这个文档主要是介绍一下我自己封装了 6 家厂商的短语音识别和实时流语音识别接口的一个包,以及对这些接口的一个对比。分别是,阿里,快商通,百度,腾讯,科大,字节。
zxmfke/asrfactory (github.com)
之前刚好在测试各家的语音识别相关功能,但是每家的返回值都不同,调用方式都不同,所以就封装了这么一个包。主要就是用简易工厂模式封装了一下,可以用来内部做测试。
功能方面,只是单纯的返回识别结果,实时流也是,正常是要再返回时间戳的,不过各家在时间戳上更是五花八门,就之后有空再封装。
有什么需求也欢迎讨论,另外,接口的app,账号需要自己去生成。
本文档偏主观,不喜勿喷
接口官方文档地址
| 短语音识别 | URL |
|---|---|
| 阿里 | 智能语音交互RESTfulAPI(ROA)示例_智能语音交互-阿里云帮助中心 (aliyun.com) |
| 快商通 | 快商通AI开放平台-短语音识别 |
| 百度 | 短语音识别标准版API - 语音技术 (baidu.com) |
| 腾讯 | 语音识别 一句话识别-一句话识别相关接口-API 中心-腾讯云 (tencent.cn) |
| 科大 | 语音听写_语音识别-讯飞开放平台 (xfyun.cn) |
| 字节 | 一句话识别–语音技术-火山引擎 (volcengine.com) |
| 实时流语音识别 | URL |
|---|---|
| 阿里 | 如何自行开发代码访问阿里语音服务_智能语音交互-阿里云帮助中心 (aliyun.com) |
| 快商通 | 快商通AI开放平台-实时语音识别 |
| 百度 | 语音技术 (baidu.com) |
| 腾讯 | 语音识别 实时语音识别(websocket)-API 文档-文档中心-腾讯云 (tencent.com) |
| 科大 | 实时语音转写_实时语音识别服务-讯飞开放平台 (xfyun.cn) |
| 字节 | 流式语音识别–语音技术-火山引擎 (volcengine.com) |
包封装实现
短语音识别
短语音比较简单,主要就是一个 http 请求,实现 Do 方法就可以了。
type Asr interface {
Do(fileName string, sampleRate define.AudioSampleRate) (string, error)
}
实时流语音识别
实时流识别主要是抽象成 5 个函数,均通过 websocket 的方式对接
type AsrWs interface {
// 初始化,创建 websocket 连接。把创建和发送 start 的逻辑封在一起。
Init() error
// 发送语音流数据
Send([]byte) error
// 接收识别结果
Recv(chan<- define.Output)
// 发送结束标识
End() error
// 关闭 websocket 连接
Close()
}
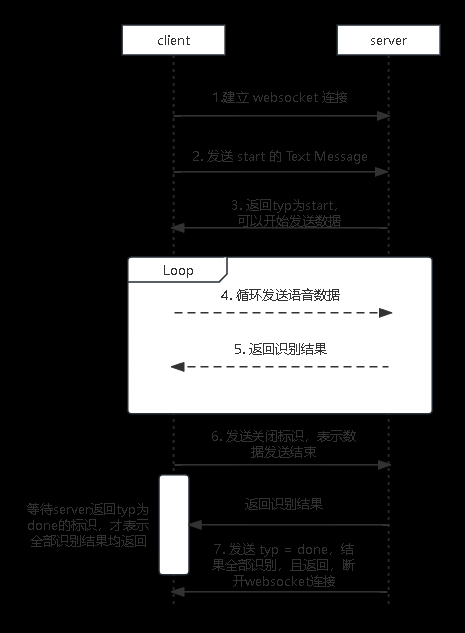
实时流语音识别可以分成 7 个步骤:
- 建立 web socket 连接;
- 发送 start 的 Text message;
这两步就是在 Init 里面实现,如果 start 没有,那 Init 里面就不会做 start 的逻辑
-
发送完 start 后,会返回给 client 可以发送的 message;
-
循环发送语音,通过 Send 方法;
-
同时接收识别结果,Recv 来接收识别结果;
-
语音数据发送结束后,发送给 server 端数据发送完毕的标识,即 End 方法;
-
发送 End 后,不要立马断开 web socket 连接。End 只是发送我没有要 server 端识别的数据了,不过还是要等 server 端把所有语音数据都是识别完成,返回全部识别结束。这时候才能 Close 连接。
Recv 和 End 方法在各家的实现里面是最不同的,所以抽象的地方主要是在这两个函数。不过无论后面要再加什么厂商的接口,基本上按照这 5 个方法,是没什么问题的。字节的就是,我在最后才加的。
接口语音要求
我只列常用的
| 语音要求 | |
|---|---|
| 阿里 | 16k/8k wav/pcm |
| 快商通 | 16k/8k wav |
| 百度 | 16k pcm |
| 腾讯 | 16k/8k wav/pcm |
| 科大 | 16k/8k pcm |
| 字节 | 16k/8k wav/pcm |
接口文档是否易懂
| 文档易懂 | |
|---|---|
| 阿里 | 有完整文档,字段描述清晰,范例代码挺多。 |
| 快商通 | 有完整文档,字段描述清晰,范例代码就一个js。 |
| 百度 | 有完整文档,字段描述清晰,逻辑性不是很强。 |
| 腾讯 | 有完整文档,字段描述清晰,逻辑性强,范例代码多 |
| 科大 | 有完整文档,字段描述清晰,过于复杂,字段命名不直观 |
| 字节 | 看文档看不懂,只能看懂调用逻辑,字段怎么用,只能直接看范例,范例也不知道为什么这么写 |
接口对接难易度
对接难易度这边更多指的是最后抽象成几个方法的难易度。
| 调用难易度 | |
|---|---|
| 阿里 | 易,发数据前要先发,开始message |
| 快商通 | 没有 go 范例,得自己写,不过逻辑还算比较简单清晰 |
| 百度 | 易,发数据前要先发,开始message |
| 腾讯 | 易,创建 ws 连接的时候得先获取 signature |
| 科大 | 有点麻烦,范例太过复杂,创建 ws 连接的时候得先获取 signature。嵌套多层,且字段名不直观,抽象过程麻烦。 |
| 字节 | 有点麻烦,范例太过复杂,发数据前要先发,开始message,抽象过程麻烦。 |
接口识别效果
识别效果我只测了中文,16k。8k 跟 16k 结果差不多。在正常语音,正常噪音情况下,腾讯,阿里排在前两位,后面的差不多。在有噪音前提下,大体相差不了多少。其中,快商通不支持多方言和多语种,其他的都可以。
响应时间,识别速度,腾讯 > 阿里 > 百度 > 快商通 > 科大 > 字节
接口免费调用次数
各平台免费调用次数都比较充足,价格就直接官网看比较直观,因为有阶梯的不好比较。直接跟商务谈的也会有所区别。文章来源:https://www.toymoban.com/news/detail-647517.html
总结
这个包就是来封装一下各家的语音识别接口,方便调用。选哪家因人而异,考量的点挺多。我个人觉得腾讯的是最好的,它文档很丰富,逻辑清晰,范例也很清楚,识别效果,识别速度都是最好的。快商通的简单,识别也还行,就是支持的功能太少了。科大的应该是不错的,不过不知道为什么识别效果怪怪的。字节的每太理解需要这么设计的逻辑,会给使用者增加一些不必要的麻烦,可能是我功力还不能理解他们的设计巧思。文章来源地址https://www.toymoban.com/news/detail-647517.html
到了这里,关于ASR 语音识别接口封装和分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!