初识基础框架
Java基础集合框架是Java编程语言中用于存储、管理和处理数据的一组核心接口和类的集合。
它提供了各种不同类型的数据结构,例如列表、集合、映射等,以及与这些数据结构相关的操作方法。
Java基础集合框架位于`java.util`包中,并在Java的标准库中提供。
Java基础集合框架的主要接口和类:
-
List 接口: 有序集合,可以包含重复元素。常见实现包括ArrayList、LinkedList 和 Vector。
-
Set 接口: 不包含重复元素的集合。常见实现包括HashSet、LinkedHashSet 和 TreeSet。
-
Map 接口: 键值对的集合,每个键映射到一个值。常见实现包括HashMap、LinkedHashMap 和 TreeMap。
-
Queue 接口: 用于表示队列数据结构,通常按照先进先出(FIFO)的顺序处理元素。常见实现包括LinkedList 和 PriorityQueue。
-
Deque 接口: 双端队列,可以从两端添加和删除元素。常见实现包括ArrayDeque 和 LinkedList。
-
Iterator 接口: 用于遍历集合中的元素。
-
Collections 类: 提供了一组静态方法,用于对集合进行操作,如排序、查找、反转等。
-
Arrays 类: 提供了一些静态方法,用于操作数组,如排序、查找等。
除了上述核心接口和类之外,还有一些其他实用类,如 BitSet、EnumSet、EnumMap 等,用于处理特定类型的数据结构。
基础集合框架为Java开发人员提供了灵活且高效的数据结构和操作方式,使得在处理不同类型的数据时更加方便和快速。不过需要注意的是,虽然基础集合框架在大多数情况下足够使用,但在某些特定场景下,可能需要使用更专门的集合库或自定义数据结构。
为什么使用集合框架
使用集合框架(Collection Framework)在Java编程中有许多好处,它提供了一种方便、高效、可重用的方式来管理和操作数据。以下是使用集合框架的一些主要理由:
-
数据存储和管理:集合框架提供了多种数据结构,如列表、集合、映射等,使得存储和管理数据变得更加简单。开发人员无需自己实现复杂的数据结构,而是可以直接使用标准库中提供的集合类。
-
高效的数据操作:集合框架中的类和方法经过优化,可以高效地执行各种数据操作,如查找、插入、删除等。这些操作的底层实现通常使用了合适的数据结构,以提供快速的性能。
-
代码重用:通过使用集合框架,可以避免重复编写数据结构和操作方法,从而提高代码的重用性。开发人员可以专注于业务逻辑而不必关心底层数据管理。
-
类型安全:集合框架在设计时考虑了类型安全性,因此可以确保在编译时捕获一些潜在的类型错误,减少运行时异常的可能性。
-
迭代和遍历:集合框架提供了统一的迭代和遍历机制,使得遍历集合中的元素变得简单。开发人员可以使用迭代器或增强的 for 循环来遍历集合。
-
线程安全性:在多线程环境下,某些集合类(如 ConcurrentHashMap 和 CopyOnWriteArrayList)提供了线程安全的实现,可以帮助开发人员处理并发访问的问题。
-
标准化接口:Java的集合框架使用了统一的接口和类命名规范,这使得开发人员可以轻松地切换和替换不同的集合实现,从而提高了代码的灵活性和可维护性。
-
算法和操作的封装:集合框架中提供了许多常用的算法和操作,如排序、查找、过滤等,这些操作可以直接应用于集合,无需开发人员手动实现。
集合框架为Java开发人员提供了一种强大的工具,帮助他们更轻松地处理和管理数据,提高了代码的效率、可读性和可维护性。
无论是小规模的项目还是大规模的应用程序,集合框架都是编程中不可或缺的重要组成部分。
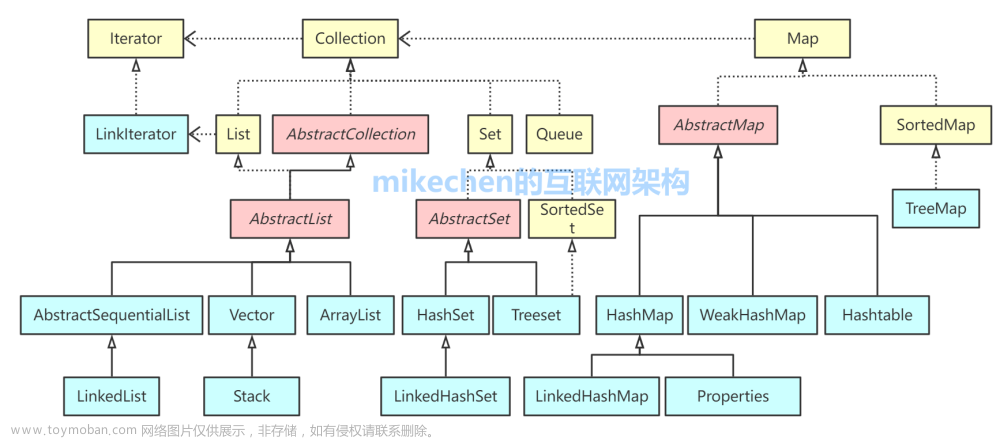
集合框架的继承关系
Java集合框架的类和接口之间存在复杂的继承关系和层次结构。
以下是Java集合框架中一些主要的类和接口及其继承关系的概述
-
Collection 接口:是所有集合类的根接口,它定义了基本的集合操作方法,如添加、删除、查找、遍历等。它派生了两个子接口:List 和 Set。
-
List 接口:表示有序的集合,可以包含重复元素。常见实现有 ArrayList、LinkedList 和 Vector。
-
Set 接口:表示不包含重复元素的集合。常见实现有 HashSet、LinkedHashSet 和 TreeSet。
-
-
Map 接口:表示键值对的集合,每个键映射到一个值。常见实现有 HashMap、LinkedHashMap 和 TreeMap。
-
Queue 接口:表示队列数据结构,通常按照先进先出(FIFO)的顺序处理元素。常见实现有 LinkedList 和 PriorityQueue。
-
Deque 接口:表示双端队列,可以从两端添加和删除元素。常见实现有 ArrayDeque 和 LinkedList。
-
Iterator 接口:用于遍历集合中的元素,是 Collection 接口的成员之一。
-
ListIterator 接口:是 Iterator 的子接口,提供了在 List 中双向遍历的能力。
-
Collections 类:是一个工具类,提供了各种静态方法用于对集合进行操作,如排序、查找、反转等。
-
Arrays 类:是一个工具类,提供了静态方法用于操作数组,如排序、查找等。
-
AbstractCollection 抽象类:实现了 Collection 接口中的大部分方法,为其他集合类提供了共享的基本实现。
-
AbstractList、AbstractSet 和 AbstractMap 抽象类:分别实现了 List、Set 和 Map 接口中的一些通用方法,为具体的实现类提供了基础。
-
AbstractSequentialList 抽象类:实现了 List 接口,为线性数据结构提供了基本实现。
-
AbstractQueue 抽象类:实现了 Queue 接口,为队列数据结构提供了基本实现。
这只是集合框架中一部分类和接口的继承关系,实际上还有许多其他类和接口在框架中扮演了重要的角色。
ArrayList入门案例
import java.util.ArrayList;
public class ArrayListExample {
public static void main(String[] args) {
// 创建一个 ArrayList,存储整数类型的数据
ArrayList<Integer> numbers = new ArrayList<>();
// 添加元素到 ArrayList
numbers.add(10);
numbers.add(20);
numbers.add(30);
numbers.add(40);
numbers.add(50);
// 打印 ArrayList 中的元素
System.out.println("ArrayList 中的元素: " + numbers);
// 使用 for 循环遍历 ArrayList
System.out.println("使用 for 循环遍历 ArrayList:");
for (int i = 0; i < numbers.size(); i++) {
System.out.println(numbers.get(i));
}
// 使用增强的 for 循环遍历 ArrayList
System.out.println("使用增强的 for 循环遍历 ArrayList:");
for (Integer num : numbers) {
System.out.println(num);
}
// 删除元素
numbers.remove(2); // 删除索引为2的元素(30)
// 打印更新后的 ArrayList
System.out.println("更新后的 ArrayList: " + numbers);
}
}
在这个案例中,我们首先创建了一个存储整数的ArrayList。然后,我们使用add()方法向列表中添加一些元素。接下来,我们展示了两种不同的遍历方式:使用传统的for循环和增强的for循环。
最后,我们使用remove()方法删除了列表中索引为2的元素(即30),并打印出更新后的ArrayList。
这个简单的案例演示了ArrayList的基本用法,包括创建、添加、遍历和删除元素。
单元测试和增删改查
单元测试(Unit Testing)是软件开发中的一种测试方法,用于测试软件中的最小可测试单元(通常是函数、方法或类)是否按照预期工作。在数据库操作中的增加(Create)、删除(Delete)、更新(Update)和查询(Retrieve)操作通常也需要进行单元测试,以确保这些操作在各种情况下都能正确地执行。
以下是一个简单的示例,演示了如何对数据库操作的增删改查功能进行单元测试:
假设我们有一个名为UserDao的类,负责与用户数据进行交互,提供增删改查操作。我们使用JUnit作为单元测试框架,来编写测试用例。
import org.junit.Before;
import org.junit.Test;
import static org.junit.Assert.*;
import java.util.List;
public class UserDaoTest {
private UserDao userDao;
@Before
public void setUp() {
// 在每个测试方法运行之前初始化 UserDao
userDao = new UserDao();
}
@Test
public void testCreateUser() {
User newUser = new User("John Doe", 25);
assertTrue(userDao.createUser(newUser));
}
@Test
public void testUpdateUser() {
User existingUser = userDao.getUserById(1); // 假设数据库中已经有一个id为1的用户
assertNotNull(existingUser);
existingUser.setName("Jane Smith");
assertTrue(userDao.updateUser(existingUser));
}
@Test
public void testDeleteUser() {
int userIdToDelete = 2; // 假设数据库中已经有一个id为2的用户
assertTrue(userDao.deleteUser(userIdToDelete));
}
@Test
public void testGetUserById() {
User retrievedUser = userDao.getUserById(3); // 假设数据库中已经有一个id为3的用户
assertNotNull(retrievedUser);
}
@Test
public void testGetAllUsers() {
List<User> users = userDao.getAllUsers();
assertNotNull(users);
assertTrue(users.size() > 0);
}
}
在上述示例中,我们编写了几个测试用例来测试UserDao类中的增删改查功能。每个测试方法使用@Test注解进行标记,表示这是一个测试方法。@Before注解表示在每个测试方法之前执行的代码,用于初始化测试环境。
在每个测试方法中,我们使用JUnit的断言方法(如assertTrue、assertNotNull等)来验证操作的结果是否符合预期。如果测试方法中的断言失败,则测试将失败,表明代码可能存在问题。
通过编写这些单元测试,我们可以在开发过程中快速发现和解决潜在的问题,确保数据库操作的增删改查功能能够正确地工作。
单元测试的注意事项
单元测试在软件开发中扮演着重要的角色,可以帮助开发人员快速发现和解决问题,确保代码的质量和可靠性。以下是一些单元测试的注意事项:
-
测试覆盖率:确保测试用例覆盖到代码中的各个分支和情况,以最大程度地减少未测试代码的存在。使用代码覆盖率工具来帮助确定测试覆盖范围。
-
独立性:每个测试用例应该是相互独立的,不应该依赖于其他测试的执行顺序或结果。这有助于定位问题和调试失败的测试。
-
可重复性:测试应该是可重复运行的,不受外部环境的影响。避免依赖外部资源或随机性因素,确保测试结果始终一致。
-
清晰明了的命名:给测试用例和测试方法起有意义的名字,以便于理解测试的目的和预期结果。良好的命名可以提高测试代码的可读性。
-
小而专注的测试:每个测试用例应该专注于测试一个特定功能或场景。避免一个测试方法测试过多的功能,以保持测试的可维护性和清晰性。
-
模拟和假设:在测试中,可能需要模拟外部依赖或假设某些条件成立。使用模拟框架或工具来创建虚拟对象,以便进行更有效的测试。
-
异常测试:确保测试代码能够正确地处理和捕获预期的异常情况。这有助于验证代码在异常情况下的行为是否符合预期。
-
持续集成:将单元测试集成到持续集成(CI)流程中,确保每次代码提交都会自动运行测试,及时发现问题并防止引入新的错误。
-
定期维护:随着代码的演进,确保及时更新和维护测试代码,以适应代码的变化和需求的变化。
-
性能测试:虽然单元测试主要关注功能的正确性,但在适当的情况下,也可以考虑添加性能测试,以确保代码在负载和压力下的表现。
-
测试文档:为每个测试用例编写清晰的文档,描述测试的目的、输入、预期结果以及其他必要信息。这有助于其他开发人员理解和维护测试。
-
版本控制:将测试代码与应用代码一起放入版本控制系统,确保测试代码与应用代码保持同步。
LinkedList入门案例
以下是一个使用简单的入门案例,演示了如何创建一个LinkedList、添加元素、遍历列表以及删除元素的基本操作:
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
// 创建一个 LinkedList,存储字符串类型的数据
LinkedList<String> names = new LinkedList<>();
// 添加元素到 LinkedList
names.add("Alice");
names.add("Bob");
names.add("Charlie");
names.add("David");
names.add("Eve");
// 打印 LinkedList 中的元素
System.out.println("LinkedList 中的元素: " + names);
// 使用 for 循环遍历 LinkedList
System.out.println("使用 for 循环遍历 LinkedList:");
for (int i = 0; i < names.size(); i++) {
System.out.println(names.get(i));
}
// 使用增强的 for 循环遍历 LinkedList
System.out.println("使用增强的 for 循环遍历 LinkedList:");
for (String name : names) {
System.out.println(name);
}
// 删除元素
names.remove(2); // 删除索引为2的元素(Charlie)
// 打印更新后的 LinkedList
System.out.println("更新后的 LinkedList: " + names);
}
}
在这个案例中,我们首先创建了一个存储字符串的LinkedList。然后,我们使用add()方法向列表中添加一些元素。接下来,我们展示了两种不同的遍历方式:使用传统的for循环和增强的for循环。
最后,我们使用remove()方法删除了列表中索引为2的元素(即"Charlie"),并打印出更新后的LinkedList。
这个简单的案例演示了LinkedList的基本用法,包括创建、添加、遍历和删除元素。LinkedList通常在需要频繁地在列表中进行插入和删除操作时比较有用,因为它支持高效的插入和删除操作。
ArrayList底层是数组
ArrayList的底层实现确实是一个数组(Array)。
ArrayList是基于数组实现的动态数组,它提供了自动扩容的功能,使得在添加或删除元素时能够高效地调整数组的大小。
当你创建一个ArrayList时,实际上是创建了一个对象,该对象内部包含了一个数组来存储元素。当添加元素时,如果数组已满,ArrayList会自动创建一个更大的数组,并将旧数组中的元素复制到新数组中,从而实现自动扩容。这种机制使得ArrayList能够灵活地处理不同大小的数据集合。
尽管ArrayList的底层是数组,但它隐藏了数组的很多细节,提供了一组方便的方法来进行元素的添加、删除、查找等操作。ArrayList还提供了动态调整数组大小的功能,使得开发人员无需手动管理数组的大小和内存分配。
由于底层是数组,ArrayList在进行插入和删除操作时可能涉及元素的移动,这可能会影响性能。
在需要频繁进行插入和删除操作的场景中,可能需要考虑其他数据结构,如LinkedList,以获得更好的性能。
LinkedList底层是链表
LinkedList的底层实现确实是一个链表(Linked List)。
LinkedList是一种双向链表的数据结构,它由一系列的节点组成,每个节点包含了元素本身以及指向前一个节点和后一个节点的引用。
当你创建一个LinkedList时,实际上是创建了一个链表对象,该对象内部维护了链表的头节点和尾节点以及其他必要的信息。在LinkedList中,添加和删除元素的操作非常高效,因为只需要修改节点之间的引用关系,而不需要像数组那样进行元素的移动。
LinkedList适用于需要频繁在中间位置插入和删除元素的场景,因为它的插入和删除操作在平均情况下是O(1)的时间复杂度。然而,需要注意的是,由于每个节点都需要额外的内存空间来存储引用,所以在内存使用方面可能会比ArrayList更高一些。
LinkedList的底层实现是一个双向链表,它提供了高效的插入和删除操作,适用于特定的使用场景。在选择使用ArrayList还是LinkedList时,需要根据具体的需求和性能要求进行权衡。
ArrayList和LinkedList选型
在选择使用ArrayList还是LinkedList时,需要根据你的具体需求和使用场景进行权衡。以下是ArrayList和LinkedList的一些特点和适用场景,可以帮助你做出选择:
ArrayList:
-
随机访问效率高:ArrayList基于数组实现,因此支持随机访问(通过索引访问元素)非常高效,时间复杂度为O(1)。
-
读取操作效率高:对于频繁读取元素的场景,ArrayList通常比LinkedList更快,因为不涉及节点间的引用操作。
-
内存使用较少:由于不需要存储额外的引用节点,ArrayList在内存使用上通常比LinkedList更少。
-
元素迭代效率高:对ArrayList进行迭代操作时(如使用增强的for循环),由于数据在内存中是连续存储的,效率较高。
使用ArrayList进行频繁的读取操作和随机访问:
import java.util.ArrayList;
import java.util.List;
public class ArrayListExample {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
names.add("David");
names.add("Eve");
// 频繁读取和随机访问
System.out.println("第二个名字:" + names.get(1));
System.out.println("名字列表:" + names);
}
}
在这两个示例中,ArrayList适用于频繁的读取操作和随机访问,因为它可以通过索引高效地访问元素。而LinkedList适用于频繁的插入和删除操作,因为它能够高效地在列表中插入和删除元素。
请注意,这只是简单的示例,实际情况可能更加复杂。在选择ArrayList还是LinkedList时,需要根据实际需求和数据操作的特点来权衡利弊。
LinkedList:
-
插入和删除效率高:LinkedList在插入和删除操作(尤其是在列表中间位置)上非常高效,时间复杂度为O(1)。这使得LinkedList在频繁进行插入和删除操作的场景中更有优势。
-
内存分配灵活:由于LinkedList是基于链表实现的,它可以动态调整内存分配,不需要像ArrayList那样提前指定容量。
-
迭代器操作效率高:在使用迭代器遍历列表时,LinkedList由于直接操作节点引用,可以在某些情况下比ArrayList更快。
-
不适合随机访问:LinkedList的随机访问效率较低,因为需要通过节点引用逐个访问,时间复杂度为O(n)。
使用LinkedList进行频繁的插入和删除操作:
import java.util.LinkedList;
import java.util.List;
public class LinkedListExample {
public static void main(String[] args) {
List<String> names = new LinkedList<>();
names.add("Alice");
names.add("Bob");
names.add("David");
// 在第二个位置插入元素
names.add(1, "Charlie");
System.out.println("插入后的名字列表:" + names);
// 删除第一个元素
names.remove(0);
System.out.println("删除后的名字列表:" + names);
}
}
综上所述,如果你需要频繁进行随机访问、读取操作或迭代操作,而且内存使用较为关键,那么ArrayList可能更适合。
如果你需要频繁进行插入和删除操作,或者希望内存分配更灵活,那么LinkedList可能更合适。
需要根据具体的场景和需求进行选择,有时也可以结合使用不同的集合类来充分发挥各自的优势。
ArrayList存放DOG对象
下面是一个简单的示例代码,展示了如何使用ArrayList存放四条狗(Dog对象):文章来源:https://www.toymoban.com/news/detail-645462.html
import java.util.ArrayList;
import java.util.List;
class Dog {
private String name;
public Dog(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
public class ArrayListDogExample {
public static void main(String[] args) {
// 创建一个存放Dog对象的ArrayList
List<Dog> dogs = new ArrayList<>();
// 添加四条狗
dogs.add(new Dog("Buddy"));
dogs.add(new Dog("Max"));
dogs.add(new Dog("Charlie"));
dogs.add(new Dog("Lucy"));
// 遍历并打印狗的名字
System.out.println("存放的狗的名字:");
for (Dog dog : dogs) {
System.out.println(dog.getName());
}
}
}
在这个示例中,我们首先定义了一个简单的Dog类,它具有一个name属性和相关的构造方法和方法。
然后,我们创建了一个ArrayList来存放Dog对象,并向其中添加了四条狗。
最后,我们遍历ArrayList,打印出每条狗的名字。
这个示例展示了如何使用ArrayList存放自定义对象,以后可以根据需要进行修改和扩展。文章来源地址https://www.toymoban.com/news/detail-645462.html
到了这里,关于Java基础集合框架学习(上)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!