作者简介
Pin,关注 RPC、Service Mesh、Serverless 等云原生技术。
一、背景
随着上云项目的不断推进,大量的应用需要部署到 aws 上,其中有很多应用都依赖延迟队列的功能。而在 aws 上,我们选择以 Kafka 作为消息队列,但是 Kafka 本身不支持延迟队列,这就需要思考如何基于 Kafka 来实现延迟队列。
二、需求
统计了一下所有需要使用到延迟队列的场景,有以下几大特点:
延迟时间不固定。有的 topic 需要支持 5 分钟的延迟,有的却要求支持 7 天的延迟。
延迟消息数量小。所有的场景中涉及到的每天延迟消息的数量不超过 1 亿条,每条消息的大小不超过 1MB。
延迟消息不能丢失,可以不保证有序。
延迟误差小。延迟误差是指实际消费消息的时间和希望消费消息之间的时间差值。根据统计的业务场景来看,要求延迟误差在 2s 以内。
生产延迟消息的峰值比较高。很多情况下,业务会一次性创建 1000 万条延迟消息,并且这些延迟消息的延迟时长都是一致的。
三、目标
由于实现延迟队列的方式有很多,我们在满足需求的前提下,制定了几个目标:云上成本低、运维成本低、开发成本低、稳定性高和延迟误差小。
四、产品选型
在 aws 上支持消息队列的产品有 RabbitMQ、Apache ActiveMQ 和 SQS。其中 RabbitMQ 和 Apache ActiveMQ aws 主要是托管其安装部署,并非是以 Serverless 的方式对外提供服务。另外,我们当前已经选择使用 Kafka 作为消息队列,若仅仅为了满足延迟队列的功能而去更换消息队列,成本显然是巨大的。
除此之外,aws 还提供了 SQS 来支持延迟队列,虽然 SQS 是 Serverless 的,但是 SQS 有他自身的局限性:SQS 最多支持 15 分钟以内的延迟,明显无法满足我们的需求。
可见,仅仅基于云上已有的产品已无法满足我们的需求,基于这个原因,我们开始调研延时消息的实现方案,看看能否通过少量的开发来实现我们的需求。
五、方案调研
业界实现延时队列功能的方案比较多,我们对其进行了简单的分析,具体如下:
5.1 RabbitMQ
RabbitMQ 是基于 TTL+ 死信队列的方式来实现的。具体来说,通过设置消息的 TTL,当达到 TTL 时消息还没有被消费,此时会投递到死信队列。TTL 分两种:
Queue 级别的 TTL:所有消息统一的 TTL
Message 级别的 TTL:每条消息可以是不同的 TTL,但是存在队头阻塞问题
该方案的优点是实现简单,但是延迟误差不确定。
5.2 Apache ActiveMQ
Apache ActiveMQ 是基于定时调度的方式来实现的。具体来说,配置延迟时间或者 cron 表达式表示消息的投递策略,基于 Java 的 Timer 实现,将消息分级存储在文件和内存中。
该方案的优点是实现简单,延迟误差可控,但是可能会占用大量内存。
5.3 RocketMQ
RocketMQ 是基于定时调度+延迟等级的方式来实现的。具体来说,将延时消息发送到指定的延时等级队列(一共有 18 个等级),然后通过一个定时器进行轮询这些 ConsumeQueue 实现延时的效果。具体实现如下:
修改消息 topic 名称和队列信息投递到对应等级的延时消息的 ConsumeQueue 中
ScheduleMessageService消费ConsumeQueue中的消息再重新投递到 CommitLog 中
将 CommitLog 中的消息投递到目标 topic 中,消费者消费目标 topic 中的消息
该方案的优点是延迟误差可控,但是实现复杂。
5.4 Redis
基于 Redis 实现延迟队列的方式有很多,在这里简单描述两种:
1)定时轮询
该方案的大致步骤如下:
将消息的延时时间戳作为 zset 的 key,消息的 ID 作为 zset 的 value
消息 ID 作为 key,消息体序列化成 String 作为 value 存储在 Redis 中
定时轮询 zset,大于当前时间则投递到 Redis 的 List 中供消费者消费
2)Key 过期监听器
每条消息设置一个过期时间,监听过期事件然后将消息投递到 target topic。
基于 Redis 实现延时队列的优点是实现简单,但是都可能存在丢消息的情况,并且存储成本高。
六、实现方案
既然使用单一的云上产品不能满足我们的需求,那就只能考虑通过少量的开发并结合云上产品的特性来实现基于 Kafka 的延迟队列的功能。具体的实现方案有如下几种:
6.1 RabbitMQ 或 Apache ActiveMQ
RabbitMQ 或者 Apache ActiveMQ 都是 aws 上支持的产品,从功能层面来看是可以满足需求。当前的消息队列是基于 Kafka 实现的,如果再结合 RabbitMQ 或者 Apache ActiveMQ 来实现延迟队列的功能,主要面临的问题是:缺少对 RabbitMQ 或者 Apache ActiveMQ 相关的技术储备,由于 aws 上对 RabbitMQ 或者 Apache ActiveMQ 仅仅只是部署层面的托管,当出现问题时,是需要有研发人员自己去 troubleshooting 的。所以,该方案就不考虑了。
6.2 基于 SQS 的多级队列
既然 SQS 已经支持 15 分钟内的延时队列,那么如果要实现更长时间的延迟队列是不是可以考虑通过多级延迟队列来实现?具体实现方案如下:
在延迟消息中增加一个字段 times 用来表示当前是第几轮(借鉴时间轮算法的思路)。
如果延迟消息的延迟时间小于 15 分钟,将延迟消息的 times 设置为 0,直接投递到 SQS 中。
如果延迟消息的延迟时间大于 15 分钟,计算一下 times 的值(延迟时间/15 分钟),然后直接投递到 SQS 中。
如果 Consumer 从 SQS 中消费到了一个延迟消息且 times 大于 0,则将 times 的值减去 1,再次投递到 SQS 中。如此反复,直到 times 为 0。
如果 Consumer 从 SQS 中消费到了一个延迟消息且 times 为 0,则表示该消息已经达到了延迟时间,则 Consumer 会直接将该消息投递到对应的目标 topic。
这种方案虽然能够实现延迟队列的功能,且 SQS 本身也是 Serverless 的,维护成本也比较低。
但是我们调研了一下 SQS 的计费标准发现,SQS 主要是根据消息数量来收费的。这样一来,如果延迟时间越长,消息数量会被放大的越严重。而我们实际业务中延迟时间在 15 分钟以内的没有,一般是 1 小时到 7 天,所以这种方案不可行。
6.3 基于 SQS 和定时调度策略
使用基于 SQS 的多级队列的方式最大的问题是云上的成本问题,更具体一点是云上的存储成本问题。因为该方案将所有的延迟消息都存储在 SQS 中,这是导致费用增加的最主要原因。既然如此,那我们是不是可以考虑将大于 15 分钟延迟时间的消息写入到一个成本低的存储上,然后在时间延迟时间小于 15 分钟的时候将其查询出来投递到 SQS 中即可。这样一来,延迟时间的长短不会对 SQS 的费用有影响,仅仅只需要考虑如何选择一个存储成本低、读写方便的 Serverless 产品作为延迟消息的存储即可。
基于这一思路,设计了一个基于 SQS 和定时调度策略的实现方案:

具体流程如下:
生产者 Producers 生产的正常消息直接投递到 Kafka 的目标 topic,如果是延迟消息投递到 Kafka 的一个延迟消息的 Delay Message Topic 中。
Consumer 消费 Delay Message Topic 中的消息,如果该消息的延迟时间小于 15 分钟,直接投递到 SQS(Delay Queue)中。如果消息的延迟时间大于 15 分钟,直接将消息写入到 Message Store 中。
Scheduler 会定时扫描 Message Store 中的消息,如果发现延迟时间小于 15 分钟,则直接投递到 SQS(Delay Queue)中,Scheculer 是通过 Event Bridge 来触发的。
Emitter 会消费 SQS(Delay Queue)中的消息,并将该消息投递到目标 topic 中。
整个流程不算复杂,里面涉及到的 aws 服务都是 Serverless 的,但是涉及的服务太多以后 troubleshooting 就会比较复杂。
基于以上问题,我们对该方案的实进行了改进和简化,具体如下:

具体流程如下:
生产者 Producers 生产的正常消息直接投递到 Kafka 的目标 topic,如果是延迟消息投递到 Kafka 的一个延迟消息的 Delay Message Topic 中。
Service 消费 Delay Message Topic 中的消息,如果该消息的延迟时间小于 15 分钟,直接投递到SQS(Delay Queue)中。如果消息的延迟时间大于 15 分钟,直接将消息写入到 Message Store 中。
Service 会定时扫描 Message Store 中的消息,如果发现延迟时间小于 15 分钟,则直接投递到 SQS(Delay Queue)中。
Service 会消费 SQS(Delay Queue)中的消息,并将该消息投递到目标 topic 中。
简化后的方案将 Consumer、Emitter 和 Scheduler 的逻辑都集中在 Service 这个服务中,Service 服务是集群部署的,这种方案所有的逻辑都在 Service 这个服务中,在 troubleshooting 时相对来说要方便一些。整体实现方案的大方向确定好以后,还需要细化以下几个问题:
1)消息如何存储
我们可以看到 Message Store的主要功能是存储延迟时间大于 15 分钟的延迟消息, 并供 Scheduler 进行查询,查询的时候是根据时间来查询的。支持 Serverless 方式存储的服务也比较多,经过调研最后选择 DynamoDB。
DynamoDB 中的 partition key 是延迟时间,sorted key 选择 message id,这样可以保证通过 partition key 和 sorted key 能够唯一定位到一条消息,不会出现冲突。同时,在查询的时候只需要根据 partition key 就可以查询出该时间片段内的所有消息,也不会出现热点或者 partition 不均匀的问题。
假设 partition key 为 1677400776(是 2023-02-26 16:39:35 的时间戳,精确到秒),则该 partition key 中对应的所有消息都是延迟时间从 2023-02-26 16:39:35 到 2023-02-26 16:39:36 之间的消息。因为每个消息都有唯一的 message id,所以将 sorted key 设置为 message id 就不会导致消息冲突的问题。Scheduler 在查询的时候只需要传入需要查询的时间戳就可以拉取该时间段内所有的消息,如果没有查询到,则表示该时间段内没有延迟消息。
同时,对于 DynamoDB 中的消息也设置了 TTL 用来自动删除数据的,设置的 TTL 时间比延迟时间大 24 小时,主要是方便 troubleshooting 的。当 DynamoDB 中的延迟消息被投递到 SQS 以后,会调用 API 去删除该消息。DynamoDB 中消息的数据结构还包括 topic、消息体等信息。
2)单点问题
单点问题主要是因为对于存储在 DynomaDB 中大于 15 分钟的延迟消息进行扫描的时候,接收到扫描通知的 Scheduler 出现了问题,则该时间段的消息没有被投递到 SQS中,从而导致消息丢失。现在 Scheduler 的功能都集成在 Service 服务中,而 Service 服务是集群部署,所以 Scheduler 不存在单点的问题。
但是需要解决另外一个问题:如何保证集群中只有一个 Scheduler 扫描 DynamoDB 中的数据,并且当 Scheduler 出现了问题以后,集群中其他 Scheduler 也可以继续接着执行?
为了解决这个问题:我们使用了 SQS 的 FIFO 队列。SQS 支持两种队列,一种是 Standard 对列,一种是 FIFO 队列。FIFO 队列可以严格保证消息的有序,同时支持消息的可见性,也就是说在一段时间内该消息只能有一个消费者可见,其他消费者无法访问。同时,SQS 的 FIFO 队列还支持去重的功能。基于 SQS 的 FIFI 队列的这些特性,解决单点问题就比较容易了。具体实现方案如下:
在 Service 服务中启动一个 Timer 定时向 SQS 的 FIFO 队列投递通知消息,一分钟投递一次。通知消息的消息体是当前时间的时间戳,精度到分钟。这样即使有 n 个 Timer 在同一分钟内向 SQS 的 FIFO 队列投递 n 次消息,也只会有一条消息被成功投递到 SQS 的 FIFO 队列中,n-1 条消息被 SQS 的 FIFO 队列的去重功能过滤掉了。
投递到 SQS 的 FIFO 队列中的可见性设置为 5分钟(可以配置)。可以保证在 5 分钟内只有一个 Scheduler 可以消费到通知消息,如果该 Scheduler 出现了故障,后续的其他 Scheduler 也可以接着继续消费。当 Scheduler 消费到通知消息时,会根据消息内容转换成时间戳,并在 DynamoDB 中查询这一时间戳范围内的所有消息,修改消息的延迟时间,投递到 SQS 的 Standard 队列中,最后删除 SQS 的 FIFO 队列中的这一条通知消息。
基于上面的方案,能够很好的解决单点问题。
3)消息丢失问题
因为 Timer 和 Schduler 都在 Service 服务中,都是集群问题,不存在单点问题。并且,SQS 的 FIFO 队列能够保证消息严格有序,所以不存在消息丢失的问题。唯一可能存在的问题是,因为消息量大积压导致的消息延迟过长。
4)如何查询延迟消息
Scheduler 查询的消息要满足该消息的延迟时间小于 15 分钟,所以在接收到通知消息并转换成对应的时间戳以后,查询当前时间戳 +14 分钟(延迟消息不能超过 15 分钟)的消息即可。
5)如何部署 Service 服务
对于 Service 服务,我们采用了 ECS+Fargate 的方式来部署。整个代码的部署都是通过 Terraform 脚本来创建 Code Pipeline、DynamoDB、SQS 和 ECS 等资源实现的,所有的资源都是通过代码来实现的,整个部署方案的设计全部都是基于 gitOps 的思想。
经过多以上方案的综合评估,最后我们选择基于 SQS 和定时调度策略的方案来实现延迟消息。
6.4 性能优化
以上方案在实践的过程中,做了很多优化,大致可以归纳成以下几点:
1)消息积压
由于需要处理的延迟消息会因为消费能力不足的情况导致消息积压的问题。优化这一问题主要从以下几个方面入手:
Delay Message Topic 的 partition 设置成 64 个。提高 Kafka 消费的消费能力可以通过增加 consumer 来实现,但是前提是要保证 partition 的数量大于等于 consumer 的数量。
降低 Service 的服务配置,增加 Service 服务的副本数。Service 集群消费 Delay Message Topic 中的消息,副本数越多,消费能力越强。
2)DynamoDB 中 WCU 和 RCU
DynamoDB 的费用有很大一部分是通过 WCU 和 RCU 来统计的。WCU 是指单位时间内消息写入的数量,RCU 是指单位时间内消息读取的数量。如果单位时间内写入消息的数量超过了 WCU 的限制会导致消息写入失败,同理也会导致读取消息失败。
如果将 WCU 和 RCU 都设置成峰值肯定不会导致读写失败的问题,但是会产生巨大的成本浪费。为此,我们将 WCU 和 RCU 设置成动态扩缩容的方式。在扩容期间如果产生失败,则进行重试。经过相关参数的优化,现在已经可以达到一个最佳现状。
3)ECS 扩缩容设置
ECS 中最小的运行单元是 task,对于每一个 task 要求扩容要快,缩容要缓慢。task 快速扩容遇到的最大的问题是,拉起 Service 的耗时比较长。对于 Service 服务我们采用 golang 来实现,扩一个 task 能够基本上可以在 8s 内完成。扩缩容是基于 CPU 的使用峰值来设置的,每次扩容会扩 4 个 task,每次所容会缩 1 个 task。
4)消息平滑处理
由于写入 Delay Message Topic 中的消息峰值可能会比较大,如果快速消费这些消息,会导致后续对 DynamoDB 的读写压力比较大。因此,在消费 Kafka 的 Delay Message Topic 中的消息时,会将控制每个 Service 消费消息的数量。尽管有多个 Service 会同时消费,但是对于单个 Service 来说,写入消息的数量较少,对 DynamoDB 来说,每一次的写入比较平稳,并非一次性写入大量的数据,从而写入失败的概率会小很多。
6.5 实践效果
目前已经在生产环境稳定运行了 6 个月,各项指标都比较健康,拉取了最近 4 周的数据。
1)延迟消息成功率

如上图所示,延迟误差在 2 秒以内的延迟消息成功率基本上是 100%。
2)延迟消息的数量

如果上图所示,延迟消息在 5 分钟内的峰值达到 15 万,也就是峰值每秒处理 500 个延迟消息。
3)DynamoDB 性能指标

从 PutItem ThrottledRequests 这个指标可以看出,通过 DynamoDB 写入消息没有发生写入失败的情况。从 QueryThrottledRequests 这个指标可以看出,通过 DynamoDB 查询消息也没有发生查询失败的情况。从 QueryReturnedItemCount 指标可以看出,延迟消息的峰值是 5 分钟内 3350 条,每秒低于 60 条。这是因为我们在 Service 中对写入消息进行了缓冲,从而降低了并发读写压力。
4)Kafka 消息积压
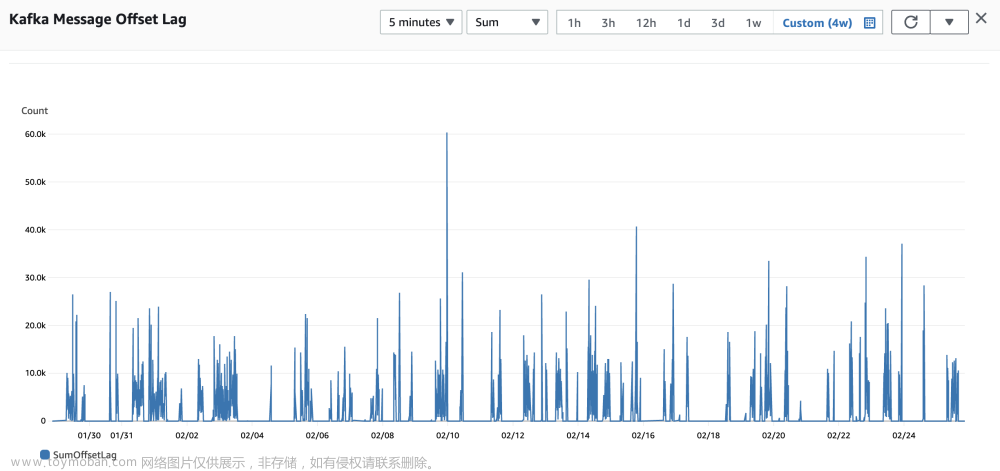
如上图所示,Kafka 在 5 分钟内消息积压的峰值是 6 万,积压的消息都能很快被消费掉。
5)Timer 性能指标

Timer 会每分钟向 SQS 的 FIFO 队列中投递一个消息,消息的数量与 Service 的副本数相同。从上图可以看出,5 分钟内最多投递了 300 个消息(因为 Service 的副本数最大为 64)。但是最后接收的消息是5分钟内仅仅接收了 5 个消息,也就是 1 分钟接收 1 条消息。
七、总结
由于该实现方案完全是基于 Serverless 的方式实现的,所以维护成本非常低。尽管开发起来有些复杂,但这是一次性的成本投入。从近几个月的数据来看,云上的使用成本大约每个月不超过 200 美元,误差延迟比较小,到目前为止整体运行起来比较稳定。
【推荐阅读】
携程中转交通方案拼接性能优化
携程 10 个有效降低客户端超时的方法
携程微服务体系下的服务治理之道和优化实践
上线效率提升 8 倍,携程门票活动直连平台实践
“携程技术”公众号文章来源:https://www.toymoban.com/news/detail-647865.html
分享,交流,成长文章来源地址https://www.toymoban.com/news/detail-647865.html
到了这里,关于干货 | 成本低误差小,携程基于 Kafka 的 Serverless 延迟队列的实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!