GPT2-Chinese 介绍
GPT-2 (Generative Pre-trained Transformer 2) 是由 OpenAI 开发的一种基于 Transformer 模型的自然语言处理(NLP)模型,旨在生成自然流畅的文本。它是一种无监督学习模型,其设计目标是能够理解人类语言的复杂性并模拟出自然的语言生成。
GPT-2 是目前最先进的自然语言处理模型之一,因为它具有大量的训练数据和强大的算法,可以生成自然流畅、准确的文本,其中文版本为GPT2-Chinese:使用wiki中文通用语料训练。
与其他基于神经网络的语言模型相比,GPT-2 具有许多独特的优点。首先,它采用了自监督学习的方式进行训练,使其能够处理多种语言和任务。其次,GPT-2 可以生成各种类型的文本,例如新闻、故事、对话和代码等。最后,GPT-2 模型使用了大量的预训练参数,使其具有强大的表现力和泛化能力。
GPT2-Chinese 版本是 GPT-2 模型的中文版本,也是基于 Transformer 模型构建的,具有相同的架构和训练技术。GPT2-Chinese 已经在多项中文 NLP 任务上取得了显著的成果,并被广泛应用于中文文本生成、问答、文本摘要和翻译等领域。
GPT-2 参数数量 1.5亿到1.75亿模型大小0.5GB到1.5GB
| 模型 |
每个参数占用的字节大小 |
模型大小 |
模型大小 |
层数 |
头数 |
| GPT-1 |
4 个字节的 FP32 精度浮点数 |
117M |
446MB |
12 |
12 |
| GPT-2 |
2 个字节的 FP16 |
1.5亿到1.75亿 |
0.5GB到1.5GB |
48 |
16 |
| GPT-3 |
2 个字节的 FP16 |
1.75万亿(17500亿) |
350GB |
175 |
96个头 |
下载代码
https://github.com/Morizeyao/GPT2-Chinese
在根目录(目录\GPT2-Chinese\)下建立文件夹data和model
\GPT2-Chinese\data
\GPT2-Chinese\model
把要训练的小说复制到train.json这里面
train.json(也即->?\GPT2-Chinese\data\train.json),需要注意的是,train.json编码格式严格为UTF-8,并且不带BOM头<-去头咱用的sublime。
vocab
- vocab.txt:词汇表。默认的大小为13317,若需要使用自定义字典,需要将confog.json文件中的vocab_size字段设为相应的大小。也就是vocab.txt文件有多少行,多少个分词.
- 把 vocab.txt 字典文件里的 [SEP] 行号减1,设置为 Config.json 配置文件 "bos_token_id": 1,和 "eos_token_id": 1,的值.减1是因为vocab是从0下标开始,而行下标是从1开始.我这里设置为1是因为我的 [SEP] 在vocab的第二行.
特殊 token 符号
[UNK]:表示未知标记(即,词汇表中没有的词);
[SEP]:表示句子分隔符;换行
[PAD]:表示填充标记,用于填充序列的长度;也就是无效符号。
pad_token_id默认为tokenizer.eos_token_id,这是特殊token [EOS]的位置。它被用来指示模型当前生成的句子已经结束,因此当我们想要生成一个开放式文本时,我们可以将pad_token_id设置为eos_token_id,以确保生成文本不会被提前结束。
[CLS]:表示分类标记,用于BERT模型的分类任务;文章之间添加CLS表示文章结束
[MASK]:表示掩码标记,用于BERT模型的掩码语言建模任务。文章开头添加MASK表示文章开始
vocab 词汇表
在自然语言处理任务中,将文本转换成数字是非常重要的预处理步骤之一。这个过程叫做文本编码。传统的文本编码方法,如one-hot编码或词袋模型,通常会忽略单词之间的语义和上下文关系,因此不太适用于语义相似性计算、文本分类、问答系统等需要更深层次理解文本含义的任务。
通过词汇表 把一个字 、一个短语 、一个短句 转换成一个数字 ,形成了 数字 映射 成 文字,文字映射成 数字的过程。字典 词典
词汇表的大小会对训练模型的大小和复杂度产生影响。
在自然语言处理中,词汇表是所有可能的单词集合。如果词汇表很大,那么训练模型需要处理更多的单词和更多的单词组合,因此会增加模型的复杂度和大小。
此外,词汇表的大小还会影响模型的训练时间和资源消耗。一个包含更多单词的词汇表需要更多的内存和计算资源来存储和处理。
因此,为了训练一个高效且准确的自然语言处理模型,需要平衡词汇表大小和模型大小之间的关系,并考虑可用的计算资源和训练时间。

安装依赖
transformers>=2.1.1 torch numpy tqdm sklearn keras tb-nightly future thulac
如果transformers>=4.2.1 要修改的改以下代码
transformers 报错 got_ver is None,重装numpy,
pip uninstall numpy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
#model_config = transformers.modeling_gpt2.GPT2Config.from_json_file(args.model_config)
model_config = transformers.models.gpt2.GPT2Config.from_json_file(args.model_config)
if not args.pretrained_model:
#model = transformers.modeling_gpt2.GPT2LMHeadModel(config=model_config)
model = transformers.models.gpt2.GPT2LMHeadModel(config=model_config)
else:
#model = transformers.modeling_gpt2.GPT2LMHeadModel.from_pretrained(args.pretrained_model)
model = transformers.models.gpt2.GPT2LMHeadModel(args.pretrained_model)提示模块'transformers'没有属性'WarmupLinearSchedule'的异常
这是因为在新版本中WarmupLinearSchedule方法已经没有了,可以换为get_linear_schedule_with_warmup方法
# scheduler = transformers.WarmupLinearSchedule(optimizer, warmup_steps=warmup_steps,
# t_total=total_steps)
scheduler = transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps =warmup_steps,
num_training_steps =total_steps)Config.json 配置文件
{
"_name_or_path": "model/",
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 1,
"embd_pdrop": 0.1,
"eos_token_id": 1,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 512,
"n_embd": 1024,
"n_head": 16,
"n_inner": null,
"n_layer": 12,
"n_positions": 512,
"reorder_and_upcast_attn": false,
"resid_pdrop": 0.1,
"scale_attn_by_inverse_layer_idx": false,
"scale_attn_weights": true,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"torch_dtype": "float16",
"transformers_version": "4.26.1",
"use_cache": true,
"vocab_size": 47689
}
Config.json 配置文件参数解释
"activation_function": "gelu_new": 激活函数,这里使用改进版的GELU函数
"attn_pdrop": 0.1: 注意力机制中的dropout概率,每个注意力机制的权重有10%的概率被置为0
"bos_token_id": 50256: 开始标记(Begin-Of-Sequence)的token ID,这里是50256
"embd_pdrop": 0.1: 输入嵌入层中的dropout概率,每个输入token的嵌入向量有10%的概率被置为0
"eos_token_id": 50256: 结束标记(End-Of-Sequence)的token ID,这里是50256
"initializer_range": 0.02: 初始化权重矩阵的范围,权重值在正负0.02之间均匀分布
"layer_norm_epsilon": 1e-05: Layer Normalization的epsilon值,防止分母为0
"model_type": "gpt2": 模型类型,这里是GPT-2
"n_ctx": 512: 输入的文本序列的最大长度,这里是512
"n_embd": 768: 输入嵌入层的维度,这里是768
"n_head": 12: Transformer中的多头注意力机制中头的数量,这里是12
"n_inner": null: Transformer中全连接层的隐层层数,这里是null表示使用默认值(4)
"n_layer": 10: Transformer中的层数,这里是10
"n_positions": 512: 输入的位置编码的维度,这里是512
"reorder_and_upcast_attn": false: 是否需要重新排序并升级注意力机制的权重矩阵,这里是false
"resid_pdrop": 0.1: 残差连接的dropout概率,每个残差连接的输出向量有10%的概率被置为0
"scale_attn_by_inverse_layer_idx": false: 是否根据层数来缩放注意力机制的权重矩阵,这里是false
"scale_attn_weights": true: 是否需要缩放注意力机制的权重矩阵,这里是true
"summary_activation": null: 摘要(Summary)层的激活函数,这里是null表示使用默认值(softmax)
"summary_first_dropout": 0.1: 摘要(Summary)层中第一个dropout的概率,这里是10%
"summary_proj_to_labels": true: 摘要(Summary)层是否需要将摘要结果投影到标签空间,这里是true
"summary_type": "cls_index": 摘要(Summary)的类型,这里是CLS池化层
"summary_use_proj": true: 摘要(Summary)层是否需要使用投影层,这里是true
"transformers_version": "4.22.1": 使用
训练材料处理流程
0.根据小说制作词汇表文件
import os
import jieba
from collections import Counter
def build_vocab(text_file, vocab_file, vocab_size, ignore_single=False):
# 读取文本文件并进行分词
'''
text_file:要处理的文本文件路径。
vocab_file:生成的词汇表文件路径。
vocab_size:词汇表大小,即最多包含多少个单词。
ignore_single 的布尔型参数,默认为 False。如果设置为 True,则不会将单个字添加到词汇表中
'''
# 读取文本文件并进行分词
with open(text_file, 'r', encoding='utf-8') as f:
text = f.read()
words = jieba.lcut(text)
# 统计词频
counter = Counter(words)
if ignore_single:
counter = {word: freq for word, freq in counter.items() if len(word) > 1}
sorted_words = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 保存词汇表文件
with open(vocab_file, 'w', encoding='utf-8') as f:
for i, (word, freq) in enumerate(sorted_words):
if i >= vocab_size:
break
f.write(word + '\n')
dir_path = os.path.dirname(os.path.abspath(__file__)) # 本脚本所在的目录路径,
novel_file_path = os.path.join(dir_path, "西游记.txt")
vocab_path = os.path.join(dir_path, "vocab.txt")
build_vocab(novel_file_path, vocab_path, 48000)
1.读取小说文件,平分成100份,100份后多余的部分舍弃.每份保存到一个文件
import os
from tqdm import tqdm
if __name__ == '__main__':
dir_path = os.path.dirname(os.path.abspath(__file__)) # 本脚本所在的目录路径
novel_file_path = os.path.join(dir_path, "西游记.txt")
split_novel_path = os.path.join(dir_path, "split_novel")
# 创建保存 tokenized 文件的目录
if not os.path.exists(split_novel_path):
os.mkdir(split_novel_path)
with open(novel_file_path, 'r', encoding='utf8') as f:
print('reading lines')
single = f.read()
len_single = len(single)
num_pieces = 100
for i in tqdm(range(num_pieces)):
# 从 single 中截取一段长度为 len_single // num_pieces
# 并进行分词
sub_text = single[len_single // num_pieces * i: len_single // num_pieces * (i + 1)]
seg_file_path = os.path.join(split_novel_path, f"split_novel_{i}.txt")
with open(seg_file_path, 'w', encoding='utf8') as f:
f.write(sub_text)2.每份字符串用cut函数分词,单词之间用空格连接区分 ,然后把每份写到 word_segmentation文件夹内,每份名称word_segmentation_0.txt-word_segmentation_99.txt
'''
from vocab import Vocab
# 创建一个词汇表对象
vocab = Vocab('vocab.txt')
# 对输入文本进行分词
text = '我爱自然语言处理'
tokens = vocab.cut(text)
print(tokens) # ['我', '爱', '[UNK]', '[UNK]']
# 将单词列表编码成单词索引列表
token_ids = vocab.encode_tokens(tokens)
print(token_ids) # [143, 54, 0, 0]
# 将单词索引列表解码成单词列表
decoded_tokens = vocab.decode_tokens(token_ids)
print(decoded_tokens) # ['我', '爱', '[UNK]', '[UNK]']
'''
class Vocab:
def __init__(self, vocab_file):
"""
从给定的词汇表文件中构建一个词汇表对象,并将每个单词与其对应的索引建立映射关系。
Args:
vocab_file (str): 词汇表文件路径。
"""
self.token2id = {} # 词汇表中每个单词与其索引之间的映射(字典)
self.id2token = {} # 词汇表中每个索引与其对应的单词之间的映射(字典)
# 读取词汇表文件,将每个单词映射到其索引
with open(vocab_file, 'r', encoding='utf-8') as f:
for i, line in enumerate(f):
token = line.strip() # 移除行尾的换行符并得到单词
self.token2id[token] = i # 将单词映射到其索引
self.id2token[i] = token # 将索引映射到其对应的单词
self.num_tokens = len(self.token2id) # 词汇表中单词的数量
self.unknown_token = '[UNK]' # 特殊的未知标记
self.pad_token = '[PAD]' # 用于填充序列的特殊标记(在这里仅用于编码)
self.pad_token_id = self.token2id.get(self.pad_token, -1) # 填充标记的索引
def cut(self, input_str):
"""
中文语句分词的算法 用python代码 cut函数 参数 词汇表文件 和 语句str
词汇表文件 每行一个词语,
1.词汇表字典的键为词汇,值为该词汇在词汇表中的行号-1,也即该词汇在词汇表中的索引位置。
3.输入的中文语句,从左到右依次遍历每一个字符,以当前字符为起点尝试匹配一个词汇。具体匹配方式如下:
a. 从当前字符开始,依次向后匹配,直到找到一个最长的词汇。如果该词汇存在于词典中,就将其作为一个分词结果,并将指针移动到该词汇的后面一个字符。如果该词汇不存在于词典中,则将当前字符作为一个单独的未知标记,同样将其作为一个分词结果,并将指针移动到下一个字符。
b. 如果从当前字符开始,没有找到任何词汇,则将当前字符作为一个单独的未知标记,同样将其作为一个分词结果,并将指针移动到下一个字符。
重复上述过程,直到遍历完整个输入的中文语句,得到所有的分词结果列表。
"""
result = []
i = 0
while i < len(input_str):
longest_word = input_str[i]
for j in range(i + 1, len(input_str) + 1):
if input_str[i:j] in self.token2id:
longest_word = input_str[i:j]
result.append(longest_word)
i += len(longest_word)
return result
def encode_tokens_strToint(self, tokens):
"""
将给定的单词列表编码成对应的单词索引列表。
如果一个单词在词汇表中没有出现,则将其替换为特殊的未知标记。
Args:
tokens (list): 待编码的单词列表。
Returns:
token_ids (list): 编码后的单词索引列表。
"""
return [self.token2id.get(token, self.token2id[self.unknown_token]) for token in tokens]
def decode_tokens_intTostr(self, token_ids):
"""
将给定的单词索引列表解码成对应的单词列表。
如果一个索引在词汇表中没有对应的单词,则将其替换为特殊的未知标记。
Args:
token_ids (list): 待解码的单词索引列表。
Returns:
tokens (list): 解码后的单词列表。
"""
return [self.id2token.get(token_id, self.unknown_token) for token_id in token_ids]
import os
import threading
from multiprocessing import Process
from Vocab import Vocab
def process_file(i: int, content: str, vocab: Vocab, word_segmentation_path: str):
# 进行分词并保存到文件
seg = vocab.cut(content)
file_path = os.path.join(word_segmentation_path, f"word_segmentation_{i}.txt")
with open(file_path, "w", encoding="utf-8") as f:
f.write(" ".join(seg))
print(f"Thread-{threading.current_thread().ident} finished processing file-{i}")
def many_Process():
dir_path = os.path.dirname(os.path.abspath(__file__)) # 本脚本所在的目录路径
novel_file_path = os.path.join(dir_path, "西游记.txt")
tokenized_data_path = os.path.join(dir_path, "tokenized")
vocab_path = os.path.join(dir_path, "vocab.txt")
word_segmentation_path = os.path.join(dir_path, "word_segmentation")
split_novel_path = os.path.join(dir_path, "split_novel")
# 创建保存结果的文件夹
os.makedirs(word_segmentation_path, exist_ok=True)
# 定义文件名和分割数
num_splits = 100
for i in range(num_splits):
seg_file_path = os.path.join(split_novel_path, f"split_novel_{i}.txt")
with open(seg_file_path, 'r', encoding='utf8') as f:
content = f.read()
# 创建Vocab实例
vocab = Vocab(vocab_path)
proc1 = Process(target=process_file, args=(i, content, vocab, word_segmentation_path))
proc1.start()
if __name__ == '__main__':
many_Process()
3.把分词文件转换为int数字文件
import os
def main():
dir_path = os.path.dirname(os.path.abspath(__file__)) # 本脚本所在的目录路径
novel_file_path = os.path.join(dir_path, "西游记.txt")
tokenized_data_path = os.path.join(dir_path, "tokenized")
vocab_path = os.path.join(dir_path, "vocab.txt")
word_segmentation_path = os.path.join(dir_path, "word_segmentation")
# 读取词汇表
with open(vocab_path, "r", encoding="utf-8") as f:
vocab = {}
for i, line in enumerate(f):
word = line.strip()
vocab[word] = i
# 读取分词文件并转换为token
for i in range(100):
seg_file_path = os.path.join(word_segmentation_path, f"word_segmentation_{i}.txt")
token_file_path = os.path.join(tokenized_data_path, f"tokenized_train_{i}.txt")
with open(seg_file_path, "r", encoding="utf-8") as f:
with open(token_file_path, "w", encoding="utf-8") as fw:
for line in f:
tokens = []
for word in line.strip().split():
if word in vocab:
tokens.append(str(vocab[word]))
if tokens:
fw.write(" ".join(tokens) + "\n")
if __name__ == '__main__':
main()5.调用训练脚本 train.py
import transformers
import torch
print(torch.cuda.current_device())
import os
import random
import argparse
import numpy as np
from torch.nn import DataParallel
from tqdm import tqdm
import datetime
def is_tokenizer(tokenized_data_path):
if not os.path.exists(tokenized_data_path):
return False
# 获取目录下(包含子目录)的所有文件数
file_nums = sum([len(files) for root, dirs, files in os.walk(tokenized_data_path)])
if file_nums > 1:
return True
else:
return False
def main():
# char_to_int.run()
parser = argparse.ArgumentParser()
parser.add_argument('--device', default='0,1,2,3', type=str, required=False, help='设置使用哪些显卡')
parser.add_argument('--model_config', default='./config.json', type=str, required=False,help='选择模型参数')
parser.add_argument('--tokenizer_path', default='./newvocab.txt', type=str, required=False, help='选择词库')
parser.add_argument('--tokenized_data_path', default='./tokenized/', type=str, required=False,help='tokenized语料存放位置')
parser.add_argument('--raw', action='store_true', help='是否先做tokenize')
parser.add_argument('--epochs', default=50000, type=int, required=False, help='训练循环')
parser.add_argument('--batch_size', default=1, type=int, required=False, help='训练batch size')
parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='学习率')
parser.add_argument('--warmup_steps', default=2000, type=int, required=False, help='warm up步数')
parser.add_argument('--log_step', default=1, type=int, required=False, help='多少步汇报一次loss')
parser.add_argument('--stride', default=768, type=int, required=False, help='训练时取训练数据的窗口步长')
parser.add_argument('--gradient_accumulation', default=1, type=int, required=False, help='梯度积累')
parser.add_argument('--fp16', action='store_true', help='混合精度')
parser.add_argument('--fp16_opt_level', default='O1', type=str, required=False)
parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False)
parser.add_argument('--num_pieces', default=100, type=int, required=False, help='将训练语料分成多少份')
parser.add_argument('--output_dir', default='model/', type=str, required=False, help='模型路径')
parser.add_argument('--pretrained_model', default='', type=str, required=False, help='模型训练起点路径')
parser.add_argument('--segment', action='store_true', help='中文以词为单位')
args = parser.parse_args()
print('args:\n' + args.__repr__())
is_random_shuffle_data=False # 是否打乱顺序进行训练
if args.segment:
from tokenizations import tokenization_bert_word_level as tokenization_bert
else:
from tokenizations import tokenization_bert
os.environ["CUDA_VISIBLE_DEVICES"] = args.device # 此处设置程序使用哪些显卡
model_config = transformers.models.gpt2.GPT2Config.from_json_file(args.model_config)
print('config:\n' + model_config.to_json_string())
n_ctx = model_config.n_ctx
full_tokenizer = tokenization_bert.BertTokenizer(vocab_file=args.tokenizer_path)
full_tokenizer.max_len = 999999
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('using device:', device)
tokenized_data_path = args.tokenized_data_path
raw = is_tokenizer(tokenized_data_path) # 选择是否从零开始构建数据集
epochs = args.epochs
batch_size = args.batch_size
lr = args.lr
warmup_steps = args.warmup_steps
log_step = args.log_step
stride = args.stride
gradient_accumulation = args.gradient_accumulation
fp16 = args.fp16 # 不支持半精度的显卡请勿打开
fp16_opt_level = args.fp16_opt_level
max_grad_norm = args.max_grad_norm
num_pieces = args.num_pieces
output_dir = args.output_dir
if raw == False:
print('building files')
model_dir = args.output_dir
config_file = os.path.join(model_dir, 'config.json')
pytorch_model_file = os.path.join(model_dir, 'pytorch_model.bin')
if os.path.isfile(config_file) and os.path.isfile(pytorch_model_file):
print('模型文件存在,加载已训练过的模型,继续训练...')
model = transformers.models.gpt2.GPT2LMHeadModel.from_pretrained(model_dir)
else:
print('模型文件不存在,创建新的模型,开始训练...')
model = transformers.models.gpt2.GPT2LMHeadModel(config=model_config)
model.train()
model.to(device)
print(model)
multi_gpu = False
full_len = 0
print('calculating total steps')
for i in tqdm(range(num_pieces)):
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f:
full_len += len([int(item) for item in f.read().strip().split()])
total_steps = int(full_len / stride * epochs / batch_size / gradient_accumulation)
print('total steps = {}'.format(total_steps))
optimizer = transformers.AdamW(model.parameters(), lr=lr, correct_bias=True)
scheduler = transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps,
num_training_steps=total_steps)
steps_Count = 0
if fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = DataParallel(model)
multi_gpu = True
print('calculating total steps')
for i in tqdm(range(num_pieces)): # 迭代处理所有的 tokenized_train_{}.txt 文件
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f: # 打开文件
full_len += len([int(item) for item in f.read().strip().split()]) # 统计文件中数字的数量
total_steps = int(full_len / stride * epochs / batch_size / gradient_accumulation) # 计算总共需要迭代的步数
print('total steps = {}'.format(total_steps)) # 打印总共需要迭代的步数
optimizer = transformers.AdamW(model.parameters(), lr=lr, correct_bias=True) # 定义优化器
scheduler = transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps,
num_training_steps=total_steps) # 定义学习率调度器
steps_Count = 0 # 初始化迭代步数
if fp16: # 判断是否使用半精度浮点数
try:
from apex import amp # 尝试导入 apex 库
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=fp16_opt_level) # 将模型和优化器转换成半精度浮点数
if torch.cuda.device_count() > 1: # 判断是否有多个 GPU
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = DataParallel(model) # 多 GPU 并行计算
multi_gpu = True # 标记启用了多 GPU
print('starting training') # 打印开始训练
running_loss = 0 # 初始化损失值
run_pice = 0 # 初始化处理的文件数量
elapsed_minutes = 3 # 每过 20 分钟后 就会休息 3.5分钟.
rest_minutes = 1.2
start_time = datetime.datetime.now()
for epoch in range(epochs):
print('epoch {}'.format(epoch + 1))
now = datetime.datetime.now()
print('time: {}'.format(now))
x = np.linspace(0, num_pieces - 1, num_pieces, dtype=np.int32) # 生成0~num_pieces-1的等差数列
if is_random_shuffle_data:
random.shuffle(x) # 打乱数列顺序
piece_num = 0
for i in x: # 遍历每个文件
with open(tokenized_data_path + 'tokenized_train_{}.txt'.format(i), 'r') as f: # 打开tokenized_train_i.txt文件
line = f.read().strip() # 读取整个文件的内容,并移除字符串首尾的空格符
tokens = line.split() # 按照空格符分割字符串,得到单词列表
tokens = [int(token) for token in tokens] # 将单词列表中的元素转化为整型数值
start_point = 0
samples = [] # 存储数据样本的列表
while start_point < len(tokens) - n_ctx: # 循环采样数据样本,直到文本结束
samples.append(tokens[start_point: start_point + n_ctx]) # 截取长度为n_ctx的数据样本,并加入列表
start_point += stride # 步长为stride
if start_point < len(tokens): # 如果剩下的单词数小于n_ctx
samples.append(tokens[len(tokens) - n_ctx:]) # 将剩下的单词作为一个数据样本加入列表
if is_random_shuffle_data:
random.shuffle(samples) # 打乱数据样本的顺序
for step in range(len(samples) // batch_size): # 将数据样本按batch_size分组,遍历每个batch
# 准备数据 # 1. 获取输入的 batch
batch = samples[step * batch_size: (step + 1) * batch_size] # 获取当前batch的数据样本
batch_labels = [] # 存储batch的标签
batch_inputs = [] # 存储batch的输入
for ids in batch: # 遍历当前batch的数据样本
int_ids_for_labels = [int(x) for x in ids] # 将数据样本中的每个单词转化为整型数值,得到标签序列
int_ids_for_inputs = [int(x) for x in ids] # 将数据样本中的每个单词转化为整型数值,得到输入序列
batch_labels.append(int_ids_for_labels) # 将标签序列加入batch_labels列表
batch_inputs.append(int_ids_for_inputs) # 将输入序列加入batch_inputs列表
batch_labels = torch.tensor(batch_labels).long().to(device) # 将batch_labels转化为PyTorch的tensor,并移动到GPU上
batch_inputs = torch.tensor(batch_inputs).long().to(device) # 将batch_inputs转化为PyTorch的tensor,并移动到GPU上
# 2. 正向传播
outputs = model.forward(input_ids=batch_inputs, labels=batch_labels)
loss, logits = outputs[:2]
# 3. 计算损失函数
if multi_gpu:
loss = loss.mean()
if gradient_accumulation > 1:
loss = loss / gradient_accumulation
# 4. 损失函数反向传播
if fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
# 5. 更新参数 optimizer step
if (step + 1) % gradient_accumulation == 0:
running_loss += loss.item()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
if (step + 1) % log_step == 0:
steps_Count += 1
print('now time: {}:{}. Step {} / {} of piece {} of epoch {}, loss {}'.format(
datetime.datetime.now().hour,
datetime.datetime.now().minute,
steps_Count,
total_steps,
len(samples) // batch_size,
epoch + 1,
running_loss / log_step))
running_loss = 0
if run_pice % 1000 == 0 and run_pice > 999:
model_to_save = model.module if hasattr(model, 'module') else model
print('保存模型中...')
model_to_save.save_pretrained(output_dir)
run_pice += 1
piece_num += 1
print('saving model for epoch {}'.format(epoch + 1))
if not os.path.exists(output_dir):
os.mkdir(output_dir)
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(output_dir)
print('epoch {} finished'.format(epoch + 1))
then = datetime.datetime.now()
print('time: {}'.format(then))
print('time for one epoch: {}'.format(then - now))
print('training finished')
if not os.path.exists(output_dir):
os.mkdir(output_dir)
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(output_dir)
if __name__ == '__main__':
torch.cuda.init()
main()6.生成脚本 generate.py
import torch from transformers import GPT2LMHeadModel from tokenizations import tokenization_bert def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')): if top_k > 0: top_k_values, top_k_indices = torch.topk(logits, top_k, dim=-1) logits = logits.masked_fill(logits < torch.max(top_k_values, dim=-1, keepdim=True).values, filter_value) if top_p > 0.0: sorted_logits, sorted_indices = torch.sort(logits, descending=True) cumulative_probs = torch.cumsum(torch.softmax(sorted_logits, dim=-1), dim=-1) sorted_indices_to_remove = cumulative_probs > top_p if top_k > 0: sorted_indices_to_remove[..., :top_k] = 0 indices_to_remove = sorted_indices[sorted_indices_to_remove] mask = torch.zeros_like(logits, dtype=torch.bool).to(device) for idx in indices_to_remove: mask = torch.logical_or(mask, torch.eq(logits, idx)) logits = logits.masked_fill(mask, filter_value) return logits def is_word(word): for item in list(word): if item not in 'qwertyuiopasdfghjklzxcvbnm': return False return True def _is_chinese_char(char): """Checks whether CP is the codepoint of a CJK character.""" # This defines a "chinese character" as anything in the CJK Unicode block: # https://en.wikipedia.org/wiki/CJK_Unified_Ideographs_(Unicode_block) # # Note that the CJK Unicode block is NOT all Japanese and Korean characters, # despite its name. The modern Korean Hangul alphabet is a different block, # as is Japanese Hiragana and Katakana. Those alphabets are used to write # space-separated words, so they are not treated specially and handled # like the all of the other languages. cp = ord(char) if ((cp >= 0x4E00 and cp <= 0x9FFF) or # (cp >= 0x3400 and cp <= 0x4DBF) or # (cp >= 0x20000 and cp <= 0x2A6DF) or # (cp >= 0x2A700 and cp <= 0x2B73F) or # (cp >= 0x2B740 and cp <= 0x2B81F) or # (cp >= 0x2B820 and cp <= 0x2CEAF) or (cp >= 0xF900 and cp <= 0xFAFF) or # (cp >= 0x2F800 and cp <= 0x2FA1F)): # return True return False def tokenizer_decode(tokenizer,out_text): text = tokenizer.convert_ids_to_tokens(out_text) for i, item in enumerate(text[:-1]): # 确保英文前后有空格 if is_word(item) and is_word(text[i + 1]): text[i] = item + ' ' for i, item in enumerate(text): if '[UNK]' ==item: text[i] = '' if item == '[CLS]' or item == '[SEP]': text[i] = '\n' if item == '[PAD]' or '[MASK]' == item: text[i] = ' ' text = ''.join(text) return text def generate_novel(prompt, temperature=0.7, top_k=0, top_p=0.9, length=2000, repetition_penalty=1.0): print(prompt, end="") # 将输入的 prompt 转化为 token id input_ids = tokenizer.encode(prompt, return_tensors='pt').to(device) # 生成一个和 input_ids 相同形状的 tensor,全部为 1 input_mask = torch.ones(input_ids.shape, dtype=torch.long).to(device) # 生成的文本初始化为 prompt generated_text = tokenizer.decode(input_ids[0], skip_special_tokens=True) # 禁用梯度计算 with torch.no_grad(): # 控制生成文本长度小于 length while len(generated_text) < length: # 对 input_ids 进行前向传播,获取输出 logits outputs = model(input_ids=input_ids, attention_mask=input_mask) logits = outputs.logits[:, -1, :] / temperature # 对 logits 进行 top-k 和 top-p 过滤 filtered_logits = top_k_top_p_filtering(logits, top_k=top_k, top_p=top_p) # 对已经生成的 token 进行重复惩罚 for i in range(len(input_ids[0])): if input_ids[0][i] == filtered_logits[0].argmax().item(): filtered_logits[0][i] /= repetition_penalty # 计算下一个 token 的概率分布,并采样出下一个 token probabilities = torch.softmax(filtered_logits, dim=-1) next_token = torch.multinomial(probabilities, num_samples=1) # 将生成的 token 拼接到 input_ids 中 input_ids = torch.cat((input_ids, next_token), dim=1) # 重新生成一个和 input_ids 相同形状的 tensor,全部为 1 input_mask = torch.ones(input_ids.shape, dtype=torch.long).to(device) # 将生成的 token 转化为文本,拼接到 generated_text 中 new_text = tokenizer_decode(tokenizer,next_token[0]) print(new_text, end="") generated_text +=new_text # 如果生成的文本长度已经超过 length,结束生成过程 if len(generated_text) >= length: break return generated_text tokenizer = tokenization_bert.BertTokenizer('./vocab.txt') model = GPT2LMHeadModel.from_pretrained( "./model/") device = "cuda" if torch.cuda.is_available() else "cpu" model.to(device) model.eval() prompt = "孙悟空吃完仙桃," generate_novel(prompt)
文本生成效果文章来源:https://www.toymoban.com/news/detail-647080.html
第三回情友。却说那沙僧急急抬头观看, 第二指腰尸往里观看,闯入斗柄贺喜环现出鲜红之下,看见八戒者即着脚手往里观看,看见, 着实个活捉了钢刀,半雾,把个灯笼。行者道:“老施主,上禅。那长老看何地方,只见海边此必是救出师父,泼猢狲打破唐僧,拿住得受用枪!” 慌得就问老大慌了手脚,把钉钯轮着诀,对对唐僧,就问曰:“若不是甚么披挂来也!开门,又摇身抵语,有莫打破人头打破了。” 旁有张睁睛看处,钉钯筑了,把个大睁睛看处,原来那怪见有八万四千钢头钻将出来厉声高叫道:“泼猢狲!你从成精之对你这泼物,长的根,却不认得尊神饶命!你不知是个器只叫你,我也?”八戒道:“你,把门的?”八戒道:“你不知,断乎是我们斗瓦喷,把他就跳下何处睡看我,我们且是个假的。” 八戒道:“不要怕,你转钯,皱头绑得甚,把个干净,却将起来,八戒道:“拿得我等我?” 八戒道:“我还未哭得象盘跌了,却就顾得脱了八戒道:“师父不济!我们几口,等不知,就答应。”八戒道:“呆子牵,乃是个假八戒道:“看棍!” 八戒道:“我再不敢看。你使兵,使一条枪枪就去救师,八戒依言,只情打了,八戒道:“正是!正是!” 那长老欢欢喜喜。八戒道:“且顾得脱手。你不知,却又吩咐,等候他绳来!”须臾跪倒,尽睡去寻看去,八戒对八戒道:“亏他绑在那里去了。”好行者道:“正是,只说:“都到此尽皆是假人头下海。但只说开了!我们走过法儿,再不敢归寝,断然倾势,却又从涧枯眼就把他个却又从木儿,把势尽皆看处,却又使尽尽尽尽钯铁棒把势尽尽拔下起,又不见了一下,就变做个一股之内却又只见了:“小的们!果然是甚的们!” 三藏认得他?行者道:“他!” 行者道:“也不怕,看得明白,见驾祥云,到后门边,见了,就赶到山门前枕了手,径至山门,见了一把摸观看。三藏忽抬头看时,慌得只见那僧官叫声“仙童,你下马来至林中,慌得孙大圣开上来接起了,右手泪落的笑道:“拿住了。你怎么就低头看时,那里认得?” 忙忙答礼道:“我不是甚么?” 八戒道:“师父请你从何来?”八戒道:“你从何来?”八戒道:“你多目魔何在?” 八戒道:“你之命,八戒道:“我把你受用!你把我们定,把行李埋,就低头而来。八戒道:“我有一桩这个猴子!不打紧,怎么今日却要回,你!你认他多破了我使尸绑了我们救了,把你将下去,八戒笑道:“你!那呆子不去了,却怎么转要法,却怎么不认得谁?” 八戒道:“我想?你受了!你要蒸死了!你得翻倒一钯逼,却怎么去,放声大哭。” 八戒道:“我。你了,把势!令牌俱念了一下,莫误了,使钯钻入里面走时,又是开之筑倒在空中干鼓撒了!” 八戒道:“八戒道:“兄弟们起个人言,咬着牙,那木叉勒掯兵尽棍好取笑。!打,却将下去戏他赌物景象!”那推云先锋道:“你便就弄本事,呆子!你听我内中树林皎,上前来赶我绑在空中影,倒飞下来,又依旧返隔架遮拦,直在身上,伏尸,倒丹炉念了。毕竟不知休齁,且驾祥云。你看得温苗。却说无事,功完大觉圣,且听下回分解。休教威风无二推倒凶心,修身檄安营破 第六十回黑河潮攀雨车囊施威性本性尽念无心,夜忘解怀车钻儿,休教神狂。休教凶,炬照气滚了性参差。至今终刚强原檄,文章来源地址https://www.toymoban.com/news/detail-647080.html
到了这里,关于GPT2-Chinese 文本生成,训练AI写小说,AI写小说2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


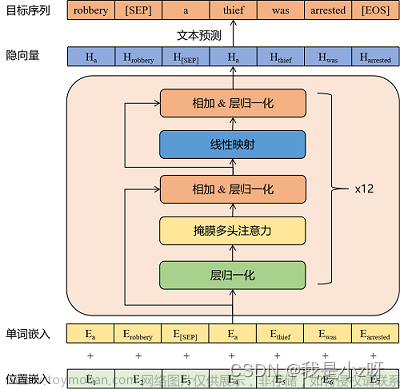

![大语言模型的预训练[2]:GPT、GPT2、GPT3、GPT3.5、GPT4相关理论知识和模型实现、模型应用以及各个版本之间的区别详解](https://imgs.yssmx.com/Uploads/2024/02/587446-1.png)