Contest type: Data mining, two classification.
User addition prediction is a key step in analyzing user usage scenarios and predicting user growth, which is helpful for subsequent product and application iterative upgrades.
The data set consists of about 620,000 training sets and 200,000 test sets, including 13 fields.
In the preceding command, uuid is the unique identifier of the sample, eid is the ID of the access behavior, and udmap is the behavior attribute. key1 to key9 indicates different behavior attributes, such as project name and project id, common_ts indicates the occurrence time of the application access record (ms timestamp), and other fields x1 to x8 are user-related attributes. Fields are processed anonymously. The target field indicates the predicted target, that is, whether a new user is added.
The contest is a typical data mining contest, which requires manual feature extraction and model construction, and feature differences will bring great differences in scores.
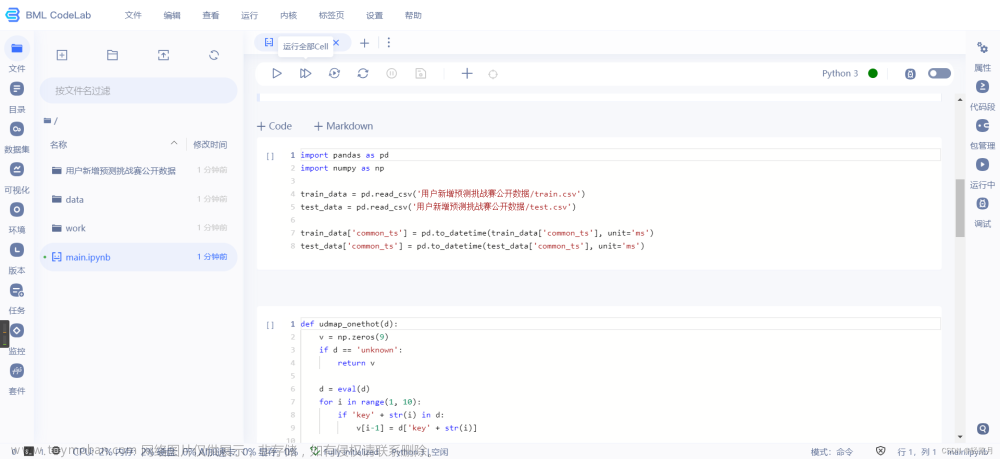
Here's the Baseline.
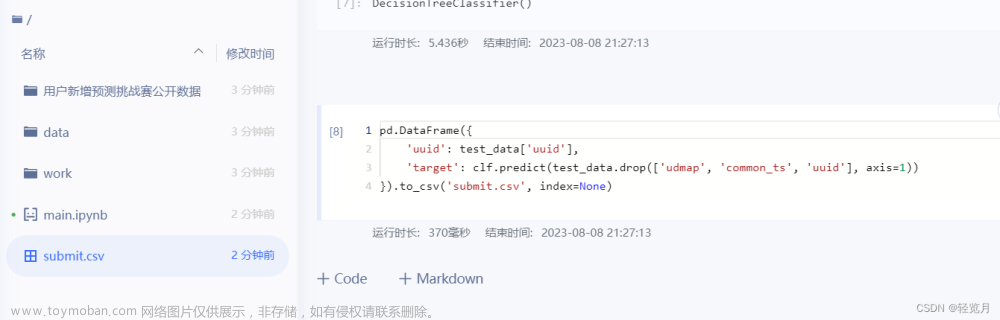
import pandas as pd import numpy as np train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv') test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv') train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms') test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')def udmap_onethot(d): v = np.zeros(9) if d == 'unknown': return v d = eval(d) for i in range(1, 10): if 'key' + str(i) in d: v[i-1] = d['key' + str(i)] return v train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot))) test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot))) train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)] test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]train_data = pd.concat([train_data, train_udmap_df], axis=1) test_data = pd.concat([test_data, test_udmap_df], axis=1)train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts()) test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts()) train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean()) test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int) test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)train_data['common_ts_hour'] = train_data['common_ts'].dt.hour test_data['common_ts_hour'] = test_data['common_ts'].dt.hourimport lightgbm as lgb from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() clf.fit( train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), train_data['target'] )pd.DataFrame({ 'uuid': test_data['uuid'], 'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) }).to_csv('submit.csv', index=None)
Evaluation index:
The evaluation criteria of this competition is f1_score, the higher the score, the better the effect.
Operational configuration requirements
- When running, select the CPU2 core 8G or V100 16G configuration, free configuration can run perfectly.
- The total running time takes 1 to 5 minutes. Please wait patiently.
文章来源:https://www.toymoban.com/news/detail-647608.html

Provide corresponding AI capabilities and solutions for different industries and different scenarios, empower developers' products and applications, help developers solve relevant practical problems through AI, and realize that products can listen, speak, see, recognize, understand and think.文章来源地址https://www.toymoban.com/news/detail-647608.html
到了这里,关于Machine Learning in Action: User Addition Prediction Challenge的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[FL]Adversarial Machine Learning (1)](https://imgs.yssmx.com/Uploads/2024/02/783704-1.jpeg)
![[Machine Learning] 损失函数和优化过程](https://imgs.yssmx.com/Uploads/2024/02/664633-1.png)
![[Machine Learning] decision tree 决策树](https://imgs.yssmx.com/Uploads/2024/02/665843-1.png)