1 问题
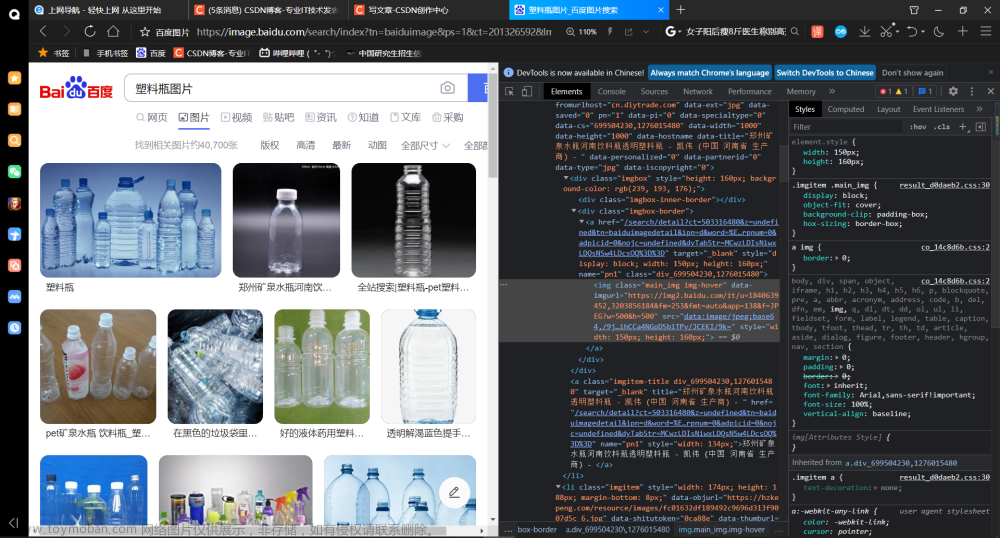
在工作中,有时会遇到需要相当多的图片资源,可是如何才能在短时间内获得大量的图片资源呢?
2 方法
我们知道,网页中每一张图片都是一个连接,所以我们提出利用爬虫爬取网页图片并下载保存下来。
首先通过网络搜索找到需要的图片集,将其中图片链接复制然后编入爬虫代码,随后利用open()、iter_content()、write()等函数将图片下载并保存下来,同时还要确定图片保存的路径以便于查找图片。
- 找到需要的图片的网页链接;
- 利用爬虫根据网页爬取图片;
- 将图片下载并保存;
通过实验、实践等证明提出的方法是有效的,是能够解决开头提出的问题。
代码清单 1
| import requests def get_pictures(web,path): headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'} re=requests.get(web,headers=headers) print(re.status_code) with open(path, 'wb') as f: for chunk in re.iter_content(chunk_size=128): f.write(chunk) web='https://static.nowcoder.com/fe/file/oss/1655700469353QRQEI.jpg' path='数据分析.jpg' get_pictures(web,path) |
3 结语文章来源:https://www.toymoban.com/news/detail-647847.html
针对如何短时间内获取大量图片的问题,提出使用爬虫、open()函数、iter_content()函数、write()函数等方法将图片下载并保存,通过实验,证明该方法是有效的。其中对于正则表达式的书写方法还不够熟练,对于函数open()、iter_content()、write()的使用还存在很多未知,由于知识和技术上存在问题以上代码只能获取一张图片,我们相信通过不断地学习与练习,我们能进一步优化方法,最终达成目的。文章来源地址https://www.toymoban.com/news/detail-647847.html
到了这里,关于利用爬虫爬取图片并保存的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!