本文首发于微信公众号 CVHub,严禁私自转载或售卖到其他平台,违者必究。

Title: FunASR: A Fundamental End-to-End Speech Recognition Toolkit
PDF: https://arxiv.org/pdf/2305.11013v1.pdf
Code: https://github.com/alibaba-damo-academy/FunASR
导读
本文介绍了一个开源语音识别工具包FunASR,旨在弥合学术研究和工业应用之间的差距。FunASR提供了在大规模工业语料库上训练的模型,并能够将其部署到应用程序中。工具包的核心模型是Paraformer,这是一个非自回归的端到端语音识别模型,经过手动注释的普通话语音识别数据集进行了训练,该数据集包含60,000小时的语音数据。为了提高Paraformer的性能,本文在标准的Paraformer基础上增加了时间戳预测和热词定制能力。此外,为了便于模型部署,本文还开源了基于前馈时序记忆网络FSMN-VAD的语音活动检测模型和基于可控时延Transformer(CT-Transformer)的文本后处理标点模型,这两个模型都是在工业语料库上训练的。这些功能模块为构建高精度的长音频语音识别服务提供了坚实的基础,与在公开数据集上训练的其它模型相比,Paraformer展现出了更卓越的性能。
引言
近年来,端到端E2E模型在自动语音识别ASR任务上的表现已经超过了传统的混合系统。目前有三种流行的E2E方法:
- 连结时序分类(CTC)
- 循环神经网络传递者(RNN-T)
- 基于注意力的编码器-解码器(AED)
其中,AED模型在ASR的seq2seq建模中占据主导地位,因为它们具有更高的识别准确性。为了促进端到端语音识别的研究,已经开发了包括ESPNET、WeNet、PaddleSpeech和K2等开源工具包。这些开源工具在降低构建端到端语音识别系统的难度方面发挥了重要作用。

本文介绍了FunASR,一个旨在弥合学术研究和工业应用之间差距的新型开源语音识别工具包。FunASR基于以前的工作,并提供了以下几个独特的功能:
-
模型范围:FunASR提供了基于工业数据的全面预训练模型。其中的核心模型Paraformer是一个非自回归的端到端语音识别模型,它经过手动注释的普通话语音识别数据集进行了训练,包含60,000小时的语音数据。与主流开源框架支持的Conformer和RNN-T相比,Paraformer在性能上具有可比性,同时更加高效。
-
训练和微调:FunASR是一个全面的语音工具包,提供了一系列工具示例,用于从头开始训练端到端语音识别模型,包括针对AISHELL、WenetSpeech和LibriSpeech等数据集的Transformer、Conformer和Paraformer模型。此外,FunASR还提供了一个方便的微调脚本,使用户能够快速在少量领域数据上微调ModelScope上的预训练模型,从而获得高性能的识别模型。这个功能对于只能访问有限数据和计算资源以从头开始训练模型的学术研究人员和开发人员尤其有益。
-
语音识别服务:FunASR使用户能够构建可在实际应用中部署的语音识别服务。为了方便模型部署,本项目还发布了基于前馈时序记忆网络FSMN-VAD的语音活动检测模型和基于可控时延Transformer(CT-Transformer)的文本后处理标点模型,这两个模型都是在工业语料库上训练的。为了提高Paraformer的性能,本项目在标准的Paraformer基础上增加了时间戳预测和热词定制能力。此外,FunASR还包括一个推理引擎,通过ONNX、libtorch和TensorRT支持CPU和GPU推理。这些功能模块简化了使用FunASR构建高精度、长音频语音识别服务的过程。
总体而言,FunASR是一个强大的语音识别工具包,提供了其它开源工具中没有的独特功能。需要注意的是,由于页面数的限制,本文仅报告了对普通话语料库的实验。事实上,FunASR支持多种语言,包括英语、法语、德语、西班牙语、俄语、日语、韩语等(有关更多详细信息,请参阅模型库)。
方法
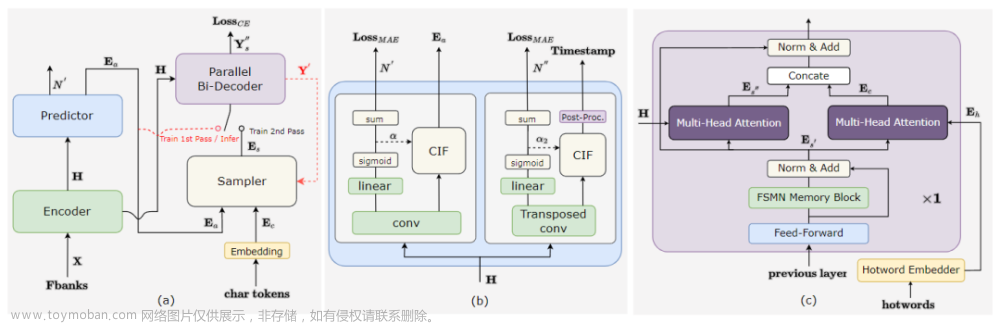
FunASR的整体框架如上图2所示。ModelScope管理FunASR中使用的模型,并托管关键模型,如Paraformer、FSMN-VAD和CT-Transformer。使用FunASR的用户可以通过其基于Pytorch的流水线轻松进行实验,这些流水线分为学术和工业两类。学术流水线使用run.sh表示,允许用户从头开始训练模型。run.sh脚本遵循ESPNET的配方风格,包括数据准备(阶段0)、特征提取(阶段1)、字典生成(阶段2)、模型训练(阶段3和4)以及模型推断和评分(阶段5)。相比之下,工业流水线提供了两个独立的脚本:infer.sh用于推断,finetune.sh用于微调。这些流水线易于使用,用户只需指定模型名称和数据集即可。
FunASR还提供了一个易于使用的运行时环境,用于在应用程序中部署模型。为了支持CPU、GPU、Android和iOS等各种硬件平台,本文提供了不同的运行时后端,包括Libtorch、ONNX和TensorRT。此外,本项目还利用了AMP量化加速推断运行时,并确保最佳性能。有了这些功能,FunASR使得在各种应用中部署和使用语音识别模型变得简单易行。
Paraformer
如上图2(a)所示。Paraformer是一个单步非自回归NAR模型,它包含一个基于扫视语言模型的采样器模块,以增强NAR解码器捕捉标记之间的相互依赖关系的能力。
Paraformer由两个核心模块组成:预测器和采样器。预测器模块用于生成声学嵌入,捕捉输入语音信号的信息。在训练过程中,采样器模块通过将目标嵌入随机替换到声学嵌入中生成语义嵌入。这种方法使模型能够捕捉不同标记之间的相互依赖关系,提高模型的整体性能。然而,在推断过程中,采样器模块处于非活动状态,声学嵌入仅通过单次传递用于输出最终预测结果。这种方法确保了更快的推断时间和更低的延迟。
Timestamp Predictor
准确的时间戳预测是ASR系统的关键功能。然而,传统的工业ASR系统需要额外的混合模型来进行强制对齐(FA)以进行时间戳预测(TP),从而增加了计算和时间成本。FunASR通过重新设计Paraformer预测器的结构,在端到端的ASR模型中实现了准确的时间戳预测,如上图2(b)所示。本文引入了转置卷积层和LSTM层来上采样编码器的输出,时间戳由后处理CIF权重α2生成。本文将两个火炉之间的帧视为前一个标记的持续时间,并根据α2标记出静音部分。此外,FunASR还发布了一个名为TP-Aligner的类似于强制对齐的模型,它包括一个较小尺寸的编码器和一个时间戳预测器,并以语音和相应的转录作为输入来生成时间戳。

本文对AISHELL和60,000小时的工业数据进行了实验,以评估时间戳预测的质量。用于衡量时间戳质量的评估指标是累积平均偏移(AAS)。本文使用了一个包含5,549个话语的测试集,其中手动标记了时间戳,以比较所提供模型的时间戳预测性能与使用Kaldi训练的FA系统之间的差异。结果表明,Paraformer-TP在AISHELL上的性能优于FA系统。在工业实验中,本文发现所提出的时间戳预测方法在时间戳准确性方面与混合FA系统相当(差距小于10毫秒)。此外,单次传递的解决方案对于商业使用非常有价值,因为它有助于减少计算和时间开销。
Hotword Customization
Contextual Paraformer是一种可以通过利用命名实体来自定义热词的模型,这增强了激励并提高了回忆率和准确性。在基本的Paraformer模型上添加了两个附加模块:热词嵌入器和解码器最后一层的多头注意力,如上图2©所示。
本文使用热词作为输入到热词嵌入器。热词嵌入器由嵌入层和LSTM层组成,将上下文热词作为输入,并使用LSTM的最后状态生成嵌入向量Eh。具体来说,首先将热词输入到热词嵌入器中,生成一系列隐藏状态。然后使用最后一个隐藏状态作为热词的嵌入向量,捕捉输入序列的上下文信息。
为了捕捉热词嵌入向量Eh和FSMN记忆块的最后一层输出E_s’之间的关系,本文采用了多头注意力模块。然后将Es’和上下文注意力Ec进行拼接。这个操作可以用如下公式1来表示:

本文使用一维卷积层(Conv1d)来降低其维度,使其与隐藏状态Es’的维度相匹配,从而作为后续层的输入。值得注意的是,除了这个修改之外,本文的Contextual Paraformer的其他过程与标准Paraformer相同。

在训练过程中,热词是从目标中随机生成的,每个训练批次都会生成新的热词。在推理过程中,本文可以通过提供命名实体列表来指定热词。
为了评估Contextual Paraformer的热词定制效果,本文从AISHELL测试集中随机选择了235个包含实体词的音频片段,其中包含187个命名实体。该数据集已上传到ModelScope,并且测试配方已对FunASR开放。此外,本文将实验扩展到了工业任务的AI领域和通用领域,如上表2所示。

上表3展示了本文对热词对Contextual Paraformer性能影响的实验结果。本文使用CER和F1得分作为定制任务的评估指标。结果显示,在AISHELL-1的命名实体子测试集上,F1得分提高了约58%,这是令人印象深刻的改进。此外,在工业定制任务中,本文平均提升了约10%的性能。
Voice Activity Detection
语音活动检测VAD在语音识别系统中起着重要作用,它能够检测有效语音的起始和结束。FunASR提供了一种基于FSMN结构的高效VAD模型。为了提高模型的区分度,本文采用单音素作为建模单元,因为它们能够提供相对丰富的语音信息。在推理过程中,VAD系统需要进行后处理以提高鲁棒性,包括阈值设置和滑动窗口等操作。

上表4详细展示了VAD的评估结果。测试集包含两个领域的手动标注数据:2小时的会议数据和4小时的视频数据。本文报告了字符错误率CER和发送到ASR推理的语音百分比。结果表明,VAD能够有效过滤掉无效的声音,使识别系统能够专注于有效的语音,从而显著提高了CER。
Text Postprocessing

文本后处理是生成可读性高的ASR转录的关键步骤,包括添加标点符号和去除语音不流畅性。FunASR包含一个CT-Transformer模型,可以实时执行这两个任务,模型的整体框架如上图3所示。为了满足实时性要求,模型允许部分输出被冻结,并且可控制时间延迟。采用快速解码策略来最小化延迟,同时保持竞争力的性能。此外,为了降低计算复杂度,该策略根据已预测的标点符号动态地丢弃过长的历史信息。

上表6展示了文本后处理的结果,实验表明,CT-Transformer以更快的推理速度实现了与竞争模型相当的F1分数。
结论
本文介绍了FunASR,这是一个旨在填补学术研究和工业应用之间差距的系统,用于语音识别。FunASR提供了在大规模工业语料库上训练的模型,并且能够轻松地将它们部署到实际应用中。本项目提供了各种工业模型,包括Paraformer-large模型、FSMN-VAD模型和CT-Transformer模型等。通过公开提供这些模型,FunASR使研究人员能够轻松地在实际场景中部署它们。文章来源:https://www.toymoban.com/news/detail-645624.html
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。关注微信公众号,欢迎参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!文章来源地址https://www.toymoban.com/news/detail-645624.html
到了这里,关于阿里达摩院开源大型端到端语音识别工具包FunASR | 弥合学术与工业应用之间的差距的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!