一、说明
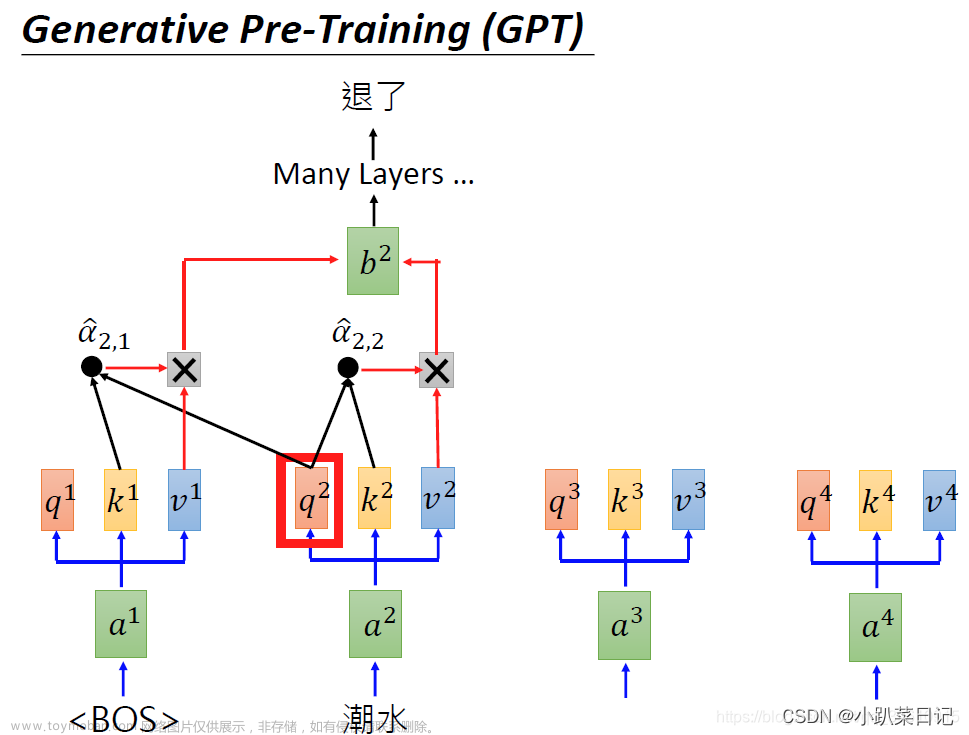
我已经解释了什么是注意力机制,以及与转换器相关的一些重要关键字和块,例如自我注意、查询、键和值以及多头注意力。在这一部分中,我将解释这些注意力块如何帮助创建转换器网络,注意、自我注意、多头注意、蒙面多头注意力、变形金刚、BERT 和 GPT。文章来源地址https://www.toymoban.com/news/detail-647779.html
二、内容:
文章来源:https://www.toymoban.com/news/detail-647779.html
到了这里,关于【变形金刚02】注意机制以及BERT 和 GPT的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!