本基于大数据爬虫实现互联网研发岗位数据分析平台,系统主要采用java,互联网爬虫技术,动态图表echarts,springboot,mysql,mybatisplus,岗位推荐算法,实现基于互联网招聘岗位实现针对用户的岗位推荐,
系统提供招聘岗位网站前台,系统岗位数据分析可视化平台展示等功能。
系统招聘网站主要包含:用户登录注册,招聘岗位推荐,岗位推荐列表,用户建立,我的投递,用户浏览,招聘岗位分类,个人中心,招聘岗位详情等模块
系统可视化分析展示平台主要包含:岗位竞争力分析,岗位薪资分析,岗位分析报告,岗位技能分析,岗位数量分析,岗位地图分布等等。
原文地址
一、程序设计
本基于大数据爬虫实现互联网研发岗位数据分析平台,主要内容涉及:
主要功能模块:用户登录注册,招聘岗位推荐,岗位推荐列表,用户建立,我的投递,用户浏览,招聘岗位分类,个人中心,招聘岗位详情等模块。
主要包含技术:java,JSOUP,httpClient,数据处理,数据分析,echarts,springboot,mysql,mybatis,javascript,数据分析存储技术,推荐计算算法等
二、效果实现
演示视频
https://www.bilibili.com/video/BV19m4y177Ti/
系统首页
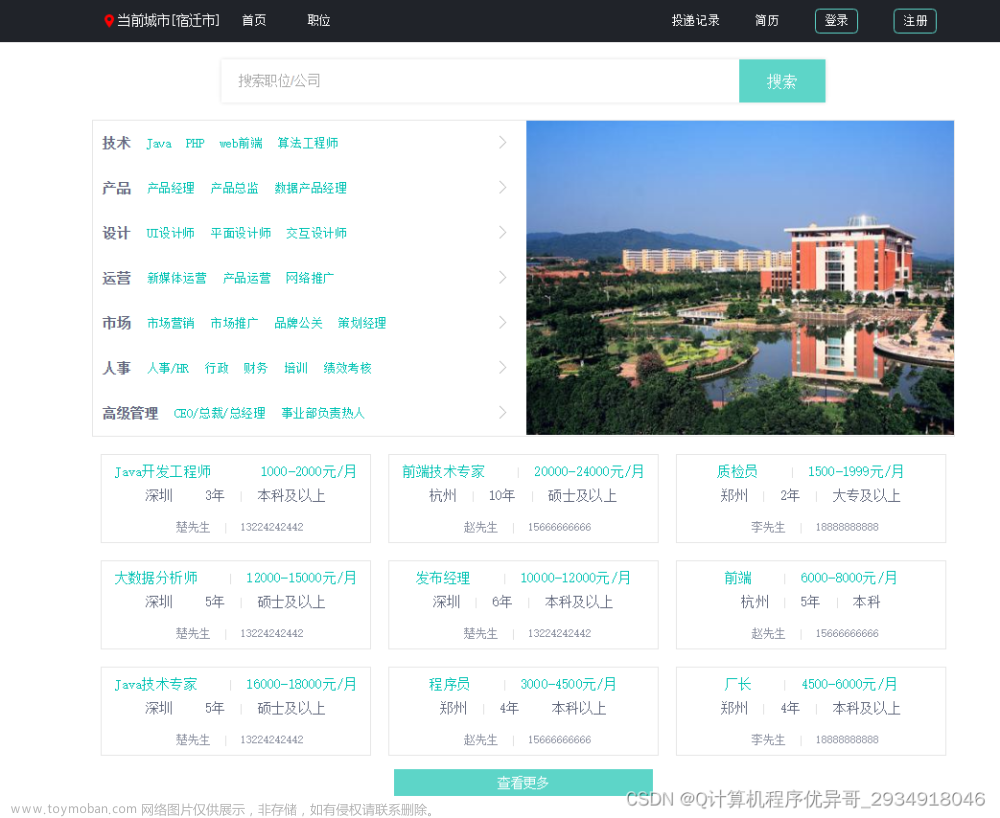
岗位检索

采集数据

数据可视化

程序报告
 文章来源:https://www.toymoban.com/news/detail-646449.html
文章来源:https://www.toymoban.com/news/detail-646449.html
三、代码实现
系统招聘岗位管理主要采用前后端分离模式,针对招聘岗位数据查询封装成JSON格式,完成数据下发至系统界面端渲染,系统界面端针对JSON解析后采用javascript完成页面展示。文章来源地址https://www.toymoban.com/news/detail-646449.html
def wish_data(wages_old):
"""
数据清洗规则:
分为元/天,千(以上/下)/月,万(以上/下)/月,万(以上/下)/年
若数据是一个区间的,则求其平均值,最后的值统一单位为元/月
"""
if '元/天' in wages_old:
if '-' in wages_old.split('元')[0]:
wages1 = wages_old.split('元')[0].split('-')[0]
wages2 = wages_old.split('元')[0].split('-')[1]
wages_new = (float(wages2) + float(wages1)) / 2 * 30
else:
wages_new = float(wages_old.split('元')[0]) * 30
return wages_new
elif '千/月' in wages_old or '千以下/月' in wages_old or '千以上/月' in wages_old:
if '-' in wages_old.split('千')[0]:
wages1 = wages_old.split('千')[0].split('-')[0]
wages2 = wages_old.split('千')[0].split('-')[1]
wages_new = (float(wages2) + float(wages1)) / 2 * 1000
else:
wages_new = float(wages_old.split('千')[0]) * 1000
return wages_new
elif '万/月' in wages_old or '万以下/月' in wages_old or '万以上/月' in wages_old:
if '-' in wages_old.split('万')[0]:
wages1 = wages_old.split('万')[0].split('-')[0]
wages2 = wages_old.split('万')[0].split('-')[1]
wages_new = (float(wages2) + float(wages1)) / 2 * 10000
else:
wages_new = float(wages_old.split('万')[0]) * 10000
return wages_new
elif '万/年' in wages_old or '万以下/年' in wages_old or '万以上/年' in wages_old:
if '-' in wages_old.split('万')[0]:
wages1 = wages_old.split('万')[0].split('-')[0]
wages2 = wages_old.split('万')[0].split('-')[1]
wages_new = (float(wages2) + float(wages1)) / 2 * 10000 / 12
else:
wages_new = float(wages_old.split('万')[0]) * 10000 / 12
return wages_new
def wages_experience_chart(data):
# 根据经验分类,求不同经验对应的平均薪资
wages_experience = data.groupby('经验').mean()
# 获取经验和薪资的值,将其作为画图的 x 和 y 数据
w = wages_experience['工资'].index.values
e = wages_experience['工资'].values
# 按照经验对数据重新进行排序,薪资转为 int 类型(也可以直接在前面对 DataFrame 按照薪资大小排序)
wages = [w[6], w[1], w[2], w[3], w[4], w[5], w[0]]
experience = [int(e[6]), int(e[1]), int(e[2]), int(e[3]), int(e[4]), int(e[5]), int(e[0])]
# 绘制柱状图
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.figure(figsize=(9, 6))
x = wages
y = experience
color = ['#E41A1C', '#377EB8', '#4DAF4A', '#984EA3', '#FF7F00', '#FFFF33', '#A65628']
plt.bar(x, y, color=color)
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom')
plt.title('Python 相关职位经验与平均薪资关系', fontsize=13)
plt.xlabel('经验', fontsize=13)
plt.ylabel('平均薪资(元 / 月)', fontsize=13)
plt.savefig('wages_experience_chart.png')
plt.show()
def wages_education_chart(data):
# 根据学历分类,求不同学历对应的平均薪资
wages_education = data.groupby('学历').mean()
# 获取学历和薪资的值,将其作为画图的 x 和 y 数据
wages = wages_education['工资'].index.values
education = [int(i) for i in wages_education['工资'].values]
# 绘制柱状图
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.figure(figsize=(9, 6))
x = wages
y = education
color = ['#E41A1C', '#377EB8', '#4DAF4A']
plt.bar(x, y, color=color)
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom')
plt.title('Python 相关职位学历与平均薪资关系', fontsize=13)
plt.xlabel('学历', fontsize=13)
plt.ylabel('平均薪资(元 / 月)', fontsize=13)
plt.savefig('wages_education_chart.png')
plt.show()
到了这里,关于BS1066-基于大数据爬虫实现互联网研发岗位数据分析平台的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!