模型推理详细步骤
模型加载步骤
首先,模型加载总共分为三步,第一步加载网络结构,需要和你训时的network结构一样。
model = Model.FeedBack3(cfg, config_path=None, pretrained=True).to(device)
第二步,加载训练好的参数,实际上虽然我们一直说训练模型,实际上训练出来的就是一组参数,这个参数是一个字典类型,一般保存的名称为xxx.pt或者pth。里面存放的是模型每一层中的权重等数据。pytorch中对于加载参数使torch.load()
pretrained_dict = torch.load('outputmicrosoft-deberta-v3-base_fold3_best.pth')
第三步,将参数加载进模型里
model.load_state_dict(pretrained_dict['model_state_dict'], strict=True)
以上就是加载模型的所有步骤了
关于模型参数和字典对不上的问题
一般报错为:Missing key(s) in state_dict: xxxx
最近在做模型部署的时候发现了这个问题,并且之前也遇到过,由于急于求成就简单实在模型加载参数的时候用了strict=False这样的条件,这个条件会使模型直接忽略所有对不上的参数,本质上没有解决问题。今天在debug时对模型每一层的参数排查终于发现了问题所在。
首先开启debug模式,直接将断点打在模型加载的代码上:
首先查看model的结构有没有问题: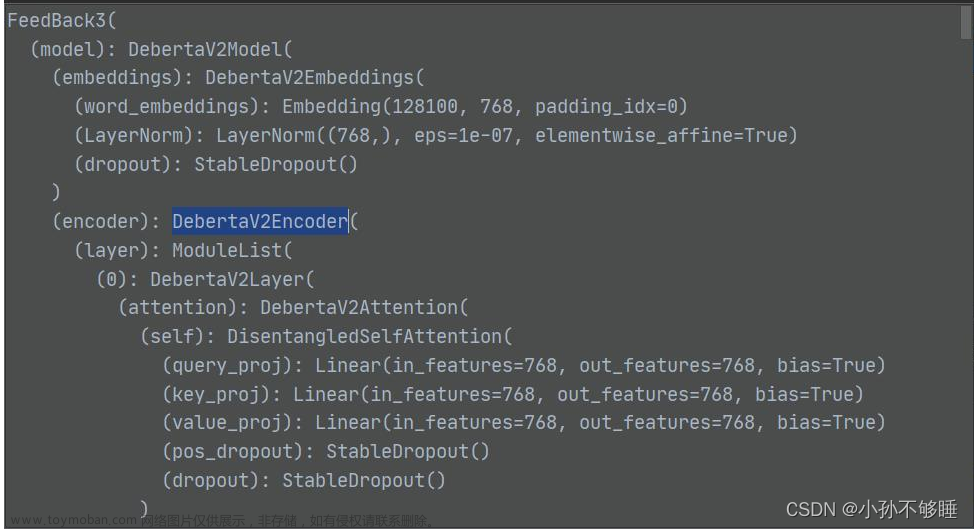
接下来进行下一步,执行到加载参数字典,同样查看你的参数字典(这里由于参数过多就不详细展示了):
那么要如何排查呢,具体步骤如下:
首先参数字典里都是以键值对和tensor型式存储的,那么我们只需要一一排查键值对和参数。比如首先是model建,那么只有你加载参数的时候只有加载里面的model建模型才能读到参数,实际上我就是错在这里了,因为我加载的是通常使用的‘model_state_dict’这个建,因为我训练部分是网上复制来的代码,没想到他把参数保存为model。
也就是我只需要把前面的
model.load_state_dict(pretrained_dict['model_state_dict'])
改成
model.load_state_dict(pretrained_dict['model'])
就行了。
那么如果你的问题不是这里,接下来改如何排查呢
接着看OrderedDict里,这里面是模型每一层的参数,对照方法如下: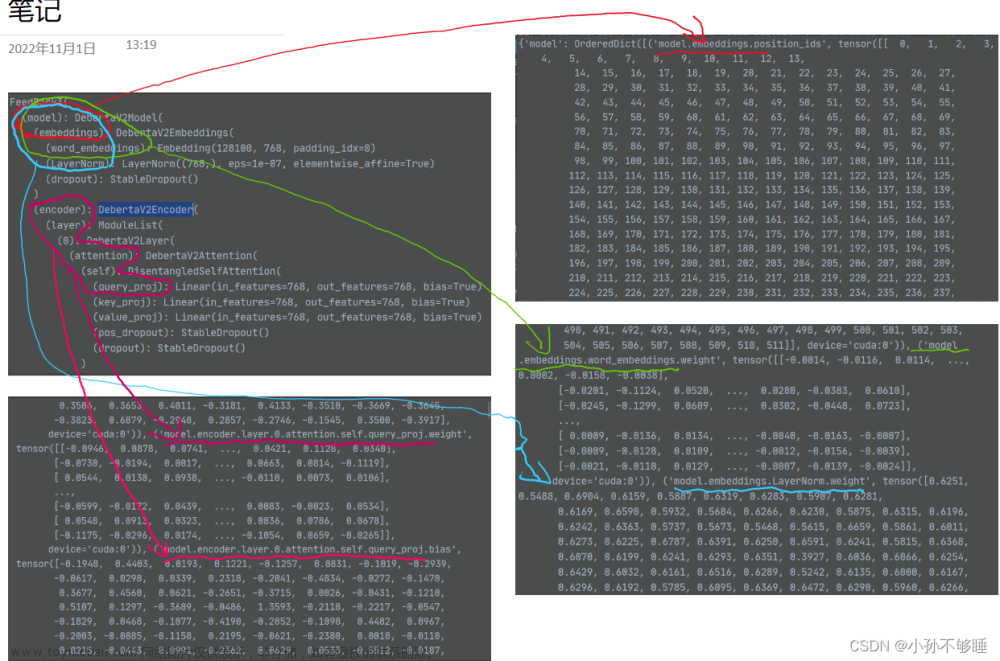
相当于网络结构中的每一层都会变为一个对应的tensor
(model)(embeddings)(LayerNorm)在参数中就会存为:(‘model.embdeddings.LayerNorm’, tensor([xxxxx])
这样就看懂了吧,如此对照每一层网络结构,只要你有耐心,就能找出来具体是那一层不对,不过大多情况下这种在网络中间层出现参数不对的情况很少,出现的原因也肯定是你推理部分加载的网络结构和训练时的网络结构不一致导致的。
顺便推荐一个能帮你排查模型参数的代码,他会输出具体有多少参数使用了和没使用:
def check_keys(model, pretrained_state_dict):
ckpt_keys = set(pretrained_state_dict.keys())
model_keys = set(model.state_dict().keys())
used_pretrained_keys = model_keys & ckpt_keys
unused_pretrained_keys = ckpt_keys - model_keys
missing_keys = model_keys - ckpt_keys
# filter 'num_batches_tracked'
missing_keys = [x for x in missing_keys
if not x.endswith('num_batches_tracked')]
if len(missing_keys) > 0:
print('[Warning] missing keys: {}'.format(missing_keys))
print('missing keys:{}'.format(len(missing_keys)))
if len(unused_pretrained_keys) > 0:
print('[Warning] unused_pretrained_keys: {}'.format(
unused_pretrained_keys))
print('unused checkpoint keys:{}'.format(
len(unused_pretrained_keys)))
print('used keys:{}'.format(len(used_pretrained_keys)))
assert len(used_pretrained_keys) > 0, \
'check_key load NONE from pretrained checkpoint'
return True
模型推理中的数据处理
首先模型推理中数据最终的处理格式要和训练时输入进网络中的格式一致,不过我们通常不再构造新的dataset和使用dataloader,而是直接针对input处理成我们需要的格式。
主要步骤为,读取数据,embedding,增加维度
读取的数据可以是本地存的,如果你是要将模型部署在web上那么数据就是从客户端传来的json格式的数据,因此通常需要先将真正的input取出来。
接下来是向量化,这里步骤和训练中的一致,比如训练中使用了resize([800,800])和toTensor,那么推理中也要这样设置。
由于我是NLP任务,那么处理的步骤为
inputs = cfg.tokenizer.encode_plus(
input,
return_tensors=None,
add_special_tokens=True,
max_length=cfg.max_lenth,
pad_to_max_length=True,
truncation=True
)
for k, v in inputs.items():
inputs[k] = torch.tensor(v, dtype=torch.long)
至此,再次输出此时的tensor和训练时输入进模型的tensor相比,只是少了一个维度,这个维度通常可以理解我们在训练的时候是有batch_size的,而推理时没有,因此要手动升维,升维度的函数有很多,通常使用unsequeeze(1)或者expand:文章来源:https://www.toymoban.com/news/detail-647935.html
for k, v in inputs.items():
s = v.shape
inputs[k] = v.expand(1,-1).to(device) #-1自动计算
这样处理完数据格式就和训练时完全一致了,说白了还是要先debug一下训练时的数据,看看到底输进去的是什么格式,然后在推理部分照着一点一点改。文章来源地址https://www.toymoban.com/news/detail-647935.html
到了这里,关于模型推理详细步骤以及如何排查模型和参数字典对不上的问题:Missing key(s) in state_dict: xxxx的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!