文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Kafka的零拷贝技术;
⚪ 了解常规的文件传输过程;
一、常规的网络传输原理

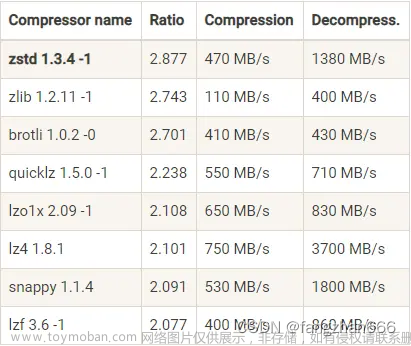
表面上一个很简单的网络文件输出的过程,在OS底层,会发现数据会被拷贝4次。
内核态可以理解为特权态,可以访问计算机的所有资源。
而用户态的访问资源是受限的。
上图中,如果要对文件数据修改,则只能在用户态的缓冲区修改,所以需要拷贝4次。
但如果仅仅是发送文件数据,则 copy 4 次是没有意义的,并且还是产生 4 次内核态和用户态的切换,这些都需要小号CPU性能的。
二、Kafka的零拷贝技术

总结:
1. Kafka的写入性能高:因为底层是磁盘顺序写。
2. Kafka的读取性能高,因为底层是由索引机制。文章来源:https://www.toymoban.com/news/detail-646693.html
3. Kafka的传输性能高,因为底层使用Zero Copy技术。文章来源地址https://www.toymoban.com/news/detail-646693.html
到了这里,关于大数据课程I4——Kafka的零拷贝技术的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!