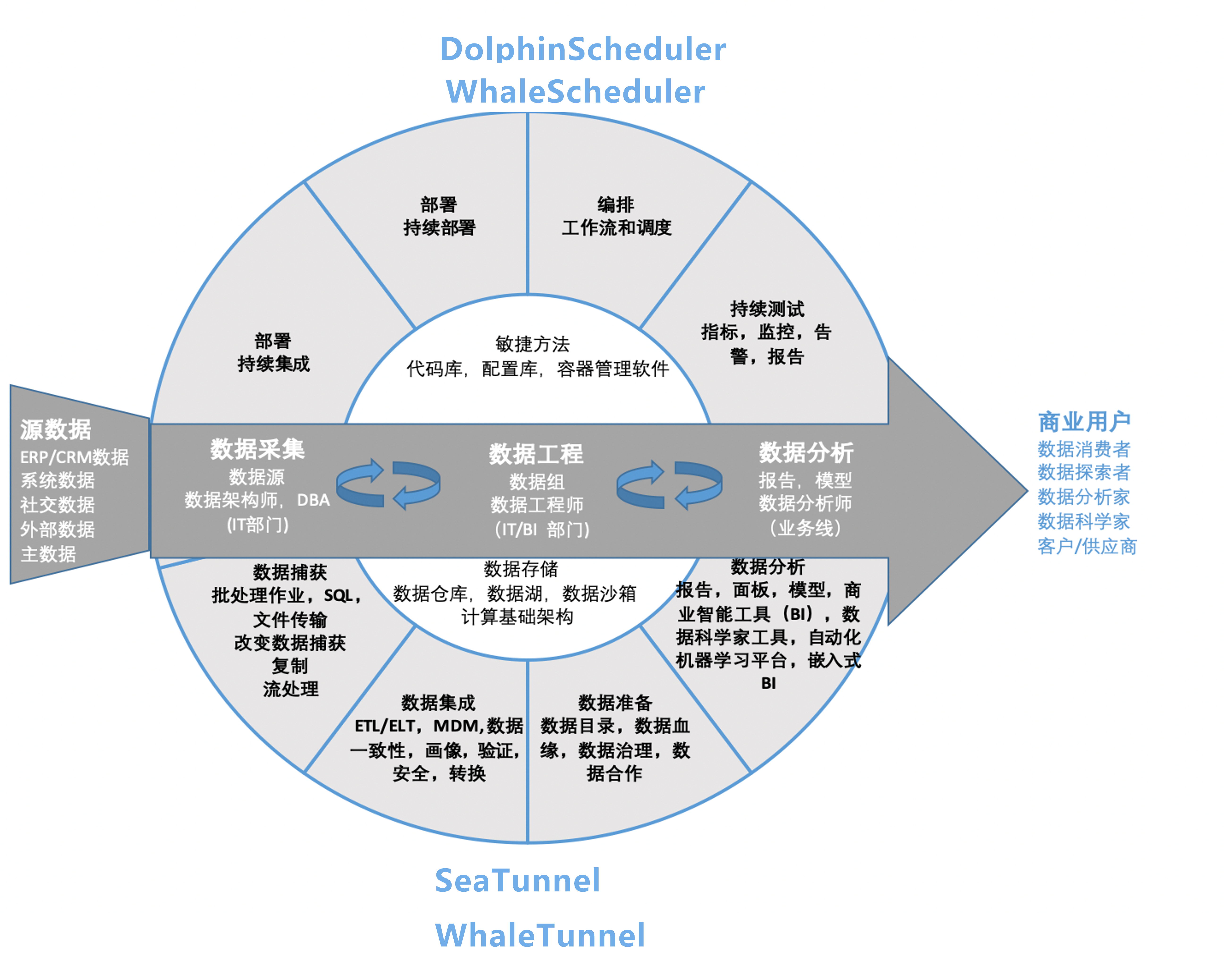
MaxCompute介绍
MaxCompute是适用于数据分析场景的企业级SaaS(Software as a Service)模式云数据仓库,以Serverless架构提供快速、全托管的在线数据仓库服务,消除了传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您可以经济并高效地分析处理海量数据。
MaxCompute提供离线和流式数据的接入,支持大规模数据计算及查询加速能力,为您提供面向多种计算场景的数据仓库解决方案及分析建模服务。
MaxCompute适用于100 GB以上规模的存储及计算需求,最大可达EB级别,并且MaxCompute已经在阿里巴巴集团内部得到大规模应用。MaxCompute适用于大型互联网企业的数据仓库和BI分析、网站的日志分析、电子商务网站的交易分析、用户特征和兴趣挖掘等。

(MaxCompute架构)
MaxCompute数据同步需求
MaxCompute虽然提供了SQL或者类SQL的语法形式,但是和关系型数据库的传统SQL相比,仍然存在许多不同之处。很多开源的ETL工具均不支持MaxCompute云数仓的同步,不得不编写代码来实现数据的同步,要不就只能借助阿里自身的DataWorks来进行同步。
由于DataWorks本身不支持私有化部署,数据同步也存在很多因无法私有化部署而不能解决的问题。ETLCloud根据企业遇到的痛点专门开发了针对MaxCompute数仓的高效同步组件,支持私有化部署,企业可以将不同来源的业务系统及文件数据同步至MaxCompute云数据库中。
ETLCloud MaxCompute同步组件开箱即用,无需学习只需几分钟分钟即可完成同步配置。
使用ETLCloud来完成MaxCompute数据同步
作为集团的数据分析师需要处理非常庞大的跨地域的用户数据。这些数据散布在各种不同的数据库中,并且存储格式和架构也各不相同。
大型企业集团面临着从多个数据库中抽取海量数据并将其整合成一个可用于分析的统一数据集的挑战。
为了解决该问题,企业可以利用ETLCloud平台来完成数据快速迁移到MaxCompute的需求。
首先,企业可以使用ETLCloud中内置的数据库或者API接口来连接各种类型的数据源,并抽取所需的数据。
然后,企业可以针对每个数据库设计特定的数据清洗和转换流程,以确保所有数据都适合于提供有价值的信息并准备统一传送到MaxCompute中。
最后,通过几步即可实现数据快速同步到MaxCompute中,在ETLCloud中使用可视化界面来同步MaxCompute数据库,并将源数据进行清洗过滤,再将数据输出到MaxCompute云数仓中。

图1 流程概览

图2 MaxCompute输入组件基本配置

图3 MaxCompute输入组件属性配置

图4 MaxCompute 组件支持自定义SQL,使数据处理更加灵活多变

图5 数据过滤配置

图6 流程运行结果

图7 数据预览
ETLCloud介绍
ETLCloud是一款零代码ETL工具,可以快速对接上百种数据源和应用系统,无需编码即可快速完成数据同步和传输,企业IT人员只需简单几步即可快速完成各种数据抽取同步并配合BI工具实现数据的统计分析。

(ETLCloud可视化流程同步界面)文章来源:https://www.toymoban.com/news/detail-646363.html
ETLCloud社区版本永久免费下载使用https://www.etlcloud.cn文章来源地址https://www.toymoban.com/news/detail-646363.html
到了这里,关于ETLCloud+MaxCompute实现云数据仓库的高效实时同步的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!