文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Kafka的消息流处理;
⚪ 掌握Kafka的索引机制;
⚪ 掌握Kafka的消息系统语义;
一、Kafka消息流处理
1. Producer 写入消息
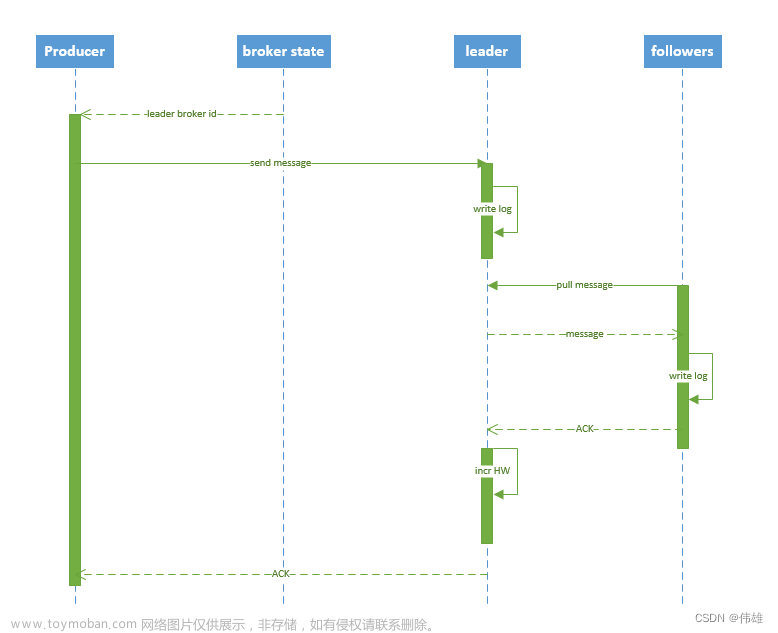
流程说明:
1. producer 要向Kafka生产消息,需要先通过 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 副本leader的位置信息。
2. producer 将消息发送给该 leader。
3. leader 收到消息后,将消息写入到分区目录下的本地 log 文件中。
4. followers 从 leader pull 同步消息,将消息写入到分区目录下的 log 中。如果同步成功(将消息写入log文件成功),则向 leader 返回 ACK(确认机制)。
细节补充:
Kafka引入了一个ISR机制(概念),在Follower和Leader数据同步的过程中,
比如:
①副本-Follower
②副本-Leader
③副本-Follower
在数据同步过程中,①②同步,③出故障没有跟上。
此时①②是同一组ISR成员,③不是。
如果后续Leader挂掉了,则Kafka会从Leader的ISR组中随机选择一个Follower成为Leader。
Kafka底层有一个同步超时的时间(10s),即一个Follower在超时时间内没有反馈ACK,则人为同步失败。
由写入流程可知ISR里面的所有replica都跟上了Leader,只有ISR里面的成员才能选为Leader。对于 f+1 个replica,一个partition可以在容忍 f 个replica失效的情况下保证消息步丢失。
比如:一个分区由5个副本,挂掉4个,剩下一个副本,依然可以工作。
注意:Kafka的选举不同于zookeeper,用的不是过半选举。
5. leader 收到所有 ISR 中的 replica 的 ACK 后,向 producer 发送 ACK。
2. kafka HA
1. 概述
同一个 partition 可能会有多个 replica(对应 server.properties 配置中的 default.replication.factor=N)。
没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。
引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据。
2. leader failover
当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader。在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息。
由写入流程可知 ISR 里面的所有 replica 都跟上了 leader,只有 ISR 里面的成员才能选为 leader。对于 f+1 个 replica,一个 partition 可以在容忍 f 个 replica 失效的情况下保证消息不丢失。
比如 一个分区 有5个副本,挂了4个,剩一个副本,依然可以工作。
注意:kafka的选举不同于zookeeper,用的不是过半选举。
3. 当所有 replica 都不工作时,有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。
2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。
kafka 0.8.* 使用第二种方式。此外, kafka 通过 Controller 来选举 leader。
二、Kafka索引机制
1. 概述
数据文件的分段与索引
Kafka解决查询效率的手段之一是将数据文件分段,可以配置每个数据文件的最大值,每段放在一个单独的数据文件里面,数据文件以该段中最小的offset命名。
每个log文件默认是1GB生成一个新的Log文件,比如新的log文件中第一条的消息的offset 16933,则此log文件的命名为:000000000000000016933.log,此外,每生成一个log文件,就会生成一个对应的索引(index)文件。这样在查找指定offset的Message的时候,用二分查找就可以定位到该Message在哪个段中。

我们发现Kafka的索引并不是为每条数据建立索引。这种索引称为稀疏索引。因为稀疏索引占用的空间小,所以可以完全将稀疏索引加载到内存中,避免从磁盘上读取索引文件数据,减少磁盘 I/O ,进一步提高性能。
Kafka的索引机制可以概括为:稀疏索引 + 加载内存 + 二分查找来实现的。
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引——Offset与position(Message在数据文件中的绝对位置)的对应关系。
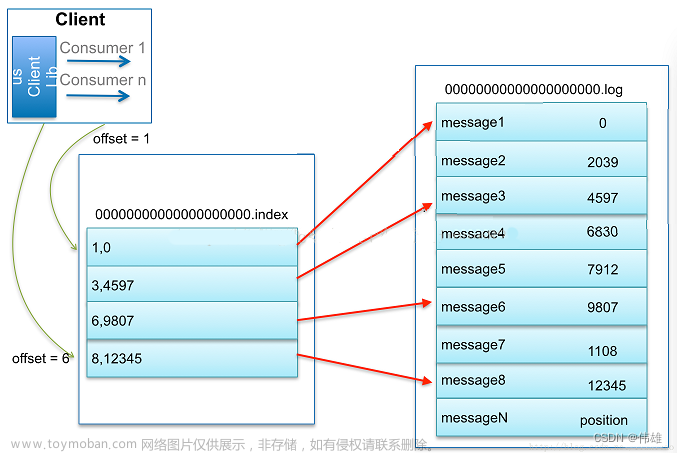
index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
索引文件被映射到内存中,所以查找的速度还是很快的。
三、Kafka的消息系统语义
1. 概述
在一个分布式发布订阅消息系统中,组成系统的计算机总会由于各自的故障而不能工作。在Kafka中,一个单独的broker,可能会在生产者发送消息到一个topic的时候宕机,或者出现网络故障,从而导致生产者发送消息失败。根据生产者如何处理这样的失败,产生了不同的语义。
消息系统语义(数据传输的可靠性保障),共有三种:
① at most once 至多一次。
② at least once 至少一次。
③ exactly once 精确一次。
1. 至多一次语义(At most once semantics):
如果生产者在ack超时或者返回错误的时候不重试发送消息,那么消息有可能最终并没有写入Kafka topic中,因此也就不会被消费者消费到。但是为了避免重复处理的可能性,我们接受有些消息可能被遗漏处理。
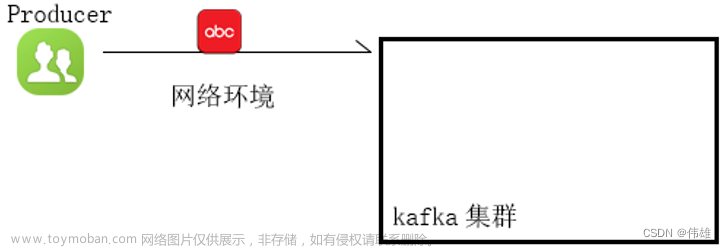
如上图所示,在发送数据时,可能由于各种故障或异常,导致没有收到数据,即产生了数据丢失。
对应的是at most once 至多一次语义,即同一条数据至多只发送一次,所以这一层语义可能造成数据传输的丢失,但不会造成数据的重复处理。这一层语义也可以人为是没有可靠性保障的委婉说法。
2. 至少一次语义(At least once semantics):
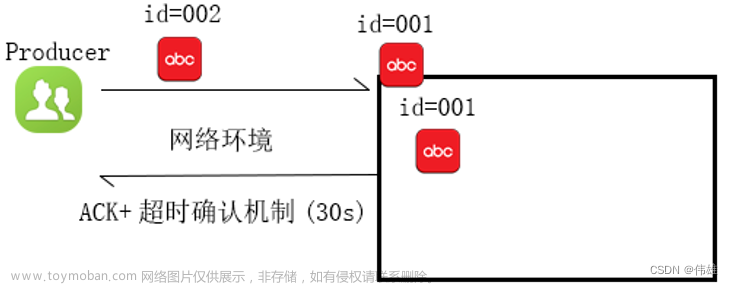
如果生产者收到了Kafka broker的确认(acknowledgement,ack),并且生产者的acks配置项设置为all(或-1),这就意味着消息已经被精确一次写入Kafka topic了。然而,如果生产者接收ack超时或者收到了错误,它就会认为消息没有写入Kafka topic而尝试重新发送消息。如果broker恰好在消息已经成功写入Kafka topic后,发送ack前,出了故障,生产者的重试机制就会导致这条消息被写入Kafka两次,从而导致同样的消息会被消费者消费不止一次。每个人都喜欢一个兴高采烈的给予者,但是这种方式会导致重复的工作和错误的结果。
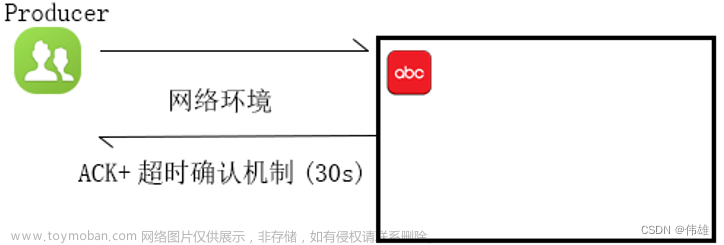
为了能够确保数据不丢失,我们可以引入ACK确认机制 + 超时时间。如果在指定的超时时间之内,没有收到ACK,则认为接收失败,则将数据重新发送。
上图对应的语义:at least once 至少一次。同一条数据至少发送一次,也可能发送多次,能够确保数据不丢失。但可能造成同一条数据的重复处理。(比如在返回ACK时超时了,有这种可能,在实际生产环境下概率时脚底的)。
3. 精确一次语义(Exactly once semantics):
即使生产者重试发送消息,也只会让消息被发送给消费者一次。精确一次语义是最令人满意的保证,但也是最难理解的。因为它需要消息系统本身和生产消息的应用程序还有消费消息的应用程序一起合作。比如,在成功消费一条消息后,你又把消费的offset重置到之前的某个offset位置,那么你将收到从那个offset到最新的offset之间的所有消息。这解释了为什么消息系统和客户端程序必须合作来保证精确一次语义。
要想实现精确一次语义,需要在at least once 至少一次语义的基础上来实现,即确保数据不丢失(ACK + 超时机制)。此外,为数据分配一个全局唯一的 id ,利用这个 id 可以实现幂等性操作(幂等性操作指的是:代码执行多次和执行一次的结果是一样的),从而避免同一条数据被重复处理。
即exactly once 精确一次:确保数据不丢失,且精确处理(不重复处理)。
综上,这三层语义,没有好坏之分,主要看具体的应用场景。
比如:
允许数据丢失但追求高性能,使用at least once
对数据精度要求非常高,一条不能丢并且结果严格正确,使用exactly once。很多框架默认是第二种(折中的),如何降低数据重复处理的可能性呢?可以适当调多超时时间,尤其是网络环境不好时。
在Kafka中,可以通过配置文件来进行设定。
在server.properties文件:
至多一次
acks=0
至少一次
acks=1 只接受副本Leader的ACK常用的
acks=2 接受副本Leader的ACK和一个Follower的ACK
acks=3 接受副本Leader的ACK和两个Follower的ACK
精确一次
acks=1
enable.idempotence=true文章来源:https://www.toymoban.com/news/detail-647902.html
2. 新版本Kafka的幂等性实现
一个幂等性的操作就是一种被执行多次造成的影响和只执行一次造成的影响一样的操作。现在生产者发送的操作是幂等的了。如果出现导致生产者重试的错误,同样的消息,仍由同样的生产者发送多次,将只被写到kafka broker的日志中一次。对于单个分区,幂等生产者不会因为生产者或broker故障而发送多条重复消息。想要开启这个特性,获得每个分区内的精确一次语义,也就是说没有重复,没有丢失,并且有序的语义,只需要设置producer配置中的”enable.idempotence=true”。文章来源地址https://www.toymoban.com/news/detail-647902.html
到了这里,关于大数据课程I3——Kafka的消息流与索引机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!