
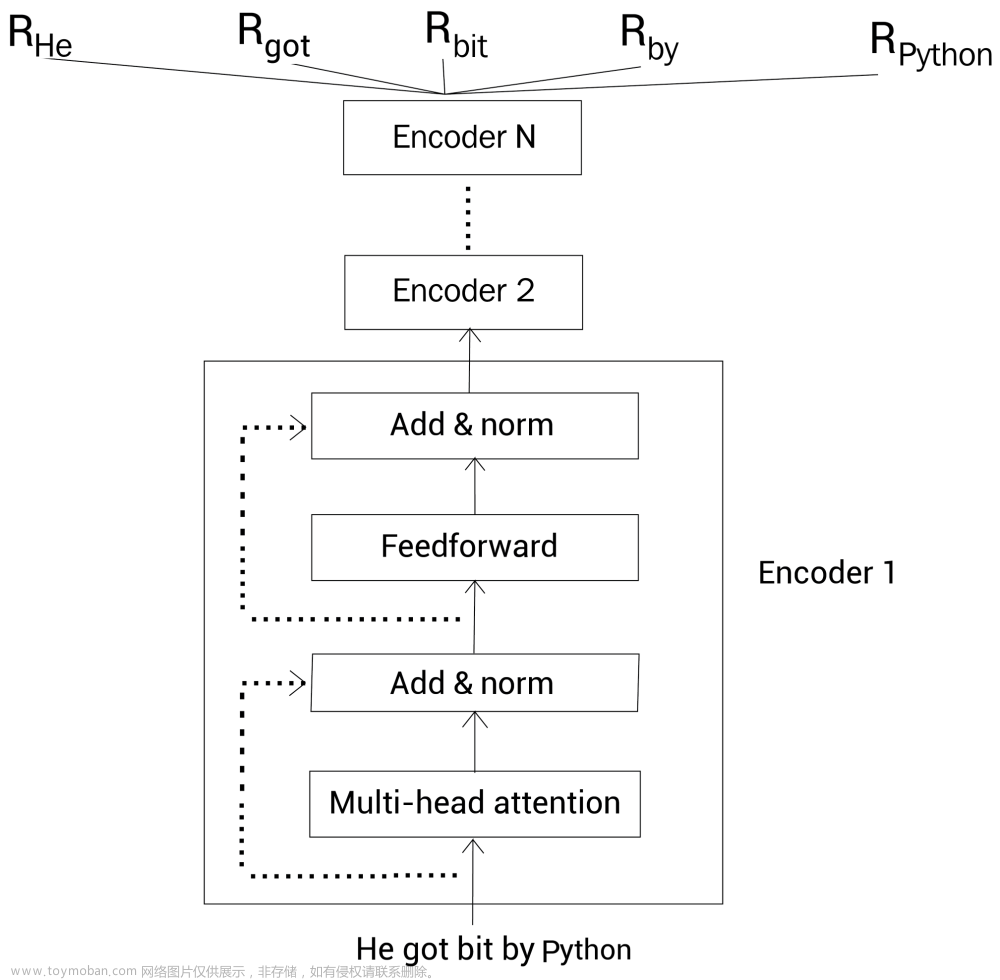
0 什么是伯特?
BERT是来自【Bidirectional Encoder Representations from Transformers】变压器的双向编码器表示的缩写,是用于自然语言处理的机器学习(ML)模型。它由Google AI Language的研究人员于2018年开发,可作为瑞士军刀解决方案,用于11 +最常见的语言任务,例如情感分析和命名实体识别。
从历史上看,语言对计算机来说很难“理解”。当然,计算机可以收集、存储和读取文本输入,但它们缺乏基本的语言上下文。文章来源:https://www.toymoban.com/news/detail-646851.html
文章来源地址https://www.toymoban.com/news/detail-646851.html
到了这里,关于【Bert101】最先进的 NLP 模型解释【01/4】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[NLP] BERT模型参数量](https://imgs.yssmx.com/Uploads/2024/02/668713-1.png)
![【深度学习应用】基于Bert模型的中文语义相似度匹配算法[离线模式]](https://imgs.yssmx.com/Uploads/2024/02/794034-1.png)




