Why Selenium?
有些网页内容是在浏览器端动态生成的,直接Http获取网页源码是得不到那些元素的。
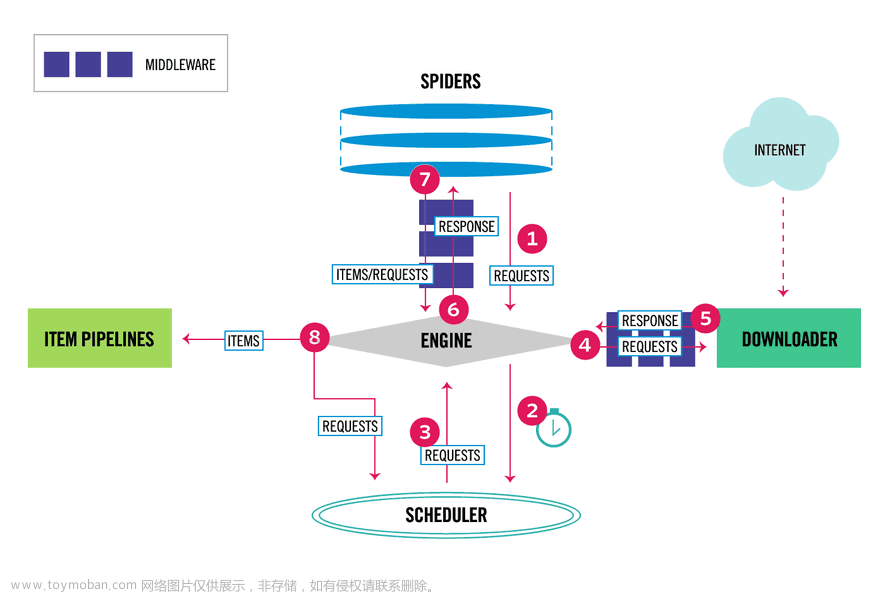
Selenium可以自动启动一个浏览器、打开网页,可以用程序操作页面元素,也可以获得浏览器当前页面动态加载的页面元素。
比如:百度图片的图片是动态加载的。
用法:
1、下载安装Chrome浏览器。
2、下载Chrome对应版本的Selenium chromeDriver

镜像文件
Index of chromedriver-local
查找版本相似的下载

我是Windows系统,就下Windows版本
下载好,把文件放在你Chrome浏览器的同一级文件夹下
3、将chromeDriver 放在chrome浏览器根目录下,它负责对Chrome浏览器执行自动化操作

4、程序通过Maven安装包:selenium-java,它和chromeDriver通讯。


下载百度图片的图片

自动的将网页打开

百度图片的图片是动态加载的。
System.setProperty("webdriver.chrome.driver", chromedriver的路径);
ChromeDriver driver = new ChromeDriver();
String url=百度图片网址;
driver.get(url);
List<WebElement> imgs = driver.findElement(By.className("imglist")).findElements(By.tagName("img"));
for(int i=0;i<imgs.size();i++)
{
WebElement img = imgs.get(i);
String imgSrc = img.getAttribute("data-imgurl");
byte[] bytes = new HttpSender().sendGetBytes(imgSrc);//yzk18-net
ImageType imgType = ImageHelpers.detectImageType(bytes);//yzk18-commons
IOHelpers.writeAllBytes("e:/temp/"+i+"."+imgType,bytes);
}
driver.close();
driver.quit();
More

package Part6;
import com.yzk18.commons.IOHelpers;
import com.yzk18.net.HttpSender;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class SeleniumTest1 {
public static void main(String[] args) throws InterruptedException {
System.setProperty("webdriver.chrome.driver","C:\\Users\\PC\\Desktop\\Google\\Chrome\\Application/chromedriver.exe");
ChromeDriver driver=new ChromeDriver();
/*
driver.get("https://image.baidu.com/");
WebElement kw =driver.findElement(By.id("kw"));//findElement如果有多个,就返回第一个,如果都没有就抛异常
kw.sendKeys("白姨");
WebElement s_newBtn=driver.findElement(By.className("s_newBtn"));
s_newBtn.click();
*/
driver.get("https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1658837529512_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&dyTabStr=&ie=utf-8&sid=&word=%E5%8E%9F%E7%A5%9E%E7%99%BD%E5%A7%A8");
List<WebElement> imgs =driver.findElements(By.className("imgitem"));
int i=1;//文件名计数
for (WebElement img:imgs){
String imgUrl=img.getAttribute("data-thumburl");
System.out.println(imgUrl);
String imgText=img.findElement(By.className("imgitem-title")).getText();
imgText=imgText.replace("*","").replace("?","").replace("|","").replace("/","").replace("\\","");
// 保存图片
byte[] bytes=new HttpSender().sendGetBytes(imgUrl);
IOHelpers.writeAllBytes("D:\\temp\\爬虫\\图片/1/"+imgText+i+".jpeg",bytes);
i++;
}
Thread.sleep(5000);
driver.close();
driver.quit();
}
}

为什么只爬了几张,这个涉及到了计算机的虚拟模式概念。
获取更多图片?文章来源:https://www.toymoban.com/news/detail-645245.html
页面滚动,但是有虚模式的问题需要处理。还有反反爬、代理、验证码…………。爬虫入门容易,如果精通则需要是优秀的网站开发者(前端+后端)。文章来源地址https://www.toymoban.com/news/detail-645245.html
到了这里,关于Java学习笔记:爬虫-操作动态网页的Selenium的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!