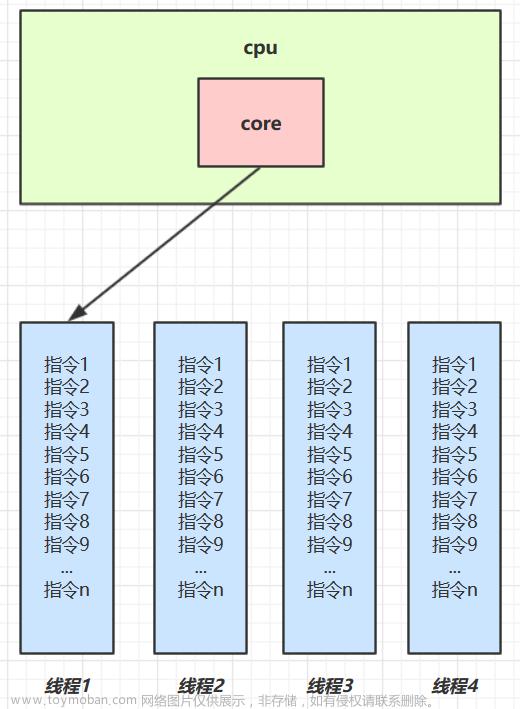
python 进程与线程是并发编程的两种常见方式。进程是操作系统中的一个基本概念,表示程序在操作系统中的一次执行过程,拥有独立的地址空间、资源、优先级等属性。线程是进程中的一条执行路径,可以看做是轻量级的进程,与同一个进程中的其他线程共享相同的地址空间和资源。
线程和进程都可以实现并发编程,但是它们之间有几点不同:
- 线程间共享进程的内存空间,但进程间的内存空间是相互独立的;
- 线程创建和销毁的开销较小,但是线程切换的开销较大;
- 进程间通信需要较为复杂的 IPC(Inter-Process Communication)机制,线程间通信则可以直接读写共享内存;
- 多进程可以充分利用多核 CPU 的性能,但是多线程受 GIL(Global Interpreter Lock)限制,只能利用单核 CPU 的性能。
在选择使用进程还是线程时,需要根据具体场景和需求进行权衡和选择。如果任务需要充分利用多核 CPU,且任务之间互不影响,可以选择多进程;如果任务之间需要共享资源和数据,可以选择多线程。同时,需要注意在 python 中使用多线程时,由于 GIL 的存在,可能无法实现真正的并行。
8.1 创建并使用线程
线程是操作系统调度的最小执行单元,是进程中的一部分,能够提高程序的效率。在python中,创建线程需要使用threading模块。该模块的实现方法是底层调用了C语言的原生函数来实现线程的创建和管理。在系统中,所有的线程看起来都是同时执行的,但实际上是由操作系统进行时间片轮转调度的。
使用函数创建线程: 创建线程并传递参数实现指定函数多线程并发,使用join方法,等待线程执行完毕后的返回结果.
import os,time
import threading
now = lambda:time.time()
def MyThread(x,y): # 定义每个线程要执行的函数体
time.sleep(5) # 睡眠5秒钟
print("传递的数据:%s,%s"%(x,y)) # 其中有两个参数,我们动态传入
if __name__ == "__main__":
ThreadPool = []
start = now()
for item in range(10): # 创建10个线程并发执行函数
thread = threading.Thread(target=MyThread,args=(item,item+1,)) # args =>函数的参数
thread.start() # 启动线程
ThreadPool.append(thread)
for item in ThreadPool:
item.join()
print("[+] 线程信息: {}".format(item))
stop = now()
print("[+] 线程总耗时: {} s".format(int(stop-start)))
使用类创建内部线程: 通过定义类,将线程函数与类进行结合实现一体化该方式调用方便思维明确.
import os,time
import threading
class MyThread(threading.Thread):
def __init__(self,x,y):
super(MyThread, self).__init__()
self.x = x
self.y = y
def run(self): # 用于执行相应操作(固定写法)
print("[+] 当前执行运算: {} + {}".format(self.x,self.y))
self.result = self.x + self.y
def get_result(self): # 获取计算结果
try:
return self.result
except Exception:
return None
if __name__ == "__main__":
ThreadPool = []
for item in range(1,10):
obj = MyThread(item,item+1)
obj.start()
ThreadPool.append(obj)
for item in ThreadPool:
item.join()
print("[+] 获取返回: ",item.get_result())
使用类创建外部线程: 该定义方式与上方完全不同,我们可以将执行过程定义到类的外部为单独函数,然后类内部去调用传参.
import os,time
import threading
def MyThreadPrint(x,y):
print("[+] 当前执行运算: {} + {}".format(x,y))
result = x + y
return result
class MyThread(threading.Thread):
def __init__(self,func,args=()):
super(MyThread, self).__init__()
self.func = func
self.args = args
def run(self):
self.result = self.func(*self.args)
def get_result(self):
try:
return self.result
except Exception:
return None
if __name__ == "__main__":
ThreadPool = []
for item in range(1,10):
obj = MyThread(func=MyThreadPrint,args=(item,item+1))
obj.start()
ThreadPool.append(obj)
for item in ThreadPool:
item.join()
print("[+] 获取返回: ",item.get_result())
在线程中创建子线程: 通过创建一个守护线程,并让守护线程调用子线程,从而实现线程中调用线程,线程嵌套调用.
import time
import threading
# run => 子线程 => 由主线程调用它
def run(num):
print("这是第 {} 个子线程".format(num))
time.sleep(2)
# main = > 主守护线程 => 在里面运行5个子线程
def main():
for each in range(5):
thread = threading.Thread(target=run,args=(each,))
thread.start()
print("启动子线程: {} 编号: {}".format(thread.getName(),each))
thread.join()
if __name__ == "__main__":
daemon = threading.Thread(target=main,args=())
daemon.setDaemon(True) # 设置主线程为守护线程
daemon.start() # 启动守护线程
daemon.join(timeout=10) # 设置10秒后关闭,不论子线程是否执行完毕
简单的线程互斥锁(Semaphore): 同时允许一定数量的线程更改数据,也就是限制每次允许执行的线程数.
import threading,time
semaphore = threading.BoundedSemaphore(5) #最多允许5个线程同时运行
def run(n):
semaphore.acquire() #添加信号
time.sleep(1)
print("运行这个线程中: %s"%n)
semaphore.release() #关闭信号
if __name__ == '__main__':
for i in range(20): #同时执行20个线程
t = threading.Thread(target=run, args=(i,))
t.start()
while threading.active_count() != 1: #等待所有线程执行完毕
pass
else:
print('----所有线程执行完毕了---')
import threading,time
class mythreading(threading.Thread):
def run(self):
semaphore.acquire() #获取信号量锁
print('running the thread:',self.getName())
time.sleep(2)
semaphore.release() #释放信号量锁
if __name__ == "__main__":
semaphore = threading.BoundedSemaphore(3) # 只运行3个线程同时运行
for i in range(20):
t1 = mythreading()
t1.start()
t1.join()
线程全局锁(Lock): 添加本全局锁以后,能够保证在同一时间内保证只有一个线程具有权限.
import time
import threading
num = 0 #定义全局共享变量
thread_list = [] #线程列表
lock = threading.Lock() #生成全局锁
def SumNumber():
global num #在每个线程中获取这个全局变量
time.sleep(2)
lock.acquire() #修改数据前给数据加锁
num += 1 #每次进行递增操作
lock.release() #执行完毕以后,解除锁定
for x in range(50): #指定生成线程数
thread = threading.Thread(target=SumNumber)
thread.start() #启动线程
thread_list.append(thread) #将结果列表加入到变量中
for y in thread_list: #等待执行完毕.
y.join()
print("计算结果: ",num)
线程递归锁(RLock): 递归锁和全局锁差不多,递归锁就是在大锁中还要添加个小锁,递归锁是常用的锁.
import threading
import time
num = 0 #初始化全局变量
lock = threading.RLock() #设置递归锁
def fun1():
lock.acquire() #添加递归锁
global num
num += 1
lock.release() #关闭递归锁
return num
def fun2():
lock.acquire() #添加递归锁
res = fun1()
print("计算结果: ",res)
lock.release() #关闭递归锁
if __name__ == "__main__":
for x in range(10): #生成10个线程
thread = threading.Thread(target=fun2)
thread.start()
while threading.active_count() != 1: #等待所有线程执行完成
print(threading.active_count())
else:
print("所有线程运行完成...")
print(num)
线程互斥锁量控制并发: 使用BoundedSemaphore定义默认信号10,既可以实现控制单位时间内的程序并发量.
import os,time
import threading
def MyThread(x):
lock.acquire() # 上锁
print("执行数据: {}".format(x))
lock.release() # 释放锁
time.sleep(2) # 模拟函数消耗时间
threadmax.release() # 释放信号,可用信号加1
if __name__ == "__main__":
# 此处的BoundedSemaphore就是说默认给与10个信号
threadmax = threading.BoundedSemaphore(10) # 限制线程的最大数量为10个
lock = threading.Lock() # 将锁内的代码串行化(防止print输出乱行)
ThreadPool = [] # 执行线程池
for item in range(1,100):
threadmax.acquire() # 增加信号,可用信号减1
thread = threading.Thread(target=MyThread,args=(item,))
thread.start()
ThreadPool.append(thread)
for item in ThreadPool:
item.join()
线程驱动事件(Event): 线程事件用于主线程控制其他线程的执行,事件主要提供了三个方法set、wait、clear、is_set,分别用于设置检测和清除标志.
import threading
event = threading.Event()
def func(x,event):
print("函数被执行了: %s 次.." %x)
event.wait() # 检测标志位状态,如果为True=继续执行以下代码,反之等待.
print("加载执行结果: %s" %x)
for i in range(10): # 创建10个线程
thread = threading.Thread(target=func,args=(i,event,))
thread.start()
print("当前状态: %s" %event.is_set()) # 检测当前状态,这里为False
event.clear() # 将标志位设置为False,默认为False
temp=input("输入yes解锁新姿势: ") # 输入yes手动设置为True
if temp == "yes":
event.set() # 设置成True
print("当前状态: %s" %event.is_set()) # 检测当前状态,这里为True
import threading
def show(event):
event.wait() # 阻塞线程执行程序
print("执行一次线程操作")
if __name__ == "__main__":
event_obj = threading.Event() # 创建event事件对象
for i in range(10):
t1 = threading.Thread(target=show,args=(event_obj,))
t1.start()
inside = input('>>>:')
if inside == '1':
event_obj.set() # 当用户输入1时set全局Flag为True,线程不再阻塞
event_obj.clear() # 将Flag设置为False
线程实现条件锁: 条件(Condition) 使得线程等待,只有满足某条件时,才释放N个线程.
import threading
def condition_func():
ret = False
inp = input(">> ")
if inp == '1':
ret = True
return ret
def run(n):
con.acquire() # 条件锁
con.wait_for(condition_func) # 判断条件
print('running...',n)
con.release() # 释放锁
if __name__ == "__main__":
con = threading.Condition() # 建立线程条件对象
for i in range(10):
t = threading.Thread(target=run,args=(i,))
t.start()
t.join()
单线程异步并发执行: 在单线程下实现异步执行多个函数,返回耗时取决于最后一个函数的执行时间.
import time,asyncio
now = lambda :time.time()
async def GetSystemMem(sleep):
print("[+] 执行获取内存异步函数.")
await asyncio.sleep(sleep) # 设置等待时间
return 1
async def GetSystemCPU(sleep):
print("[+] 执行获取CPU异步函数.")
await asyncio.sleep(sleep) # 设置等待时间
return 1
if __name__ == "__main__":
stop = now()
mem = GetSystemMem(1)
cpu = GetSystemCPU(4)
task=[
asyncio.ensure_future(mem), # 将多个任务添加进一个列表
asyncio.ensure_future(cpu)
]
loop=asyncio.get_event_loop() # 创建一个事件循环
loop.run_until_complete(asyncio.wait(task)) # 开始并发执行
for item in task:
print("[+] 返回结果: ",item.result()) # 输出回调
print('总耗时: {}'.format(stop - now()))
8.2 创建并使用进程
进程是指正在执行的程序,创建进程需要使用multiprocessing模块,创建方法和线程相同,但由于进程之间的数据需要各自持有一份,所以创建进程需要更大的开销。进程间数据不共享,多进程可以用来处理多任务,但很消耗资源。计算密集型任务最好交给多进程来处理,I/O密集型任务最好交给多线程来处理。另外,进程的数量应该和CPU的核心数保持一致,以充分利用系统资源。
使用进程函数执行命令: 通过系统提供的进程线程函数完成对系统命令的调用与执行.
>>> import os,subprocess
>>>
>>> os.system("ping -n 1 www.baidu.com") # 在当前shell中执行命令
>>>
>>> ret = os.popen("ping -n 1 www.baidu.com") # 在子shell中执行命令
>>> ret.read()
>>>
>>> subprocess.run("ping www.baidu.com",shell=True)
>>> subprocess.call("ping www.baidu.com", shell=True)
>>>
>>> ret = subprocess.Popen("ping www.baidu.com",shell=True,stdout=subprocess.PIPE)
>>> ret.stdout.read()
创建多进程与子线程: 通过使用multiprocessing库,循环创建4个主进程,而在每个主进程内部又起了5个子线程.
import multiprocessing
import threading,os
def ThreadingFunction():
print("[-] ----> 子线程PPID: {}".format(threading.get_ident()))
def ProcessFunction(number):
print("[*] -> 主进程PID: {} 父进程: {}".format(os.getpid(),os.getppid()))
for i in range(5): # 在主进程里开辟5个线程
thread = threading.Thread(target=ThreadingFunction,) # 嵌套子线程
thread.start() # 执行子线程
if __name__ == "__main__":
for item in range(4): # 启动4个主进程
proc = multiprocessing.Process(target=ProcessFunction,args=(item,))
proc.start()
proc.join()
使用基于类的方式创建进程: 除了使用函数式方式创建进程以外,我们还可以使用基于类的方式创建.
import os,time
from multiprocessing import Process
class Myprocess(Process):
def __init__(self,person):
super().__init__()
self.person = person
def run(self):
print("[*] -> 当前PID: {}".format(os.getpid()))
print("--> 传入的人名: {}".format(self.person))
time.sleep(3)
if __name__ == '__main__':
process = Myprocess("lyshark")
#process.daemon = True # 设置p为守护进程
process.start()
进程锁(Lock): 进程中也有锁,可以实现进程之间数据的一致性,也就是进程数据的同步,保证数据不混乱.
# 由并发变成了串行,牺牲了运行效率,但避免了竞争
import multiprocessing
def func(loc,num):
loc.acquire() #添加进程锁
print("hello ---> %s" %num)
loc.release() #关闭进程锁
if __name__ == "__main__":
lock = multiprocessing.Lock() #生成进程锁
for number in range(10):
proc = multiprocessing.Process(target=func,args=(lock,number,))
proc.start()
异步进程池: 进程池内部维护一个进程序列,当使用时则去进程池中获取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止.
import multiprocessing
import time
def ProcessFunction(number):
time.sleep(2)
print("[+] 进程执行ID: {}".format(number))
def ProcessCallback(arg):
print("[-] 进程执行结束,执行回调函数")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=5) # 允许进程池同时放入5个进程
for item in range(10):
pool.apply_async(func=ProcessFunction,args=(item,),callback=ProcessCallback)
pool.close()
pool.join()
from multiprocessing import Pool, TimeoutError
import time,os
def f(x):
return x*x
if __name__ == '__main__':
#启动4个工作进程作为进程池
with Pool(processes=4) as pool:
#返回函数参数运行结果列表
print(pool.map(f, range(10)))
#在进程池中以任意顺序打印相同的数字
for i in pool.imap_unordered(f, range(10)):
print(i,end=' ')
#异步评估
res = pool.apply_async(f,(20,)) #在进程池中只有一个进程运行
print('\n',res.get(timeout=1)) #打印结果,超时为1秒
#打印该进程的PID
res = pool.apply_async(os.getpid,()) #在进程池中只有一个进程运行
print(res.get(timeout=1)) #打印进程PID
#打印4个进程的PID
multiple_results = [pool.apply_async(os.getpid, ()) for i in range(4)]
print([res.get(timeout=1) for res in multiple_results])
#进程等待10秒,获取数据超时为1秒,将输出异常
res = pool.apply_async(time.sleep, (10,))
try:
print(res.get(timeout=1))
except TimeoutError:
print("We lacked patience and got a multiprocessing.TimeoutError")
8.3 多进程数据共享
一般当我们创建两个进程后,进程各自持有一份数据,默认无法共享数据,如果我们想要共享数据必须通过一个中间件来实现数据的交换,来帮你把数据进行一个投递,要实现进程之间的数据共享,其主要有以下几个方法来实现进程间数据的共享.
共享队列(Queue): 这个Queue主要实现进程与进程之间的数据共享,与线程中的Queue不同.
from multiprocessing import Process
from multiprocessing import queues
import multiprocessing
def foo(i,arg):
arg.put(i)
print('say hi',i,arg.qsize())
li = queues.Queue(20,ctx=multiprocessing)
for i in range(10):
p = Process(target=foo,args=(i,li,))
p.start()
共享整数(int): 整数之间的共享,只需要使用multiprocessing.Value方法,即可实现.
import multiprocessing
def func(num):
num.value = 1024 #虽然赋值了,但是子进程改变了这个数值
print("函数中的数值: %s"%num.value)
if __name__ == "__main__":
num = multiprocessing.Value("d",10.0) #主进程与子进程共享这个value
print("这个共享数值: %s"%num.value)
for i in range(5):
num = multiprocessing.Value("d", i) #声明进程,并传递1,2,3,4这几个数
proc = multiprocessing.Process(target=func,args=(num,))
proc.start() #启动进程
#proc.join()
print("最后打印数值: %s"%num.value)
共享数组(Array): 数组之间的共享,只需要使用multiprocessing.Array方法,即可实现.
import multiprocessing
def func(ary): #子进程改变数组,主进程跟着改变
ary[0]=100
ary[1]=200
ary[2]=300
''' i所对应的类型是ctypes.c_int,其他类型如下参考:
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
'''
if __name__ == "__main__":
ary = multiprocessing.Array("i",[1,2,3]) #主进程与子进程共享这个数组
for i in range(5):
proc = multiprocessing.Process(target=func,args=(ary,))
print(ary[:])
proc.start()
共享字典(dict): 通过使用Manager方法,实现两个进程中的,字典与列表的数据共享.文章来源:https://www.toymoban.com/news/detail-646995.html
import multiprocessing
def func(mydict, mylist):
mydict["字典1"] = "值1"
mydict["字典2"] = "值2"
mylist.append(1)
mylist.append(2)
mylist.append(3)
if __name__ == "__main__":
mydict = multiprocessing.Manager().dict() #主进程与子进程共享字典
mylist = multiprocessing.Manager().list() #主进程与子进程共享列表
proc = multiprocessing.Process(target=func,args=(mydict,mylist))
proc.start()
proc.join()
print("列表中的元素: %s" %mylist)
print("字典中的元素: %s" %mydict)
管道共享(Pipe): 通过Pipe管道的方式在两个进程之间共享数据,类似于Socket套接字.文章来源地址https://www.toymoban.com/news/detail-646995.html
import multiprocessing
def func(conn):
conn.send("你好我是子进程.") #发送消息给父进程
print("父进程传来了:",conn.recv()) #接收父进程传来的消息
conn.close()
if __name__ == "__main__":
parent_conn,child_conn = multiprocessing.Pipe() #管道创建两个端口,一收一发送
proc = multiprocessing.Process(target=func,args=(child_conn,))
proc.start()
print("子进程传来了:",parent_conn.recv()) #接收子进程传来的数据
parent_conn.send("我是父进程,收到消息了..") #父进程发送消息给子进程
到了这里,关于8.0 Python 使用进程与线程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!