👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——注意力提示、注意力池化(核回归)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
接下来就要慢慢开始实战了,把这边过了,我们接下来就要进行机器翻译的实战了。实战完,我们需要开始学习当今很先进的transformer以及BERT,并且做点模型出来了。最近有点累了,做完这个以后会休息一两天然后继续肝,预推免前一定要肝出一些不错科研项目出来。
编码器-解码器结构
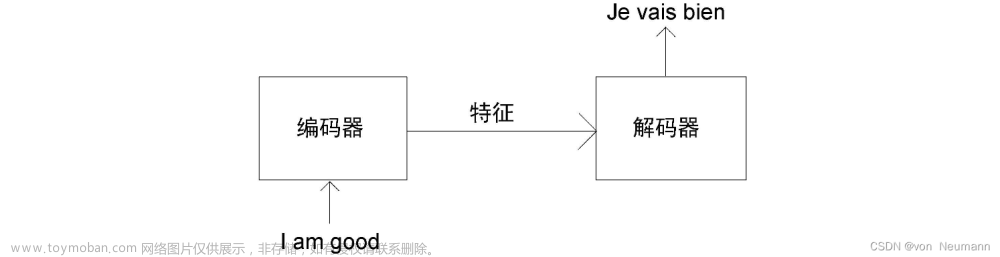
机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列。为了处理这种类型的输入和输出,我们可以设计一个包含两个主要组件的架构:第一个组件是一个编码器(encoder):它接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。 第二个组件是解码器(decoder):它将固定形状的编码状态映射到长度可变的序列。这被称为编码器-解码器。结构如图:
所以我们之前遇到的CNN与RNN,某种程度上也可以看成这种结构的。
比如之前分类猫狗的例子,CNN的特征抽取可以看成编码器,其作用是将输入编程成中间表达形式(特征);而softmax回归就可以看成是解码器,其将中间表示解码成输出。
而对于RNN,编码器就是将文本表示成了向量,解码器就是将向量表示成输出。
这里将把“编码器-解码器”架构转换为接口方便后面的代码实现。
编码器
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。任何继承这个Encoder基类的模型将完成代码实现。
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
解码器
解码器接口中,我们新增一个init_state函数,用于将编码器的输出(enc_outputs)转换为编码后的状态(此步骤可能需要额外的输入,例如:输入序列的有效长度)。 为了逐个地生成长度可变的词元序列,解码器在每个时间步都会将输入 (例如:在前一时间步生成的词元)和编码后的状态映射成当前时间步的输出词元。
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
合并编码器和解码器
总而言之,“编码器-解码器”架构包含了一个编码器和一个解码器,并且还拥有可选的额外的参数。在前向传播中,编码器的输出用于生成编码状态,这个状态又被解码器作为其输入的一部分。
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
“编码器-解码器”体系架构中的术语状态会启发人们使用具有状态的神经网络来实现该架构。
小结
1、“编码器-解码器”架构可以将长度可变的序列作为输入和输出,因此适用于机器翻译等序列转换问题。
2、编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
3、解码器将具有固定形状的编码状态映射为长度可变的序列。
序列到序列学习(seq2seq)
机器翻译中的输入序列和输出序列都是长度可变的。为了解决这个问题才提出了“编码器-解码器”架构。这里将使用两个循环神经网络的编码器和解码器,并将其应用到序列到序列,也就是seq2seq类的学习任务。
循环神经网络编码器使用长度可变的序列作为输入,将其转换为固定形状的隐状态(可理解为输入序列的信息被编码到循环神经网络编码器的隐状态中)。为了连续生成输出序列的词元,独立的循环神经网络解码器是基于输入序列的编码信息和输出序列已经看见的或者生成的词元来预测下一个词元。
如下图是机器翻译英文为法语的过程图,可以看出我们解码器不仅会接受编码器编码出来的结果,还会接受其真正翻译为法语的信息,因此我们根本不用担心解码器太长,然后预测错误以后会一直错,因为本来就有正确的信息了。文章来源:https://www.toymoban.com/news/detail-644072.html

再剖析一下这张图,特定的“eos”表示序列结束词元。一旦输出序列生成此词元,模型就会停止预测。
在循环神经网络解码器的初始化时间步,有两个特定的设计决定:首先,特定的“bos”表示序列开始词元;其次,使用循环神经网络编码器最终的隐状态来初始化解码器的隐状态。
接下来将会利用seq2seq来实现机器翻译。文章来源地址https://www.toymoban.com/news/detail-644072.html
到了这里,关于机器学习&&深度学习——从编码器-解码器架构到seq2seq(机器翻译)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!