json.decoder.JSONDecodeError,则将该对象定义为ValueError。
JSONDecodeError = json.decoder.JSONDecodeError
except AttributeError:
JSONDecodeError = ValueError
# 通过上述处理,可以确保无论是在 Python 3.7 及 更早版本下,还是在 Python 3.8及更新版本下,都能正确处理 JSON 数据解码过程中出现的异常。
# 这是一个用于判断字符串是否为空的函数,content是传入的参数,用于判断字符串是否为空。
def is_not_null_and_blank_str(content):
"""
非空字符串
:param content: 字符串
:return: 非空 - True,空 - False
"""
# 判断content是否是一个非空字符串,其中content and content.strip()的结果是判断content是否有值,以及去掉字符串两端空格后是否有值。函数返回一个bool类型的结果。
return bool(content and content.strip())
# 综上,该函数的作用是判断传入的字符串是否为空。如果为空字符串,函数返回 False;否则返回 True。
# 这是一个FeiShuTalkChatBot类的构造函数__init__,用于初始化FeiShuTalkChatBot类的实例变量。
class FeiShuTalkChatBot:
"""飞书机器人通知"""
# metrics是TestMetrics类的实例变量,是用于记录测试结果的指标类的一个实例。构造函数,接收一个TestMetrics类型的参数metrics,并将其保存为FeiShuTalkChatBot类的实例变量metrics。
def __init__(self, metrics: TestMetrics):
self.metrics = metrics
# 综上,这个类是用于飞书机器人通知,并且将测试结果的指标类作为实例变量来保存,方便后续调用。
# 接收一个字符类型的参数msg,表示要发送的文本消息。
def send_text(self, msg: str):
"""
消息类型为text类型
:param msg: 消息内容
:return: 返回消息发送结果
"""
# 定义一个字典类型的变量data,表示要发送的消息类型为"text"。
data = {"msg_type": "text", "at": {}}
# 使用下面定义好的函数is_not_null_and_blank_str判断msg是否为空。
if is_not_null_and_blank_str(msg):
# 如果msg非空,将msg作为文本内容添加到data的content中。
data["content"] = {"text": msg}
else:
# 如果msg为空,输出日志和错误信息。
logging.error("text类型,消息内容不能为空!")
raise ValueError("text类型,消息内容不能为空!")
# 这是一个Python内置的logging库,用来打印和记录日志信息。通过设置logging的不同级别,可以控制输出不同类型的日志信息,如调试信息、错误信息等。这里使用的是调试信息级别(debug),用来输出程序运行时的详细信息。'text类型:%s',这是一个格式化字符串,其中%s是一个占位符,表示这个位置可以被任何类型的数据替换。具体替换的数据是在后面的参数中传入的,即data。
logging.debug('text类型:%s', data)
# 调用类中的post方法,将发送文本消息的请求发送出去,并返回发送结果。
return self.post()
# 综上,send_text方法是用于发送文本消息的,并且判断了msg是否为空。如果为空,则输出错误信息并抛出异常;否则,发送文本消息,并返回发送结果。
def post(self):
"""
发送消息(内容UTF-8编码)
:return: 返回消息发送结果
"""
# 用于创建一个字典 rich_text,包含需要发送的消息内容。 字典中包含“send“,”text“和”at“等字典, text又包含了标题、测试人员姓名、测试环境等字符串,还包含一个记录各种数值数据的列表。这些数值数据包括成功率、通过的用例数、失败的用例数、异常的用例数和当前时间等。其中的值都是从配置文件中获取的,例如 config.tester_name 和 config.env。最后一项是一张测试结果的图片,图片的地址可以从远程服务器上获取。
rich_text = {
"email": "2393557647@qq.com",
"msg_type": "post",
"content": {
"post": {
"zh_cn": {
"title": "【自动化测试通知】",
"content": [
[
{
"tag": "a",
"text": "测试报告",
"href": "https://192.168.xx.72:8080"
},
{
"tag": "at",
"user_id": "ou_18eac85d35a26f989317ad4f02e8bbbb"
# "text":"皓月"
}
],
[
{
"tag": "text",
"text": "测试 人员 : "
},
{
"tag": "text",
"text": f"{config.tester_name}"
}
],
[
{
"tag": "text",
"text": "运行 环境 : "
},
{
"tag": "text",
"text": f"{config.env}"
}
],
[{
"tag": "text",
"text": "成 功 率 : "
},
{
"tag": "text",
"text": f"{self.metrics.pass_rate} %"
}], # 成功率
[{
"tag": "text",
"text": "成功用例数 : "
},
{
"tag": "text",
"text": f"{self.metrics.passed}"
}], # 成功用例数
[{
"tag": "text",
"text": "失败用例数 : "
},
{
"tag": "text",
"text": f"{self.metrics.failed}"
}], # 失败用例数
[{
"tag": "text",
"text": "异常用例数 : "
},
{
"tag": "text",
"text": f"{self.metrics.failed}"
}], # 损坏用例数
[
{
"tag": "text",
"text": "时 间 : "
},
{
"tag": "text",
"text": f"{datetime.datetime.now().strftime('%Y-%m-%d')}"
}
],
[
{
"tag": "img",
"image_key": "d640eeea-4d2f-4cb3-88d8-c964fab53987",
"width": 300,
"height": 300
}
]
]
}
}
}
}
# 字典 headers 用于存储向服务器发送请求时的请求头信息。在这个字典中,我们指定了消息为 Json 类型,同时指定编码。
headers = {'Content-Type': 'application/json; charset=utf-8'}
# 消息内容被转化为Json格式,并赋给变量post_data。
post_data = json.dumps(rich_text)
# 我们使用requests库中的post()方法发送一个POST请求,请求包含了上面提到的内容,包括飞书机器人的连接地址、请求头信息、发送的数据内容。 这里的标志verify=False用于禁用SSL安全,可用于自签名的SSL证书。
response = requests.post(
config.lark.webhook,
headers=headers,
data=post_data,
verify=False
)
# 我们使用 json() 方法将响应转换为 Json 格式并赋给变量 result。
result = response.json()
# 如果返回的结果字典中键 ‘StatusCode’ 对应的值不为0,则代表发送失败。
if result.get('StatusCode') != 0:
# 我们获取当前时间 time_now,同时检查响应结果字典中是否有 errmsg 这个键,如果有这个键,则将值赋给变量 result_msg,否则赋值为未知异常。
time_now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
result_msg = result['errmsg'] if result.get('errmsg', False) else '未知异常'
# 我们定义了一个 error_data 变量,包含一个消息文本字典。此字典中定义了消息内容、消息类型和是否需要 at。如果消息发送失败,则需要通过此字典向管理员群发送消息通知。
error_data = {
"msgtype": "text",
"text": {
"content": f"[注意-自动通知]飞书机器人消息发送失败,时间:{time_now},"
f"原因:{result_msg},请及时跟进,谢谢!"
},
"at": {
"isAtAll": False
}
}
# 如果出现了消息发送失败的情况,则使用 Python 标准库的 logging 模块,记录细节日志(使用 "error" 级别)。同时将错误信息的内容附加到日志消息中去。
logging.error("消息发送失败,自动通知:%s", error_data)
# 我们使用requests库向飞书机器人的Webhook地址发送错误消息。此时再次发送消息会通过其他通道(例如短信或者微信)通知管理员,提醒他们尽快解决这个问题。
requests.post(config.lark.webhook, headers=headers, data=json.dumps(error_data))
# 最后返回的是响应结果字典 result,包括响应消息是否成功、成功/失败的消息和其他相关的响应元数据。
return result
send_mail.py # 邮箱通知
详细讲解
import smtplib
from email.mime.text import MIMEText
from utils.other_tools.allure_data.allure_report_data import TestMetrics, AllureFileClean
from utils import config
# 定义了一个名为SendEmail的类,用于发送测试结果邮件。
class SendEmail:
""" 发送邮箱 """
# 定义类的构造方法__init__,接受一个metrics参数,该参数的类型是TestMetrics。
def __init__(self, metrics: TestMetrics):
# 将metrics参数赋值给类属性self.metrics。
self.metrics = metrics
# 创建一个名为allure_data的类属性,并将AllureFileClean类的实例赋值给它。
self.allure_data = AllureFileClean()
# 创建一个名为CaseDetail的类属性,并调用AllureFileClean类实例的get_failed_cases_detail方法,并将返回值赋值给CaseDetail属性。
self.CaseDetail = self.allure_data.get_failed_cases_detail()
# @classmethod表示是一个类方法,也就是说,该方法是直接属于类定义的,而不是属于某个类对象的。类方法第一个参数通常是cls,表示类本身,而不是实例对象。通过cls参数可以操作类的属性和方法,也可以实例化类对象。
@classmethod
# 定义了一个类方法send_mail,cls表示类本身;user_list:接收邮件的邮箱列表;sub:邮件主题;content:邮件正文;返回值:None。
def send_mail(cls, user_list: list, sub, content: str) -> None:
"""
@param user_list: 发件人邮箱
@param sub:
@param content: 发送内容
@return:
"""
# 将发件人姓名和邮箱地址拼接成发件人字符串。
user = "皓月" + "<" + config.email.send_user + ">"
# 创建一个MIMEText对象,用于存储邮件内容。
message = MIMEText(content, _subtype='plain', _charset='utf-8')
# 为邮件添加主题、发件人和收件人。
message['Subject'] = sub
message['From'] = user
message['To'] = ";".join(user_list)
# 创建SMTP对象,连接到SMTP服务器。
server = smtplib.SMTP()
server.connect(config.email.email_host)
# 登录SMTP服务器。
server.login(config.email.send_user, config.email.stamp_key)
# 发送邮件,参数依次为发件人、收件人、邮件内容。
server.sendmail(user, user_list, message.as_string())
# 关闭与SMTP服务器的连接。
server.close()
# 定义了一个实例方法error_mail,用于发送异常邮件通知,self表示实例本身;error_message:报错信息;返回值:None。
def error_mail(self, error_message: str) -> None:
"""
执行异常邮件通知
@param error_message: 报错信息
@return:
"""
# 从config文件中获取了邮件列表config.email.send_list,并将其 拆分为多个邮件地址。我们将这些地址的数组作为变量user_list。
email = config.email.send_list
user_list = email.split(',') # 多个邮箱发送,config文件中直接添加 '2393557647@qq.com'
# 通过将config文件中项目名称 config.project_name 和 "接口自动化执行异常通知" 连接在一起产生邮件的主题 sub。
sub = config.project_name + "接口自动化执行异常通知"
# 邮件的正文 content 为以 error_message 为内容的字符串。
content = f"自动化测试执行完毕,程序中发现异常,请悉知。报错信息如下:\n{error_message}"
# 使用另一个叫做 self.send_mail() 的私有函数来发送邮件。发送邮件接收三个参数:邮件收件人列表、邮件主题和邮件内容(以HTML格式发送)。
self.send_mail(user_list, sub, content)
# 总的来说,该函数是一个封装好的用于发送邮件通知的函数,当出现异常时可以调用该函数来通知相关人员。
# 定义了一个 send_main 的类方法,不接受任何参数,不返回任何值。
def send_main(self) -> None:
"""
发送邮件
:return:
"""
# 获取邮件列表
email = config.email.send_list
user_list = email.split(',') # 多个邮箱发送,yaml文件中直接添加 '2393557647@qq.com'
# 生成邮件主题字符串,将config文件中的项目名称 config.project_name 和 "接口自动化报告" 进行连接。
sub = config.project_name + "接口自动化报告"
# 生成邮件正文内容,并使用 self.metrics 变量中的数据填充邮件正文。其中,self.allure_data.get_failed_cases_detail() 可以通过获取 Allure 报告的详细信息,包括测试失败原因等更多细节信息。
content = f"""
各位同事, 大家好:
自动化用例执行完成,执行结果如下:
用例运行总数: {self.metrics.total} 个
通过用例个数: {self.metrics.passed} 个
失败用例个数: {self.metrics.failed} 个
异常用例个数: {self.metrics.broken} 个
跳过用例个数: {self.metrics.skipped} 个
成 功 率: {self.metrics.pass_rate} %
{self.allure_data.get_failed_cases_detail()}
**********************************
jenkins地址:https://121.xx.xx.47:8989/login
详细情况可登录jenkins平台查看,非相关负责人员可忽略此消息。谢谢。
"""
# 使用 self.send_mail() 函数发送邮件,具体发送包括邮件收件人列表 user_list,邮件主题 sub 和邮件内容 content(以HTML格式)。
self.send_mail(user_list, sub, content)
wechat_send.py # 企业微信通知
详细讲解
"""
描述: 发送企业微信通知
"""
import requests
from utils.logging_tool.log_control import ERROR
from utils.other_tools.allure_data.allure_report_data import TestMetrics, AllureFileClean
from utils.times_tool.time_control import now_time
from utils.other_tools.get_local_ip import get_host_ip
from utils.other_tools.exceptions import SendMessageError, ValueTypeError
from utils import config
# 定义了一个 WeChatSend 的类。
class WeChatSend:
"""
企业微信消息通知
"""
# 定义WeChatSend类的构造函数__init__,该函数接受一个名为metrics的参数,该参数的类型为TestMetrics。
def __init__(self, metrics: TestMetrics):
# 将构造函数传入的metrics参数赋值给self.metrics成员变量,该成员变量存储了测试度量指标的信息。
self.metrics = metrics
# 定义了一个名为headers的成员变量,使用Python字典形式存储了HTTP请求头的Content-Type字段值。该值为application/json,即请求体使用JSON格式发送。
self.headers = {"Content-Type": "application/json"}
# send_text是一个实例方法,接收三个参数,self代表当前对象,content表示文本内容,mentioned_mobile_list表示手机号列表,提醒手机号对应的群成员。
def send_text(self, content, mentioned_mobile_list=None):
"""
发送文本类型通知
:param content: 文本内容,最长不超过2048个字节,必须是utf8编码
:param mentioned_mobile_list: 手机号列表,提醒手机号对应的群成员(@某个成员),@all表示提醒所有人
:return:
"""
# 定义了一个名为_data的变量,使用Python字典形式存储了请求体中的各个字段和对应属性。在这里,定义了msgtype字段为文本类型,text字段为文本内容,mentioned_list和mentioned_mobile_list分别为提醒的群成员ID和手机号列表。其中,content参数将作为文本内容发送。
_data = {"msgtype": "text", "text": {"content": content, "mentioned_list": None,
"mentioned_mobile_list": mentioned_mobile_list}}
# if语句使用or逻辑操作符判断mentioned_mobile_list是否为空或属于list类型。如果是,则执行if子类;如果不是,则执行else子句。
if mentioned_mobile_list is None or isinstance(mentioned_mobile_list, list):
# 如果mentioned_mobile_list中存在手机号码,则进入for循环:
if len(mentioned_mobile_list) >= 1:
# 遍历所有手机号码,其中i为每个手机号。
for i in mentioned_mobile_list:
# 检查 i 这个变量是否为字符串类型(str)。如果 i 是字符串类型,则进入下一层的代码块,否则抛出一个 ValueTypeError 异常。
if isinstance(i, str):
# 向企业微信应用机器人URL 发送HTTP POST请求,通过json参数发送请求正文。在此处,_data 字典将转换为JSON格式,并包含在HTTP请求的正文中。config.wechat.webhook 为企业微信应用机器人URL,它接收发送给工作群的各种消息类型。。
res = requests.post(url=config.wechat.webhook, json=_data, headers=self.headers)
# 消息发送没问题,返回值的errcode为0。
if res.json()['errcode'] != 0:
# 消息发送异常,则返回错误日志。
ERROR.logger.error(res.json())
# 发送消息出现错误,则引发具有相应错误消息的异常。
raise SendMessageError("企业微信「文本类型」消息发送失败")
else:
# 如果手机号列表的元素包含类型不为字符串类型,则抛出ValueTypeError异常,提醒用户手机号必须为字符串类型。
raise ValueTypeError("手机号码必须是字符串类型.")
else:
# 如果mentioned_mobile_list变量不为空且不是一个列表,则抛出ValueTypeError异常,提醒用户该变量必须为列表类型。
raise ValueTypeError("手机号码列表必须是list类型.")
# 定义了一个 send_markdown() 方法,并且定义了两个参数 self 和 content。
def send_markdown(self, content):
"""
发送 MarkDown 类型消息
:param content: 消息内容,markdown形式
:return:
"""
# 这一行定义一个字典 _data,用于存储要发送的 Markdown 消息内容。首先,字典中包含了键名为 msgtype 的 JSON 对象,其值为字符串类型的 markdown,表示将要发送的消息类型为 Markdown 格式。接下来,字典中包含了键名为 markdown 的 JSON 对象,其值是一个字典对象,包含了 content 键,其值为变量 content。
_data = {"msgtype": "markdown", "markdown": {"content": content}}
# 这一行使用 requests.post() 方法向企业微信机器人发送消息。其中,参数 url 表示企业微信机器人的 Webhook 地址,json 参数表示将要发送的数据,headers 参数设置为 self.headers,表示使用 self.headers 来发送 HTTP 请求头。发送请求后,返回一个 HTTP 响应对象 res,其中包含了发送请求的结果。
res = requests.post(url=config.wechat.webhook, json=_data, headers=self.headers)
# 判断从企业微信服务器返回的 JSON 数据中 errcode 的值是否为 0。如果不为 0,表示发送消息出现了问题,需要进行错误处理。
if res.json()['errcode'] != 0:
# 通过调用名为 logger 的日志记录器的 error() 方法记录错误信息。
ERROR.logger.error(res.json())
# 会抛出一个自定义的异常 SendMessageError,该异常提示用户消息发送失败。
raise SendMessageError("企业微信「MarkDown类型」消息发送失败")
# 定义了一个 _upload_file 方法来上传文件。
def _upload_file(self, file):
"""
先将文件上传到临时媒体库
"""
# 从 config.wechat.webhook 变量中提取了一个密钥 key,这个密钥用于对请求进行授权。它从字符串 "key=" 的第一个出现位置开始截取。
key = config.wechat.webhook.split("key=")[1]
# 拼接了上传文件需要访问的 URL。其中,key 是刚刚获取的密钥,在 URL 的查询参数部分传递。同时,type 参数设置为 "file" 表示上传的是一个文件。
url = f"https://qyapi.weixin.qq.com/cgi-bin/webhook/upload_media?key={key}&type=file"
# 创建了一个 dict 类型的 data 变量。它只有一个键 "file",值是打开文件并读取二进制数据的 file 对象。
data = {"file": open(file, "rb")}
# 发送文件上传请求,requests.post() 方法发送一个 POST 请求,上传文件并返回请求的结果。具体而言,url 是请求的 URL,files=data 表示上传文件的信息。json() 方法将响应的 JSON 字符串转换成 Python 对象,并复制该对象给变量 res。
res = requests.post(url, files=data).json()
# 返回从响应 JSON 中提取的 "media_id",它是上传文件的唯一标识符,并在后续步骤中用于发送消息。
return res['media_id']
# 定义了一个 send_file_msg 方法来发送企业微信中的文件消息。
def send_file_msg(self, file):
"""
发送文件类型的消息
@return:
"""
# 创建了一个 dict 类型的 _data 变量,这个字典包含两个键值对,一个键是 "msgtype",值是 "file" 表示消息类型为文件;另一个键是 "file",值是另一个字典,它包含一个键 "media_id",值是 _upload_file 方法返回的媒体唯一标识符。
_data = {"msgtype": "file", "file": {"media_id": self._upload_file(file)}}
# 使用 requests.post() 方法来发送文件消息,url 是消息发送的 URL,_data 包含要发送的消息内容,而 headers 值是 HTTP 消息头,用于授权访问。其中,发送的数据是以 JSON 格式提供的,requests.post() 方法通过将数据编码为 JSON 字符串并设置 HTTP 消息头中的 Content-Type 来发送数据,而不需要手动编码。该方法返回响应对象。
res = requests.post(url=config.wechat.webhook, json=_data, headers=self.headers)
# 判断返回的响应 JSON 中的 "errcode" 不为 0,则说明企业微信发送消息失败
if res.json()['errcode'] != 0:
# 通过调用名为 logger 的日志记录器的 error() 方法记录错误信息。
ERROR.logger.error(res.json())
# 引发一个 SendMessageError 异常,以提醒开发者消息发送失败
raise SendMessageError("企业微信「file类型」消息发送失败")
# 定义了一个 send_wechat_notification 方法来发送企业微信通知,self 是指类方法需要访问的所在的实例本身。
def send_wechat_notification(self):
""" 发送企业微信通知 """
# 定义了 text 变量,它是一个通过 f-string 初始化的长字符串,将在企业微信中作为 markdown 消息的主要内容。文本中使用了多个格式化字符,如 > 符号用于缩进,<font color=\"info\"> 标签用于设置字体样式和颜色,{self.metrics.pass_rate}% 则使用了变量来填充实际值。值得注意的是,这里使用了双引号和单引号的混搭来生成嵌套的字符串,从而使代码更易读。
text = f"""【{config.project_name}自动化通知】
>测试环境:<font color=\"info\">TEST</font>
>测试负责人:@{config.tester_name}
>
> **执行结果**
><font color=\"info\">成 功 率 : {self.metrics.pass_rate}%</font>
>用例 总数:<font color=\"info\">{self.metrics.total}</font>
>成功用例数:<font color=\"info\">{self.metrics.passed}</font>
>失败用例数:`{self.metrics.failed}个`
>异常用例数:`{self.metrics.broken}个`
>跳过用例数:<font color=\"warning\">{self.metrics.skipped}个</font>
>用例执行时长:<font color=\"warning\">{self.metrics.time} s</font>
>时间:<font color=\"comment\">{now_time()}</font>
>
>非相关负责人员可忽略此消息。
>测试报告,点击查看>>[测试报告入口](http://{get_host_ip()}:9999/index.html)"""
# 初始化了一个 WeChatSend 实例,并使用它来发送 markdown 文本消息。AllureFileClean().get_case_count() 返回测试用例数量,作为消息附件的内容,而 send_markdown() 方法则使用上面的 text 变量作为消息的正文。
WeChatSend(AllureFileClean().get_case_count()).send_markdown(text)
other_tools # 其他工具类
allure_data # allure封装
allure_report_data.py # allure报告数据清洗
详细讲解
"""
描述: 收集 allure 报告
"""
import json
from typing import List, Text
from common.setting import ensure_path_sep
from utils.read_files_tools.get_all_files_path import get_all_files
from utils.other_tools.models import TestMetrics
# 定义了一个名为 AllureFileClean 的类
class AllureFileClean:
"""allure 报告数据清洗,提取业务需要得数据"""
# @classmethod 是 Python 中的一个装饰器,用来指示一个类方法。类方法与实例方法的不同之处在于,类方法第一个参数必须是类本身,Python 会自动传入该参数,通常命名为 cls,而不是 self,这也是 @classmethod 装饰器的作用之一。通过类名可以直接调用类方法,而不需要实例化对象。
@classmethod
# 使用了一个类装饰器 cls,其返回值是一个列表,该列表中的元素是一个测试用例数据。
def get_testcases(cls) -> List:
""" 获取所有 allure 报告中执行用例的情况"""
# 创建一个空列表 files 用于存放读取到的测试用例数据。
files = []
# 使用 get_all_files 函数来获取所有测试用例文件的路径,并通过迭代器 for 循环遍历每个路径。ensure_path_sep 函数将文件路径格式化为当前操作系统的标准格式(加上 \ 或 / 等分隔符),以确保路径可用。
for i in get_all_files(ensure_path_sep("\\report\\html\\data\\test-cases")):
# 使用 Python 的 with 语句打开测试用例文件,并赋值给变量 file,指定使用 utf-8 编码方式打开文件。
with open(i, 'r', encoding='utf-8') as file:
# 从打开的文件中读取 JSON 数据,并使用 json.load 函数将其加载到 date 变量中。
date = json.load(file)
# 将从文件中获取的数据 date 添加到 files 列表中。
files.append(date)
# 当获取所有测试用例文件的数据后,返回 files 列表作为结果,结束 get_testcases 方法的执行。
return files
# 总的来说,这段代码的作用是遍历指定路径下的所有测试用例文件,将其中的 JSON 数据提取出来,并将所有数据放入列表 files 中,最后返回该列表。这个过程可以以简单而灵活的方式提取并汇总数据,方便后续的数据处理和分析。
# 定义了一个名为 get_failed_case 的方法,返回一个 List 类型对象。
def get_failed_case(self) -> List:
""" 获取到所有失败的用例标题和用例代码路径"""
# 创建一个名为 error_case 的空列表,用于存储所有失败和中断的测试用例的标题和代码路径。
error_case = []
# 使用 for 循环遍历所有测试用例数据(该方法调用了 get_testcases 函数来获取测试用例数据列表,这个函数我们前面已经讲过)。
for i in self.get_testcases():
# 对于每个测试用例数据,如果它的执行状态为 'failed' 或 'broken',则将其标题和代码路径作为元组 (title, path) 添加到 error_case 列表中。
if i['status'] == 'failed' or i['status'] == 'broken':
error_case.append((i['name'], i['fullName']))
# 当循环遍历完所有测试用例数据,返回 error_case 列表作为结果。
return error_case
# 定义了一个名为 get_failed_cases_detail 的方法,返回一个 Text 类型(即 str 类型)对象。
def get_failed_cases_detail(self) -> Text:
""" 返回所有失败的测试用例相关内容 """
# 调用 get_failed_case 方法获取所有失败和中断的测试用例的标题和代码路径。
date = self.get_failed_case()
# 创建一个空字符串变量 values,用于拼接所有失败用例的详细信息。
values = ""
# 如果存在失败用例,则将 values 设置为 失败用例:\n,表示下面的字符串是所有失败用例的详细信息。
if len(date) >= 1:
values = "失败用例:\n"
# 添加一行格式化的分隔符,用于区分每个测试用例的详细信息
values += " **********************************\n"
# 遍历所有失败和中断的测试用例数据,对于每个测试用例数据,将其标题和代码路径拼接成字符串,并添加到 values 变量中。
for i in date:
values += " " + i[0] + ":" + i[1] + "\n"
# 当循环遍历完所有失败和中断的测试用例数据后,返回 values,即所有失败用例的详细信息字符串。
return values
@classmethod
# get_case_count 的类方法,用于统计用例的数量和成功率。
def get_case_count(cls) -> "TestMetrics":
""" 统计用例数量 """
# 用 try 语句块来处理可能抛出的异常情况。
try:
# 定义变量 file_name 来保存所有测试用例执行结果的统计数据路径,确保文件路径的结尾符为 / 。
file_name = ensure_path_sep("/report/html/widgets/summary.json")
# 使用 with 语句打开文件并读取 JSON 数据,确保文件以 utf-8 编码打开。
with open(file_name, 'r', encoding='utf-8') as file:
# 使用 json.load 加载文件数据为 Python 对象,并保存到变量 data 中。
data = json.load(file)
# 获取统计数据中的用例总数。
_case_count = data['statistic']
# # 获取统计数据中的测试执行时间。
_time = data['time']
# 创建集合 keep_keys 来存储要保留的统计数据键名。
keep_keys = {"passed", "failed", "broken", "skipped", "total"}
# 使用字典推导式,将 _case_count 子字典中存在于 keep_keys 集合中的键名和对应的值,在新的字典 run_case_data 中保存下来。
run_case_data = {k: v for k, v in data['statistic'].items() if k in keep_keys}
# 判断运行用例总数大于0则执行下面代码块
if _case_count["total"] > 0:
# 计算测试用例的通过率,并将其存储在run_case_data["pass_rate"]键中,保留两位小数。
run_case_data["pass_rate"] = round(
(_case_count["passed"] + _case_count["skipped"]) / _case_count["total"] * 100, 2
)
else:
# 如果没有运行的用例,则将通过率设置为0.0。
run_case_data["pass_rate"] = 0.0
# 如果测试用例总数为0,则将时间数据存储在run_case_data['time']键中,否则将运行时间除以1000,保留两位小数,并将其存储在run_case_data['time']键中。
run_case_data['time'] = _time if run_case_data['total'] == 0 else round(_time['duration'] / 1000, 2)
# 使用run_case_data创建一个TestMetrics对象,并将其作为函数的返回值。
return TestMetrics(**run_case_data)
# 如果读取文件时出现FileNotFoundError异常,则捕获该异常并将其存储在exc中。
except FileNotFoundError as exc:
# 从exc中重新抛出一个FileNotFoundError异常,并将新异常的说明文本存储在异常对象实例中。
raise FileNotFoundError(
"程序中检查到您未生成allure报告,"
"通常可能导致的原因是allure环境未配置正确"
) from exc
allure_tools.py # allure 方法封装
详细讲解
import json
import allure
from utils.other_tools.models import AllureAttachmentType
# 定义了一个名为allure_step的函数,它接受两个字符串参数step和var,并不返回任何内容(返回值为None)。
def allure_step(step: str, var: str) -> None:
"""
:param step: 步骤及附件名称
:param var: 附件内容
"""
# 定义一个名为step的allure步骤,包含了需要记录的步骤信息。
with allure.step(step):
# 把一个JSON字符串作为附件附加到allure报告的当前步骤中。其中,json.dumps()函数将var对象转换为JSON字符串,然后使用allure.attach()函数将它作为JSON附件附加到报告中。该函数还指定了所附加的附件类型(JSON)。
allure.attach(
json.dumps(
str(var),
ensure_ascii=False,
indent=4),
step,
allure.attachment_type.JSON)
# 定义了一个名为allure_attach的函数,它接受三个参数source、name和extension,不返回任何内容(返回值为None)。
def allure_attach(source: str, name: str, extension: str):
"""
allure报告上传附件、图片、excel等
:param source: 文件路径,相当于传一个文件
:param name: 附件名称
:param extension: 附件的拓展名称
:return:
"""
# 获取name参数的拓展名,并转换为大写字母。
_name = name.split('.')[-1].upper()
# 从AllureAttachmentType枚举中获取与拓展名匹配的枚举值,如果找到了,则将它存储在变量_attachment_type中,否则将_attachment_type设置为None。
_attachment_type = getattr(AllureAttachmentType, _name, None)
# 附加一个文件到allure报告中。使用source参数指定文件路径,使用name参数指定文件名,使用attachment_type参数指定文件类型,使用extension参数指定文件的扩展名。
allure.attach.file(
source=source,
name=name,
attachment_type=_attachment_type if _attachment_type is None else _attachment_type.value,
extension=extension
)
# 定义了一个名为allure_step_no的函数,它接受一个字符串参数step,不返回任何内容(返回值为None)。
def allure_step_no(step: str):
"""
无附件的操作步骤
:param step: 步骤名称
:return:
"""
# 定义一个名为step的allure步骤,包含了需要记录的步骤信息。
with allure.step(step):
# 这个代码块为空,因此不执行任何操作。
pass
error_case_excel.p # 收集allure异常用例,生成excel测试报告
详细讲解
import json
import shutil
import ast
import xlwings
from common.setting import ensure_path_sep
from utils.read_files_tools.get_all_files_path import get_all_files
from utils.notify.wechat_send import WeChatSend
from utils.other_tools.allure_data.allure_report_data import AllureFileClean
# TODO 还需要处理动态值
# 定义一个名为ErrorTestCase的类。
class ErrorTestCase:
""" 收集错误的excel """
# 定义一个名为__init__的方法,用于初始化对象,并接受一个默认参数self。
def __init__(self):
# 设置test_case_path属性,将其初始化为\report\html\data\test-cases\字符串。ensure_path_sep函数可能会在字符串结尾添加路径分隔符("/")或者"",以保证路径的完整性。
self.test_case_path = ensure_path_sep("\\report\\html\\data\\test-cases\\")
# 定义一个名为get_error_case_data的方法,用于获取失败用例的数据,其中self参数是该类的实例本身。
def get_error_case_data(self):
"""
收集所有失败用例的数据
@return:
"""
# 调用名为get_all_files的函数,传入test_case_path属性作为参数,获取该路径下的所有文件路径并返回path。
path = get_all_files(self.test_case_path)
# 创建一个空的列表files,用于存储所有执行失败的用例数据。
files = []
# 遍历path列表。
for i in path:
# 用"r"模式打开文件路径i,命名为file。encoding='utf-8'指定打开文件的字符编码,这里使用utf-8格式打开文件。
with open(i, 'r', encoding='utf-8') as file:
# 用json.load()方法从文件file中读取内容,并将读取的内容存储在date变量中。
date = json.load(file)
# 使用if语句判断读取的内容中的状态是否为failed或者broken,如果是则进入if语句块。
if date['status'] == 'failed' or date['status'] == 'broken':
# 将符合条件的date添加到files列表中。
files.append(date)
# 打印files列表中收集到的所有执行失败的用例数据。
print(files)
# 返回files列表。
return files
@classmethod
# 定义一个名为get_case_name的方法,并且该方法接受两个参数,一个是cls表示该方法属于该类,第二个参数是test_case,表示要处理的测试用例。
def get_case_name(cls, test_case):
"""
收集测试用例名称
@return:
"""
# 获取测试用例字典中的name属性,通过字符串的split()方法,按照'['进行分割,并且将分割后的结果存储在name列表中。
name = test_case['name'].split('[')
# 获取列表中的第二个元素,并使用切片操作去掉该元素的最后一个字符']',将获取到的值存储在case_name变量中。
case_name = name[1][:-1]
# 返回得到的测试用例名称。
return case_name
@classmethod
# 定义了一个名为get_parameters的方法,用于获取allure报告中parameters参数中的内容,即请求前的数据。如果测试用例未发送请求导致异常情况,则该函数用于依然能够处理该用例。
def get_parameters(cls, test_case):
"""
获取allure报告中的 parameters 参数内容, 请求前的数据
用于兼容用例执行异常,未发送请求导致的情况
@return:
"""
# 获取测试用例字典中的parameters参数的第一个字典中的value属性。
parameters = test_case['parameters'][0]['value']
# 通过ast.literal_eval()方法对parameters进行字面上的评估,将字符串转换为相应的Python数据类型并进行返回。这里的parameters是一个字符串形式的dict类型,使用该方法能够将其转化为Python的dict类型,以方便处理。
return ast.literal_eval(parameters)
@classmethod
# 定义了一个名为get_test_stage的方法,用于获取allure报告中请求后的数据。
def get_test_stage(cls, test_case):
"""
获取allure报告中请求后的数据
@return:
"""
# 获取测试用例字典中的testStage字典中的steps属性,并将其存储在test_stage变量中。
test_stage = test_case['testStage']['steps']
# 将获取到的测试步骤数据进行返回。
return test_stage
# 定义了一个名为get_case_url的方法,用于获取测试用例的url
def get_case_url(self, test_case):
"""
获取测试用例的 url
@param test_case:
@return:
"""
# 如果测试用例的状态为broken,即测试用例的步骤数据异常。
if test_case['testStage']['status'] == 'broken':
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出url属性的值,然后将其存储到_url变量中。
_url = self.get_parameters(test_case)['url']
# 如果测试用例的状态不为broken。
else:
# 调用get_test_stage方法获取测试用例请求后的数据,然后从中取出倒数第七个步骤的name属性的值的子串,存储在_url变量中。
_url = self.get_test_stage(test_case)[-7]['name'][7:]
# 将获取到的url数据进行返回。
return _url
# 定义了一个名为get_method的方法,用于获取测试用例的请求方式。
def get_method(self, test_case):
"""
获取用例中的请求方式
@param test_case:
@return:
"""
# 如果测试用例的状态为broken,即测试用例的步骤数据异常。
if test_case['testStage']['status'] == 'broken':
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出method属性的值,然后将其存储到_method变量中。
_method = self.get_parameters(test_case)['method']
# 如果测试用例的状态不为broken。
else:
# 调用get_test_stage方法获取测试用例请求后的数据,然后从中取出倒数第六个步骤的name属性的值的子串,存储在_method变量中。
_method = self.get_test_stage(test_case)[-6]['name'][6:]
# 将获取到的请求方式进行返回。
return _method
# 定义了一个名为get_headers的方法,用于获取测试用例的请求头信息。
def get_headers(self, test_case):
"""
获取用例中的请求头
@return:
"""
# 如果测试用例的状态为broken,即测试用例的步骤数据异常。
if test_case['testStage']['status'] == 'broken':
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出headers属性的值,然后将其存储到_headers变量中。
_headers = self.get_parameters(test_case)['headers']
# 如果测试用例的状态不为broken。
else:
# 从测试用例请求后的数据中取出倒数第五个步骤的attachments属性的第一个元素,从中取出source属性的值,即请求头附件的文件名。
_headers_attachment = self.get_test_stage(test_case)[-5]['attachments'][0]['source']
# 拼接请求头附件文件的完整路径,并将其存储到path变量中。
path = ensure_path_sep("\\report\\html\\data\\attachments\\" + _headers_attachment)
# 打开该文件,并将其存储到file变量中。
with open(path, 'r', encoding='utf-8') as file:
# 读取file变量中的JSON格式内容,并将其存储到_headers变量中。
_headers = json.load(file)
# 将获取到的请求头内容进行返回。
return _headers
# 定义了一个名为get_request_type的方法,用于获取测试用例的请求类型。
def get_request_type(self, test_case):
"""
获取用例的请求类型
@param test_case:
@return:
"""
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出requestType属性的值,并将其存储在request_type变量中。
request_type = self.get_parameters(test_case)['requestType']
# 将获取到的请求类型进行返回。
return request_type
# 定义了一个名为get_case_data的方法,用于获取测试用例的请求体内容。
def get_case_data(self, test_case):
"""
获取用例内容
@return:
"""
# 如果测试用例的状态为broken,即测试用例的步骤数据异常。
if test_case['testStage']['status'] == 'broken':
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出data属性的值,然后将其存储到_case_data变量中。
_case_data = self.get_parameters(test_case)['data']
# 如果测试用例的状态不为broken。
else:
# 从测试用例请求后的数据中取出倒数第四个步骤的attachments属性的第一个元素,从中取出source属性的值,即请求体附件的文件名。
_case_data_attachments = self.get_test_stage(test_case)[-4]['attachments'][0]['source']
# 拼接请求体附件文件的完整路径,并将其存储到path变量中。
path = ensure_path_sep("\\report\\html\\data\\attachments\\" + _case_data_attachments)
# 打开该文件,并将其存储到file变量中。
with open(path, 'r', encoding='utf-8') as file:
# 读取file变量中的JSON格式内容,并将其存储到_case_data变量中。
_case_data = json.load(file)
# 将获取到的请求体内容进行返回。
return _case_data
# 定义了一个名为get_dependence_case的方法,用于获取测试用例的依赖用例信息。
def get_dependence_case(self, test_case):
"""
获取依赖用例
@param test_case:
@return:
"""
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出dependence_case_data属性的值,并将其存储在_dependence_case_data变量中。
_dependence_case_data = self.get_parameters(test_case)['dependence_case_data']
# 将获取到的依赖用例信息进行返回。
return _dependence_case_data
# 定义了一个名为get_sql的方法,用于获取测试用例的SQL语句。
def get_sql(self, test_case):
"""
获取 sql 数据
@param test_case:
@return:
"""
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出sql属性的值,并将其存储在sql变量中。
sql = self.get_parameters(test_case)['sql']
# 将获取到的SQL语句进行返回。
return sql
# 定义了一个名为get_assert的方法,用于获取测试用例的断言数据。
def get_assert(self, test_case):
"""
获取断言数据
@param test_case:
@return:
"""
# 调用get_parameters方法获取测试用例请求前的数据,再从中取出assert_data属性的值,并将其存储在assert_data变量中。
assert_data = self.get_parameters(test_case)['assert_data']
# 将获取到的断言数据进行返回。
return assert_data
@classmethod
# 定义一个名为get_response的方法,并且该方法接受两个参数,一个是cls,表示该方法是一个类方法,第二个参数是test_case,表示要处理的测试用例。
def get_response(cls, test_case):
"""
获取响应内容的数据
@param test_case:
@return:
"""
# 如果测试用例的状态为broken,代表该测试用例没有响应数据,将其状态信息作为响应内容。
if test_case['testStage']['status'] == 'broken':
# 将测试用例状态信息作为响应内容,并将其存储在_res_date变量中。
_res_date = test_case['testStage']['statusMessage']
# 如果测试用例状态不是broken,则尝试获取响应数据。
else:
try:
# 获取最后一步操作的附件中的响应数据路径。
res_data_attachments = \
test_case['testStage']['steps'][-1]['attachments'][0]['source']
# 拼接出响应数据的完整路径。
path = ensure_path_sep("\\report\\html\\data\\attachments\\" + res_data_attachments)
# 打开响应数据所在文件,读取其中的JSON数据,并将其赋值给_res_date变量。
with open(path, 'r', encoding='utf-8') as file:
_res_date = json.load(file)
# 如果找不到响应数据所在文件,则代表程序中没有提取到响应数据,将None赋值给_res_date变量。
except FileNotFoundError:
_res_date = None
# 将获取到的响应数据进行返回。
return _res_date
@classmethod
# 定义了一个名为get_case_time的类方法,用于获取测试用例的运行时长。
def get_case_time(cls, test_case):
"""
获取用例运行时长
@param test_case:
@return:
"""
# 获取测试用例运行时长,并将其单位转换为毫秒,并将其存储在case_time变量中。
case_time = str(test_case['time']['duration']) + "ms"
# 将获取到的运行时长进行返回。
return case_time
@classmethod
# 定义了一个名为get_uid的类方法,用于获取测试用例在Allure报告中的唯一标识符(uid)。
def get_uid(cls, test_case):
"""
获取 allure 报告中的 uid
@param test_case:
@return:
"""
# 获取测试用例的唯一标识符(uid),并将其存储在uid变量中。
uid = test_case['uid']
# 将获取到的uid进行返回。
return uid
# 定义了用于整理运行失败的测试用例成excel报告的方法
class ErrorCaseExcel:
""" 收集运行失败的用例,整理成excel报告 """
# 定义类的构造方法。
def __init__(self):
# 定义一个名为_excel_template的私有变量,表示excel模板文件的路径。
_excel_template = ensure_path_sep("\\utils\\other_tools\\allure_data\\自动化异常测试用例.xlsx")
# 定义一个名为self._file_path的变量,表示生成excel报告的文件路径。
self._file_path = ensure_path_sep("\\Files\\" + "自动化异常测试用例.xlsx")
# 将_excel_template模板文件复制到self._file_path路径下。
shutil.copyfile(src=_excel_template, dst=self._file_path)
# 创建一个Excel应用程序对象。
self.app = xlwings.App(visible=False, add_book=False)
# 打开excel报告文件,返回一个xlwings.Book对象。
self.w_book = self.app.books.open(self._file_path, read_only=False)
# 选取指定名称的工作表异常用例。
self.sheet = self.w_book.sheets['异常用例'] # 或通过索引选取
# 创建一个ErrorTestCase对象,用于收集运行失败的测试用例。
self.case_data = ErrorTestCase()
# 定义一个名为background_color的方法,参数是self,表示类的实例本身,position表示要设置背景颜色的单元格位置,rgb表示要设置的背景色的RGB值。
def background_color(self, position: str, rgb: tuple):
"""
excel 单元格设置背景色
@param rgb: rgb 颜色 rgb=(0,255,0)
@param position: 位置,如 A1, B1...
@return:
"""
# 获取工作表中指定位置的单元格范围对象。
rng = self.sheet.range(position)
# 设置单元格范围对象的颜色属性为RGB值rgb,并将值赋给变量excel_rgb。
excel_rgb = rng.color = rgb
# 将设置的颜色RGB值返回。
return excel_rgb
# 定义一个名为column_width的方法,参数是self,表示类的实例本身,position表示要设置列宽的列的位置(如"A","B"等),width表示要设置的列宽度。
def column_width(self, position: str, width: int):
"""
设置列宽
@return:
"""
# 获取工作表中指定列的范围对象。
rng = self.sheet.range(position)
# 将指定列的列宽设置为width,并将值赋给变量excel_column_width。
excel_column_width = rng.column_width = width
# 将设置的列宽度返回。
return excel_column_width
# 定义一个名为row_height的方法,参数是self,表示类的实例本身,position表示要设置行高的行的位置,height表示要设置的行高度。
def row_height(self, position, height):
"""
设置行高
@param position:
@param height:
@return:
"""
# 获取工作表中指定行的范围对象。
rng = self.sheet.range(position)
# 将指定行的行高设置为height,并将值赋给变量excel_row_height。
excel_row_height = rng.row_height = height
# 将设置的行高度返回。
return excel_row_height
# 定义一个名为column_width_adaptation的方法,参数是self,表示类的实例本身,position表示要进行宽度自适应的列的范围
def column_width_adaptation(self, position):
"""
excel 所有列宽度自适应
@return:
"""
# 获取工作表中指定范围的对象。
rng = self.sheet.range(position)
# 将该范围内所有列的宽度自适应调整。
auto_fit = rng.columns.autofit()
返回自适应后的结果。
return auto_fit
# 定义一个名为row_width_adaptation的方法,参数是self,表示类的实例本身,position表示要进行宽度自适应的行的范围。
def row_width_adaptation(self, position):
"""
excel 设置所有行宽自适应
@return:
"""
# 获取工作表中指定范围的对象。
rng = self.sheet.range(position)
# 将该范围内所有行的宽度自适应调整。
row_adaptation = rng.rows.autofit()
# 返回自适应后的结果。
return row_adaptation
# 定义一个名为write_excel_content的方法。参数是self,表示类的实例本身,position表示要写入的位置,value表示要写入的内容,均为字符串类型。
def write_excel_content(self, position: str, value: str):
"""
excel 中写入内容
@param value:
@param position:
@return:
"""
# 将给定位置的单元格赋值为给定的值。由于sheet是当前实例的一个属性,因此可以使用self.sheet来获取该工作表对象。range(position)表示获取给定位置的单元格对象,然后对其value属性进行赋值操作。
self.sheet.range(position).value = value
# 定义一个名为write_case的方法,参数是self,表示类的实例本身。
def write_case(self):
"""
用例中写入失败用例数据
@return:
"""
# 从case_data对象获取失败用例数据。
_data = self.case_data.get_error_case_data()
# 如果存在失败用例,则继续执行。
if len(_data) > 0:
# 设置行号开始的编号,默认从第二行开始。
num = 2
# 遍历失败用例数据。
for data in _data:
# 在第num行的“A”列中写入用例的唯一标识。
self.write_excel_content(position="A" + str(num), value=str(self.case_data.get_uid(data)))
# 在第num行的“B”列中写入用例的名称。
self.write_excel_content(position='B' + str(num), value=str(self.case_data.get_case_name(data)))
# 在第num行的“C”列中写入用例的 URL。
self.write_excel_content(position="C" + str(num), value=str(self.case_data.get_case_url(data)))
# 在第num行的“D”列中写入用例的请求方法名。
self.write_excel_content(position="D" + str(num), value=str(self.case_data.get_method(data)))
# 在第num行的“E”列中写入用例的请求类型。
self.write_excel_content(position="E" + str(num), value=str(self.case_data.get_request_type(data)))
# 在第num行的“F”列中写入用例的头部信息。
self.write_excel_content(position="F" + str(num), value=str(self.case_data.get_headers(data)))
# 在第num行的“G”列中写入用例的请求数据。
self.write_excel_content(position="G" + str(num), value=str(self.case_data.get_case_data(data)))
# 在第num行的“H”列中写入用例依赖的其他用例。
self.write_excel_content(position="H" + str(num), value=str(self.case_data.get_dependence_case(data)))
# 在第num行的“I”列中写入用例的断言信息。
self.write_excel_content(position="I" + str(num), value=str(self.case_data.get_assert(data)))
# 在第num行的“J”列中写入用例的 SQL 语句。
self.write_excel_content(position="J" + str(num), value=str(self.case_data.get_sql(data)))
# 在第num行的“K”列中写入用例的执行时间。
self.write_excel_content(position="K" + str(num), value=str(self.case_data.get_case_time(data)))
# 在第num行的“L”列中写入用例的响应信息。
self.write_excel_content(position="L" + str(num), value=str(self.case_data.get_response(data)))
# 将行号加一,以便写入下一个用例。
num += 1
# 保存文件修改。
self.w_book.save()
# 关闭工作簿。
self.w_book.close()
# 结束 Excel 进程。
self.app.quit()
# 通知企业微信发送文件消息,包括更新的用例数量和文件路径。
WeChatSend(AllureFileClean().get_case_count()).send_file_msg(self._file_path)
if __name__ == '__main__':
ErrorCaseExcel().write_case()
install_tool # 安装工具
install_requirements.py # 自动识别安装最新的依赖库
详细讲解
"""
# @describe: 判断程序是否每次会更新依赖库,如有更新,则自动安装
"""
import os
import chardet
from common.setting import ensure_path_sep
from utils.logging_tool.log_control import INFO
from utils import config
# 这是一个使用 os.system 命令来执行系统命令 pip3 install chardet 的语句。该语句用于在 Python 环境中通过 PyPI 安装 chardet 库。 os.system 函数将给定的字符串作为一个命令运行,并返回其执行结果。具体来说,pip3 是 Python3 中的包管理器工具,install 是 它的一个子命令,用于安装第三方库,而 chardet 则是要安装的库名。执行该语句将自动下载并安装 chardet 库,以便在 Python 中使用它的功能。
os.system("pip3 install chardet")
# 定义一个名为 InstallRequirements 的类。
class InstallRequirements:
""" 自动识别安装最新的依赖库 """
# 定义该类的构造函数,它将在创建类的新实例时自动调用。
def __init__(self):
# 设置 version_library_comparisons.txt 文件的路径。函数ensure_path_sep用于确保路径分隔符为正斜杠。
self.version_library_comparisons_path = ensure_path_sep("\\utils\\other_tools\\install_tool\\") \
# 设置 requirements.txt 文件的路径。该路径使用os模块函数os.path.dirname获取当前文件所在的目录两级上的目录(即项目的根目录),并拼接 os.sep 和文件名requirements.txt。 + "version_library_comparisons.txt"
self.requirements_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) \
+ os.sep + "requirements.txt"
# 从 config 中获取镜像 URL,该 URL 作为从镜像源下载软件包的基础 URL。
self.mirror_url = config.mirror_source
# 定义一个名为 read_version_library_comparisons_txt 的方法,它将从文件中读取字符串,并返回读取的内容。
def read_version_library_comparisons_txt(self):
"""
获取版本比对默认的文件
@return:
"""
# 使用 with 语句来安全地打开指定路径下的文件 version_library_comparisons.txt 并读取其内容。open() 函数的第一个参数是文件路径,第二个参数是打开文件的模式,r 代表只读模式,第三个参数是文件编码方式,这里是 utf-8。
with open(self.version_library_comparisons_path, 'r', encoding="utf-8") as file:
# 返回打开文件后读取的内容,并使用 strip 函数去除字符串开头和结尾的空格。
return file.read().strip(' ')
@classmethod
# 定义一个名为 check_charset 的类方法,它的第一个参数是 cls,指向当前类对象(而不是实例对象)。第二个参数是 file_path,表示要检查字符集的文件路径。
def check_charset(cls, file_path):
"""获取文件的字符集"""
# 使用 with 语句打开指定文件,并使用二进制模式(rb)打开文件。
with open(file_path, "rb") as file:
# 读取文件前四个字节的内容。这足以确定文件的编码方式,因为对于大多数文件来说,其编码方式信息包含在开头的几个字节中。
data = file.read(4)
# 使用 chardet 模块检测文件的编码方式,并将检测到的编码方式存储在 charset 变量中。
charset = chardet.detect(data)['encoding']
# 返回检测到的文件编码方式。
return charset
# 定义一个名为 read_requirements 的方法,它将读取指定文件的内容,并返回文件的内容。
def read_requirements(self):
"""获取安装文件"""
# 创建一个空字符串,用于存储文件内容。
file_data = ""
# 打开指定文件以读取其内容,并使用 with 语句确保安全关闭文件。 self.requirements_path 是文件的路径, r 表示以只读模式打开该文件, encoding 参数使用 check_charset 函数来确定文件的编码方式。
with open(
self.requirements_path,
'r',
encoding=self.check_charset(self.requirements_path)
) as file:
# 读取打开文件的每一行,将其作为 line 变量的值。
for line in file:
# 检查读取的行是否包含某个字符串“[0m”,并用空字符串替换该字符串。于是获得的新字符串添加到 file_data 字符串中。
if "[0m" in line:
line = line.replace("[0m", "")
file_data += line
# 重新打开指定文件以覆盖原始文件,然后将 file_data 中的内容写入文件,实现删除了 “[0m” 字符串的目的。
with open(
self.requirements_path,
"w",
encoding=self.check_charset(self.requirements_path)
) as file:
file.write(file_data)
# 返回读取的内容字符串。
return file_data
# 定义名为 text_comparison 的方法,其目的是检查库的依赖项是否有更新,并自动安装更新的依赖项。
def text_comparison(self):
"""
版本库比对
@return:
"""
# 使用 self.read_version_library_comparisons_txt() 方法读取存储了库依赖项版本信息的文件内容,并将其赋值给 read_version_library_comparisons_txt 变量(可能是一个字符串)。
read_version_library_comparisons_txt = self.read_version_library_comparisons_txt()
# 使用 self.read_requirements() 方法读取当前库依赖项的版本信息,并将其存储在 read_requirements 变量中。
read_requirements = self.read_requirements()
# 检查 read_version_library_comparisons_txt 变量和 read_requirements 变量是否相等。如果相等,则没有更新的库依赖项,并输出相关信息;否则,将进行安装更新。
if read_version_library_comparisons_txt == read_requirements:
INFO.logger.info("程序中未检查到更新版本库,已为您跳过自动安装库")
# 程序中如出现不同的文件,则安装
else:
INFO.logger.info("程序中检测到您更新了依赖库,已为您自动安装")
# 如果应用程序中存在版本差异,则使用 os.system 方法调用 pip3 安装库依赖项。
os.system(f"pip3 install -r {self.requirements_path}")
# 更新依赖项库版本信息文件,将当前库依赖项写入文件以供比较使用。
with open(self.version_library_comparisons_path, "w",
encoding=self.check_charset(self.requirements_path)) as file:
file.write(read_requirements)
version_library_comparisons.txt # 依赖
aiofiles==0.8.0
allure-pytest==2.9.45
allure-python-commons==2.9.45
asgiref==3.5.1
atomicwrites==1.4.0
attrs==21.2.0
blinker==1.4
Brotli==1.0.9
certifi==2021.10.8
cffi==1.15.0
chardet==4.0.0
charset-normalizer==2.0.7
click==8.1.3
colorama==0.4.4
colorlog==6.6.0
cryptography==36.0.0
DingtalkChatbot==1.5.3
et-xmlfile==1.1.0
execnet==1.9.0
Faker==9.8.3
Flask==2.0.3
h11==0.13.0
h2==4.1.0
hpack==4.0.0
httptools==0.4.0
hyperframe==6.0.1
idna==3.3
iniconfig==1.1.0
itchat==1.3.10
itsdangerous==2.1.2
Jinja2==3.1.2
jsonpath==0.82
kaitaistruct==0.9
ldap3==2.9.1
MarkupSafe==2.1.1
mitmproxy==8.0.0
msgpack==1.0.3
multidict==6.0.2
openpyxl==3.0.9
packaging==21.3
passlib==1.7.4
pluggy==1.0.0
protobuf==3.19.4
publicsuffix2==2.20191221
py==1.11.0
pyasn1==0.4.8
pycparser==2.21
pydivert==2.1.0
PyMySQL==1.0.2
pyOpenSSL==21.0.0
pyparsing==3.0.6
pyperclip==1.8.2
pypng==0.0.21
PyQRCode==1.2.1
pytest==6.2.5
pytest-forked==1.3.0
pytest-xdist==2.4.0
python-dateutil==2.8.2
pywin32==304
PyYAML==6.0
requests==2.26.0
requests-toolbelt==0.9.1
ruamel.yaml==0.17.21
ruamel.yaml.clib==0.2.6
sanic==22.3.1
sanic-routing==22.3.0
six==1.16.0
sortedcontainers==2.4.0
text-unidecode==1.3
toml==0.10.2
tornado==6.1
urllib3==1.26.7
urwid==2.1.2
websockets==10.3
Werkzeug==2.1.2
wsproto==1.1.0
xlrd==2.0.1
xlutils==2.0.0
xlwings==0.27.7
xlwt==1.3.0
zstandard==0.17.0
exceptions.py # 自定义异常类
详细讲解
# MyBaseFailure 类是一个基本的异常类,其他的异常都是它的子类,继承了它的特性和方法,如异常处理和错误信息的输出等。
class MyBaseFailure(Exception):
pass
# 这个异常类是用来描述 Jsonpath 提取失败的情况。
class JsonpathExtractionFailed(MyBaseFailure):
pass
# 这个异常类是用来表示由于某些原因找不到其所需的值而导致的“未找到”错误。
class NotFoundError(MyBaseFailure):
pass
# 这个异常类是 FileNotFoundError 和 NotFoundError 两个异常类的子类。它是用来描述文件未找到时的情况。
class FileNotFound(FileNotFoundError, NotFoundError):
pass
# 这个异常类是 NotFoundError 类的子类。它是用来描述在处理 SQL 数据时未找到数据表、字段或行的情况。
class SqlNotFound(NotFoundError):
pass
# 这个异常类是用来描述断言失败的情况,即函数或方法的返回值与预期值不一致的情况。
class AssertTypeError(MyBaseFailure):
pass
# 这个异常类是用来描述数据获取失败的情况。
class DataAcquisitionFailed(MyBaseFailure):
pass
# 这个异常类是用来描述变量或函数参数类型错误的情况。
class ValueTypeError(MyBaseFailure):
pass
# 这个异常类是用来描述发送消息失败的情况,例如在发送邮件或短信时出错。
class SendMessageError(MyBaseFailure):
pass
# 这个异常类是用来描述在处理请求或操作时未找到所需值的情况。
class ValueNotFoundError(MyBaseFailure):
pass
get_local_ip.py # 获取本地IP
详细讲解
import socket
# 定义一个名为 get_host_ip 的函数。
def get_host_ip():
"""
查询本机ip地址
:return:
"""
# 初始化一个变量 '_s' ,并将其值置为 None。
_s = None
try:
# # 使用 Python 标准库中的 socket 模块创建一个 socket 对象 _s。其中 socket.AF_INET 表示建立面向 IPv4 的网络套接字, socket.SOCK_DGRAM 表示该套接字是数据报类型。接着,使用 connect 方法将 socket 对象 _s 连接到 ('8.8.8.8', 80) 这个公共 DNS 服务器。然后,使用 getsockname() 方法获取本机的 IP 地址,用变量 l_host 保存。
_s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
_s.connect(('8.8.8.8', 80))
l_host = _s.getsockname()[0]
# finally 语句块中关闭 socket 连接,确保资源释放。
finally:
_s.close()
# 返回 l_host,本机 IP 地址。
return l_host
jsonpath_date_replace.py # 处理jsonpath数据
详细讲解
# 定义一个名为 jsonpath_replace 的函数,该函数接受三个参数,分别是 change_data、 key_name 和 data_switch,用于处理 JSONPath 数据。
def jsonpath_replace(change_data, key_name, data_switch=None):
"""处理jsonpath数据"""
# 定义 _new_data 变量,初始值为 key_name 与一个空字符串拼接。
_new_data = key_name + ''
# 使用 for 循环遍历 change_data 变量中的每一个元素,i 是遍历时用于找到元素的迭代变量。
for i in change_data:
# 如果检测到 JSONPath 路径中存在 $,则什么都不做,直接跳过。
if i == '$':
pass
# 如果 data_switch 为 None 并且元素为 "data",则在 _new_data 的后面追加一个字符串 '.data' 。
elif data_switch is None and i == "data":
_new_data += '.data'
# 如果检测到元素是索引(即 i 表示一个列表元素),则在 _new_data 的后面追加一对方括号和 /i[1:-1]/。
elif i[0] == '[' and i[-1] == ']':
_new_data += "[" + i[1:-1] + "]"
# 如果是「非索引形式」的元素,则在 _new_data 的后面追加一对方括号和引号组成的字符串 /"/i/"/(即元素 i 用引号括起来)。
else:
_new_data += '[' + '"' + i + '"' + "]"
# 返回最终的 _new_data 变量,其中包含了处理后的字符串形式的 JSONPath。
return _new_data
models.py # 定义类和枚举变量
详细讲解
import types
from enum import Enum, unique
from typing import Text, Dict, Callable, Union, Optional, List, Any
from dataclasses import dataclass
from pydantic import BaseModel
# 定义一个 NotificationType 枚举类。
class NotificationType(Enum):
""" 自动化通知方式 """
# 定义了5个枚举常量,分别对应自动化通知的5种方式,每个枚举常量都由名称和值组成。这里的值表示通知方式的代号,名称则表述了该通知方式的语义。
DEFAULT = '0'
DING_TALK = '1'
WECHAT = '2'
EMAIL = '3'
FEI_SHU = '4'
# 使用装饰器 @dataclass 定义一个数据类 TestMetrics,该数据类包含了多个测试数据指标。
@dataclass
class TestMetrics:
""" 用例执行数据 """
# 使用 docstring 注释对数据类进行描述,表明该数据类用于表示用例执行数据。
passed: int # 表示通过的测试用例数
failed: int # 表示失败的测试用例数
broken: int # 表示中断的测试用例数
skipped: int # 表示跳过的测试用例数
total: int # 表示总共的测试用例数
pass_rate: float # 表示测试通过率
time: Text # 表示测试执行的时间
# 定义一个 RequestType 枚举类。
class RequestType(Enum):
"""
request请求发送,请求参数的数据类型
"""
# 使用 docstring 注释对枚举类进行描述,表明该枚举类用于定义请求参数的数据类型。定义了6个枚举常量,分别对应请求参数的6种数据类型。每个枚举常量都由名称和值组成。这里的值是字符串类型,表示不同的数据类型。
JSON = "JSON"
PARAMS = "PARAMS"
DATA = "DATA"
FILE = 'FILE'
EXPORT = "EXPORT"
NONE = "NONE"
# 定义一个 TestCaseEnum 枚举类。
class TestCaseEnum(Enum):
# 定义了多个枚举常量,每个枚举常量都是一个元组类型,由两个元素组成。第一个元素表示测试用例中对应的字段名称,第二个元素表示该字段是否必需。
URL = ("url", True)
HOST = ("host", True)
METHOD = ("method", True)
DETAIL = ("detail", True)
IS_RUN = ("is_run", True)
HEADERS = ("headers", True)
REQUEST_TYPE = ("requestType", True)
DATA = ("data", True)
DE_CASE = ("dependence_case", True)
DE_CASE_DATA = ("dependence_case_data", False)
CURRENT_RE_SET_CACHE = ("current_request_set_cache", False)
SQL = ("sql", False)
ASSERT_DATA = ("assert", True)
SETUP_SQL = ("setup_sql", False)
TEARDOWN = ("teardown", False)
TEARDOWN_SQL = ("teardown_sql", False)
SLEEP = ("sleep", False)
# 定义一个 Method 枚举类。
class Method(Enum):
# 定义了7个枚举常量,每个常量都代表一个 HTTP 请求方法。常量名称即为请求方法名,常量值为对应的字符串类型的请求方法。
GET = "GET"
POST = "POST"
PUT = "PUT"
PATCH = "PATCH"
DELETE = "DELETE"
HEAD = "HEAD"
OPTION = "OPTION"
# 定义了一个名为 load_module_functions 的函数,输入参数 module 为要处理的 Python 模块,函数返回值为一个字典类型,其中键为函数名称,值为函数所在的内存地址。
def load_module_functions(module) -> Dict[Text, Callable]:
""" 获取 module中方法的名称和所在的内存地址 """
# 先初始化一个名为 module_functions 的空字典。
module_functions = {}
# 使用内置函数 vars() 取出 module 模块中的所有属性,将其转换为字典类型,并使用 for 循环遍历其中的每一项。若遍历到的属性类型为函数类型,则将其加入到 module_functions 字典中,键为函数名称,值为函数所在的内存地址。
for name, item in vars(module).items():
if isinstance(item, types.FunctionType):
module_functions[name] = item
# 将 module_functions 字典作为函数返回值返回。
return module_functions
# 定义了一个 DependentType 枚举类,使用装饰器 @unique 来保证枚举常量的唯一性。
@unique
class DependentType(Enum):
"""
数据依赖相关枚举
"""
# 定义了4个枚举常量,常量名称即为相关数据的依赖类型,常量值为对应的字符串类型的依赖类型。
RESPONSE = 'response'
REQUEST = 'request'
SQL_DATA = 'sqlData'
CACHE = "cache"
# 定义了一个名为 Assert 的数据类,它继承了 BaseModel 类,即 Assert 类具有了 BaseModel 类的所有属性和方法。
class Assert(BaseModel):
# 定义了 Assert 类的4个属性。其中,jsonpath 的类型为 Text,表示 JSON 路径;type 的类型为 Text,表示数据的类型;value 的类型为 Any,表示数据的值;AssertType 的类型为 Union[None, Text],表示断言类型。
jsonpath: Text
type: Text
value: Any
AssertType: Union[None, Text] = None
# 此数据类 Assert 的作用是定义一个测试断言模型,其中 jsonpath 表示需要测试的数据在 JSON 文件中的路径,value 表示需要测试的数据的具体值,type 表示需要测试的数据的类型,例如字符串、数字等,AssertType 表示测试断言的类型,例如等于断言、不等断言等。使用数据类可以更加方便地处理这些数据,并在使用时有更好的类型提示和验证。
# 定义了一个名为 DependentData 的数据类,它同样继承了 BaseModel 类,即 DependentData 类也具有了 BaseModel 类的所有属性和方法。
class DependentData(BaseModel):
# 定义了 DependentData 类的4个属性。其中,dependent_type 的类型为 Text,表示依赖的数据类型;jsonpath 的类型为 Text,表示依赖数据在 JSON 文件中的路径;set_cache 的类型为 Optional[Text],表示需要将依赖数据缓存,可选参数;replace_key 的类型为 Optional[Text],表示需要替换的依赖数据在 JSON 文件中的路径,可选参数。
dependent_type: Text
jsonpath: Text
set_cache: Optional[Text]
replace_key: Optional[Text]
# 此数据类 DependentData 的作用是定义测试用例中的数据依赖模型,其中 dependent_type 表示数据依赖类型,例如响应数据、请求数据等;jsonpath 表示需要依赖的数据在 JSON 文件中的路径;set_cache 表示依赖数据是否需要进行缓存;replace_key 表示需要替换的依赖数据在 JSON 文件中的路径。使用数据类可以更加方便地处理这些数据,并在使用时有更好的类型提示和验证。
# 定义了一个名为 DependentCaseData 的数据类,它继承了 BaseModel 类,即 DependentCaseData 类也具有了 BaseModel 类的所有属性和方法。
class DependentCaseData(BaseModel):
# 定义了 DependentCaseData 类的2个属性。其中,case_id 的类型为 Text,表示测试用例的 ID;dependent_data 的类型为 Union[None, List[DependentData]],表示测试用例所依赖的数据,可选参数,数据类型为 DependentData 列表。
case_id: Text
dependent_data: Union[None, List[DependentData]] = None
# 此数据类 DependentCaseData 的作用是定义测试用例所依赖的数据模型,其中 case_id 表示测试用例的 ID,dependent_data 表示测试用例所依赖的数据,可能有多个依赖数据,所以使用列表存储。DependentCaseData 数据类的属性 dependent_data 是一个可选参数,因为可能存在某些测试用例不需要依赖数据的情况。
# 定义了一个名为 ParamPrepare 的数据类,它继承了 BaseModel 类,即 ParamPrepare 类也具有了 BaseModel 类的所有属性和方法。
class ParamPrepare(BaseModel):
# 定义了 ParamPrepare 类的3个属性。其中,dependent_type 的类型为 Text,表示依赖的数据类型;jsonpath 的类型为 Text,表示需要依赖数据在 JSON 文件中的路径;set_cache 的类型为 Text,表示需要将依赖数据进行缓存。
dependent_type: Text
jsonpath: Text
set_cache: Text
# 此数据类 ParamPrepare 的作用是定义 API 的参数准备数据模型,其中 dependent_type 表示参数依赖的数据类型,例如响应数据、请求数据等;jsonpath 表示需要依赖的数据在 JSON 文件中的路径;set_cache 表示依赖数据是否需要进行缓存。使用数据类可以更加方便地处理这些数据,并在使用时有更好的类型提示和验证。
# 定义了一个名为 SendRequest 的数据类,它继承了 BaseModel 类,即 SendRequest 类也具有了 BaseModel 类的所有属性和方法。
class SendRequest(BaseModel):
# 定义了 SendRequest 类的5个属性。其中,dependent_type 的类型为 Text,表示依赖的数据类型;jsonpath, cache_data, set_cache, 和 replace_key 的类型均为可选的 Optional[Text]。
dependent_type: Text
jsonpath: Optional[Text]
cache_data: Optional[Text]
set_cache: Optional[Text]
replace_key: Optional[Text]
# 此数据类 SendRequest 的作用是定义 API 请求数据模型,其中 dependent_type 表示参数依赖的数据类型,例如响应数据、请求数据等;jsonpath 表示需要从依赖数据中提取的数据在 JSON 文件中的路径,由于该属性为可选参数,所以不一定所有的请求都需要依赖数据;cache_data 表示需要缓存的数据;set_cache 表示缓存的数据是否需要进行缓存,并可以为空;replace_key 表示需要替换的数据键名。
# 定义了一个名为 TearDown 的数据类,它继承了 BaseModel 类,即 TearDown 类也具有了 BaseModel 类的所有属性和方法。
class TearDown(BaseModel):
# 定义了 TearDown 类的3个属性。其中,case_id 的类型为 Text,表示测试用例的 ID;param_prepare 和 send_request 的类型均为可选参数的列表类型,其中 param_prepare 表示参数准备数据模型的列表,send_request 表示 API 请求数据模型的列表。
case_id: Text
param_prepare: Optional[List["ParamPrepare"]]
send_request: Optional[List["SendRequest"]]
# 此数据类 TearDown 的作用是定义 API 测试用例的后置条件数据模型,其中 case_id 表示测试用例的 ID;param_prepare 表示测试用例后置条件中所需的参数准备数据模型列表,它是可选参数,因为不是所有的测试用例都需要参数准备;send_request 则表示测试用例后置条件中 API 请求数据模型的列表,同样是可选参数。使用数据类可以更加方便地处理这些数据,并在使用时有更好的类型提示和验证,从而减少代码出错的可能。
# 定义了一个名为 CurrentRequestSetCache 的数据类,它继承了 BaseModel 类,即 CurrentRequestSetCache 类也具有了 BaseModel 类的所有属性和方法。
class CurrentRequestSetCache(BaseModel):
# 定义了 CurrentRequestSetCache 类的3个属性。其中,type、jsonpath 和 name 的类型均为 Text,其中 type 表示当前缓存的类型,具体包括 response 和 request;jsonpath 表示需要从返回结果中提取的数据在 JSON 文件中的路径;name 表示需要缓存的数据的名称。
type: Text
jsonpath: Text
name: Text
# 此数据类 CurrentRequestSetCache 的作用是定义 API 请求数据模型中当前请求需要缓存的数据模型,其中 type 表示缓存的类型,具体包括响应和请求;jsonpath 表示需要从响应结果或请求参数中提取的数据的路径,它是需要自己定义的;name 则表示缓存数据的名称。使用数据类可以更加方便地处理这些数据,并在使用时有更好的类型提示和验证,从而减少代码出错的可能。
# 定义了一个名为 TestCase 的数据类,它同样是继承自 BaseModel 类,即 TestCase 类也具有了 BaseModel 类的所有属性和方法。
class TestCase(BaseModel):
url: Text # 表示 API 的请求地址
method: Text # 表示请求方式,例如 GET、POST 等
detail: Text # 表示测试用例的详细信息
assert_data: Union[Dict, Text] # 表示需要进行断言的数据,可能为字典类型,也可能为文本类型
headers: Union[None, Dict, Text] = {} # 表示请求头,它是可选参数,默认值为空字典
requestType: Text # 表示请求的数据类型,例如 json、form data 等
is_run: Union[None, bool, Text] = None # 表示是否需要运行该测试用例,它是可选参数,默认值为 None
data: Any = None # 表示请求体数据,它是可选参数
dependence_case: Union[None, bool] = False # 表示该测试用例是否依赖其他用例,默认为 False
dependence_case_data: Optional[Union[None, List["DependentCaseData"], Text]] = None # 表示该测试用例依赖的其他用例的数据列表,默认为 None
sql: List = None # 表示该测试用例执行前需要执行的 SQL 语句列表,它是可选参数
setup_sql: List = None # 表示该测试用例执行完后需要执行的 SQL 语句列表,它是可选参数
status_code: Optional[int] = None # 表示请求返回的状态码,它是可选参数
teardown_sql: Optional[List] = None # 表示该测试用例执行完后需要执行的 SQL 语句列表,它是可选参数
teardown: Union[List["TearDown"], None] = None # 表示模拟测试数据的后置条件
current_request_set_cache: Optional[List["CurrentRequestSetCache"]] # 表示缓存当前请求需要的数据
sleep: Optional[Union[int, float]] # 表示请求完后需要等待的时间,它是可选参数
# 定义了一个名为 ResponseData 的数据类,它同样是继承自 BaseModel 类,即 ResponseData 类也具有了 BaseModel 类的所有属性和方法。
class ResponseData(BaseModel):
url: Text # 表示 API 的请求地址
is_run: Union[None, bool, Text] # 表示是否需要运行该测试用例,它是可选参数,默认值为 None
detail: Text # 表示测试用例的详细信息
response_data: Text # 表示响应结果的文本内容
request_body: Any # 表示请求体数据,它是可选参数
method: Text # 表示请求方式,例如 GET、POST 等
sql_data: Dict # 表示数据库执行后的结果数据,它是一个字典
yaml_data: "TestCase" # 表示该测试用例的详细信息,是一个 TestCase 实例
headers: Dict # 表示响应结果的请求头
cookie: Dict # 表示响应结果的 cookie 信息
assert_data: Dict # 表示需要进行断言的数据,是一个字典
res_time: Union[int, float] # 表示响应时间
status_code: int # 表示请求返回的状态码
teardown: List["TearDown"] = None # 表示模拟测试数据的后置条件
teardown_sql: Union[None, List] # 表示该测试用例执行完后需要执行的 SQL 语句列表,它是可选参数
body: Any # 表示响应结果的请求体数据
# 定义了一个名为 DingTalk 的数据类,它同样是继承自 BaseModel 类,即 DingTalk 类也具有了 BaseModel 类的所有属性和方法。
class DingTalk(BaseModel):
# 定义了 DingTalk 类的两个属性
webhook: Union[Text, None] # 表示钉钉机器人的 Webhook 地址,是一个文本类型的可选参数,默认值为 None
secret: Union[Text, None] # 表示加签的密钥,是一个文本类型的可选参数,默认值为 None
# 这个数据类可以用来存储钉钉机器人的相关信息,方便程序中的调用和使用。由于这两个属性都是可选参数,所以在使用时需要注意判断是否为空。
# 定义了一个名为 MySqlDB 的数据类,它同样是继承自 BaseModel 类,即 MySqlDB 类也具有了 BaseModel 类的所有属性和方法。
class MySqlDB(BaseModel):
switch: bool = False # 表示该数据库是否需要连接,是一个布尔类型的可选参数,默认值为 False
host: Union[Text, None] = None # 表示数据库的地址,是一个文本类型的可选参数,默认值为 None
user: Union[Text, None] = None # 表示连接数据库的用户名,是一个文本类型的可选参数,默认值为 None
password: Union[Text, None] = None # 表示连接数据库的密码,是一个文本类型的可选参数,默认值为 None
port: Union[int, None] = 3306 # 表示连接数据库的端口,是一个整型的可选参数,默认值为 3306
# 这个数据类可以用来存储 MySQL 数据库的相关信息,方便程序中的调用和使用。由于所有属性都是可选参数,所以在使用时需要注意判断是否为空。此外,通过在属性定义中设置默认值,可以方便地进行参数配置。
# 定义了一个名为 Webhook 的数据类,它同样是继承自 BaseModel 类,即 Webhook 类也具有了 BaseModel 类的所有属性和方法。
class Webhook(BaseModel):
webhook: Union[Text, None] # 表示 Webhook 地址,是一个文本类型的可选参数,默认值为 None
# 这个数据类可以用来存储 Webhook 的相关信息,方便程序中的调用和使用。由于 webhook 属性是一个可选参数,所以在使用时需要注意判断是否为空。
# 定义了一个名为 Email 的数据类,它同样是继承自 BaseModel 类,即 Email 类也具有了 BaseModel 类的所有属性和方法。
class Email(BaseModel):
send_user: Union[Text, None] # 表示发件人邮箱的用户名,是一个文本类型的可选参数,默认值为 None
email_host: Union[Text, None] # 表示邮件服务器的地址,是一个文本类型的可选参数,默认值为 None
stamp_key: Union[Text, None] # 表示发件人的密码或授权码,是一个文本类型的可选参数,默认值为 None
send_list: Union[Text, None] # 表示邮件的接收人列表,是一个文本类型的可选参数,默认值为 None
# 这个数据类可以用来存储发送邮件的相关信息,方便程序中的调用和使用。由于所有属性都是可选参数,所以在使用时需要注意判断是否为空。此外,通过在属性定义中设置默认值,可以方便地进行参数配置。
# 定义了一个名为 Config 的数据类,它同样是继承自 BaseModel 类,即 Config 类也具有了 BaseModel 类的所有属性和方法。
class Config(BaseModel):
project_name: Text # 表示项目的名称,是一个文本类型的必选参数
env: Text # 表示运行的环境,是一个文本类型的必选参数
tester_name: Text # 表示测试人员的姓名,是一个文本类型的必选参数
notification_type: Text = '0' # 表示通知的方式,是一个文本类型的可选参数,它的默认值为 '0'
excel_report: bool # 表示是否生成 Excel 报告,是一个布尔类型的必选参数
ding_talk: "DingTalk" # 表示钉钉机器人的相关信息,是一个 DingTalk 类的实例,是一个必选参数
mysql_db: "MySqlDB" # 表示 MySQL 数据库的相关信息,是一个 MySqlDB 类的实例,是一个必选参数
mirror_source: Text # 表示测试用例所在的镜像源,是一个文本类型的必选参数
wechat: "Webhook" # 表示微信机器人的相关信息,是一个 Webhook 类的实例,是一个必选参数
email: "Email" # 表示邮件相关信息,是一个 Email 类的实例,是一个必选参数
lark: "Webhook" # 表示飞书机器人的相关信息,是一个 Webhook 类的实例,是一个必选参数
real_time_update_test_cases: bool = False # 表示是否实时更新测试用例,是一个布尔类型的可选参数,它的默认值为 False
host: Text # 表示测试服务器的地址,是一个文本类型的必选参数
app_host: Union[Text, None] # 表示被测应用程序的地址,是一个文本类型的可选参数,默认值为 None
# 这个数据类封装了一个测试框架的配置信息,包括项目名称、测试环境、测试人员信息、通知方式、测试用例相关信息、被测应用程序相关信息等。可以通过实例化 Config 类来快速配置测试框架的相关信息。由于部分属性有默认值,因此在实例化时可以只传递必选参数。
# 定义了一个名为 AllureAttachmentType 的枚举类,它继承自 Python 内置的 Enum 类,表示这是一个枚举类。同时使用 @unique 修饰符确保枚举类成员的值各不相同。
@unique
class AllureAttachmentType(Enum):
"""
allure 报告的文件类型枚举
"""
# 定义了一个包含 19 个成员的枚举,每个成员表示一种 Allure 报告中的文件类型。其中,每个成员都由一个名称和一个值构成,名称即为成员名称(如 TEXT、CSV),而值则为成员的实际取值(如 "text"、"csv")。枚举中的所有成员都是不可变的,例如不能重新赋值或删除成员。
TEXT = "txt"
CSV = "csv"
TSV = "tsv"
URI_LIST = "uri"
HTML = "html"
XML = "xml"
JSON = "json"
YAML = "yaml"
PCAP = "pcap"
PNG = "png"
JPG = "jpg"
SVG = "svg"
GIF = "gif"
BMP = "bmp"
TIFF = "tiff"
MP4 = "mp4"
OGG = "ogg"
WEBM = "webm"
PDF = "pdf"
# 这个枚举类可以用于定义 Allure 报告中的文件类型,所以在测试框架中被广泛使用。它可以帮助开发人员、测试人员和其他相关人员快速识别和解析 Allure 报告中包含的文件类型。
@unique
class AssertMethod(Enum):
"""断言类型"""
# 是否相等
equals = "=="
# 判断实际结果小于预期结果
less_than = "lt"
# 判断实际结果小于等于预期结果
less_than_or_equals = "le"
# 判断实际结果大于预期结果
greater_than = "gt"
# 判断实际结果大于等于预期结果
greater_than_or_equals = "ge"
# 判断实际结果不等于预期结果
not_equals = "not_eq"
# 判断字符串是否相等
string_equals = "str_eq"
# 判断长度是否相等
length_equals = "len_eq"
# 判断长度大于
length_greater_than = "len_gt"
# 判断长度大于等于
length_greater_than_or_equals = 'len_ge'
# 判断长度小于
length_less_than = "len_lt"
# 判断长度小于等于
length_less_than_or_equals = 'len_le'
# 判断期望结果内容包含在实际结果中
contains = "contains"
# 判断实际结果包含在期望结果中
contained_by = 'contained_by'
# 检查响应内容的开头是否和预期结果内容的开头相等
startswith = 'startswith'
# 检查响应内容的结尾是否和预期结果内容相等
endswith = 'endswith'
# 去重无序判断是否相等
setlist = 'setlist'
# list转成str 去重无序判断是否相等
str_set = 'str_set'
# 可散列判断
counter = 'counter'
thread_tool.py # 定时器类
详细讲解
import time
import threading
class PyTimer:
"""定时器类"""
# 定义了一个 __init__ 方法作为该类的构造函数,接收一个函数 func 和一些参数和关键字参数 *args、**kwargs。并且初始化了 4 个属性
def __init__(self, func, *args, **kwargs):
"""构造函数"""
self.func = func # 表示需要定时执行的函数
self.args = args # 表示传递给需要定时执行的函数的位置参数或参数元组
self.kwargs = kwargs # 表示传递给需要定时执行的函数的关键字参数或参数字典
self.running = False # 表示定时器是否正在运行的标志,初始化为 False
# 定义了一个 _run_func 实例方法。
def _run_func(self):
"""运行定时事件函数"""
# 使用 threading.Thread 方法创建一个新的线程对象 _thread,并将 self.func 函数作为该线程的目标函数,位置参数和关键字参数分别为 self.args 和 self.kwargs。
_thread = threading.Thread(target=self.func, args=self.args, kwargs=self.kwargs)
# 将 _thread 线程设置为守护线程,即子线程在主线程结束时会自动退出。
_thread.setDaemon(True)
# 启动 _thread 线程,开始执行定时事件函数。
_thread.start()
# 这个方法实现了在一个新线程中运行定时事件函数。使用多线程可以在程序启动后,让程序在后台运行不被阻塞,提高程序的响应能力。
# 定义了一个名为 _start 的定时器线程函数,包含参数 interval 和 once。interval 是任务执行的时间间隔, once 是一个布尔值,表示任务在定时完成后是否仅执行一次。
def _start(self, interval, once):
"""启动定时器的线程函数"""
# 首先使用 max 函数将 interval 设定为 0.01 或更大的值。这是因为当 interval 的值太小可能会导致执行过程中的误差。
interval = max(interval, 0.01)
# 根据 interval 的大小, _dt 的值被设定为最小的执行时间。如果 interval 小于 0.05 秒,则 _dt 值为1/10倍的 interval。
if interval < 0.050:
_dt = interval / 10
# 否则, _dt 值为0.005秒。
else:
_dt = 0.005
# 如果任务只要单次执行,该代码块会先计算到达期限时间 deadline,等待直到时间到达 deadline(通过不断的 time.sleep(dt)),然后执行 self._run_func() 方法,以执行任务。
if once:
deadline = time.time() + interval
while time.time() < deadline:
time.sleep(_dt)
# 定时时间到,调用定时事件函数
self._run_func()
# 如果任务需要重复执行,该代码块会设置 self.running = True,然后在一个循环中重复执行任务。在循环中,该代码块先计算下一个到期时间 deadline,然后等待时间直到到期(通过不断的time.sleep(dt))。然后,为下一个定时执行更新 deadline 的值。最后,该代码块调用 _run_func() 方法来执行任务。
else:
# 当 self.running 被设置为 False 时,定时器将再次暂停,任务将不会被重复执行。
self.running = True
deadline = time.time() + interval
while self.running:
while time.time() < deadline:
time.sleep(_dt)
# 更新下一次定时时间
deadline += interval
# 定时时间到,调用定时事件函数
if self.running:
self._run_func()
# 这是启动定时器的外部函数,在类中设定了 interval、once 其默认值为 False。
def start(self, interval, once=False):
"""启动定时器
interval - 定时间隔,浮点型,以秒为单位,最高精度10毫秒
once - 是否仅启动一次,默认是连续的
"""
# thread_ 是定义的一个线程对象,这里使用 threading.Thread 函数从 _start 中创建一个新线程。
thread_ = threading.Thread(target=self._start, args=(interval, once))
# 将线程设置为守护线程。在 Python 中,当一个线程为守护线程时,在主线程退出时,守护线程会自动退出。这可以确保定时器线程在主线程结束时自动结束。
thread_.setDaemon(True)
# 启动新线程,让定时器开始工作。线程开始执行 _start 方法,在该方法中,根据设定好的 interval 和 once参数,对定时器的执行进行相应设定和控制。
thread_.start()
def stop(self):
"""停止定时器"""
# 是 running 属性的赋值操作,将类属性 self.running 设为 False,用于控制定时器的运行。
self.running = False
# 这个方法非常简单,它的作用就是让定时器主线程停止运行,因为在定时器的主线程中,使用了 while self.running: 循环,当 self.running 为 False 时,循环就会退出,从而实现停止定时器的目的。
# 定义了一个函数 do_something,函数接收两个参数,其中 name 是必须传递的参数,而 gender 是可选参数,如果不传递则默认为 'male'。
def do_something(name, gender='male'):
"""执行"""
# 使用 time.time() 函数获取当前时间戳,并输出一个提示信息,表示在定时任务到达时,需要执行特定的任务。
print(time.time(), '定时时间到,执行特定任务')
# 使用字符串的 format 方法对字符串进行格式化输出,输出传入的 name 和 gender,其中 %s 是占位符。
print('name:%s, gender:%s', name, gender)
# 使用 time 模块的 sleep 函数使得程序暂停 5 秒,用于模拟执行一些需要耗费时间的操作。
time.sleep(5)
# 输出当前时间戳和一个提示信息,表示特定任务已经完成。
print(time.time(), '完成特定任务')
# 定义了一个 PyTimer 对象,并传入了三个参数,分别是 do_something 函数、字符串 'Alice' 和字典 {'gender': 'female'},其中 'Alice' 和 'female' 分别对应了 do_something 中的 name 和 gender 两个参数。
timer = PyTimer(do_something, 'Alice', gender='female')
# 调用了定时器对象 timer 的 start() 方法,开始了定时器操作。其中,第一个参数 0.5 表示每隔 0.5 秒执行一次任务,第二个参数 once=False 表示定时器会一直执行,而不是只执行一次。
timer.start(0.5, once=False)
# 使用 input 函数实现的阻塞操作,等待用户按下回车键,以便之后停止定时器操作。
input('按回车键结束\n') # 此处阻塞住进程
# 调用了定时器对象 timer 的 stop() 方法,停止了定时器的操作。
timer.stop()
read_files_tools # 读取文件工具
case_automatic_control.py # 自动生成测试代码
详细讲解
import os
from typing import Text
from common.setting import ensure_path_sep
from utils.read_files_tools.testcase_template import write_testcase_file
from utils.read_files_tools.yaml_control import GetYamlData
from utils.read_files_tools.get_all_files_path import get_all_files
# 定义了一个名为 TestCaseAutomaticGeneration 的类,用于自动生成测试用例代码。
class TestCaseAutomaticGeneration:
# 类的 __init__() 方法中初始化了 self.yaml_case_data 和 self.file_path,它们分别用于存储读取的测试用例数据和测试用例文件路径。
def __init__(self):
# 它是一个成员变量,用于存储 YAML 格式的测试用例数据。
self.yaml_case_data = None
# 它是一个成员变量,用于存储测试用例数据文件的路径。
self.file_path = None
# @property 可以将一个方法转换成一个属性,可以像访问普通属性一样,使用 obj.case_date_path 的方式访问该属性。
@property
# 定义了一个名为 case_date_path 的属性,并使用了 ensure_path_sep("\\data") 方法返回一个格式化后的路径字符串。
def case_date_path(self) -> Text:
"""返回 yaml 用例文件路径"""
return ensure_path_sep("\\data")
@property
# 定义了一个名为 case_path 的属性,它指定了测试用例代码存放的路径,并使用了 ensure_path_sep("\\test_case") 方法对路径进行了格式化。
def case_path(self) -> Text:
""" 存放用例代码路径"""
return ensure_path_sep("\\test_case")
@property
# 定义了一个名为 allure_epic 的属性,它用于获取指定的 YAML 文件中的测试数据中的 allureEpic 字段。如果该字段不存在或为空,则代码会抛出一个 AssertionError,其中包含了有关错误的详细信息,例如文件路径和字段名称,并提示用户进行检查。
def allure_epic(self):
# 从当前实例的 yaml_case_data 属性中获取 case_common 键所对应的值中的 allureEpic 键所对应的值,并将其赋值给 _allure_epic 变量。如果没有找到或者为空,那么 _allure_epic 将会是 None。
_allure_epic = self.yaml_case_data.get("case_common").get("allureEpic")
# 检查 _allure_epic 是否为空。如果为空,则使用 assert 关键字抛出一个断言错误,其中包含了错误信息。该错误信息包含了文件路径和缺失的字段名称。
assert _allure_epic is not None, (
"用例中 allureEpic 为必填项,请检查用例内容, 用例路径:'%s'" % self.file_path
)
# 返回 _allure_epic 的值作为这个属性的值,也就是当前 YAML 文件中的 allureEpic 字段的值。
return _allure_epic
@property
def allure_feature(self):
# 从 yaml_case_data 属性中获取当前 YAML 文件中的 case_common 键所对应的值中的 allureFeature 键所对应的值,并将其赋值给 _allure_feature 变量。如果没有找到或者为空,那么 _allure_feature 将会是 None。
_allure_feature = self.yaml_case_data.get("case_common").get("allureFeature")
# 检查 _allure_feature 是否为空。如果为空,则使用 assert 关键字抛出一个断言错误,其中包含了错误信息。该错误信息包含了文件路径和缺失的字段名称。
assert _allure_feature is not None, (
"用例中 allureFeature 为必填项,请检查用例内容, 用例路径:'%s'" % self.file_path
)
# 返回 _allure_feature 的值作为这个属性的值,也就是当前 YAML 文件中的 allureFeature 字段的值。
return _allure_feature
@property
def allure_story(self):
# 从 yaml_case_data 属性中获取当前 YAML 文件中的 case_common 键所对应的值中的 allureStory 键所对应的值,并将其赋值给 _allure_story 变量。如果没有找到或者为空,那么 _allure_story 将会是 None。
_allure_story = self.yaml_case_data.get("case_common").get("allureStory")
# 检查 _allure_story 是否为空。如果为空,则使用 assert 关键字抛出一个断言错误,其中包含了错误信息。该错误信息包含了文件路径和缺失的字段名称。
assert _allure_story is not None, (
"用例中 allureStory 为必填项,请检查用例内容, 用例路径:'%s'" % self.file_path
)
# 返回 _allure_story 的值作为这个属性的值,也就是当前 YAML 文件中的 allureStory 字段的值。
return _allure_story
@property
def file_name(self) -> Text:
"""
通过 yaml文件的命名,将名称转换成 py文件的名称
:return: 示例: DateDemo.py
"""
# 获取 self.file_path 属性中除去 self.case_date_path 前缀的部分,并将其赋值给 yaml_path 变量。
i = len(self.case_date_path)
yaml_path = self.file_path[i:]
# 这里初始化了一个 file_name 变量为 None。
file_name = None
# if-elif 循环检查 yaml_path 变量中是否包含 .yaml 或 .yml 字符串,如果包含,则将其替换成 .py 字符串,并将结果赋值给 file_name 变量。路径转换
if '.yaml' in yaml_path:
file_name = yaml_path.replace('.yaml', '.py')
elif '.yml' in yaml_path:
file_name = yaml_path.replace('.yml', '.py')
# 返回 file_name 变量的值作为这个方法的返回值。
return file_name
@property
def get_test_class_title(self):
"""
自动生成类名称
:return: sup_apply_list --> SupApplyList
"""
# 获取 self.file_name 中的文件名,去除了 .py 后缀,并将结果赋值给 _file_name 变量。
_file_name = os.path.split(self.file_name)[1][:-3]
# 使用 _file_name 的值初始化了一个 _name 列表,并且获取了 _name 的长度。
_name = _file_name.split("_")
_name_len = len(_name)
# for 循环将 _name 中的每个单词首字母转换成大写字母。将文件名称格式,转换成类名称: sup_apply_list --> SupApplyList
for i in range(_name_len):
_name[i] = _name[i].capitalize()
# 将 _name 中的所有单词合并成一个字符串,赋值给 _class_name 变量。
_class_name = "".join(_name)
# 返回 _class_name 变量的值作为这个方法的返回值,也就是测试用例所对应的类的名称。
return _class_name
@property
def func_title(self) -> Text:
"""
函数名称
:return:
"""
# 返回了 self.file_name 中的文件名,去除了 .py 后缀,作为函数的返回值。因为 self.file_name 中已经是 .py 后缀的文件名了,所以返回值就是一个函数名。
return os.path.split(self.file_name)[1][:-3]
@property
def spilt_path(self):
# 使用 os.sep 分隔符将路径字符串拆分成列表,把结果赋值给新的 path 变量。
path = self.file_name.split(os.sep)
# 将列表中最后一个元素修改为 "test_" + path[-1],也就是在该文件名前面添加 "test_"。
path[-1] = path[-1].replace(path[-1], "test_" + path[-1])
# spilt_path 方法返回修改后的 path 列表,也即是测试用例文件的所在路径。
return path
@property
def get_case_path(self):
"""
根据 yaml 中的用例,生成对应 testCase 层代码的路径
:return: D:\\Project\\test_case\\test_case_demo.py
"""
# 将 spilt_path 方法返回的路径列表加上分隔符,生成新路径字符串。比如,如果原路径是 ['home', 'user', 'Documents', 'test.py'],那么这一行代码返回的结果就是 'home/user/Documents/test.py'。
new_name = os.sep.join(self.spilt_path)
# 调用了 ensure_path_sep 方法,确保路径字符串最后一个字符是路径分隔符。然后,将字符串 "\test_case" 与新生成的路径使用 + 拼接,并返回该字符串。比如,如果原路径是 D:\Project\test.py,那么这一行代码返回的结果就是 D:\Project\test_case\test.py。
return ensure_path_sep("\\test_case" + new_name)
@property
def case_ids(self):
# 使用列表推导式,遍历 yaml_case_data (即测试数据)中所有的键,如果该键不等于 "case_common",那么返回该键。也就是说,这里会返回一个列表,表示测试数据中所有测试用例的 id 字段。
return [k for k in self.yaml_case_data.keys() if k != "case_common"]
@property
def get_file_name(self):
# 判断生成的 testcase 文件名称,需要以test_ 开头
# 根据 spilt_path 方法返回的文件路径,提取出文件名称。然后,使用 replace 方法将文件名替换为以 "test_" 开头的新文件名。比如,如果原文件名是 sample.py,那么这一行代码返回的结果就是 test_sample.py。
case_name = self.spilt_path[-1].replace(
self.spilt_path[-1], "test_" + self.spilt_path[-1]
)
# 返回新的测试用例 Python 文件名。
return case_name
def mk_dir(self) -> None:
""" 判断生成自动化代码的文件夹路径是否存在,如果不存在,则自动创建 """
# 调用 os.path.split 方法,将 get_case_path (测试数据文件路径) 分解成目录路径和文件名,这样就可以提取出测试数据文件所在的目录路径了。
_case_dir_path = os.path.split(self.get_case_path)[0]
# 通过 os.path.exists 方法判断目录路径是否存在,如果不存在就使用 os.makedirs 方法创建目录。也就是说,这个函数的作用是创建测试数据文件所在目录的子目录,用于存储生成的测试用例代码文件。
if not os.path.exists(_case_dir_path):
os.makedirs(_case_dir_path)
def get_case_automatic(self) -> None:
""" 自动生成 测试代码"""
# 使用 get_all_files 方法获取测试数据文件夹下所有的 YAML 文件路径,并将结果存储到 file_path 变量中。这些 YAML 文件将作为测试用例的源数据。
file_path = get_all_files(file_path=ensure_path_sep("\\data"), yaml_data_switch=True)
# 使用 for 循环遍历所有的测试数据文件。
for file in file_path:
# if 语句判断当前文件不是代理拦截的 YAML 文件。如果是,则不生成测试用例代码。
if 'proxy_data.yaml' not in file:
# 这里调用了 GetYamlData 类的 get_yaml_data 方法,获取 YAML 文件的数据内容,并将其保存到 yaml_case_data 变量中。
self.yaml_case_data = GetYamlData(file).get_yaml_data()
# 将当前文件路径保存到 file_path 变量中
self.file_path = file
# 调用 mk_dir 方法,在测试用例代码所需的目录路径不存在时创建目录。
self.mk_dir()
# 这里调用 write_testcase_file 函数,生成测试用例 Python 文件。
write_testcase_file(
allure_epic=self.allure_epic,
allure_feature=self.allure_feature,
class_title=self.get_test_class_title,
func_title=self.func_title,
case_path=self.get_case_path,
case_ids=self.case_ids,
file_name=self.get_file_name,
allure_story=self.allure_story
)
if __name__ == '__main__':
# 创建了 TestCaseAutomaticGeneration 类的一个实例,并调用 get_case_automatic 方法,来自动生成测试用例代码。也就是说,当你直接运行这个脚本的时候,就会自动生成测试用例代码。
TestCaseAutomaticGeneration().get_case_automatic()
clean_files.py # 清理文件
详细讲解
import os
# 函数定义,输入参数为要删除的路径名。
def del_file(path):
"""删除目录下的文件"""
# 获取指定路径下的所有子文件和子目录,并存储到 list_path 变量中。
list_path = os.listdir(path)
# 依次遍历 list_path 中的每个目录和文件,将它们的绝对路径存储到 c_path 变量中。
for i in list_path:
c_path = os.path.join(path, i)
# 如果当前路径 c_path 是一个目录,则递归调用 del_file 函数,继续删除目录中的文件和子目录。
if os.path.isdir(c_path):
del_file(c_path)
# 如果当前路径 c_path 是一个文件,则直接删除它。
else:
os.remove(c_path)
# 这个函数会递归地删除指定的路径下所有的文件和子目录,直到删除完毕并返回。
excel_control.py # 读写excel
详细讲解
import json
import xlrd
from xlutils.copy import copy
from common.setting import ensure_path_sep
# 函数名为get_excel_data,参数为sheet_name和case_name,返回值为列表类型list。
def get_excel_data(sheet_name: str, case_name: any) -> list:
"""
读取 Excel 中的数据
:param sheet_name: excel 中的 sheet 页的名称
:param case_name: 测试用例名称
:return:
"""
# 创建一个空列表res_list,用于存储读取Excel中的数据。
res_list = []
# 用于将路径中的斜杠转换为对应系统的分隔符。这里将Excel文件所在的路径作为参数传入,并将结果赋值给excel_dire变量。
excel_dire = ensure_path_sep("\\data\\TestLogin.xls")
# 使用xlrd库打开Excel文件,并将结果赋值给work_book变量。formatting_info=True表示保留Excel中的格式信息。
work_book = xlrd.open_workbook(excel_dire, formatting_info=True)
# 获取指定名称的子表(sheet)并将结果赋值给work_sheet变量。
work_sheet = work_book.sheet_by_name(sheet_name)
# 初始化变量idx为0,用于记录行数。
idx = 0
# 使用col_values方法获取第一列的所有值,并遍历每一个值。
for one in work_sheet.col_values(0):
# 判断当前行是否包含指定的测试用例名称,如果是,则继续执行下一步。
if case_name in one:
#获取当前行第10列(索引从0开始)的值,并将结果赋值给req_body_data变量,用于存储请求体数据。
req_body_data = work_sheet.cell(idx, 9).value
# 获取当前行第12列(索引从0开始)的值,并将结果赋值给resp_data变量,用于存储响应数据。
resp_data = work_sheet.cell(idx, 11).value
# 将请求体数据和响应数据组成一个元组,并添加到res_list列表中。
res_list.append((req_body_data, json.loads(resp_data)))
# 行数加1,继续读取下一行的数据。
idx += 1
# 返回读取到的Excel数据列表。
return res_list
# 函数名为set_excel_data,参数为sheet_index,返回值为元组类型tuple。
def set_excel_data(sheet_index: int) -> tuple:
"""
excel 写入
:return:
"""
# 用于指定Excel文件的路径。这里使用相对路径来指定文件所在的位置。
excel_dire = '../data/TestLogin.xls'
# 使用xlrd库打开Excel文件,并将结果赋值给work_book变量。formatting_info=True表示保留Excel中的格式信息。
work_book = xlrd.open_workbook(excel_dire, formatting_info=True)
# 使用xlutils.copy库的copy函数复制一份Excel文件,并将结果赋值给work_book_new变量。这里使用xlutils库是因为xlrd库只能读取Excel文件,不能进行写入操作。
work_book_new = copy(work_book)
# 获取指定索引的子表(sheet)并将结果赋值给work_sheet_new变量,用于写入数据
work_sheet_new = work_book_new.get_sheet(sheet_index)
# 返回复制后的Excel文件和要写入数据的子表(sheet)。
return work_book_new, work_sheet_new
get_all_files_path.py # 获取所有文件路径
详细讲解
import os
# 函数名为get_all_files,参数为file_path和yaml_data_switch,返回值为列表类型list。
def get_all_files(file_path, yaml_data_switch=False) -> list:
"""
获取文件路径
:param file_path: 目录路径
:param yaml_data_switch: 是否过滤文件为 yaml格式, True则过滤
:return:
"""
# 创建一个空列表filename,用于存储文件路径。
filename = []
# 使用os.walk函数遍历指定路径下的所有文件和文件夹,并获取每一个子目录的路径、子目录列表和文件列表。
for root, dirs, files in os.walk(file_path):
# 遍历文件列表中的每一个文件路径。
for _file_path in files:
# 使用os.path.join函数将当前文件所在目录的路径和文件名拼接成完整的文件路径,并赋值给path变量。
path = os.path.join(root, _file_path)
# 判断yaml_data_switch参数是否为True,如果是,则继续执行下一步。
if yaml_data_switch:
# 判断文件路径中是否包含yaml或.yml,如果是,则将文件路径添加到filename列表中。
if 'yaml' in path or '.yml' in path:
filename.append(path)
# 如果yaml_data_switch参数为False,则将文件路径添加到filename列表中。
else:
filename.append(path)
# 返回所有文件的路径列表。
return filename
get_yaml_data_analysis.py # yaml用例数据清洗
详细讲解
from typing import Union, Text, List
from utils.read_files_tools.yaml_control import GetYamlData
from utils.other_tools.models import TestCase
from utils.cache_process.cache_control import CacheHandler
from utils import config
from utils.other_tools.models import RequestType, Method, TestCaseEnum
import os
class CaseDataCheck:
"""
yaml 数据解析, 判断数据填写是否符合规范
"""
# 类的构造方法,接收一个参数file_path,用于指定yaml文件的路径。
def __init__(self, file_path):
# 将传入的file_path赋值给实例变量self.file_path,以便在类的其他方法中使用。
self.file_path = file_path
# 判断指定的文件路径是否存在,如果不存在则抛出FileNotFoundError异常。
if os.path.exists(self.file_path) is False:
raise FileNotFoundError("用例地址未找到")
# 初始化一个实例变量self.case_data,用于存储解析后的yaml数据。
self.case_data = None
# 初始化一个实例变量self.case_id,用于存储当前解析的用例ID。
self.case_id = None
# 定义一个名为_assert的方法,接收一个参数attr,用于指定需要判断的参数是否存在。
def _assert(self, attr: Text):
# 判断指定的参数是否在yaml数据的keys中存在,如果不存在则抛出异常,提示缺少该参数。
assert attr in self.case_data.keys(), (
f"用例ID为 {self.case_id} 的用例中缺少 {attr} 参数,请确认用例内容是否编写规范."
f"当前用例文件路径:{self.file_path}"
)
# 定义一个名为check_params_exit的方法,用于检查yaml数据中是否缺少必要的参数。
def check_params_exit(self):
# 遍历TestCaseEnum枚举中所有的成员。
for enum in list(TestCaseEnum._value2member_map_.keys()):
# 判断枚举成员是否是必要的参数。
if enum[1]:
# 调用_assert方法,判断当前枚举成员对应的参数是否存在。
self._assert(enum[0])
# 定义一个名为check_params_right的方法,接收两个参数enum_name和attr,用于检查参数是否填写正确。
def check_params_right(self, enum_name, attr):
# 获取枚举成员的所有名称。
_member_names_ = enum_name._member_names_
# 判断枚举成员是否包含指定的参数,如果不包含则抛出异常,提示参数填写错误。
assert attr.upper() in _member_names_, (
f"用例ID为 {self.case_id} 的用例中 {attr} 填写不正确,"
f"当前框架中只支持 {_member_names_} 类型."
f"如需新增 method 类型,请联系管理员."
f"当前用例文件路径:{self.file_path}"
)
# 返回大写的参数名称。
return attr.upper()
# 装饰器,将方法转换成属性,以便在调用时不需要使用括号。
@property
# 定义一个名为get_method的属性方法,用于获取yaml数据中的请求方法。
def get_method(self) -> Text:
# 调用check_params_right方法,检查请求方法是否填写正确。
return self.check_params_right(
# 枚举类型,指定参数类型为请求方法。
Method,
# 从yaml数据中获取请求方法。
self.case_data.get(TestCaseEnum.METHOD.value[0])
)
@property
# 定义一个名为get_host的属性方法,用于获取完整的请求地址。
def get_host(self) -> Text:
# 拼接请求地址,包含主机地址和请求路径。
host = (
# 从yaml数据中获取主机地址。
self.case_data.get(TestCaseEnum.HOST.value[0]) +
# 从yaml数据中获取请求路径。
self.case_data.get(TestCaseEnum.URL.value[0])
)
# 返回完整的请求地址。
return host
@property
# 定义一个名为get_request_type的属性方法,用于获取yaml数据中的请求类型。
def get_request_type(self):
# 调用check_params_right方法,检查请求类型是否填写正确。
return self.check_params_right(
# 枚举类型,指定参数类型为请求类型。
RequestType,
# 从yaml数据中获取请求类型。
self.case_data.get(TestCaseEnum.REQUEST_TYPE.value[0])
)
@property
# 定义了一个名为get_dependence_case_data的方法,该方法不需要传入参数,属于类方法。
def get_dependence_case_data(self):
# 从self.case_data中获取DE_CASE的值,赋值给变量_dep_data。
_dep_data = self.case_data.get(TestCaseEnum.DE_CASE.value[0])
# 如果_dep_data存在。
if _dep_data:
# 断言self.case_data中是否存在DE_CASE_DATA的值,如果不存在,抛出异常。
assert self.case_data.get(TestCaseEnum.DE_CASE_DATA.value[0]) is not None, (
f"程序中检测到您的 case_id 为 {self.case_id} 的用例存在依赖,但是 {_dep_data} 缺少依赖数据."
f"如已填写,请检查缩进是否正确, 用例路径: {self.file_path}"
)
@ 返回self.case_data中的DE_CASE_DATA的值。
return self.case_data.get(TestCaseEnum.DE_CASE_DATA.value[0])
@property
# 定义了一个名为get_assert的方法,该方法不需要传入参数,属于类方法。
def get_assert(self):
# 从self.case_data中获取ASSERT_DATA的值,赋值给变量_assert_data。
_assert_data = self.case_data.get(TestCaseEnum.ASSERT_DATA.value[0])
# 断言_assert_data是否存在,如果不存在,抛出异常。
assert _assert_data is not None, (
f"用例ID 为 {self.case_id} 未添加断言,用例路径: {self.file_path}"
)
# 返回_assert_data的值。
return _assert_data
@property
# 定义了一个名为get_sql的方法,该方法不需要传入参数,属于类方法。
def get_sql(self):
# 从self.case_data中获取SQL的值,赋值给变量_sql。
_sql = self.case_data.get(TestCaseEnum.SQL.value[0])
# 判断数据库开关为开启状态,并且sql不为空
if config.mysql_db.switch and _sql is None:
# 返回None。
return None
# 返回_sql的值。
return _sql
# 定义了一个名为case_process的方法,需要传入一个case_id_switch参数,属于类方法。
def case_process(self, case_id_switch: Union[None, bool] = None):
# 从self.file_path中获取yaml文件中的数据,赋值给变量data。
data = GetYamlData(self.file_path).get_yaml_data()
case_list = []
# 循环遍历data中的每一个元素,赋值给变量key和values。
for key, values in data.items():
# 如果key不等于case_common。
if key != 'case_common':
# 将values赋值给self.case_data。
self.case_data = values
# 将key赋值给self.case_id。
self.case_id = key
# 调用CaseDataCheck类中的check_params_exit方法,检查yaml文件中的参数是否正确。
super().check_params_exit()
# 定义一个字典case_date,用于存储每一个测试用例的数据。
case_date = {
'method': self.get_method, # 获取请求方法。
'is_run': self.case_data.get(TestCaseEnum.IS_RUN.value[0]), # 获取是否执行该测试用例。
'url': self.get_host, # 获取请求url。
'detail': self.case_data.get(TestCaseEnum.DETAIL.value[0]), # 获取测试用例的描述信息。
'headers': self.case_data.get(TestCaseEnum.HEADERS.value[0]), # 获取请求头信息。
'requestType': super().get_request_type, # 获取请求类型。
'data': self.case_data.get(TestCaseEnum.DATA.value[0]), # 获取请求数据。
'dependence_case': self.case_data.get(TestCaseEnum.DE_CASE.value[0]), # 获取依赖的测试用例。
'dependence_case_data': self.get_dependence_case_data, # 获取依赖测试用例的返回数据。
"current_request_set_cache": self.case_data.get(TestCaseEnum.CURRENT_RE_SET_CACHE.value[0]), # 获取当前请求的缓存设置。
"sql": self.get_sql, # 获取执行的sql语句。
"assert_data": self.get_assert, # 获取断言数据。
"setup_sql": self.case_data.get(TestCaseEnum.SETUP_SQL.value[0]), # 获取测试用例执行前需要执行的sql语句。
"teardown": self.case_data.get(TestCaseEnum.TEARDOWN.value[0]), # 获取测试用例执行后需要执行的方法。
"teardown_sql": self.case_data.get(TestCaseEnum.TEARDOWN_SQL.value[0]), # 获取测试用例执行后需要执行的sql语句。
"sleep": self.case_data.get(TestCaseEnum.SLEEP.value[0]), # 获取测试用例执行前需要等待的时间。
}
# 如果case_id_switch为True,则将测试用例的id和数据存储为字典的形式
if case_id_switch is True:
case_list.append({key: TestCase(**case_date).dict()})
# 否则直接存储测试用例的数据。
else:
case_list.append(TestCase(**case_date).dict())
# 返回case_list
return case_list
class GetTestCase:
# 该标记表示该方法是一个静态方法,可以通过类名直接调用,不需要实例化类。
@staticmethod
# 定义了一个名为case_data的方法,该方法需要传入一个参数case_id_lists,该参数是一个列表类型,用于存储测试用例的id。
def case_data(case_id_lists: List):
# 初始化一个空列表,用于存储测试用例数据。
case_lists = []
# 循环遍历case_id_lists中的每一个元素,赋值给变量i。
for i in case_id_lists:
# 通过调用CacheHandler类的get_cache方法,获取指定测试用例的数据,并将其赋值给变量_data。
_data = CacheHandler.get_cache(i)
# 将获取到的测试用例数据存储到case_lists列表中。
case_lists.append(_data)
# 返回存储测试用例数据的列表case_lists。
return case_lists
regular_control.py # 正则
详细讲解文章来源:https://www.toymoban.com/news/detail-643765.html
import re
import datetime
import random
from datetime import date, timedelta, datetime
from jsonpath import jsonpath
from faker import Faker
from utils.logging_tool.log_control import ERROR
class Context:
""" 正则替换 """
# 用于初始化对象的属性。
def __init__(self):
# self.faker 是对象的一个属性,用于存储一个Faker对象,Faker 是一个Python库,用于生成随机数据,如姓名、地址、电话号码等。使用了 locale='zh_CN' 参数来指定生成的数据的语言环境为中文。
self.faker = Faker(locale='zh_CN')
@classmethod
def generate_email(cls) -> str:
"""
:return: 随机生成邮箱
"""
Mailbox_number = 'register' + str(random.randint(0, 9999999)) + '@123.com'
return Mailbox_number
def generate_google_email(self) -> str:
"""
:return: 随机生成Google邮箱
"""
Google_email = 'google' + str(random.randint(0, 9999999)) + '@test.com'
return Google_email
def random_int(self) -> int:
"""
:return: 随机数
"""
_data = random.randint(0, 5000)
return _data
def get_phone(self) -> int:
"""
:return: 随机生成手机号码
"""
phone = self.faker.phone_number()
return phone
@classmethod
def get_time(cls) -> str:
"""
计算当前时间
:return:
"""
# 使用 datetime.now() 方法获取当前时间,然后使用 strftime() 方法将时间格式化为 '%Y-%m-%d %H:%M:%S' 的字符串格式。%Y 表示年份(4位数字),%m 表示月份(2位数字),%d 表示日期(2位数字),%H 表示小时(24小时制,2位数字),%M 表示分钟(2位数字),%S 表示秒(2位数字)。因此,now_time 变量将包含当前时间的字符串表示,格式为 '年-月-日 时:分:秒'。
now_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
return now_time
# 装饰器,用于定义类方法。类方法与实例方法不同,类方法是针对整个类而不是实例的方法。
@classmethod
# 这是一个类方法,用于获取接口域名。-> str表示返回类型为字符串。
def host(cls) -> str:
from utils import config
""" 获取接口域名 """
# 返回config模块中的host变量。
return config.host
@classmethod
# 这是一个类方法,用于获取app的host。-> str表示返回类型为字符串。
def app_host(cls) -> str:
from utils import config
"""获取app的host"""
# 返回config模块中的app_host变量。
return config.app_host
# 这是一个函数,用于提取sql中的json数据。
def sql_json(js_path, res):
""" 提取 sql中的 json 数据 """
# 这是一个jsonpath语法,用于从res变量中提取js_path指定的json数据。[0]表示取第一个元素。
_json_data = jsonpath(res, js_path)[0]
# 如果_json_data为False,即提取失败,则抛出ValueError异常。
if _json_data is False:
# 抛出ValueError异常,提示sql中的jsonpath获取失败。f""表示格式化字符串。
raise ValueError(f"sql中的jsonpath获取失败 {res}, {js_path}")
# 返回提取的json数据。
return jsonpath(res, js_path)[0]
# 这是一个函数,用于处理sql中的依赖数据。
def sql_regular(value, res=None):
"""
这里处理sql中的依赖数据,通过获取接口响应的jsonpath的值进行替换
:param res: jsonpath使用的返回结果
:param value:
:return:
"""
# 使用正则表达式查找value中以$json()格式包含的内容,并将其存储在sql_json_list列表中。
sql_json_list = re.findall(r"\$json\((.*?)\)\$", value)
# 循环遍历sql_json_list中的元素。
for i in sql_json_list:
# 使用正则表达式构造一个模式,用于匹配以$json()格式包含的内容。
pattern = re.compile(r'\$json\(' + i.replace('$', "\$").replace('[', '\[') + r'\)\$')
# 调用sql_json()函数获取json数据,并将其转换为字符串类型。
key = str(sql_json(i, res))
# 使用re.sub()函数将匹配到的内容替换成json数据中对应的值,替换次数为1。
value = re.sub(pattern, key, value, count=1)
# 返回替换后的value值。
return value
# 定义了一个名为 cache_regular 的函数,用于通过正则表达式的方式读取缓存中的内容,参数为 value。
def cache_regular(value):
from utils.cache_process.cache_control import CacheHandler
"""
通过正则的方式,读取缓存中的内容
例:$cache{login_init}
:param value:
:return:
"""
# 正则表达式\$cache\{(.*?)\}用来匹配字符串中以$cache{}包含的内容,.*?表示匹配任意字符,()表示括号内的内容为需要匹配的内容。re.findall()方法返回一个列表,包含所有匹配的结果。
# 正则获取 $cache{login_init}中的值 --> login_init
regular_dates = re.findall(r"\$cache\{(.*?)\}", value)
# for循环遍历regular_dates列表中的所有元素,即匹配到的所有缓存数据。
for regular_data in regular_dates:
# 定义了一个缓存数据类型的列表
value_types = ['int:', 'bool:', 'list:', 'dict:', 'tuple:', 'float:']
# 如果缓存数据的类型在value_types列表中,则将缓存数据类型和缓存数据名称分别提取出来
if any(i in regular_data for i in value_types) is True:
value_types = regular_data.split(":")[0]
regular_data = regular_data.split(":")[1]
# 使用re.compile()方法创建一个正则表达式对象pattern,用来匹配需要替换的字符串。
pattern = re.compile(r'\'\$cache\{' + value_types.split(":")[0] + ":" + regular_data + r'\}\'')
# 如果缓存数据的类型不在value_types列表中,则直接使用re.compile()方法创建一个正则表达式对象pattern,用来匹配需要替换的字符串。
else:
pattern = re.compile(
r'\$cache\{' + regular_data.replace('$', "\$").replace('[', '\[') + r'\}'
)
try:
# 使用CacheHandler.get_cache()方法读取缓存数据
cache_data = CacheHandler.get_cache(regular_data)
# 使用re.sub()方法将匹配到的字符串替换为缓存数据
value = re.sub(pattern, str(cache_data), value)
# 如果读取缓存数据或替换字符串过程中出现异常,则跳过并不处理。
except Exception:
pass
# 将处理好的字符串作为函数的返回值。
return value
# 定义了一个名为 regular 的函数,该函数接受一个参数 target。
def regular(target):
"""
新版本
使用正则替换请求数据
:return:
"""
try:
# 定义了一个正则表达式,用于匹配字符串中的 "${{}}" 格式的内容。
regular_pattern = r'\${{(.*?)}}'
# 使用 while 循环,当字符串中还存在 "${{}}" 格式的内容时,继续循环。
while re.findall(regular_pattern, target):
# 使用 re.search() 函数在字符串中找到第一个匹配的 "${{}}" 格式的内容,并获取其中的关键字。
key = re.search(regular_pattern, target).group(1)
# 定义了一个列表,包含了可能出现的数据类型。
value_types = ['int:', 'bool:', 'list:', 'dict:', 'tuple:', 'float:']
# 如果关键字中包含了可能出现的数据类型,则执行下面的代码。
if any(i in key for i in value_types) is True:
# 从关键字中获取函数名。
func_name = key.split(":")[1].split("(")[0]
# 从关键字中获取参数列表字符串,并去除字符串末尾的 ")"。
value_name = key.split(":")[1].split("(")[1][:-1]
# 如果参数列表字符串为空,则执行下面的代码。
if value_name == "":
# 从 Context 类中获取函数名为 func_name 的函数,并执行该函数,获取返回值。
value_data = getattr(Context(), func_name)()
# 如果参数列表字符串不为空,则执行下面的代码。
else:
# 从 Context 类中获取函数名为 func_name 的函数,并将参数列表字符串转换为参数列表,执行该函数,获取返回值。
value_data = getattr(Context(), func_name)(*value_name.split(","))
# 定义正则表达式模式,用于匹配字符串中的 "'${{}}'" 格式的内容。
regular_int_pattern = r'\'\${{(.*?)}}\''
# 将字符串中第一个匹配的 "'${{}}'" 格式的内容替换为 value_data。
target = re.sub(regular_int_pattern, str(value_data), target, 1)
# 如果关键字中不包含可能出现的数据类型,则执行下面的代码。
else:
# 从关键字中获取函数名。
func_name = key.split("(")[0]
# 从关键字中获取参数列表字符串,并去除字符串末尾的 ")"。
value_name = key.split("(")[1][:-1]
# 如果参数列表字符串为空,则执行下面的代码。
if value_name == "":
# 从 Context 类中获取函数名为 func_name 的函数,并执行该函数,获取返回值。
value_data = getattr(Context(), func_name)()
# 如果参数列表字符串不为空,则执行下面的代码。
else:
# 从 Context 类中获取函数名为 func_name 的函数,并将参数列表字符串转换为参数列表,执行该函数,获取返回值。
value_data = getattr(Context(), func_name)(*value_name.split(","))
# 将字符串中第一个匹配的 "${{}}" 格式的内容替换为 value_data。
target = re.sub(regular_pattern, str(value_data), target, 1)
# 返回处理后的字符串。
return target
# 捕获 AttributeError 异常。
except AttributeError:
# 打印错误日志,提示未找到对应的替换的数据。
ERROR.logger.error("未找到对应的替换的数据, 请检查数据是否正确 %s", target)
# 抛出异常。
raise
# 捕获 IndexError 异常。
except IndexError:
# 打印错误日志,提示 yaml 中的 ${{}} 函数方法不正确。
ERROR.logger.error("yaml中的 ${{}} 函数方法不正确,正确语法实例:${{get_time()}}")
# 抛出异常。
raise
swagger_for_yaml.py # Swagger文档转换,生成YAML用例
import json
from jsonpath import jsonpath
from common.setting import ensure_path_sep
from typing import Dict
from ruamel import yaml
import os
class SwaggerForYaml:
def __init__(self):
self._data = self.get_swagger_json()
@classmethod
def get_swagger_json(cls):
"""
获取 swagger 中的 json 数据
:return:
"""
try:
with open('./file/test_OpenAPI.json', "r", encoding='utf-8') as f:
row_data = json.load(f)
return row_data
except FileNotFoundError:
raise FileNotFoundError("文件路径不存在,请重新输入")
def get_allure_epic(self):
""" 获取 yaml 用例中的 allure_epic """
_allure_epic = self._data['info']['title']
return _allure_epic
@classmethod
def get_allure_feature(cls, value):
""" 获取 yaml 用例中的 allure_feature """
_allure_feature = value['tags']
return str(_allure_feature)
@classmethod
def get_allure_story(cls, value):
""" 获取 yaml 用例中的 allure_story """
_allure_story = value['summary']
return _allure_story
@classmethod
def get_case_id(cls, value):
""" 获取 case_id """
_case_id = value.replace("/", "_")
return "01" + _case_id
@classmethod
def get_detail(cls, value):
_get_detail = value['summary']
return "测试" + _get_detail
@classmethod
def get_request_type(cls, value, headers):
""" 处理 request_type """
if jsonpath(obj=value, expr="$.parameters") is not False:
_parameters = value['parameters']
if _parameters[0]['in'] == 'query':
return "params"
else:
if 'application/x-www-form-urlencoded' or 'multipart/form-data' in headers:
return "data"
elif 'application/json' in headers:
return "json"
elif 'application/octet-stream' in headers:
return "file"
else:
return "data"
@classmethod
def get_case_data(cls, value):
""" 处理 data 数据 """
_dict = {}
if jsonpath(obj=value, expr="$.parameters") is not False:
_parameters = value['parameters']
for i in _parameters:
if i['in'] == 'header':
...
else:
_dict[i['name']] = None
else:
return None
return _dict
@classmethod
def yaml_cases(cls, data: Dict, file_path: str) -> None:
"""
写入 yaml 数据
:param file_path:
:param data: 测试用例数据
:return:
"""
_file_path = ensure_path_sep("\\data\\" + file_path[1:].replace("/", os.sep) + '.yaml')
_file = _file_path.split(os.sep)[:-1]
_dir_path = ''
for i in _file:
_dir_path += i + os.sep
try:
os.makedirs(_dir_path)
except FileExistsError:
...
with open(_file_path, "a", encoding="utf-8") as file:
yaml.dump(data, file, Dumper=yaml.RoundTripDumper, allow_unicode=True)
file.write('\n')
@classmethod
def get_headers(cls, value):
""" 获取请求头 """
_headers = {}
if jsonpath(obj=value, expr="$.consumes") is not False:
_headers = {"Content-Type": value['consumes'][0]}
if jsonpath(obj=value, expr="$.parameters") is not False:
for i in value['parameters']:
if i['in'] == 'header':
_headers[i['name']] = None
else:
_headers = None
return _headers
def write_yaml_handler(self):
_api_data = self._data['paths']
for key, value in _api_data.items():
for k, v in value.items():
yaml_data = {
"case_common": {"allureEpic": self.get_allure_epic(), "allureFeature": self.get_allure_feature(v),
"allureStory": self.get_allure_story(v)},
self.get_case_id(key): {
"host": "${{host()}}", "url": key, "method": k, "detail": self.get_detail(v),
"headers": self.get_headers(v), "requestType": self.get_request_type(v, self.get_headers(v)),
"is_run": None, "data": self.get_case_data(v), "dependence_case": False,
"assert": {"status_code": 200}, "sql": None}}
self.yaml_cases(yaml_data, file_path=key)
testcase_template.py # 测试用例模板
"""
# @describe: 用例模板
"""
import datetime
import os
from utils.read_files_tools.yaml_control import GetYamlData
from common.setting import ensure_path_sep
from utils.other_tools.exceptions import ValueNotFoundError
def write_case(case_path, page):
""" 写入用例数据 """
with open(case_path, 'w', encoding="utf-8") as file:
file.write(page)
def write_testcase_file(*, allure_epic, allure_feature, class_title,
func_title, case_path, case_ids, file_name, allure_story):
"""
:param allure_story:
:param file_name: 文件名称
:param allure_epic: 项目名称
:param allure_feature: 模块名称
:param class_title: 类名称
:param func_title: 函数名称
:param case_path: case 路径
:param case_ids: 用例ID
:return:
"""
conf_data = GetYamlData(ensure_path_sep("\\common\\config.yaml")).get_yaml_data()
author = conf_data['tester_name']
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
real_time_update_test_cases = conf_data['real_time_update_test_cases']
page = f'''#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : {now}
# @Author : {author}
import allure
import pytest
from utils.read_files_tools.get_yaml_data_analysis import GetTestCase
from utils.assertion.assert_control import Assert
from utils.requests_tool.request_control import RequestControl
from utils.read_files_tools.regular_control import regular
from utils.requests_tool.teardown_control import TearDownHandler
case_id = {case_ids}
TestData = GetTestCase.case_data(case_id)
re_data = regular(str(TestData))
@allure.epic("{allure_epic}")
@allure.feature("{allure_feature}")
class Test{class_title}:
@allure.story("{allure_story}")
@pytest.mark.parametrize('in_data', eval(re_data), ids=[i['detail'] for i in TestData])
def test_{func_title}(self, in_data, case_skip):
"""
:param :
:return:
"""
res = RequestControl(in_data).http_request()
TearDownHandler(res).teardown_handle()
Assert(assert_data=in_data['assert_data'],
sql_data=res.sql_data,
request_data=res.body,
response_data=res.response_data,
status_code=res.status_code).assert_type_handle()
yaml_control.py # yaml文件读写
import os
import ast
import yaml.scanner
from utils.read_files_tools.regular_control import regular
class GetYamlData:
""" 获取 yaml 文件中的数据 """
def __init__(self, file_dir):
self.file_dir = str(file_dir)
def get_yaml_data(self) -> dict:
"""
获取 yaml 中的数据
:param: fileDir:
:return:
"""
# 判断文件是否存在
if os.path.exists(self.file_dir):
data = open(self.file_dir, 'r', encoding='utf-8')
res = yaml.load(data, Loader=yaml.FullLoader)
else:
raise FileNotFoundError("文件路径不存在")
return res
def write_yaml_data(self, key: str, value) -> int:
"""
更改 yaml 文件中的值, 并且保留注释内容
:param key: 字典的key
:param value: 写入的值
:return:
"""
with open(self.file_dir, 'r', encoding='utf-8') as file:
# 创建了一个空列表,里面没有元素
lines = []
for line in file.readlines():
if line != '\n':
lines.append(line)
file.close()
with open(self.file_dir, 'w', encoding='utf-8') as file:
flag = 0
for line in lines:
left_str = line.split(":")[0]
if key == left_str.lstrip() and '#' not in line:
newline = f"{left_str}: {value}"
line = newline
file.write(f'{line}\n')
flag = 1
else:
file.write(f'{line}')
file.close()
return flag
class GetCaseData(GetYamlData):
""" 获取测试用例中的数据 """
def get_different_formats_yaml_data(self) -> list:
"""
获取兼容不同格式的yaml数据
:return:
"""
res_list = []
for i in self.get_yaml_data():
res_list.append(i)
return res_list
def get_yaml_case_data(self):
"""
获取测试用例数据, 转换成指定数据格式
:return:
"""
_yaml_data = self.get_yaml_data()
# 正则处理yaml文件中的数据
re_data = regular(str(_yaml_data))
return ast.literal_eval(re_data)
recording # 代理录制
mitmproxy_control.py # mitmproxy库拦截获取网络请求
from urllib.parse import parse_qs, urlparse
from typing import Any, Union, Text, List, Dict, Tuple
import ast
import os
import mitmproxy.http
from mitmproxy import ctx
from ruamel import yaml
class Counter:
"""
代理录制,基于 mitmproxy 库拦截获取网络请求
将接口请求数据转换成 yaml 测试用例
参考资料: https://blog.wolfogre.com/posts/usage-of-mitmproxy/
"""
def __init__(self, filter_url: List, filename: Text = './data/proxy_data.yaml'):
self.num = 0
self.file = filename
self.counter = 1
# 需要过滤的 url
self.url = filter_url
def response(self, flow: mitmproxy.http.HTTPFlow) -> None:
"""
mitmproxy抓包处理响应,在这里汇总需要数据, 过滤 包含指定url,并且响应格式是 json的
:param flow:
:return:
"""
# 存放需要过滤的接口
filter_url_type = ['.css', '.js', '.map', '.ico', '.png', '.woff', '.map3', '.jpeg', '.jpg']
url = flow.request.url
ctx.log.info("=" * 100)
# 判断过滤掉含 filter_url_type 中后缀的 url
if any(i in url for i in filter_url_type) is False:
# 存放测试用例
if self.filter_url(url):
data = self.data_handle(flow.request.text)
method = flow.request.method
header = self.token_handle(flow.request.headers)
response = flow.response.text
case_id = self.get_case_id(url) + str(self.counter)
cases = {
case_id: {
"host": self.host_handle(url),
"url": self.url_path_handle(url),
"method": method,
"detail": None,
"headers": header,
'requestType': self.request_type_handler(method),
"is_run": True,
"data": data,
"dependence_case": None,
"dependence_case_data": None,
"assert": self.response_code_handler(response),
"sql": None
}
}
# 判断如果请求参数时拼接在url中,提取url中参数,转换成字典
if "?" in url:
cases[case_id]['url'] = self.get_url_handler(url)[1]
cases[case_id]['data'] = self.get_url_handler(url)[0]
ctx.log.info("=" * 100)
ctx.log.info(cases)
# 判断文件不存在则创建文件
try:
self.yaml_cases(cases)
except FileNotFoundError:
os.makedirs(self.file)
self.counter += 1
@classmethod
def get_case_id(cls, url: Text) -> Text:
"""
通过url,提取对应的user_id
:param url:
:return:
"""
_url_path = str(url).split('?')[0]
# 通过url中的接口地址,最后一个参数,作为case_id的名称
_url = _url_path.split('/')
return _url[-1]
def filter_url(self, url: Text) -> bool:
"""过滤url"""
for i in self.url:
# 判断当前拦截的url地址,是否是addons中配置的host
if i in url:
# 如果是,则返回True
return True
# 否则返回 False
return False
@classmethod
def response_code_handler(cls, response) -> Union[Dict, None]:
"""
处理接口响应,默认断言数据为code码,如果接口没有code码,则返回None
@param response:
@return:
"""
try:
data = cls.data_handle(response)
return {"code": {"jsonpath": "$.code", "type": "==",
"value": data['code'], "AssertType": None}}
except KeyError:
return None
except NameError:
return None
@classmethod
def request_type_handler(cls, method: Text) -> Text:
""" 处理请求类型,有params、json、file,需要根据公司的业务情况自己调整 """
if method == 'GET':
# 如我们公司只有get请求是prams,其他都是json的
return 'params'
return 'json'
@classmethod
def data_handle(cls, dict_str) -> Any:
"""处理接口请求、响应的数据,如null、true格式问题"""
try:
if dict_str != "":
if 'null' in dict_str:
dict_str = dict_str.replace('null', 'None')
if 'true' in dict_str:
dict_str = dict_str.replace('true', 'True')
if 'false' in dict_str:
dict_str = dict_str.replace('false', 'False')
dict_str = ast.literal_eval(dict_str)
if dict_str == "":
dict_str = None
return dict_str
except Exception as exc:
raise exc
@classmethod
def token_handle(cls, header) -> Dict:
"""
提取请求头参数
:param header:
:return:
"""
# 这里是将所有请求头的数据,全部都拦截出来了
# 如果公司只需要部分参数,可以在这里加判断过滤
headers = {}
for key, value in header.items():
headers[key] = value
return headers
def host_handle(self, url: Text) -> Tuple:
"""
解析 url
:param url: https://xxxx.test.xxxx.com/#/goods/listShop
:return: https://xxxx.test.xxxx.com/
"""
host = None
# 循环遍历需要过滤的hosts数据
for i in self.url:
# 这里主要是判断,如果我们conf.py中有配置这个域名,则用例中展示 ”${{host}}“,动态获取用例host
# 大家可以在这里改成自己公司的host地址
if 'https://www.wanandroid.com' in url:
host = '${{host}}'
elif i in url:
host = i
return host
def url_path_handle(self, url: Text):
"""
解析 url_path
:param url: https://xxxx.test.xxxx.com/shopList/json
:return: /shopList/json
"""
url_path = None
# 循环需要拦截的域名
for path in self.url:
if path in url:
url_path = url.split(path)[-1]
return url_path
def yaml_cases(self, data: Dict) -> None:
"""
写入 yaml 数据
:param data: 测试用例数据
:return:
"""
with open(self.file, "a", encoding="utf-8") as file:
yaml.dump(data, file, Dumper=yaml.RoundTripDumper, allow_unicode=True)
file.write('\n')
def get_url_handler(self, url: Text) -> Tuple:
"""
将 url 中的参数 转换成字典
:param url: /trade?tradeNo=&outTradeId=11
:return: {“outTradeId”: 11}
"""
result = None
url_path = None
for i in self.url:
if i in url:
query = urlparse(url).query
# 将字符串转换为字典
params = parse_qs(query)
# 所得的字典的value都是以列表的形式存在,如请求url中的参数值为空,则字典中不会有该参数
result = {key: params[key][0] for key in params}
url = url[0:url.rfind('?')]
url_path = url.split(i)[-1]
return result, url_path
# 1、本机需要设置代理,默认端口为: 8080
# 2、控制台输入 mitmweb -s .\utils\recording\mitmproxy_control.py - p 8888命令开启代理模式进行录制
addons = [
Counter(["https://www.wanandroid.com"])
]
requests_tool # 请求数据模块
dependent_case.py # 数据依赖处理
import ast
import json
from typing import Text, Dict, Union, List
from jsonpath import jsonpath
from utils.requests_tool.request_control import RequestControl
from utils.mysql_tool.mysql_control import SetUpMySQL
from utils.read_files_tools.regular_control import regular, cache_regular
from utils.other_tools.jsonpath_date_replace import jsonpath_replace
from utils.logging_tool.log_control import WARNING
from utils.other_tools.models import DependentType
from utils.other_tools.models import TestCase, DependentCaseData, DependentData
from utils.other_tools.exceptions import ValueNotFoundError
from utils.cache_process.cache_control import CacheHandler
from utils import config
class DependentCase:
""" 处理依赖相关的业务 """
def __init__(self, dependent_yaml_case: TestCase):
self.__yaml_case = dependent_yaml_case
@classmethod
def get_cache(cls, case_id: Text) -> Dict:
"""
获取缓存用例池中的数据,通过 case_id 提取
:param case_id:
:return: case_id_01
"""
_case_data = CacheHandler.get_cache(case_id)
return _case_data
@classmethod
def jsonpath_data(
cls,
obj: Dict,
expr: Text) -> list:
"""
通过jsonpath提取依赖的数据
:param obj: 对象信息
:param expr: jsonpath 方法
:return: 提取到的内容值,返回是个数组
对象: {"data": applyID} --> jsonpath提取方法: $.data.data.[0].applyId
"""
_jsonpath_data = jsonpath(obj, expr)
# 判断是否正常提取到数据,如未提取到,则抛异常
if _jsonpath_data is False:
raise ValueNotFoundError(
f"jsonpath提取失败!\n 提取的数据: {obj} \n jsonpath规则: {expr}"
)
return _jsonpath_data
@classmethod
def set_cache_value(cls, dependent_data: "DependentData") -> Union[Text, None]:
"""
获取依赖中是否需要将数据存入缓存中
"""
try:
return dependent_data.set_cache
except KeyError:
return None
@classmethod
def replace_key(cls, dependent_data: "DependentData"):
""" 获取需要替换的内容 """
try:
_replace_key = dependent_data.replace_key
return _replace_key
except KeyError:
return None
def url_replace(
self,
replace_key: Text,
jsonpath_dates: Dict,
jsonpath_data: list) -> None:
"""
url中的动态参数替换
# 如: 一般有些接口的参数在url中,并且没有参数名称, /api/v1/work/spu/approval/spuApplyDetails/{id}
# 那么可以使用如下方式编写用例, 可以使用 $url_params{}替换,
# 如/api/v1/work/spu/approval/spuApplyDetails/$url_params{id}
:param jsonpath_data: jsonpath 解析出来的数据值
:param replace_key: 用例中需要替换数据的 replace_key
:param jsonpath_dates: jsonpath 存放的数据值
:return:
"""
if "$url_param" in replace_key:
_url = self.__yaml_case.url.replace(replace_key, str(jsonpath_data[0]))
jsonpath_dates['$.url'] = _url
else:
jsonpath_dates[replace_key] = jsonpath_data[0]
def _dependent_type_for_sql(
self,
setup_sql: List,
dependence_case_data: "DependentCaseData",
jsonpath_dates: Dict) -> None:
"""
判断依赖类型为 sql,程序中的依赖参数从 数据库中提取数据
@param setup_sql: 前置sql语句
@param dependence_case_data: 依赖的数据
@param jsonpath_dates: 依赖相关的用例数据
@return:
"""
# 判断依赖数据类型,依赖 sql中的数据
if setup_sql is not None:
if config.mysql_db.switch:
setup_sql = ast.literal_eval(cache_regular(str(setup_sql)))
sql_data = SetUpMySQL().setup_sql_data(sql=setup_sql)
dependent_data = dependence_case_data.dependent_data
for i in dependent_data:
_jsonpath = i.jsonpath
jsonpath_data = self.jsonpath_data(obj=sql_data, expr=_jsonpath)
_set_value = self.set_cache_value(i)
_replace_key = self.replace_key(i)
if _set_value is not None:
CacheHandler.update_cache(cache_name=_set_value, value=jsonpath_data[0])
# cache(_set_value).set_caches(jsonpath_data[0])
if _replace_key is not None:
jsonpath_dates[_replace_key] = jsonpath_data[0]
self.url_replace(
replace_key=_replace_key,
jsonpath_dates=jsonpath_dates,
jsonpath_data=jsonpath_data,
)
else:
WARNING.logger.warning("检查到数据库开关为关闭状态,请确认配置")
def dependent_handler(
self,
_jsonpath: Text,
set_value: Text,
replace_key: Text,
jsonpath_dates: Dict,
data: Dict,
dependent_type: int
) -> None:
""" 处理数据替换 """
jsonpath_data = self.jsonpath_data(
data,
_jsonpath
)
if set_value is not None:
if len(jsonpath_data) > 1:
CacheHandler.update_cache(cache_name=set_value, value=jsonpath_data)
else:
CacheHandler.update_cache(cache_name=set_value, value=jsonpath_data[0])
if replace_key is not None:
if dependent_type == 0:
jsonpath_dates[replace_key] = jsonpath_data[0]
self.url_replace(replace_key=replace_key, jsonpath_dates=jsonpath_dates,
jsonpath_data=jsonpath_data)
def is_dependent(self) -> Union[Dict, bool]:
"""
判断是否有数据依赖
:return:
"""
# 获取用例中的dependent_type值,判断该用例是否需要执行依赖
_dependent_type = self.__yaml_case.dependence_case
# 获取依赖用例数据
_dependence_case_dates = self.__yaml_case.dependence_case_data
_setup_sql = self.__yaml_case.setup_sql
# 判断是否有依赖
if _dependent_type is True:
# 读取依赖相关的用例数据
jsonpath_dates = {}
# 循环所有需要依赖的数据
try:
for dependence_case_data in _dependence_case_dates:
_case_id = dependence_case_data.case_id
# 判断依赖数据为sql,case_id需要写成self,否则程序中无法获取case_id
if _case_id == 'self':
self._dependent_type_for_sql(
setup_sql=_setup_sql,
dependence_case_data=dependence_case_data,
jsonpath_dates=jsonpath_dates)
else:
re_data = regular(str(self.get_cache(_case_id)))
re_data = ast.literal_eval(cache_regular(str(re_data)))
res = RequestControl(re_data).http_request()
if dependence_case_data.dependent_data is not None:
dependent_data = dependence_case_data.dependent_data
for i in dependent_data:
_case_id = dependence_case_data.case_id
_jsonpath = i.jsonpath
_request_data = self.__yaml_case.data
_replace_key = self.replace_key(i)
_set_value = self.set_cache_value(i)
# 判断依赖数据类型, 依赖 response 中的数据
if i.dependent_type == DependentType.RESPONSE.value:
self.dependent_handler(
data=json.loads(res.response_data),
_jsonpath=_jsonpath,
set_value=_set_value,
replace_key=_replace_key,
jsonpath_dates=jsonpath_dates,
dependent_type=0
)
# 判断依赖数据类型, 依赖 request 中的数据
elif i.dependent_type == DependentType.REQUEST.value:
self.dependent_handler(
data=res.body,
_jsonpath=_jsonpath,
set_value=_set_value,
replace_key=_replace_key,
jsonpath_dates=jsonpath_dates,
dependent_type=1
)
else:
raise ValueError(
"依赖的dependent_type不正确,只支持request、response、sql依赖\n"
f"当前填写内容: {i.dependent_type}"
)
return jsonpath_dates
except KeyError as exc:
# pass
raise ValueNotFoundError(
f"dependence_case_data依赖用例中,未找到 {exc} 参数,请检查是否填写"
f"如已填写,请检查是否存在yaml缩进问题"
) from exc
except TypeError as exc:
raise ValueNotFoundError(
"dependence_case_data下的所有内容均不能为空!"
"请检查相关数据是否填写,如已填写,请检查缩进问题"
) from exc
else:
return False
def get_dependent_data(self) -> None:
"""
jsonpath 和 依赖的数据,进行替换
:return:
"""
_dependent_data = DependentCase(self.__yaml_case).is_dependent()
_new_data = None
# 判断有依赖
if _dependent_data is not None and _dependent_data is not False:
# if _dependent_data is not False:
for key, value in _dependent_data.items():
# 通过jsonpath判断出需要替换数据的位置
_change_data = key.split(".")
# jsonpath 数据解析
# 不要删 这个yaml_case
yaml_case = self.__yaml_case
_new_data = jsonpath_replace(change_data=_change_data, key_name='yaml_case')
# 最终提取到的数据,转换成 __yaml_case.data
_new_data += ' = ' + str(value)
exec(_new_data)
encryption_algorithm_control.py # 加密算法
import hashlib
from hashlib import sha256
import hmac
from typing import Text
import binascii
from pyDes import des, ECB, PAD_PKCS5
def hmac_sha256_encrypt(key, data):
"""hmac sha 256算法"""
_key = key.encode('utf8')
_data = data.encode('utf8')
encrypt_data = hmac.new(_key, _data, digestmod=sha256).hexdigest()
return encrypt_data
def md5_encryption(value):
""" md5 加密"""
str_md5 = hashlib.md5(str(value).encode(encoding='utf-8')).hexdigest()
return str_md5
def sha1_secret_str(_str: Text):
"""
使用sha1加密算法,返回str加密后的字符串
"""
encrypts = hashlib.sha1(_str.encode('utf-8')).hexdigest()
return encrypts
def des_encrypt(_str):
"""
DES 加密
:return: 加密后字符串,16进制
"""
# 密钥,自行修改
_key = 'PASSWORD'
secret_key = _key
_iv = secret_key
key = des(secret_key, ECB, _iv, pad=None, padmode=PAD_PKCS5)
_encrypt = key.encrypt(_str, padmode=PAD_PKCS5)
return binascii.b2a_hex(_encrypt)
def encryption(ency_type):
"""
:param ency_type: 加密类型
:return:
"""
def decorator(func):
def swapper(*args, **kwargs):
res = func(*args, **kwargs)
_data = res['body']
if ency_type == "md5":
def ency_value(data):
if data is not None:
for key, value in data.items():
if isinstance(value, dict):
ency_value(data=value)
else:
data[key] = md5_encryption(value)
else:
raise ValueError("暂不支持该加密规则,如有需要,请联系管理员")
ency_value(_data)
return res
return swapper
return decorator
request_control.py # 请求封装
import ast
import os
import random
import time
import urllib
from typing import Tuple, Dict, Union, Text
import requests
import urllib3
from requests_toolbelt import MultipartEncoder
from common.setting import ensure_path_sep
from utils.other_tools.models import RequestType
from utils.logging_tool.log_decorator import log_decorator
from utils.mysql_tool.mysql_control import AssertExecution
from utils.logging_tool.run_time_decorator import execution_duration
from utils.other_tools.allure_data.allure_tools import allure_step, allure_step_no, allure_attach
from utils.read_files_tools.regular_control import cache_regular
from utils.requests_tool.set_current_request_cache import SetCurrentRequestCache
from utils.other_tools.models import TestCase, ResponseData
from utils import config
# from utils.requests_tool.encryption_algorithm_control import encryption
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class RequestControl:
""" 封装请求 """
def __init__(self, yaml_case):
self.__yaml_case = TestCase(**yaml_case)
def file_data_exit(
self,
file_data) -> None:
"""判断上传文件时,data参数是否存在"""
# 兼容又要上传文件,又要上传其他类型参数
try:
_data = self.__yaml_case.data
for key, value in ast.literal_eval(cache_regular(str(_data)))['data'].items():
if "multipart/form-data" in str(self.__yaml_case.headers.values()):
file_data[key] = str(value)
else:
file_data[key] = value
except KeyError:
...
@classmethod
def multipart_data(
cls,
file_data: Dict):
""" 处理上传文件数据 """
multipart = MultipartEncoder(
fields=file_data, # 字典格式
boundary='-----------------------------' + str(random.randint(int(1e28), int(1e29 - 1)))
)
return multipart
@classmethod
def check_headers_str_null(
cls,
headers: Dict) -> Dict:
"""
兼容用户未填写headers或者header值为int
@return:
"""
headers = ast.literal_eval(cache_regular(str(headers)))
if headers is None:
headers = {"headers": None}
else:
for key, value in headers.items():
if not isinstance(value, str):
headers[key] = str(value)
return headers
@classmethod
def multipart_in_headers(
cls,
request_data: Dict,
header: Dict):
""" 判断处理header为 Content-Type: multipart/form-data"""
header = ast.literal_eval(cache_regular(str(header)))
request_data = ast.literal_eval(cache_regular(str(request_data)))
if header is None:
header = {"headers": None}
else:
# 将header中的int转换成str
for key, value in header.items():
if not isinstance(value, str):
header[key] = str(value)
if "multipart/form-data" in str(header.values()):
# 判断请求参数不为空, 并且参数是字典类型
if request_data and isinstance(request_data, dict):
# 当 Content-Type 为 "multipart/form-data"时,需要将数据类型转换成 str
for key, value in request_data.items():
if not isinstance(value, str):
request_data[key] = str(value)
request_data = MultipartEncoder(request_data)
header['Content-Type'] = request_data.content_type
return request_data, header
def file_prams_exit(self) -> Dict:
"""判断上传文件接口,文件参数是否存在"""
try:
params = self.__yaml_case.data['params']
except KeyError:
params = None
return params
@classmethod
def text_encode(
cls,
text: Text) -> Text:
"""unicode 解码"""
return text.encode("utf-8").decode("utf-8")
@classmethod
def response_elapsed_total_seconds(
cls,
res) -> float:
"""获取接口响应时长"""
try:
return round(res.elapsed.total_seconds() * 1000, 2)
except AttributeError:
return 0.00
def upload_file(
self) -> Tuple:
"""
判断处理上传文件
:return:
"""
# 处理上传多个文件的情况
_files = []
file_data = {}
# 兼容又要上传文件,又要上传其他类型参数
self.file_data_exit(file_data)
_data = self.__yaml_case.data
for key, value in ast.literal_eval(cache_regular(str(_data)))['file'].items():
file_path = ensure_path_sep("\\Files\\" + value)
file_data[key] = (value, open(file_path, 'rb'), 'application/octet-stream')
_files.append(file_data)
# allure中展示该附件
allure_attach(source=file_path, name=value, extension=value)
multipart = self.multipart_data(file_data)
# ast.literal_eval(cache_regular(str(_headers)))['Content-Type'] = multipart.content_type
self.__yaml_case.headers['Content-Type'] = multipart.content_type
params_data = ast.literal_eval(cache_regular(str(self.file_prams_exit())))
return multipart, params_data, self.__yaml_case
def request_type_for_json(
self,
headers: Dict,
method: Text,
**kwargs):
""" 判断请求类型为json格式 """
_headers = self.check_headers_str_null(headers)
_data = self.__yaml_case.data
_url = self.__yaml_case.url
res = requests.request(
method=method,
url=cache_regular(str(_url)),
json=ast.literal_eval(cache_regular(str(_data))),
data={},
headers=_headers,
verify=False,
params=None,
**kwargs
)
return res
def request_type_for_none(
self,
headers: Dict,
method: Text,
**kwargs) -> object:
"""判断 requestType 为 None"""
_headers = self.check_headers_str_null(headers)
_url = self.__yaml_case.url
res = requests.request(
method=method,
url=cache_regular(_url),
data=None,
headers=_headers,
verify=False,
params=None,
**kwargs
)
return res
def request_type_for_params(
self,
headers: Dict,
method: Text,
**kwargs):
"""处理 requestType 为 params """
_data = self.__yaml_case.data
url = self.__yaml_case.url
if _data is not None:
# url 拼接的方式传参
params_data = "?"
for key, value in _data.items():
if value is None or value == '':
params_data += (key + "&")
else:
params_data += (key + "=" + str(value) + "&")
url = self.__yaml_case.url + params_data[:-1]
_headers = self.check_headers_str_null(headers)
res = requests.request(
method=method,
url=cache_regular(url),
headers=_headers,
verify=False,
data={},
params=None,
**kwargs)
return res
def request_type_for_file(
self,
method: Text,
headers,
**kwargs):
"""处理 requestType 为 file 类型"""
multipart = self.upload_file()
yaml_data = multipart[2]
_headers = multipart[2].headers
_headers = self.check_headers_str_null(_headers)
res = requests.request(
method=method,
url=cache_regular(yaml_data.url),
data=multipart[0],
params=multipart[1],
headers=ast.literal_eval(cache_regular(str(_headers))),
verify=False,
**kwargs
)
return res
def request_type_for_data(
self,
headers: Dict,
method: Text,
**kwargs):
"""判断 requestType 为 data 类型"""
data = self.__yaml_case.data
_data, _headers = self.multipart_in_headers(
ast.literal_eval(cache_regular(str(data))),
headers
)
_url = self.__yaml_case.url
res = requests.request(
method=method,
url=cache_regular(_url),
data=_data,
headers=_headers,
verify=False,
**kwargs)
return res
@classmethod
def get_export_api_filename(cls, res):
""" 处理导出文件 """
content_disposition = res.headers.get('content-disposition')
filename_code = content_disposition.split("=")[-1] # 分隔字符串,提取文件名
filename = urllib.parse.unquote(filename_code) # url解码
return filename
def request_type_for_export(
self,
headers: Dict,
method: Text,
**kwargs):
"""判断 requestType 为 export 导出类型"""
_headers = self.check_headers_str_null(headers)
_data = self.__yaml_case.data
_url = self.__yaml_case.url
res = requests.request(
method=method,
url=cache_regular(_url),
json=ast.literal_eval(cache_regular(str(_data))),
headers=_headers,
verify=False,
stream=False,
data={},
**kwargs)
filepath = os.path.join(ensure_path_sep("\\Files\\"), self.get_export_api_filename(res)) # 拼接路径
if res.status_code == 200:
if res.text: # 判断文件内容是否为空
with open(filepath, 'wb') as file:
# iter_content循环读取信息写入,chunk_size设置文件大小
for chunk in res.iter_content(chunk_size=1):
file.write(chunk)
else:
print("文件为空")
return res
@classmethod
def _request_body_handler(cls, data: Dict, request_type: Text) -> Union[None, Dict]:
"""处理请求参数 """
if request_type.upper() == 'PARAMS':
return None
else:
return data
@classmethod
def _sql_data_handler(cls, sql_data, res):
"""处理 sql 参数 """
# 判断数据库开关,开启状态,则返回对应的数据
if config.mysql_db.switch and sql_data is not None:
sql_data = AssertExecution().assert_execution(
sql=sql_data,
resp=res.json()
)
else:
sql_data = {"sql": None}
return sql_data
def _check_params(
self,
res,
yaml_data: "TestCase",
) -> "ResponseData":
data = ast.literal_eval(cache_regular(str(yaml_data.data)))
_data = {
"url": res.url,
"is_run": yaml_data.is_run,
"detail": yaml_data.detail,
"response_data": res.text,
# 这个用于日志专用,判断如果是get请求,直接打印url
"request_body": self._request_body_handler(
data, yaml_data.requestType
),
"method": res.request.method,
"sql_data": self._sql_data_handler(sql_data=ast.literal_eval(cache_regular(str(yaml_data.sql))), res=res),
"yaml_data": yaml_data,
"headers": res.request.headers,
"cookie": res.cookies,
"assert_data": yaml_data.assert_data,
"res_time": self.response_elapsed_total_seconds(res),
"status_code": res.status_code,
"teardown": yaml_data.teardown,
"teardown_sql": yaml_data.teardown_sql,
"body": data
}
# 抽离出通用模块,判断 http_request 方法中的一些数据校验
return ResponseData(**_data)
@classmethod
def api_allure_step(
cls,
*,
url: Text,
headers: Text,
method: Text,
data: Text,
assert_data: Text,
res_time: Text,
res: Text
) -> None:
""" 在allure中记录请求数据 """
allure_step_no(f"请求URL: {url}")
allure_step_no(f"请求方式: {method}")
allure_step("请求头: ", headers)
allure_step("请求数据: ", data)
allure_step("预期数据: ", assert_data)
_res_time = res_time
allure_step_no(f"响应耗时(ms): {str(_res_time)}")
allure_step("响应结果: ", res)
@log_decorator(True)
@execution_duration(3000)
# @encryption("md5")
def http_request(
self,
dependent_switch=True,
**kwargs
):
"""
请求封装
:param dependent_switch:
:param kwargs:
:return:
"""
from utils.requests_tool.dependent_case import DependentCase
requests_type_mapping = {
RequestType.JSON.value: self.request_type_for_json,
RequestType.NONE.value: self.request_type_for_none,
RequestType.PARAMS.value: self.request_type_for_params,
RequestType.FILE.value: self.request_type_for_file,
RequestType.DATA.value: self.request_type_for_data,
RequestType.EXPORT.value: self.request_type_for_export
}
is_run = ast.literal_eval(cache_regular(str(self.__yaml_case.is_run)))
# 判断用例是否执行
if is_run is True or is_run is None:
# 处理多业务逻辑
if dependent_switch is True:
DependentCase(self.__yaml_case).get_dependent_data()
res = requests_type_mapping.get(self.__yaml_case.requestType)(
headers=self.__yaml_case.headers,
method=self.__yaml_case.method,
**kwargs
)
if self.__yaml_case.sleep is not None:
time.sleep(self.__yaml_case.sleep)
_res_data = self._check_params(
res=res,
yaml_data=self.__yaml_case)
self.api_allure_step(
url=_res_data.url,
headers=str(_res_data.headers),
method=_res_data.method,
data=str(_res_data.body),
assert_data=str(_res_data.assert_data),
res_time=str(_res_data.res_time),
res=_res_data.response_data
)
# 将当前请求数据存入缓存中
SetCurrentRequestCache(
current_request_set_cache=self.__yaml_case.current_request_set_cache,
request_data=self.__yaml_case.data,
response_data=res
).set_caches_main()
return _res_data
set_current_request_cache.py # 缓存设置
import json
from typing import Text
from jsonpath import jsonpath
from utils.other_tools.exceptions import ValueNotFoundError
from utils.cache_process.cache_control import CacheHandler
class SetCurrentRequestCache:
"""将用例中的请求或者响应内容存入缓存"""
def __init__(
self,
current_request_set_cache,
request_data,
response_data
):
self.current_request_set_cache = current_request_set_cache
self.request_data = {"data": request_data}
self.response_data = response_data.text
def set_request_cache(
self,
jsonpath_value: Text,
cache_name: Text) -> None:
"""将接口的请求参数存入缓存"""
_request_data = jsonpath(
self.request_data,
jsonpath_value
)
if _request_data is not False:
CacheHandler.update_cache(cache_name=cache_name, value=_request_data[0])
# cache(cache_name).set_caches(_request_data[0])
else:
raise ValueNotFoundError(
"缓存设置失败,程序中未检测到需要缓存的数据。"
f"请求参数: {self.request_data}"
f"提取的 jsonpath 内容: {jsonpath_value}"
)
def set_response_cache(
self,
jsonpath_value: Text,
cache_name
):
"""将响应结果存入缓存"""
_response_data = jsonpath(json.loads(self.response_data), jsonpath_value)
if _response_data is not False:
CacheHandler.update_cache(cache_name=cache_name, value=_response_data[0])
# cache(cache_name).set_caches(_response_data[0])
else:
raise ValueNotFoundError("缓存设置失败,程序中未检测到需要缓存的数据。"
f"请求参数: {self.response_data}"
f"提取的 jsonpath 内容: {jsonpath_value}")
def set_caches_main(self):
"""设置缓存"""
if self.current_request_set_cache is not None:
for i in self.current_request_set_cache:
_jsonpath = i.jsonpath
_cache_name = i.name
if i.type == 'request':
self.set_request_cache(jsonpath_value=_jsonpath, cache_name=_cache_name)
elif i.type == 'response':
self.set_response_cache(jsonpath_value=_jsonpath, cache_name=_cache_name)
teardown_control.py # 请求处理
"""
# @describe: 请求后置处理
"""
import ast
import json
from typing import Dict, Text
from jsonpath import jsonpath
from utils.requests_tool.request_control import RequestControl
from utils.read_files_tools.regular_control import cache_regular, sql_regular, regular
from utils.other_tools.jsonpath_date_replace import jsonpath_replace
from utils.mysql_tool.mysql_control import MysqlDB
from utils.logging_tool.log_control import WARNING
from utils.other_tools.models import ResponseData, TearDown, SendRequest, ParamPrepare
from utils.other_tools.exceptions import JsonpathExtractionFailed, ValueNotFoundError
from utils.cache_process.cache_control import CacheHandler
from utils import config
class TearDownHandler:
""" 处理yaml格式后置请求 """
def __init__(self, res: "ResponseData"):
self._res = res
@classmethod
def jsonpath_replace_data(
cls,
replace_key: Text,
replace_value: Dict) -> Text:
""" 通过jsonpath判断出需要替换数据的位置 """
_change_data = replace_key.split(".")
# jsonpath 数据解析
_new_data = jsonpath_replace(
change_data=_change_data,
key_name='_teardown_case',
data_switch=False
)
if not isinstance(replace_value, str):
_new_data += f" = {replace_value}"
# 最终提取到的数据,转换成 _teardown_case[xxx][xxx]
else:
_new_data += f" = '{replace_value}'"
return _new_data
@classmethod
def get_cache_name(
cls,
replace_key: Text,
resp_case_data: Dict) -> None:
"""
获取缓存名称,并且讲提取到的数据写入缓存
"""
if "$set_cache{" in replace_key and "}" in replace_key:
start_index = replace_key.index("$set_cache{")
end_index = replace_key.index("}", start_index)
old_value = replace_key[start_index:end_index + 2]
cache_name = old_value[11:old_value.index("}")]
CacheHandler.update_cache(cache_name=cache_name, value=resp_case_data)
# cache(cache_name).set_caches(resp_case_data)
@classmethod
def regular_testcase(cls, teardown_case: Dict) -> Dict:
"""处理测试用例中的动态数据"""
test_case = regular(str(teardown_case))
test_case = ast.literal_eval(cache_regular(str(test_case)))
return test_case
@classmethod
def teardown_http_requests(cls, teardown_case: Dict) -> "ResponseData":
"""
发送后置请求
@param teardown_case: 后置用例
@return:
"""
test_case = cls.regular_testcase(teardown_case)
res = RequestControl(test_case).http_request(
dependent_switch=False
)
return res
def dependent_type_response(
self,
teardown_case_data: "SendRequest",
resp_data: Dict) -> Text:
"""
判断依赖类型为当前执行用例响应内容
:param : teardown_case_data: teardown中的用例内容
:param : resp_data: 需要替换的内容
:return:
"""
_replace_key = teardown_case_data.replace_key
_response_dependent = jsonpath(
obj=resp_data,
expr=teardown_case_data.jsonpath
)
# 如果提取到数据,则进行下一步
if _response_dependent is not False:
_resp_case_data = _response_dependent[0]
data = self.jsonpath_replace_data(
replace_key=_replace_key,
replace_value=_resp_case_data
)
else:
raise JsonpathExtractionFailed(
f"jsonpath提取失败,替换内容: {resp_data} \n"
f"jsonpath: {teardown_case_data.jsonpath}"
)
return data
def dependent_type_request(
self,
teardown_case_data: Dict,
request_data: Dict) -> None:
"""
判断依赖类型为请求内容
:param : teardown_case_data: teardown中的用例内容
:param : request_data: 需要替换的内容
:return:
"""
try:
_request_set_value = teardown_case_data['set_value']
_request_dependent = jsonpath(
obj=request_data,
expr=teardown_case_data['jsonpath']
)
if _request_dependent is not False:
_request_case_data = _request_dependent[0]
self.get_cache_name(
replace_key=_request_set_value,
resp_case_data=_request_case_data
)
else:
raise JsonpathExtractionFailed(
f"jsonpath提取失败,替换内容: {request_data} \n"
f"jsonpath: {teardown_case_data['jsonpath']}"
)
except KeyError as exc:
raise ValueNotFoundError("teardown中缺少set_value参数,请检查用例是否正确") from exc
def dependent_self_response(
self,
teardown_case_data: "ParamPrepare",
res: Dict,
resp_data: Dict) -> None:
"""
判断依赖类型为依赖用例ID自己响应的内容
:param : teardown_case_data: teardown中的用例内容
:param : resp_data: 需要替换的内容
:param : res: 接口响应的内容
:return:
"""
try:
_set_value = teardown_case_data.set_cache
_response_dependent = jsonpath(
obj=res,
expr=teardown_case_data.jsonpath
)
# 如果提取到数据,则进行下一步
if _response_dependent is not False:
_resp_case_data = _response_dependent[0]
# 拿到 set_cache 然后将数据写入缓存
# cache(_set_value).set_caches(_resp_case_data)
CacheHandler.update_cache(cache_name=_set_value, value=_resp_case_data)
self.get_cache_name(
replace_key=_set_value,
resp_case_data=_resp_case_data
)
else:
raise JsonpathExtractionFailed(
f"jsonpath提取失败,替换内容: {resp_data} \n"
f"jsonpath: {teardown_case_data.jsonpath}")
except KeyError as exc:
raise ValueNotFoundError("teardown中缺少set_cache参数,请检查用例是否正确") from exc
@classmethod
def dependent_type_cache(cls, teardown_case: "SendRequest") -> Text:
"""
判断依赖类型为从缓存中处理
:param : teardown_case_data: teardown中的用例内容
:return:
"""
if teardown_case.dependent_type == 'cache':
_cache_name = teardown_case.cache_data
_replace_key = teardown_case.replace_key
# 通过jsonpath判断出需要替换数据的位置
_change_data = _replace_key.split(".")
_new_data = jsonpath_replace(
change_data=_change_data,
key_name='_teardown_case',
data_switch=False
)
# jsonpath 数据解析
value_types = ['int:', 'bool:', 'list:', 'dict:', 'tuple:', 'float:']
if any(i in _cache_name for i in value_types) is True:
# _cache_data = cache(_cache_name.split(':')[1]).get_cache()
_cache_data = CacheHandler.get_cache(_cache_name.split(':')[1])
_new_data += f" = {_cache_data}"
# 最终提取到的数据,转换成 _teardown_case[xxx][xxx]
else:
# _cache_data = cache(_cache_name).get_cache()
_cache_data = CacheHandler.get_cache(_cache_name)
_new_data += f" = '{_cache_data}'"
return _new_data
def send_request_handler(
self, data: "TearDown",
resp_data: Dict,
request_data: Dict
) -> None:
"""
后置请求处理
@return:
"""
_send_request = data.send_request
_case_id = data.case_id
# _teardown_case = ast.literal_eval(cache('case_process').get_cache())[_case_id]
_teardown_case = CacheHandler.get_cache(_case_id)
for i in _send_request:
if i.dependent_type == 'cache':
exec(self.dependent_type_cache(teardown_case=i))
# 判断从响应内容提取数据
if i.dependent_type == 'response':
exec(
self.dependent_type_response(
teardown_case_data=i,
resp_data=resp_data)
)
# 判断请求中的数据
elif i.dependent_type == 'request':
self.dependent_type_request(
teardown_case_data=i,
request_data=request_data
)
test_case = self.regular_testcase(_teardown_case)
self.teardown_http_requests(test_case)
def param_prepare_request_handler(
self,
data: "TearDown",
resp_data: Dict) -> None:
"""
前置请求处理
@param data:
@param resp_data:
@return:
"""
_case_id = data.case_id
# _teardown_case = ast.literal_eval(cache('case_process').get_cache())[_case_id]
_teardown_case = CacheHandler.get_cache(_case_id)
_param_prepare = data.param_prepare
res = self.teardown_http_requests(_teardown_case)
for i in _param_prepare:
# 判断请求类型为自己,拿到当前case_id自己的响应
if i.dependent_type == 'self_response':
self.dependent_self_response(
teardown_case_data=i,
resp_data=resp_data,
res=json.loads(res.response_data)
)
def teardown_handle(self) -> None:
"""
为什么在这里需要单独区分 param_prepare 和 send_request
假设此时我们有用例A,teardown中我们需要执行用例B
那么考虑用户可能需要获取获取teardown的用例B的响应内容,也有可能需要获取用例A的响应内容,
因此我们这里需要通过关键词去做区分。这里需要考虑到,假设我们需要拿到B用例的响应,那么就需要先发送请求然后在拿到响应数据
那如果我们需要拿到A接口的响应,此时我们就不需要在额外发送请求了,因此我们需要区分一个是前置准备param_prepare,
一个是发送请求send_request
@return:
"""
# 拿到用例信息
_teardown_data = self._res.teardown
# 获取接口的响应内容
_resp_data = self._res.response_data
# 获取接口的请求参数
_request_data = self._res.yaml_data.data
# 判断如果没有 teardown
if _teardown_data is not None:
# 循环 teardown中的接口
for _data in _teardown_data:
if _data.param_prepare is not None:
self.param_prepare_request_handler(
data=_data,
resp_data=json.loads(_resp_data)
)
elif _data.send_request is not None:
self.send_request_handler(
data=_data,
request_data=_request_data,
resp_data=json.loads(_resp_data)
)
self.teardown_sql()
def teardown_sql(self) -> None:
"""处理后置sql"""
sql_data = self._res.teardown_sql
_response_data = self._res.response_data
if sql_data is not None:
for i in sql_data:
if config.mysql_db.switch:
_sql_data = sql_regular(value=i, res=json.loads(_response_data))
MysqlDB().execute(cache_regular(_sql_data))
else:
WARNING.logger.warning("程序中检查到您数据库开关为关闭状态,已为您跳过删除sql: %s", i)
times_tool # 时间模块
time_control.py # 时间设置
import time
from typing import Text
from datetime import datetime
def count_milliseconds():
"""
计算时间
:return:
"""
access_start = datetime.now()
access_end = datetime.now()
access_delta = (access_end - access_start).seconds * 1000
return access_delta
def timestamp_conversion(time_str: Text) -> int:
"""
时间戳转换,将日期格式转换成时间戳
:param time_str: 时间
:return:
"""
try:
datetime_format = datetime.strptime(str(time_str), "%Y-%m-%d %H:%M:%S")
timestamp = int(
time.mktime(datetime_format.timetuple()) * 1000.0
+ datetime_format.microsecond / 1000.0
)
return timestamp
except ValueError as exc:
raise ValueError('日期格式错误, 需要传入得格式为 "%Y-%m-%d %H:%M:%S" ') from exc
def time_conversion(time_num: int):
"""
时间戳转换成日期
:param time_num:
:return:
"""
if isinstance(time_num, int):
time_stamp = float(time_num / 1000)
time_array = time.localtime(time_stamp)
other_style_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
return other_style_time
def now_time():
"""
获取当前时间, 日期格式: 2021-12-11 12:39:25
:return:
"""
localtime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
return localtime
def now_time_day():
"""
获取当前时间, 日期格式: 2021-12-11
:return:
"""
localtime = time.strftime("%Y-%m-%d", time.localtime())
return localtime
def get_time_for_min(minute: int) -> int:
"""
获取几分钟后的时间戳
@param minute: 分钟
@return: N分钟后的时间戳
"""
return int(time.time() + 60 * minute) * 1000
def get_now_time() -> int:
"""
获取当前时间戳, 整形
@return: 当前时间戳
"""
return int(time.time()) * 1000
pytest.ini # Pytest 的配置文件
[pytest]
addopts = -p no:warnings
testpaths = test_case/
python_files = test_*.py
python_classes = Test*
python_function = test_*
markers =
smoke: 冒烟测试
run.py # 运行入口
import os
import traceback
import pytest
from utils.other_tools.models import NotificationType
from utils.other_tools.allure_data.allure_report_data import AllureFileClean
from utils.logging_tool.log_control import INFO
from utils.notify.wechat_send import WeChatSend
from utils.notify.ding_talk import DingTalkSendMsg
from utils.notify.send_mail import SendEmail
from utils.notify.lark import FeiShuTalkChatBot
from utils.other_tools.allure_data.error_case_excel import ErrorCaseExcel
from utils import config
def run():
# 从配置文件中获取项目名称
try:
INFO.logger.info(
"""
_
/\ (_)
/ \ _ __ _
/ /\ \ | '_ \| |
/ ____ \| |_) | |
/_/ \_\ .__/|_|
| |
|_|
开始执行{}项目...
""".format(config.project_name)
)
# 判断现有的测试用例,如果未生成测试代码,则自动生成
# TestCaseAutomaticGeneration().get_case_automatic()
pytest.main(['-s', '-W', 'ignore:Module already imported:pytest.PytestWarning',
'--alluredir', './report/tmp', "--clean-alluredir"])
"""
--reruns: 失败重跑次数
--count: 重复执行次数
-v: 显示错误位置以及错误的详细信息
-s: 等价于 pytest --capture=no 可以捕获print函数的输出
-q: 简化输出信息
-m: 运行指定标签的测试用例
-x: 一旦错误,则停止运行
--maxfail: 设置最大失败次数,当超出这个阈值时,则不会在执行测试用例
"--reruns=3", "--reruns-delay=2"
"""
os.system(r"allure generate ./report/tmp -o ./report/html --clean")
allure_data = AllureFileClean().get_case_count()
notification_mapping = {
NotificationType.DING_TALK.value: DingTalkSendMsg(allure_data).send_ding_notification,
NotificationType.WECHAT.value: WeChatSend(allure_data).send_wechat_notification,
NotificationType.EMAIL.value: SendEmail(allure_data).send_main,
NotificationType.FEI_SHU.value: FeiShuTalkChatBot(allure_data).post
}
if config.notification_type != NotificationType.DEFAULT.value:
notify_type = config.notification_type.split(",")
for i in notify_type:
notification_mapping.get(i.lstrip(""))()
if config.excel_report:
ErrorCaseExcel().write_case()
# 程序运行之后,自动启动报告,如果不想启动报告,可注释这段代码
os.system(f"allure serve ./report/tmp -h 127.0.0.1 -p 8080")
except Exception:
# 如有异常,相关异常发送邮件
e = traceback.format_exc()
send_email = SendEmail(AllureFileClean.get_case_count())
send_email.error_mail(e)
raise
if __name__ == '__main__':
run()
持续更新中...文章来源地址https://www.toymoban.com/news/detail-643765.html
到了这里,关于Yaml版接口自动化详细讲解(Python + pytest + allure + log + yaml + mysql + redis + 钉钉通知 + Jenkins)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!