Object 类相关方法
Object 类相关方法
getClass 获取当前运行时对象的 Class 对象。
hashCode 返回对象的 hash 码。
clone 拷贝当前对象, 必须实现 Cloneable 接口。浅拷贝对基本类型进行值拷贝,对引用类型拷贝引用;深拷贝对基本类型进行值拷贝,对引用类型对象不但拷贝对象的引用还拷贝对象的相关属性和方法。两者不同在于深拷贝创建了一个新的对象。
equals 通过内存地址比较两个对象是否相等,String 类重写了这个方法使用值来比较是否相等。
toString 返回类名@哈希码的 16 进制。
notify 唤醒当前对象监视器的任一个线程。
notifyAll 唤醒当前对象监视器上的所有线程。
wait 1、暂停线程的执行;2、三个不同参数方法(等待多少毫秒;额外等待多少毫秒;一直等待)3、与 Thread.sleep(long time) 相比,sleep 使当前线程休眠一段时间,并没有释放该对象的锁,wait 释放了锁。
finalize 对象被垃圾回收器回收时执行的方法。
2、基本数据类型
整型:byte(8)、short(16)、int(32)、long(64)
浮点型:float(32)、double(64)
布尔型:boolean(8)
字符型:char(16)
3、序列化
Java 对象实现序列化要实现 Serializable 接口。
反序列化并不会调用构造方法。反序列的对象是由 JVM 自己生成的对象,不通过构造方法生成。
序列化对象的引用类型成员变量,也必须是可序列化的,否则,会报错。
如果想让某个变量不被序列化,使用 transient 修饰。
单例类序列化,需要重写 readResolve() 方法。
4、String、StringBuffer、StringBuilder
String 由 char[] 数组构成,使用了 final 修饰,是不可变对象,可以理解为常量,线程安全;对 String 进行改变时每次都会新生成一个 String 对象,然后把指针指向新的引用对象。
StringBuffer 线程安全;StringBuiler 线程不安全。
操作少量字符数据用 String;单线程操作大量数据用 StringBuilder;多线程操作大量数据用 StringBuffer。
5、重载与重写
重载 发生在同一个类中,方法名相同,参数的类型、个数、顺序不同,方法的返回值和修饰符可以不同。
重写 发生在父子类中,方法名和参数相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 或者 final 则子类就不能重写该方法。
6、final
修饰基本类型变量,一经出初始化后就不能够对其进行修改。
修饰引用类型变量,不能够指向另一个引用。
修饰类或方法,不能被继承或重写。
7、反射
在运行时动态的获取类的完整信息
增加程序的灵活性
JDK 动态代理使用了反射
8、JDK 动态代理
使用步骤
创建接口及实现类
实现代理处理器:实现 InvokationHandler ,实现 invoke(Proxy proxy,Method method,Object[] args) 方法
通过 Proxy.newProxyInstance(ClassLoaderloader, Class[] interfaces, InvocationHandler h) 获得代理类
通过代理类调用方法。
9、Java IO
普通 IO ,面向流,同步阻塞线程。
NIO,面向缓冲区,同步非阻塞。
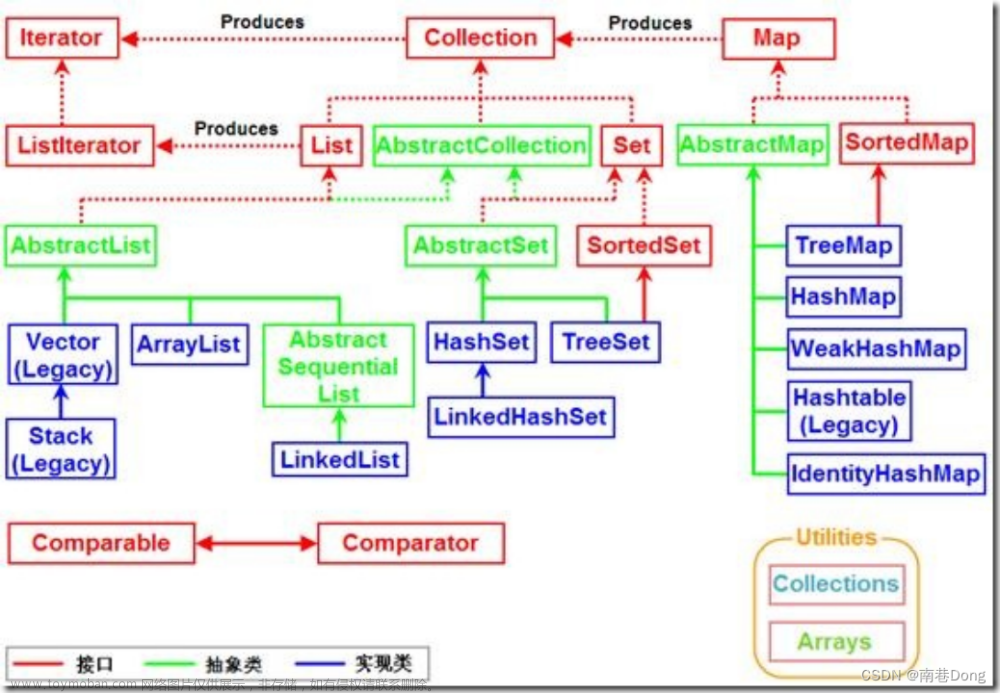
二、Java 集合框架
1、List(线性结构)
ArrayList Object[] 数组实现,默认大小为 10 ,支持随机访问,连续内存空间,插入末尾时间复杂度 o(1),插入第 i 个位置时间复杂度 o(n - i)。扩容,大小变为 1.5 倍,Arrays.copyOf(底层 System.ArrayCopy),复制到新数组,指针指向新数组。
Vector 类似 ArrayList,线程安全,扩容默认增长为原来的 2 倍,还可以指定增长空间长度。
LinkedList 基于链表实现,1.7 为双向链表,1.6 为双向循环链表,取消循环更能分清头尾。
2、Map(K,V 对)
HashMap
底层数据结构,JDK 1.8 是数组 + 链表 + 红黑树,JDK 1.7 无红黑树。链表长度大于 8 时,转化为红黑树,优化查询效率。
初始容量为 16,通过 tableSizeFor 保证容量为 2 的幂次方。寻址方式,高位异或,(n-1)&h 取模,优化速度。
扩容机制,当元素数量大于容量 x 负载因子 0.75 时,容量扩大为原来的 2 倍,新建一个数组,然后转移到新数组。
基于 Map 实现。
线程不安全。
HashMap (1.7) 多线程循环链表问题
在多线程环境下,进行扩容时,1.7 下的 HashMap 会形成循环链表。
怎么形成循环链表: 假设有一 HashMap 容量为 2 , 在数组下标 1 位置以 A -> B 链表形式存储。有一线程对该 map 做 put 操作,由于触发扩容条件,需要进行扩容。这时另一个线程也 put 操作,同样需要扩容,并完成了扩容操作,由于复制到新数组是头部插入,所以 1 位置变为 B -> A 。这时第一个线程继续做扩容操作,首先复制 A ,然后复制 B ,再判断 B.next 是否为空时,由于第二个线程做了扩容操作,导致 B.next = A,所以在将 A 放到 B 前,A.next 又等于 B ,导致循环链表出现。
HashTable
线程安全,方法基本全用 Synchronized 修饰。
初始容量为 11 ,扩容为 2n + 1 。
继承 Dictionary 类。
ConcurrentHashMap
线程安全的 HashMap。
1.7 采用分段锁的形式加锁;1.8 使用 Synchronized 和 CAS 实现同步,若数组的 Node 为空,则通过 CAS 的方式设置值,不为空则加在链表的第一个节点。获取第一个元素是否为空使用 Unsafe 类提供的 getObjectVolatile 保证可见性。
对于读操作,数组由 volatile 修饰,同时数组的元素为 Node,Node 的 K 使用 final 修饰,V 使用 volatile 修饰,下一个节点也用 volatile 修饰,保证多线程的可见性。
LinkedHashMap LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。
TreeMap 有序的 Map,红黑树结构,可以自定义比较器来进行排序。
Collections.synchronizedMap 如何实现 Map 线程安全? 基于 Synchronized ,实际上就是锁住了当前传入的 Map 对象。
3、Set(唯一值)
HashSet 基于 HashMap 实现,使用了 HashMap 的 K 作为元素存储,V 为 new Object() ,在 add() 方法中如果两个元素的 Hash 值相同,则通过 equals 方法比较是否相等。
LinkedHashSet LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。
TreeSet 红黑树实现有序唯一。
三、Java 多线程
1、synchronized
修饰代码块 底层实现,通过 monitorenter & monitorexit 标志代码块为同步代码块。
修饰方法 底层实现,通过 ACC_SYNCHRONIZED 标志方法是同步方法。
修饰类 class 对象时,实际锁在类的实例上面。
单例模式
public class Singleton {
private static volatile Singleton instance = null;
private Singleton(){}
public static Singleton getInstance(){
if (null == instance) {
synchronized (Singleton.class) {
if (null == instance) {
instance = new Singleton();
}
}
}
return instance;
}
}
private static volatile Singleton instance = null;
private Singleton(){}
public static Singleton getInstance(){
if (null == instance) {
synchronized (Singleton.class) {
if (null == instance) {
instance = new Singleton();
}
}
}
return instance;
}
偏向锁,自旋锁,轻量级锁,重量级锁
通过 synchronized 加锁,第一个线程获取的锁为偏向锁,这时有其他线程参与锁竞争,升级为轻量级锁,其他线程通过循环的方式尝试获得锁,称自旋锁。若果自旋的次数达到一定的阈值,则升级为重量级锁。
需要注意的是,在第二个线程获取锁时,会先判断第一个线程是否仍然存活,如果不存活,不会升级为轻量级锁。
2、Lock
ReentrantLock
基于 AQS (AbstractQueuedSynchronizer)实现,主要有 state (资源) + FIFO (线程等待队列) 组成。
公平锁与非公平锁:区别在于在获取锁时,公平锁会判断当前队列是否有正在等待的线程,如果有则进行排队。
使用 lock() 和 unLock() 方法来加锁解锁。
ReentrantReadWriteLock
同样基于 AQS 实现,内部采用内部类的形式实现了读锁(共享锁)和写锁 (排它锁)。
非公平锁吞吐量高 在获取锁的阶段来分析,当某一线程要获取锁时,非公平锁可以直接尝试获取锁,而不是判断当前队列中是否有线程在等待。一定情况下可以避免线程频繁的上下文切换,这样,活跃的线程有可能获得锁,而在队列中的锁还要进行唤醒才能继续尝试获取锁,而且线程的执行顺序一般来说不影响程序的运行。
3、volatile
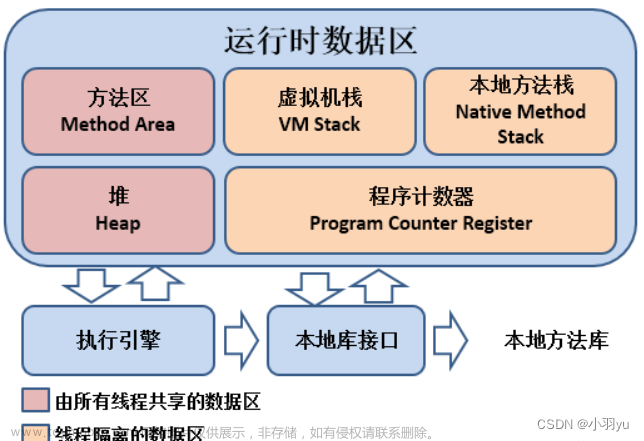
Java 内存模型
image.png
在多线程环境下,保证变量的可见性。使用了 volatile 修饰变量后,在变量修改后会立即同步到主存中,每次用这个变量前会从主存刷新。
禁止 JVM 指令重排序。文章来源:https://www.toymoban.com/news/detail-647564.html
单例模式双重校验锁变量为什么使用 volatile 修饰? 禁止 JVM 指令重排序,new Object()分为三个步骤:申请内存空间,将内存空间引用赋值给变量,变量初始化。如果不禁止重排序,有可能得到一个未经初始化的变文章来源地址https://www.toymoban.com/news/detail-647564.html
到了这里,关于Java 基础知识点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!