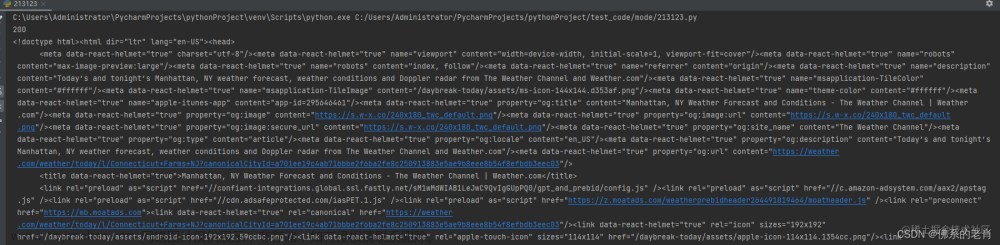
Python之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
目录文章来源:https://www.toymoban.com/news/detail-646567.html
Python之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息文章来源地址https://www.toymoban.com/news/detail-646567.html
到了这里,关于Python 之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[HTML]Web前端开发技术2(HTML5、CSS3、JavaScript )格式化文本标记,定义列表,<blockquote>,definition description,ruby——喵喵画网页](https://imgs.yssmx.com/Uploads/2024/02/753184-1.png)