目录
一、flink cdc介绍
1、什么是flink cdc
2、flink cdc能用来做什么
3、flink cdc的优点
二、flink cdc基础使用
1、使用flink cdc读取txt文本数据
2、DataStream的使用方式
3、SQL的方式
总结
一、flink cdc介绍
1、什么是flink cdc
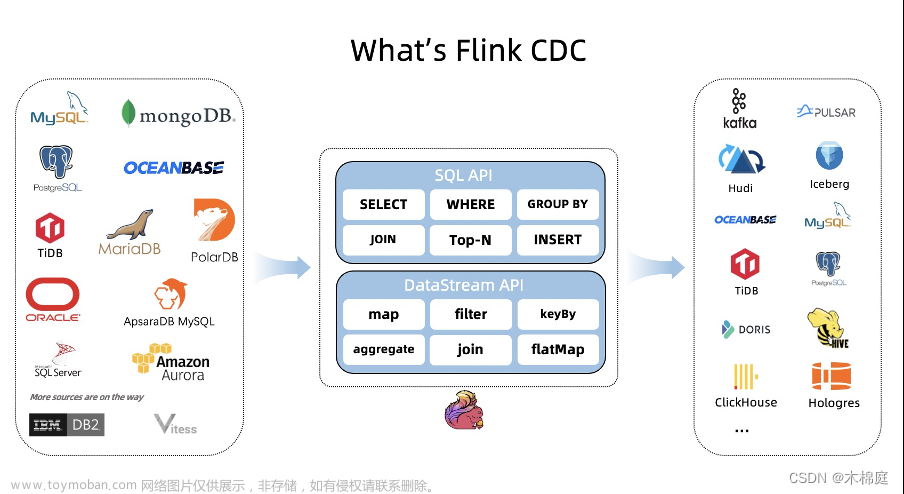
flink cdc是一个由阿里研发的,一个可以直接从MySQL、PostgreSQL等数据库直接读取全量数据和增量变更数据的source组件。
2、flink cdc能用来做什么
flink cdc能感知数据库的所有修改、新增、删除操作,并以流的形式,进行实时的触发和反馈。如:你想监听一个表的数据是否有变动,并且需要把变动的数据读取出来,插入到另外的表里,或者对该数据进行其他处理。在我们传统的开发里,如果不使用cdc技术,是不是就只能通过定时任务去定时的获取数据?或者在执行数据修改操作时调用指定的接口来进行数据上报?并且还要拿新数据和旧数据进行比较,才能得到自己想要的结果?flink cdc就是解决这种问题的,它是cdc里面的佼佼者,它能在数据表被修改时,进行实时的反馈。
3、flink cdc的优点
① 低延迟:毫秒级的延迟
② 高吞吐:每秒能处理数百万个事件
③ 高可用及结果的准确性、良好的容错性,动态扩展、全天候24小时运行
二、flink cdc基础使用
1、使用flink cdc读取txt文本数据
① 项目目录

② 需要用到的flink依赖(有些可以不用的,看实际需要使用哪些功能):
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-parser</artifactId>
<version>1.13.0</version>
</dependency>③ 具体代码(TestFlinkController)
package com.bug.controller;
import com.bug.util.flink.TextFlatUtil;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple3;
import org.springframework.web.bind.annotation.*;
/**
* 1、flink读取本地txt文件数据
*/
public class TestFlinkController {
/**
* 1、flink读取本地txt文件数据
* @param args args
*/
public static void main(String[] args) throws Exception {
String path = "D:\\javaprojects\\my_springboot1\\my_springboot1\\src\\main\\resources\\flinkText\\flinkTest.txt";
//创建执行环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
//读取txt文件数据
DataSet<String> dataSet = environment.readTextFile(path);
//处理读取的数据
DataSet<Tuple3<String, String, String>> out = dataSet.flatMap(new TextFlatUtil());
//输出
out.print();
}
}
TextFlatUtil代码:
package com.bug.util.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.util.Collector;
/**
* 1、flink读取本地txt文件数据
*/
public class TextFlatUtil implements FlatMapFunction<String, Tuple3<String, String, String>> {
@Override
public void flatMap(String value, Collector<Tuple3<String, String, String>> collector) {
for(String word : value.split("\n")){
String[] res = word.split("\t");
collector.collect(new Tuple3<>(res[0],res[1],res[2]));
}
}
}
flinkTest.txt文件值:
801165935581855745 小明1 年龄1
801165936156475393 小明3 年龄3
801165936567517185 小明5 年龄5
801165936991141889 小明7 年龄7
801165937460903937 小明9 年龄9④ 输出效果

2、DataStream的使用方式
① 数据库修改配置my.cnf文件:binlog_format=row

② 直接上代码
package com.bug.flinkcdc;
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* 2、DataStream的方式
*/
public class TestFlinkStream {
/**
* 2、DataStream的方式
*/
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//线程数
//开启ck
// env.enableCheckpointing(60*1000);//60秒启动一次checkpoint
// env.getCheckpointConfig().setCheckpointTimeout(30*1000);//设置超时时间,默认是10min
// env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//Checkpoint级别,EXACTLY_ONCE精准一次,AT_LEAST_ONCE最多一次
// env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000);//设置两次checkpoint的最小时间间隔
// env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//允许的最大checkpoint并行度
// env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/cdc-test/ck"));//设置checkpoint的地址
//构建sourceFunction环境,正式开发可以把一些配置提取出来写成公共配置即可
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("***.***.***.***")//ip地址
.port(***)//端口号
.username("***")//用户名
.password("***")//密码
.databaseList("xiaobug")//数据库名称
.tableList("xiaobug.test_flink")//表名称
.deserializer(new StringDebeziumDeserializationSchema())//反序列化
.startupOptions(StartupOptions.initial())//同步方式,initial全量和增量,latest增量
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//数据输出
dataStreamSource.print();
//启动
env.execute();
}
}
③ 效果

3、SQL的方式
① 数据库修改配置my.cnf文件:binlog_format=row

② 代码
package com.bug.flinkcdc;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* 3、SQL的方式
*/
public class TestFlinkSQL {
/**
* 3、SQL的方式
*/
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//线程数
StreamTableEnvironment tev = StreamTableEnvironment.create(env);
//正式开发时可以把这些语句做成单独的sql文件,更方便管理和维护,with的配置也可以做成公共的,然后读取即可
tev.executeSql("CREATE TABLE test_flink (" +
" userid String primary key," +
" username String," +
" userAge String," +
" userCardid String" +
" ) with ( " +
" 'connector' = 'mysql-cdc'," + //别名
" 'hostname' = '***.***.***.***'," + //数据库ip地址
" 'port' = '***'," + //端口号
" 'username' = '***'," + //用户名
" 'password' = '***'," + //密码
" 'database-name' = 'xiaobug'," + //数据库名称
" 'table-name' = 'test_flink' " + //表名称
")");
//查询数据sql,也可以写在单独的文件里,然后引用即可,复杂的连表查询也是可以的,但需要其他表也进行加载
Table table = tev.sqlQuery("select * from test_flink");
//输出,正式开发可以用sql语句的insert into进行插入,直接实现表到表的同步
DataStream<Tuple2<Boolean, Row>> dataStream = tev.toRetractStream(table,Row.class);
dataStream.print();
//启动
env.execute("FlinkSQLCDC");
}
}
③ 效果

总结
搞定啦,就是这么简单!flinkcdc的进阶:怎样确保数据的一致性、可靠性、不重复、不丢失,后面有时间再写啦。
测试的时候还碰到了一个jar包版本的问题,sql的方式一定要使用1.13.0以上的版本,不然会报错!
还有flink-sql-parser的这个包也一定要添加,不然会出现下面这个提示:文章来源:https://www.toymoban.com/news/detail-644983.html
org.apache.calcite.tools.FrameworkConfig.getTraitDefs()Lorg/apache/flink/calcite/shaded/com/google/common/collect/ImmutableList;文章来源地址https://www.toymoban.com/news/detail-644983.html
到了这里,关于flink cdc数据同步,DataStream方式和SQL方式的简单使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!