Stable Diffusion教程
本文是我在B站学习SD时做的笔记,大家有时间的话可以去学习一下这个教程,讲的很详细,是一个比较系统的教学,UP:Nenly同学

stable diffusion的安装
stable diffusion 百宝书_shenmingik的博客-CSDN博客
一、提示词分类和书写方式
正向提示词和反向提示词
提示词要用英文书写,可以有道翻译
书写方式可以以词组的方式进行书写
词组之间需要间隔符号,就是使用英文逗号
1.提示词分类
内容提示词
| 人物及主体特征 |
场景特征 |
环境光照 |
画幅视角 |
| 服饰穿搭 white dress |
室内、室外 indoor/outdoor |
白天黑夜 day/night |
距离 close-up,distant |
| 发型发色 blonde hair,long hair |
大场景 forest,city,street |
特定时段 morning,sunset |
人物比例 full body,upper body |
| 五官特征 small eyes,big moutn |
小细节 tree,bush,white flower |
光环境sunlight,bright,dark |
观察视角from above,view of back |
| 面部表情 smiling |
天空blue sky,starry sky |
镜头类型 wide angle,Sony A7 Ⅲ |
|
| 肢体动作 stretching arms |
画质提示词
| 画质提示词 |
画风提示词 |
| 通用高画质 best quality,ultra-detailed,masterpiece,hires,8k |
插画风 illustration,painting,paintbrush |
| 特定高分辨率 extremly,detailed CG unity 8K wallpaper(超精细的8K unity游戏CG),unreal engine rendered(虚幻引擎渲染) |
二次元 anime,comic,game CG |
| 写实系 photorealistic,realistic,photograph |
提示词模板
| 描述人物 |
(1girl:2.0),solo,nilou \(genshin impect\),solo,long hair,jewelry,blue gemstone,earrings,horns,crown,cyan satin strapless dress,white veil,neck ring,red hair,{green eyes}, (1个女孩:2.0),独奏,nilou \(genshin impect\),独奏,长发,珠宝,蓝色宝石,耳环,角,皇冠,青色缎面抹胸裙,白色面纱,颈环,红头发,{绿眼睛}, |
| 描述场景 |
indoor,room,house,sofa,wooden floor,plant,flowers,trees,windows 室内,房间,房子,沙发,木地板,植物,花,树木,窗户 |
| 描述环境(时间,光照) |
day,morning,sunlight,dappled sunlight,backlight,light rays,cloudy sky 白天,早晨,阳光,斑驳的阳光,背光,光线,多云的天空 |
| 描述画幅视角 |
full body,wide angle shot,depth of field 全身,广角,景深 |
| 其他画面要素 |
light particles,fantasy,wind blow,maple leaf,dusty...(其他往后增加) 光粒子,奇幻,风吹,枫叶,飞扬 |
| 高品质标准化 |
{{masterpiece}},{best quality},{highres},original,reflection,unreal engine,body shadow,artstationextremely detailed CG unity 8K wallpaper {{杰作}},{最佳质量},{高分辨率},原创,反射,虚幻引擎,身体阴影,(超精细的8K unity游戏CG) |
| 画风标准化 |
(illustration),painting,(stretch),anime coloring,fantasy (插图)、绘画、(拉伸),动漫着色,奇幻 |
| 其他特殊要求 |
exaggerated body proportion,greasy skin,realistic and delicate facial feature,SFW 夸张的身体比例,油腻的皮肤,逼真细腻的五官,SFW |
2. 权重与负面提示词
增强权重的方式
| 括号加数字 |
例:(white flower:1.5), 含义:调节白花(white flower)权重为原来的1.5倍(增强) |
例:(white flower:0.8), 含义:调节百花(white flower)的权重为原来的0.8倍(减弱) |
|
| 套括号 |
圆括号((((white flower))), 每套一层,额外×1.1倍 此处:调节白花(white flower)的权重为原来的1.1*1.1*1.1=1.331倍(增强) |
大括号{{{white flower}}}, 每套一层,额外×1.05倍 此处:调节白花(white flower)的权重为原来的约1.15倍(增强) |
方括号:[[[white flower]]] 每套一层,额外×0.9倍 此处:调节白花(white flower)的权重为原来的0.729倍(减弱) |
| 进阶语法 |
混合:white/yellow flower, 混合两个描述同一对象的提示词要素 此处:生成黄色和白色混合的花 |
迁移:[white/red/blue]flower 连续生成具有多个不同特征的对象,不断迁移 此处:先生成白色的花,在生成红色的花,最后在生成蓝色的花 |
迭代:(white flower:bush:0.8), 与采样进程关联,一定阶段后再生成特定的对象 此处:进程达到80%之前生成白花,80%之后在生成灌木 |
注意:避免个别词条权重过高,安全范围在1上下0.5左右,如果想要强调一个词条可以多写几个类似词条
负面提示词通用模板
保持画面颜色鲜艳,人物角色不缺少手指等畸形效果
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
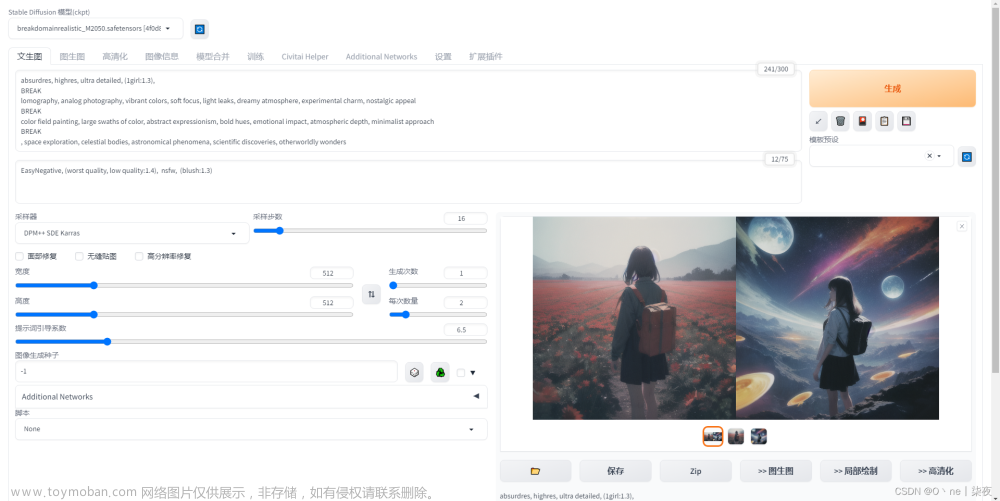
3.出图参数详解
- 采样迭代步数:默认20,最低不低于10,算力充足且想要更高的清晰度最高为30-40
- 采样方法:
Euler a,Euler——适合插画风格,出图比较朴素
DPM 2M,2M Karras——出图速度较快
SDE Karras——细节会更丰富
推荐使用最下面几个带+号的,改进过的算法,相对比较稳定
- 宽和高:出图分辨率,默认分辨率512*512,设备允许一般设置为1024*1024
分辨率过大会出现多人,多手,多脚效果
原因:AI训练使用的分辨率都很低,太大就默认多图拼接
解决措施:采用低分辨率创作,再使用高清修复选项进行修复
- 面部修复会默认勾选
- 平铺:用来生成可以无缝贴满整个屏幕的纹理性图片,不需要不用勾选
- 提示词相关性:数值越高,反应提示词的忠实度也越高,一般7-12,太高容易变形
- 生成批次:批量根据提示词生成图片
- 每批数量:增大可以让每批次的图像数量增多,是把同一批次的画拼在一起一次画的,一般不改动,容易爆显存
4.写提示词的三大方法
翻译法:自然语言转化——中文转英文,有提示词翻译插件Waifu Diffusion 1.4标签器
工具法:借助在线工具——辅助书写提示词的网站:AI绘画提示词生成器AI绘画提示词生成器 - 一个工具箱 - 好用的在线工具都在这里! (atoolbox.net)、AI词汇加速器AI词汇加速器 AcceleratorI Prompt (dawnmark.cn)
抄作业:参考提示词样本
模型网站:OpenArt.Ai:SD官方模型和欧美主流的模型生成的作品

网站二:arthub.ai——Arthub.ai: Discover, Upload and Share AI Generated Art
二、图生图
图生图原理
图片作为一种信息和特征提供给AI,更好的满足需求
2.图生图三个步骤
图生图基本三步法
上传图片——>输入提示词——>参数设置(大部分和文生图一致,最大区别重绘幅度,推荐0.6-0.8)
提示词余参数的技术解析
- 上传图片
通过拖拽或资源管理器加载图片
- 填写提示词
即便是经由图生图让AI绘画,也需要具体、准确的提示词
内容型+标准化提示词
- 参数设置
重绘幅度:
原图和成品图有多高的相似度,太高了容易变形,太低了实现不了重绘效果
分辨率:
优先维持和原图一致;
如果原图太大,可以按照比例折算到计算机可以实现的安全范围内;
如果成品比例和原图的比例不一致
法一:现在电脑上剪裁好再导入
法二:三种不同裁切方式提供适应尺寸
其他参数:
出图参数详解一致
3.随机种子作用解析
- 提示词修正:对背景进行进一步定义()in background:准确定义背景内容
- depth of field:景深,有助于营造摄影氛围
- 随机种子:抽卡的核心:每次会议一种不同的方式随机生成,随机生成的方式被记录为一串随机数字,即随机种子
- 不同随机种子带来随机性,相同随机种子效果相似——保持随机种子一致,进行提示词修改,实现人物风格基本一致
- 固定随机种子的方法:图库浏览也有记录随机种子数,在图片信息处,你可以看到Seed这个就是随机种子数

4.图生图的扩展应用
- 利用图生图实现物体拟人化
把真实的人像图片变得二次元:使用SD有更高的精确度和更大的定义空间
把静物、风景拟人化:导入不是人物的图片,用描述人物的提示词进行定义
- 二次元人物的三次元化
- 抽象派的AI画法
三、模型
1.文件格式
- 大模型被称为checkpoint,一般3-7GB,也有小的模型,后缀名为safetensors,一般1-2GB
2.模型网站平台
网站一:Hugging face
主流AI学习模型和数据集平台:Hugging face
链接:Hugging Face – The AI community building the future.
在modle下搜索:stable diffusion,左侧标签选择text to image就可以看到其他用户发布的主要用于AI绘画的文生图模型了

选择对应的模型可以看到Modle card标签介绍模型
需要下载选择File and versions,里面有模型的文件,需要大模型就去safe_checker文件夹找
Vae滤镜就在对应的文件夹下面找

进入对应的文件中下载就好啦

community标签是对这个模型感兴趣的人发起的社区,如果模型有什么bug可以来这边讨论
网站二:Civitai
选择标签High Rated,就是热度最高的模型

需要大模型需要在右边筛选栏选择:checkpoint,模型种类一般选择All,底模类型一般不选择

不同标签的含义

每个模型下面的介绍都应该读取,可能作者会推荐使用的VAE以及lora

点击模型下面对应的i标识,就有作者这个模型作品的提示词和一些关键参数设置

3.模型的类目与推荐
模型类目
二次元类:插画、漫画风
真实系:真实风格
2.5D风格:介于二者之间的
推荐查找关键词
| 二次元模型 |
真实系模型 |
2.5D模型 |
|
| 推荐标签与风格关键词 |
illustration,painting,skectch,drawing,comic,anime,cartoon |
photography,photo,realistic,photorealistic,Raw photo |
3D,render,chibi,digital art,concept art,{realistic} |
模型推荐


四、高清修复与放大算法
高清修复
概念:分两步,第一步生成低分辨率的图画,第二步使用它指定的高清算法,生成一个高分辨率的版本,在不改变构图的情况下丰富细节
文生图

高清修复参数:
- 放大倍数:是指放大到原图的多少倍,也可以按照参数后面手动设置新图像的宽和高
- 重绘幅度:是和原图的差异度,一般推荐0.5,安全放大区间0.3-0.5,具有自由度区间0.5-0.7
- 高清采样次数:和采样迭代数一样,不用选择,保持默认0的迭代次数
- 放大算法:概念比较复杂,几乎所有的算法出来的结果都是一致的,网上推荐无脑选择R-ESRGAN 4x+ 的,二次元的选择R-ESRGAN4x+ Anime6B,效果相较于其他算法是好一点的
图生图
- 在图库浏览器里,浏览已经做好的图片,选择信息栏的图生图,他会把你这个图片的所有信息同步到图生图里面,你只需要改变分辨率,控制重绘幅度就可以啦(PS:图片浏览器需要自己下载,我后面内容会有写到)
- 在设置选项的放大功能下可以自行定义用于放大图像的算法,选择完之后记得保存,这里选择的算法还是我们文生图推荐的那两个算法
SD放大(SD Upscale)
概念:根据指定的放大倍数,将图生图的图像拆解成若干小块按照固定逻辑重绘,再合并成一张大图,可以实现在低显存的条件下生成大尺寸的图片
选择”脚本“选项的SD放大脚本
缩放系数:相当于放大倍数,设置为2的意思是放大为原来的两倍
放大算法:我们还是默认选择R-ESRGAN 4x+ 的,二次元的选择R-ESRGAN4x+ Anime6B
图块重叠的像素:维持默认的64像素不变,是为了避免图片分块重画拼合的割裂的感觉(如下图),64是一个缓冲带的作用,为了分块画的画,画的更好,如果你觉得图片还是拼接的生硬,你可以把重叠像素改成128
注意:这时候要手动更改图片的尺寸,本身你的尺寸是600*600这时候要加上图块重叠像素,你要改成664*664(同理,重叠像素是128的话图片尺寸就要改成728*728)

对于缺点解决方法:增加缓冲带,重绘幅度降低为0.4
附加功能放大
概念:利用各种放大算法啊,在图像生成后再对它进行单独处理,使之拥有更高的分辨率尺寸
可以把已经绘制好的图片上传在附加功能下,也可以在图片浏览器显示的图片信息下面直接选择”附加功能”选项

在附加功能里面,可以看到以下设置,特点是有两个放大算法选择,可以给第二个算法选择权重,当然也可以不选择第二个算法,其他参数默认不变

4.总结
| 文生图:高清修复 |
图生图:SD放大 |
生成后处理:附加功能 |
| “打回重画,再来一幅” |
”分几块画,拼在一起“ |
”简单放大,随时可用“ |
| 分两步,第一步生成低分辨率的图画,第二步使用它指定的高清算法,生成一个高分辨率的版本,在不改变构图的情况下丰富细节 |
根据指定的放大倍数,将图生图的图像拆解成若干小块按照固定逻辑重绘,再合并成一张大图,可以实现在低显存的条件下生成大尺寸的图片 |
利用各种放大算法啊,在图像生成后再对它进行单独处理,使之拥有更高的分辨率尺寸 |
| 优势:
|
优势:
|
优势:
|
| 缺点:
|
缺点:
对于缺点解决方法:增加缓冲带,重绘幅度降低为0.4 |
缺点: 放大功能的效果不太显著 |
五、AI绘画进阶模型
文本嵌入——解决AI不会画手问题
(Embeddings/Textual Inversion)
- 概念:可以为我们指向一个特定的形象
- 后缀名:.pt
- 文件放置位置:model文件夹旁边的同名文件夹embeddings
- 使用方法:
不需要特别调用,只需要在提示词里使用"咒语"来召唤它,使用的咒语在下载C站的Details,可以看到Trigger World,在提示词后面加上这个”咒语“就可以生成对应的文件里

如果效果还是不是很明显,你可以将你下载的embedding图片导入到图生图功能中,选择反推提示词,有两种算法,CLP和DeepBooru,推荐DB,因为速度和识别准确度更好,再将反推词修改使用

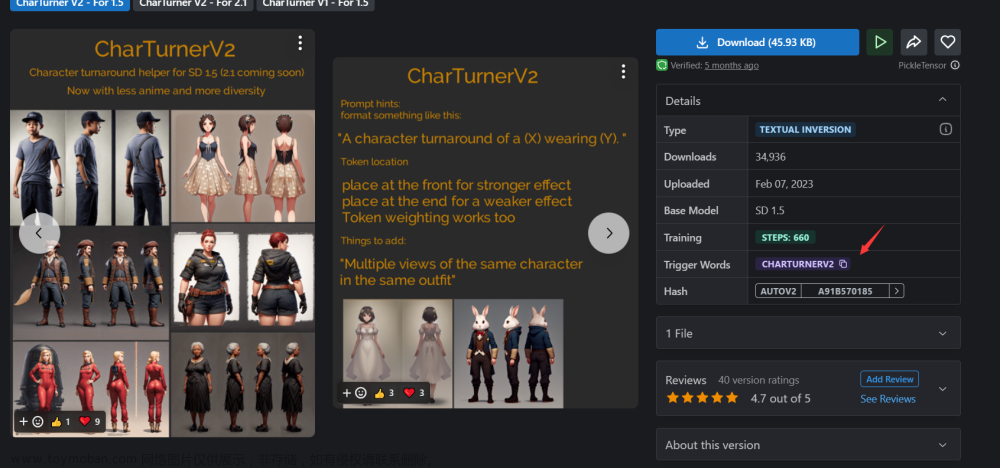
- 主要应用:角色转身、AI不会画手


模型:CharTurner(角色转身),很多精致的三视图人物设计
使用技巧:如下图

做出来的示例图

主要是在提示词前面要加上咒语,咒语是下载模型的时候那个信息栏的Trigger World

当然下载解决手部画的不好问题的embedding模型,可以解决这个问题
只需要在C站下载这类模型,我这里下载的是下面这个,咒语在图中标出,将咒语放在反向提示词中,给权重1.2就可以避免出现手部有问题的情况了,easynegitive不过可以处理手部的问题,它还可以处理肢体错落等问题,是一个比较好的负面提示词,但是他也不能100%保证所有的手部和四肢是好的。
这种画手模型有两个推荐:easynegitive提供给二次元
DeepNegitive主要是真人手部的问题

低秩模型Lora
概念:帮助你向AI传递一个特征明确,主体清晰的形象
放置位置:和model目录下的Lora子文件夹
使用方式:放置进去后,记住文件名字,在提示词里面使用尖括号<lora:+名字>就可以触发,现在好像可以在设置栏选择了

超网络——改变画风
Hypernetwork
- 概念:类似Lora
- 应用:用于改善图像整体风格,画风
- 放置位置:model文件夹下hypernetwork文件夹下
- 推荐:最受欢迎的叫Waven Chibi style

- 使用方法
到”设置“找到”附加网络“,将对应的hypernetwork文件添加到提示词中

六、局部重绘
当我们在进行AI绘画的过程中经常会出现画面畸形的现象,但是我们有很喜欢其他部分,重新画图就会改变这张图的整体布局,针对这一问题,可以参考使用局部重绘功能。
局部重绘功能只是在你要重绘的区域进行修正,其他区域的画面不会发生修改。
局部重绘基本操作
打开方式
方式一:点击图片下方局部重绘功能

方式二:打开图生图,在图生图中可以找到局部重绘的选项

既可以使用AI生成的图片也可以使用自己导入的图片
使用方法
我们维持提示词不变,在提示词后面添加需要改动的提示词,在参数重绘幅度开到一个比较高的数值,比如0.75,当把鼠标移动到图片区域会出现一个画笔笔尖,在图片中你想要更改的地方涂上黑色区域,画错了还有撤销和橡皮擦功能在右上角可以使用

核心参数解析
蒙版:蒙住关键区域的板子,上图中黑色区域就是蒙版
蒙版模式:默认选择“重绘蒙版内容”,如果是“重绘非蒙版内容”就是重绘黑色区域以外的内容
重绘区域:就是你要求AI重绘的时候你所提供的信息,默认“原图”,如果选择“仅蒙版”,那么AI得不到全图信息,重绘后的部分会和其他的地方有割裂感。如果你选的是仅蒙版模式,要对于右侧的仅蒙版模式的边缘预留像素进行调整,默认32。这个预留像素的意思就是缓冲带,使得重绘拼图的时候看上去更加自然。
蒙版模糊:类似PS羽化效果,使得拼接更加丝滑
蒙版蒙住的内容:随便选,看缘分

局部重绘(手涂蒙版)功能应用
局部重绘(手涂蒙版):相较于局部重绘功能没有太大区别,多了一个调色盘,相当于AI提示了颜色信息,比如说你可以给图片主角添加一个蓝色的眼镜,并在提示词上写出来,你会发现右边就会画出来蓝色的眼镜。如果你想重绘出原本画错的手,你可以自己画一个肤色的手,在提示词中添加相关提示词:手、击掌、五根手指。
3.局部重绘(上传蒙版)功能应用
点击标签,需要上传两张图片,一张是需要修改的图片,下方需要上传蒙版图片,来告诉AI哪里是需要重绘的,白色区域是所谓的蒙版区域,默认会被重绘,黑白区域哪一个需要重绘可以在下面的参数进行调整哦!

选择选区
你可以在PS里面进行创建蒙版照片
法一:在这里简单介绍一下PS的操作,如果你的画面有很明显的主体,点击上方菜单栏的“选择”,选择“主体”

法二:如果你画面的人物过于复杂,你可以选择左边工具栏的“对象选择工具”,在图片上框选出对应选区就可以了

法三:以上两种选择方式都是2021以上的高版本才可以使用的,你可以使用最常用的“魔棒工具”或“快速选择工具”进行选择。

蒙版制作
选择上方菜单栏的“图层”——“新建填充图层”——“纯色”

在跳出来的拾色器里,先把颜色定义为“白色”

随后在图层窗口里选中这个填充图层,按下CTRL+J复制一层图层

双击拷贝图层后前面的小方块,双击,把填充图层的颜色改成黑色

然后,鼠标单击后面的长方形,后面的东西就是我们要的蒙版

选中这个长方形,按下CTRL+I,交换蒙版区域

选择”文件“——”存储为副本导出图像“,格式可以是PNG或者是JPG的,一路维持默认参数,之后,把蒙版图片上传

这个蒙版图片就相当于前面两种局部重绘的涂涂画画,接下来写相关提示词和参数就可以在这一区域生成新的图形了(PS:我这里没扣干净,看一下大概效果就好)

七、功能扩展安装与推荐
1.3种扩展安装方式教学
SD所有扩展都在菜单栏的“扩展”模块中,分为三种,“已安装”、“可用的”、“通过链接安装”
 文章来源:https://www.toymoban.com/news/detail-647329.html
文章来源:https://www.toymoban.com/news/detail-647329.html
未完待续…… 文章来源地址https://www.toymoban.com/news/detail-647329.html
到了这里,关于Stable Diffusion最详细教程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!