背景
因为经常出差火车上没网、不方便电子书阅读器批注,需要从某网站上批量下载多本书籍的图片并自动打包成PDF文件。
分析
1、尝试获得图片地址,发现F12被禁
解决方法:使用Chrome浏览器,点击右上角三个点呼出菜单,选择“更多工具”->“开发者工具”
或者使用Ctrl+Shift+C、Ctrl+Shift+I
2、审查元素,发现图片地址非常有规律:
在class为side-image的div里有一个img,src是../files/mobile/1.jpg?220927153454,去掉后面的问号部分即可得到/files/mobile/1.jpg,通过观察,这本书一共有多少页就会有多少个.jpg文件
3、回到栏目页,可得到基目录,所以批量抓取的大致思路是从栏目页获得基目录,然后不断累加一个数,直到获得jpg时对方服务器报404错误,即可得到刚刚处理的那一页即最后一页。
4、如何从栏目页获得基目录呢?
经观察,每个page_pc_btm_book_body里都有两个a标签,第一个是图片,第二个是“在线阅读”按钮,但是需要翻页怎么办呢?所以需要建立一个变量收集它们,每翻一页,做一次收集。于是可以写如下收集函数:
let books=[]
function catchBook() {
let links = document.getElementsByClassName("page_pc_btm_book_body");
for (let i in links) {
if(!links[i].children||links[i].children.length<2)continue;
let title = links[i].children[0].title;
let link = links[i].children[0].href;
books.push({title,link})
}
}
然后在浏览器里每翻一页,在控制台里执行一次catchBook,这样书名和基目录就都获得了。
5、如何把JSON导出来呢
在控制台里JSON.stringify(books),把结果复制出来,然后到网上随便找一个JSON转Excel的工具,转出来即可,然后注意把第一行当表头,数据复制到第二行开始。
6、最后一步就写个程序从Excel里读出数据,把图片都批量抓下来即可,下面就说说如何写程序来处理。
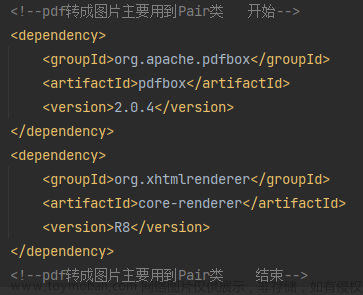
需要引的包
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>ooxml-schemas</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13.3</version>
</dependency>
从Excel到实体
先定义一个实体,这里我多加了一列type,表示类型,name就是从上面那个里面获得的title,link就是上面获得的link属性。
import lombok.Data;
@Data
public class Book {
private String type;
private String name;
private String link;
}
然后写个ExcelReader
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ExcelReader {
public static List<Book> readXlsxToList(String filePath) {
List<Book> bookList = new ArrayList<>();
try (FileInputStream fileInputStream = new FileInputStream(filePath);
Workbook workbook = new XSSFWorkbook(fileInputStream)) {
Sheet sheet = workbook.getSheetAt(0);
Iterator<Row> rowIterator = sheet.iterator();
// 获取表头(第一行)并转换为属性数组
Row headerRow = rowIterator.next();
String[] headers = getRowDataAsStringArray(headerRow);
// 遍历每一行(从第二行开始)
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
Book book = new Book();
// 遍历每个单元格,并根据属性名称设置对应的实体类属性值
for (Cell cell : row) {
int columnIndex = cell.getColumnIndex();
if (columnIndex < headers.length) {
String headerValue = headers[columnIndex];
String cellValue = getCellValueAsString(cell);
setBookProperty(book, headerValue, cellValue);
}
}
bookList.add(book);
}
} catch (IOException e) {
e.printStackTrace();
}
return bookList;
}
private static String[] getRowDataAsStringArray(Row row) {
String[] rowData = new String[row.getLastCellNum()];
for (Cell cell : row) {
int columnIndex = cell.getColumnIndex();
rowData[columnIndex] = getCellValueAsString(cell);
}
return rowData;
}
private static String getCellValueAsString(Cell cell) {
String cellValue = "";
if (cell != null) {
switch (cell.getCellType()) {
case STRING:
cellValue = cell.getStringCellValue();
break;
case NUMERIC:
cellValue = String.valueOf(cell.getNumericCellValue());
break;
case BOOLEAN:
cellValue = String.valueOf(cell.getBooleanCellValue());
break;
case FORMULA:
cellValue = cell.getCellFormula();
break;
default:
cellValue = "";
}
}
return cellValue;
}
private static void setBookProperty(Book book, String propertyName, String propertyValue) {
switch (propertyName) {
case "type":
book.setType(propertyValue);
break;
case "name":
book.setName(propertyValue);
break;
case "link":
book.setLink(propertyValue);
break;
// 添加其他属性
default:
// 未知属性,可以根据需要进行处理
break;
}
}
}
从实体集合到批量下载成jpg
还需要想办法实现批量下载的功能,需要注意的是Windows的默认文件排序是按ASC码排序的,会把10.jpg排在2.jpg前面,所以需要对页码格式化一下,把它变成三位数。
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.List;
public class ImageDownloader {
public static void downloadImages(List<Book> bookList, String targetDir) {
for (Book book : bookList) {
String type = book.getType();
String name = book.getName();
String link = book.getLink();
String basePath = targetDir + "/" + type + "/" + name;
int count = 1;
boolean continueDownload = true;
if(!new File(basePath).exists()){
new File(basePath).mkdirs();
}
while (continueDownload) {
String imgUrl = link + "files/mobile/" + count + ".jpg";
String outputPath = String.format("%s/%03d.jpg", basePath, count);
if (!imageExists(outputPath)) {
try {
downloadImage(imgUrl, outputPath);
System.out.println("Downloaded: " + outputPath);
} catch (IOException e) {
System.out.println("Error downloading image: " + imgUrl);
e.printStackTrace();
continueDownload = false;
}
} else {
System.out.println("Image already exists: " + outputPath);
}
count++;
}
}
}
private static boolean imageExists(String path) {
Path imagePath = Paths.get(path);
return Files.exists(imagePath);
}
private static void downloadImage(String imageUrl, String outputPath) throws IOException {
URL url = new URL(imageUrl);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
int responseCode = httpConn.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
try (InputStream inputStream = httpConn.getInputStream();
FileOutputStream outputStream = new FileOutputStream(outputPath)) {
byte[] buffer = new byte[4096];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
}
} else {
throw new IOException("Server returned response code " + responseCode);
}
}
}
开始批量下载
import java.util.List;
public class Test {
public static void main(String[] args) {
List<Book> books = ExcelReader.readXlsxToList("C:\\Users\\Administrator\\Desktop\\某某书库.xlsx");
String targetDir = "D:\\书库\\";
ImageDownloader.downloadImages(books, targetDir);
}
}
写完执行,回去睡一觉
jpg图片批量转成pdf
都下载完之后,就可以想办法批量转成PDF格式了。
import com.itextpdf.text.*;
import com.itextpdf.text.pdf.PdfWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.MalformedURLException;
public class ImageToPdfConverter {
public static void convertToPdf(String folderPath, String outputFilePath) {
try {
// 获取文件夹中的所有jpg文件
File folder = new File(folderPath);
File[] files = folder.listFiles((dir, name) -> name.toLowerCase().endsWith(".jpg"));
// 预读第一章图片获得大小
Rectangle rect = null;
if (files.length == 0) {
return;
} else {
Image image = Image.getInstance(files[0].getAbsolutePath());
rect = new Rectangle(image.getWidth(), image.getHeight());
}
// 创建PDF文档对象
Document document = new Document(rect);
document.setMargins(0, 0, 0, 0);
// 创建PDF写入器
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(outputFilePath));
writer.setStrictImageSequence(true);
// 打开PDF文档
document.open();
// 遍历图片文件并将其加入到PDF文档中
for (File file : files) {
Image image = Image.getInstance(file.getAbsolutePath());
document.add(image);
}
// 关闭PDF文档
document.close();
System.out.println("PDF文件生成成功!");
} catch (FileNotFoundException | DocumentException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) {
String startDir="D:\\书库\\开发技术\\";
File[] subdirs = new File(startDir).listFiles();
for (File subdir : subdirs) {
if(subdir.isDirectory()){
convertToPdf(subdir.getAbsolutePath(), subdir.getAbsolutePath()+".pdf");
}
}
}
}
结束
最后把PDF文件传到网盘上,手机、平板、电脑随时可以下载离线看,非常舒服。文章来源:https://www.toymoban.com/news/detail-645479.html
注意:自己抓取书籍自己看无所谓,但通过网络分享出去是侵犯他人著作权的。文章来源地址https://www.toymoban.com/news/detail-645479.html
到了这里,关于Java批量下载书籍图片并保存为PDF的方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!