前言
之前7月中旬,我曾在微博上说准备做“20个LLM大型项目的源码解读”

针对这个事,目前的最新情况是
- 已经做了的:LLaMA、Alpaca、ChatGLM-6B、deepspeedchat、transformer、langchain、langchain-chatglm知识库
- 准备做的:chatpaper、deepspeed、Megatron-LM
- 再往后则:BERT、GPT、pytorch、chatdoctor、baichuan、BLOOM/BELLE、Chinese LLaMA、PEFT BLIP2 llama.cpp
总之,够未来半年忙了。为加快这个事情的进度,本文
- 前两个部分,解读两个关于学术论文的GPT(我把这两个项目的结构做了拆解/解析,且基本把原有代码的每一行都补上了注释,如果大家对任何一行代码有疑问,可以随时在本文评论区留言,我会及时做补充说明)
第一部分 解读chatpaper:https://github.com/kaixindelele/ChatPaper,1.4和1.5节和我司杜老师共创
第二部分 解读gpt_academic:https://github.com/binary-husky/gpt_academic - 第三部分,则展示下我司正在做的论文审稿GPT的部分工作 (由于我司每周都有好几个或为申博、或为评职称、或为硕/博毕业而报名论文1V1发表辅导的,比如中文期刊、EI会议、ei期刊/SCI等等,所以对这个方向一直都是高度关注),侧重阐述如何从零实现一个论文审稿GPT,该部分和我司黄老师共创
第一部分 ChatPaper:论文对话、总结、翻译
ChatPaper的自身定位是全流程加速科研:论文总结+专业级翻译+润色+审稿+审稿回复,因为论文更多是PDF的格式,故针对PDF的对话、总结、翻译,便不可避免的涉及到PDF的解析
1.1 论文审稿:ChatPaper/ChatReviewerAndResponse
1.1.1 对PDF的解析:ChatReviewerAndResponse/get_paper.py
// 待更
1.1.2 论文审查:ChatReviewerAndResponse/chat_reviewer.py
使用OpenAI的GPT模型进行论文审查的脚本。它首先定义了一个Reviewer类来处理审查工作,然后在if __name__ == '__main__':语句下使用argparse处理命令行参数,并调用chat_reviewer_main函数来开始审查过程
- 导入模块:比如jieba、tenacity等
- 命名元组定义:用于保存与论文审稿相关的参数
ReviewerParams = namedtuple( "ReviewerParams", [ "paper_path", "file_format", "research_fields", "language" ], ) - 判断文本中是否包含中文:
def contains_chinese(text): for ch in text: if u'\u4e00' <= ch <= u'\u9fff': return True return False - 插入句子到文本
主要功能是在给定文本的每隔一定数量的单词或中文字符后插入一个指定的句子。如果文本行包含中文字符,则使用jieba分词工具来切分中文,否则使用空格来切分:def insert_sentence(text, sentence, interval): # 将输入文本按换行符分割成行 lines = text.split('\n') # 初始化一个新的行列表 new_lines = [] # 遍历每一行 for line in lines: # 检查行中是否包含中文字符 if contains_chinese(line): # 如果是中文,使用jieba分词工具进行分词 words = list(jieba.cut(line)) # 定义分隔符为空字符(对于中文分词) separator = '' else: # 如果不包含中文,按空格分割行 words = line.split() # 定义分隔符为空格(对于英文或其他非中文语言) separator = ' ' # 初始化一个新的单词列表 new_words = [] # 初始化一个计数器 count = 0 # 遍历当前行的每一个单词 for word in words: # 将当前单词添加到新的单词列表 new_words.append(word) # 计数器增加 count += 1 # 检查是否达到了插入句子的间隔 if count % interval == 0: # 在达到指定间隔时,将要插入的句子添加到新的单词列表 new_words.append(sentence) # 将新的单词列表连接起来,并添加到新的行列表 new_lines.append(separator.join(new_words)) # 将新的行列表连接起来,返回结果 return '\n'.join(new_lines) - 论文审稿类:定义了一个Reviewer类,包含以下功能:
第一阶段审稿:先是基于论文标题和摘要,选择要审稿的部分
然后分别实现两个函数# 定义Reviewer类 class Reviewer: # 初始化方法,设置属性 def __init__(self, args=None): if args.language == 'en': self.language = 'English' elif args.language == 'zh': self.language = 'Chinese' else: self.language = 'Chinese' # 创建一个ConfigParser对象 self.config = configparser.ConfigParser() # 读取配置文件 self.config.read('apikey.ini') # 获取某个键对应的值 self.chat_api_list = self.config.get('OpenAI', 'OPENAI_API_KEYS')[1:-1].replace('\'', '').split(',') self.chat_api_list = [api.strip() for api in self.chat_api_list if len(api) > 5] self.cur_api = 0 self.file_format = args.file_format self.max_token_num = 4096 self.encoding = tiktoken.get_encoding("gpt2") def validateTitle(self, title): # 修正论文的路径格式 rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/ \ : * ? " < > |' new_title = re.sub(rstr, "_", title) # 替换为下划线 return new_title
一个stage_1,主要功能是为了与GPT-3模型进行对话,获取模型对于文章的两个最关键部分的选择意见
一个chat_review,主要功能是调用GPT-3模型进行论文审稿,对输入的文章文本进行审查,并按照预定格式生成审稿意见def stage_1(self, paper): # 初始化一个空列表,用于存储生成的HTML内容 htmls = [] # 初始化一个空字符串,用于存储文章的标题和摘要 text = '' # 添加文章的标题 text += 'Title: ' + paper.title + '. ' # 添加文章的摘要 text += 'Abstract: ' + paper.section_texts['Abstract'] # 计算文本的token数量 text_token = len(self.encoding.encode(text)) # 判断token数量是否超过最大token限制的一半减去800 if text_token > self.max_token_num/2 - 800: input_text_index = int(len(text)*((self.max_token_num/2)-800)/text_token) # 如果超出,则截取文本以满足长度要求 text = text[:input_text_index] # 设置OpenAI API的密钥 openai.api_key = self.chat_api_list[self.cur_api] # 更新当前使用的API索引 self.cur_api += 1 # 如果当前API索引超过API列表的长度,则重置为0 self.cur_api = 0 if self.cur_api >= len(self.chat_api_list)-1 else self.cur_api # 创建与GPT-3的对话消息 messages = [ {"role": "system", "content": f"You are a professional reviewer in the field of {args.research_fields}. " f"I will give you a paper. You need to review this paper and discuss the novelty and originality of ideas, correctness, clarity, the significance of results, potential impact and quality of the presentation. " f"Due to the length limitations, I am only allowed to provide you the abstract, introduction, conclusion and at most two sections of this paper." f"Now I will give you the title and abstract and the headings of potential sections. " f"You need to reply at most two headings. Then I will further provide you the full information, includes aforementioned sections and at most two sections you called for.\n\n" f"Title: {paper.title}\n\n" f"Abstract: {paper.section_texts['Abstract']}\n\n" f"Potential Sections: {paper.section_names[2:-1]}\n\n" f"Follow the following format to output your choice of sections:" f"{{chosen section 1}}, {{chosen section 2}}\n\n"}, {"role": "user", "content": text}, ] # 调用OpenAI API与GPT-3进行对话 response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages, ) # 初始化一个空字符串,用于存储模型的回复 result = '' # 遍历模型的回复,将其添加到结果字符串中 for choice in response.choices: result += choice.message.content # 打印模型的回复 print(result) # 返回模型的回复,将其分割为多个部分 return result.split(',')
使用ChatGPT进行审稿,且有tenacity重试机制和更多的功能,其中review_by_chatgpt 调用了上面所示的两个函数,一个stage_1,一个chat_reviewdef chat_review(self, text): # 设置OpenAI API的密钥 openai.api_key = self.chat_api_list[self.cur_api] # 更新当前使用的API密钥索引 self.cur_api += 1 # 如果当前API密钥索引超过API密钥列表的长度,则将其重置为0 self.cur_api = 0 if self.cur_api >= len(self.chat_api_list)-1 else self.cur_api # 定义用于审稿提示的token数量 review_prompt_token = 1000 # 计算输入文本的token数量 text_token = len(self.encoding.encode(text)) # 计算输入文本的截取位置 input_text_index = int(len(text)*(self.max_token_num-review_prompt_token)/text_token) # 截取文本并添加前缀 input_text = "This is the paper for your review:" + text[:input_text_index] # 从'ReviewFormat.txt'文件中读取审稿格式 with open('ReviewFormat.txt', 'r') as file: review_format = file.read() # 创建与GPT-3的对话消息 messages=[ {"role": "system", "content": "You are a professional reviewer in the field of "+args.research_fields+". Now I will give you a paper. You need to give a complete review opinion according to the following requirements and format:"+ review_format +" Please answer in {}.".format(self.language)}, {"role": "user", "content": input_text}, ] # 调用OpenAI API与GPT-3进行对话 response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages, ) # 初始化一个空字符串,用于存储模型的回复 result = '' # 遍历模型的回复,将其添加到结果字符串中 for choice in response.choices: result += choice.message.content # 在结果中插入特定的句子,警告不允许复制 result = insert_sentence(result, '**Generated by ChatGPT, no copying allowed!**', 15) # 追加伦理声明 result += "\n\n⚠伦理声明/Ethics statement:\n--禁止直接复制生成的评论用于任何论文审稿工作!\n--Direct copying of generated comments for any paper review work is prohibited!" # 打印分隔符和结果 print("********"*10) print(result) print("********"*10) # 打印相关的token使用信息和响应时间 print("prompt_token_used:", response.usage.prompt_tokens) print("completion_token_used:", response.usage.completion_tokens) print("total_token_used:", response.usage.total_tokens) print("response_time:", response.response_ms/1000.0, 's') # 返回模型生成的审稿意见 return resultdef review_by_chatgpt(self, paper_list): # 创建一个空列表用于存储每篇文章审稿后的HTML格式内容 htmls = [] # 遍历paper_list中的每一篇文章 for paper_index, paper in enumerate(paper_list): # 使用第一阶段审稿方法选择文章的关键部分 sections_of_interest = self.stage_1(paper) # 初始化一个空字符串用于提取文章的主要部分 text = '' # 添加文章的标题 text += 'Title:' + paper.title + '. ' # 添加文章的摘要 text += 'Abstract: ' + paper.section_texts['Abstract'] # 查找并添加“Introduction”部分 intro_title = next((item for item in paper.section_names if 'ntroduction' in item.lower()), None) if intro_title is not None: text += 'Introduction: ' + paper.section_texts[intro_title] # 同样地,查找并添加“Conclusion”部分 conclusion_title = next((item for item in paper.section_names if 'onclusion' in item), None) if conclusion_title is not None: text += 'Conclusion: ' + paper.section_texts[conclusion_title] # 遍历sections_of_interest,添加其他感兴趣的部分 for heading in sections_of_interest: if heading in paper.section_names: text += heading + ': ' + paper.section_texts[heading] # 使用ChatGPT进行审稿,并得到审稿内容 chat_review_text = self.chat_review(text=text) # 将审稿的文章编号和内容添加到htmls列表中 htmls.append('## Paper:' + str(paper_index+1)) htmls.append('\n\n\n') htmls.append(chat_review_text) # 获取当前日期和时间,并转换为字符串格式 date_str = str(datetime.datetime.now())[:13].replace(' ', '-') try: # 创建输出文件夹 export_path = os.path.join('./', 'output_file') os.makedirs(export_path) except: # 如果文件夹已存在,则不执行任何操作 pass # 如果是第一篇文章,则写模式为'w',否则为'a' mode = 'w' if paper_index == 0 else 'a' # 根据文章标题和日期生成文件名 file_name = os.path.join(export_path, date_str+'-'+self.validateTitle(paper.title)+"."+self.file_format) # 将审稿内容导出为Markdown格式并保存 self.export_to_markdown("\n".join(htmls), file_name=file_name, mode=mode) # 清空htmls列表,为下一篇文章做准备 htmls = [] - 主程序部分:
定义了一个chat_reviewer_main 函数,该函数创建了一个Reviewer对象,并对指定路径中的PDF文件进行审稿
主程序中定义了命令行参数解析,并调用了chat_reviewer_main 函数def chat_reviewer_main(args): reviewer1 = Reviewer(args=args) # 开始判断是路径还是文件: paper_list = [] if args.paper_path.endswith(".pdf"): paper_list.append(Paper(path=args.paper_path)) else: for root, dirs, files in os.walk(args.paper_path): print("root:", root, "dirs:", dirs, 'files:', files) #当前目录路径 for filename in files: # 如果找到PDF文件,则将其复制到目标文件夹中 if filename.endswith(".pdf"): paper_list.append(Paper(path=os.path.join(root, filename))) print("------------------paper_num: {}------------------".format(len(paper_list))) [print(paper_index, paper_name.path.split('\\')[-1]) for paper_index, paper_name in enumerate(paper_list)] reviewer1.review_by_chatgpt(paper_list=paper_list)
在主程序中增加了审稿时间的计算功能if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("--paper_path", type=str, default='', help="path of papers") parser.add_argument("--file_format", type=str, default='txt', help="output file format") parser.add_argument("--research_fields", type=str, default='computer science, artificial intelligence and reinforcement learning', help="the research fields of paper") parser.add_argument("--language", type=str, default='en', help="output lauguage, en or zh") reviewer_args = ReviewerParams(**vars(parser.parse_args())) start_time = time.time() chat_reviewer_main(args=reviewer_args) print("review time:", time.time() - start_time)
当然,这个项目的论文审稿部分更多是用的ChatGPT的API审稿,我司在API的基础上进一步做了微调的工作,比如如何通过论文审阅语料微调出一个论文审稿GPT(甚至通过10万量级的paper+review语料微调/训练),详见本文的第三部分或我司的「大模型项目开发线下营」
1.2 PDF解析:ChatPaper/scipdf_parser-master/
通过这个项目文件:ChatPaper/scipdf_parser-master/scipdf/pdf/parse_pdf.py可以看到以下内容
1.2.1 必要的库、常量、PDF路径
- 导入必要的库
re: 正则表达式库,用于匹配和处理字符串
os 和 os.path: 操作文件和路径的库
glob: 搜索文件的库
urllib: 用于处理和获取 URL
subprocess: 执行外部命令和程序的库
requests: 用于发送 HTTP 请求的库
BeautifulSoup 和 NavigableString: 从 bs4 导入,用于解析和操作 XML/HTML 内容
tqdm 和 tqdm_notebook: 提供进度条功能 - 定义常量
GROBID_URL: GROBID 是一个开源软件,可以从 PDF 文件中提取和解析学术出版物的结构化信息
PDF_FIGURES_JAR_PATH: 这是指向某个 jar 文件的路径,但这段代码中并没有用到这个常量 - 函数 list_pdf_paths: 返回给定文件夹中所有 PDF 文件的路径
- 函数 validate_url: 通过正则表达式验证给定的路径是否为有效的 URL
def validate_url(path: str): """ 验证给定的``path``是否为URL """ # 定义正则表达式以匹配URL # 下面的正则表达式主要匹配了以下几部分: # 1. http:// 或 https:// 开头 # 2. 域名 (例如:example.com) # 3. localhost (本地主机) # 4. IP地址 (例如:192.168.1.1) # 5. 可选的端口号 (例如::80) # 6. 路径或者查询字符串 regex = re.compile( r"^(?:http|ftp)s?://" # http:// or https:// 开头 # 域名部分 r"(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}\.?)|" r"localhost|" # localhost 部分 r"\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})" # IP地址部分 r"(?::\d+)?" # 可选的端口号部分 r"(?:/?|[/?]\S+)$", # 路径或查询字符串部分 re.IGNORECASE, # 忽略大小写 ) # 使用上述正则表达式匹配给定的path,如果匹配成功则返回True,否则返回False return re.match(regex, path) is not None
1.2.2 parse_pdf:对PDF的解析
这是代码中的核心功能,用 GROBID 服务从 PDF 文档中解析 XML 或 BeautifulSoup 格式的信息
如果 fulltext 参数为 True,则解析整篇文章;否则,只解析标题
可以从本地或云端的 GROBID 服务中获取数据
def parse_pdf(
pdf_path: str,
fulltext: bool = True,
soup: bool = False,
return_coordinates: bool = True,
grobid_url: str = GROBID_URL,
):
"""
使用GROBID工具将PDF解析为XML或BeautifulSoup
可以查看http://grobid.readthedocs.io/en/latest/Install-Grobid/了解如何本地运行GROBID
加载GROBID zip文件后,可以使用以下方法运行GROBID
>> ./gradlew run
参数
==========
pdf_path: str 或 bytes,出版物、文章的路径、URL或PDF的字节字符串
fulltext: bool, 解析选项,如果为True,解析文章的全部文本
如果为False,只解析头部
grobid_url: str, GROBID解析器的url,默认为'http://localhost:8070'
可以更改为"https://cloud.science-miner.com/grobid/"使用云服务
soup: bool, 如果为True,返回文章的BeautifulSoup
输出
======
parsed_article: 如果soup为False,则返回文本格式的解析后的XML,
否则返回XML的BeautifulSoup
示例
=======
>> parsed_article = parse_pdf(pdf_path, fulltext=True, soup=True)
"""
# GROBID的URL
if fulltext:
url = "%s/api/processFulltextDocument" % grobid_url # 完整文本处理URL
else:
url = "%s/api/processHeaderDocument" % grobid_url # 仅处理头部的URL
files = []
if return_coordinates: # 如果需要返回坐标
files += [
("teiCoordinates", (None, "persName")),
("teiCoordinates", (None, "figure")),
("teiCoordinates", (None, "ref")),
("teiCoordinates", (None, "formula")),
("teiCoordinates", (None, "biblStruct")),
]
if isinstance(pdf_path, str): # 如果pdf_path是字符串
if validate_url(pdf_path) and op.splitext(pdf_path)[-1].lower() != ".pdf":
print("输入的URL必须以``.pdf``结尾")
parsed_article = None
elif validate_url(pdf_path) and op.splitext(pdf_path)[-1] == ".pdf":
page = urllib.request.urlopen(pdf_path).read() # 从URL下载PDF
parsed_article = requests.post(url, files={"input": page}).text # 通过GROBID处理下载的PDF
elif op.exists(pdf_path): # 如果pdf_path是文件路径
parsed_article = requests.post(
url, files={"input": open(pdf_path, "rb")}
).text # 通过GROBID处理文件
else:
parsed_article = None
elif isinstance(pdf_path, bytes): # 如果pdf_path是字节
# 假设传入的是字节字符串
parsed_article = requests.post(url, files={"input": pdf_path}).text # 通过GROBID处理字节
else:
parsed_article = None
if soup and parsed_article is not None: # 如果需要返回BeautifulSoup对象
parsed_article = BeautifulSoup(parsed_article, "lxml")
return parsed_article1.2.3 提取作者信息/parse_authors、出版日期/parse_date、摘要/parse_abstract、段落/parse_sections
- 函数parse_authors从 BeautifulSoup 文章对象中提取作者信息
def parse_authors(article): """ Parse authors from a given BeautifulSoup of an article """ # 从文章的 BeautifulSoup 对象中查找包含作者信息的 "sourcedesc" 标签,然后找到其中所有的 "persname" 标签 author_names = article.find("sourcedesc").findAll("persname") # 创建一个空列表,用于保存解析的作者名字 authors = [] # 遍历每个作者标签 for author in author_names: # 查找作者的名字,并进行处理,如果不存在则返回空字符串 firstname = author.find("forename", {"type": "first"}) firstname = firstname.text.strip() if firstname is not None else "" # 查找作者的中间名,并进行处理,如果不存在则返回空字符串 middlename = author.find("forename", {"type": "middle"}) middlename = middlename.text.strip() if middlename is not None else "" # 查找作者的姓氏,并进行处理,如果不存在则返回空字符串 lastname = author.find("surname") lastname = lastname.text.strip() if lastname is not None else "" # 判断中间名是否存在,然后将名、中间名和姓组合在一起 if middlename is not "": authors.append(firstname + " " + middlename + " " + lastname) else: authors.append(firstname + " " + lastname) # 使用"; "连接所有的作者名,生成一个字符串 authors = "; ".join(authors) # 返回最终的作者名字符串 return authors - 下面这个parse_date函数是提取初版日期,从 BeautifulSoup 文章对象中提取出版日期
def parse_date(article): """ Parse date from a given BeautifulSoup of an article """ # 从文章的 BeautifulSoup 对象中查找包含出版日期信息的 "publicationstmt" 标签 pub_date = article.find("publicationstmt") # 在 "publicationstmt" 标签下查找 "date" 标签 year = pub_date.find("date") # 尝试获取 "date" 标签的 "when" 属性,如果标签不存在则返回空字符串 year = year.attrs.get("when") if year is not None else "" # 返回解析出的年份 return year - 而parse_abstract这个函数则是提取摘要,即从 BeautifulSoup 文章对象中提取摘要
def parse_abstract(article): """ Parse abstract from a given BeautifulSoup of an article """ # 从文章的 BeautifulSoup 对象中查找 "abstract" 标签 div = article.find("abstract") # 初始化摘要字符串为空 abstract = "" # 遍历 "abstract" 标签下的所有直接子节点 for p in list(div.children): # 如果子节点不是纯文本(NavigableString)且子节点的子元素数量大于0 if not isinstance(p, NavigableString) and len(list(p)) > 0: # 将子节点下的所有非纯文本子元素的文本内容加入摘要字符串 abstract += " ".join( [elem.text for elem in p if not isinstance(elem, NavigableString)] ) # 返回解析出的摘要 return abstract - 而parse_sections则是提取段落,从 BeautifulSoup 文章对象中提取文章的各个部分或段落,且它还计算每个部分中的引用数量
def parse_sections(article, as_list: bool = False): """ 从给定的BeautifulSoup文章中解析章节列表 参数 ========== as_list: bool, 如果为True,则将输出文本作为段落列表, 而不是将其连接成一个单一的文本 """ # 找到文章中的"text"部分 article_text = article.find("text") # 获取所有带有特定属性的"div"标签 divs = article_text.find_all("div", attrs={"xmlns": "http://www.tei-c.org/ns/1.0"}) sections = [] # 初始化章节列表 for div in divs: div_list = list(div.children) if len(div_list) == 0: heading = "" text = "" elif len(div_list) == 1: # 如果只有一个子元素 if isinstance(div_list[0], NavigableString): heading = str(div_list[0]) text = "" else: heading = "" text = div_list[0].text else: text = [] heading = div_list[0] if isinstance(heading, NavigableString): heading = str(heading) p_all = list(div.children)[1:] else: heading = "" p_all = list(div.children) for p in p_all: if p is not None: try: text.append(p.text) # 尝试添加文本 except: pass if not as_list: text = "\n".join(text) # 如果标题或文本不为空 if heading is not "" or text is not "": # 计算参考文献数量 ref_dict = calculate_number_of_references(div) sections.append( { "heading": heading, "text": text, "n_publication_ref": ref_dict["n_publication_ref"], "n_figure_ref": ref_dict["n_figure_ref"], } ) return sections
1.2.4 计算引用与解析文献引用/parse_references(article)
- calculate_number_of_references:计算给定部分中的引用数量
def calculate_number_of_references(div): """ 对于给定的章节,计算章节中的参考文献数量 """ # 计算给定章节中的文献引用数量 n_publication_ref = len( # 列表推导式查找所有type属性为"bibr"的"ref"标签 [ref for ref in div.find_all("ref") if ref.attrs.get("type") == "bibr"] ) # 计算给定章节中的图形引用数量 n_figure_ref = len( # 列表推导式查找所有type属性为"figure"的"ref"标签 [ref for ref in div.find_all("ref") if ref.attrs.get("type") == "figure"] ) # 返回一个字典,包含文献引用数量和图形引用数量 return {"n_publication_ref": n_publication_ref, "n_figure_ref": n_figure_ref} - parse_references(article):解析文献引用
功能:从给定的BeautifulSoup对象中解析文献引用列表
主要步骤:
寻找包含引用的部分
对于每个引用,提取文章标题、期刊、发布日期和作者信息
返回包含所有引用信息的列表def parse_references(article): """ 从给定的BeautifulSoup文章中解析引用列表 """ reference_list = [] # 初始化引用列表 # 在文章中查找文本部分中的引用部分 references = article.find("text").find("div", attrs={"type": "references"}) # 如果存在引用,则查找所有的"biblstruct"标签,否则返回空列表 references = references.find_all("biblstruct") if references is not None else [] reference_list = [] # 再次初始化引用列表 for reference in references: # 尝试查找引用的文章标题 title = reference.find("title", attrs={"level": "a"}) if title is None: title = reference.find("title", attrs={"level": "m"}) title = title.text if title is not None else "" # 尝试查找引用的期刊名 journal = reference.find("title", attrs={"level": "j"}) journal = journal.text if journal is not None else "" if journal is "": journal = reference.find("publisher") journal = journal.text if journal is not None else "" # 查找引用的出版年份 year = reference.find("date") year = year.attrs.get("when") if year is not None else "" authors = [] # 初始化作者列表 # 遍历引用中的所有作者 for author in reference.find_all("author"): firstname = author.find("forename", {"type": "first"}) firstname = firstname.text.strip() if firstname is not None else "" middlename = author.find("forename", {"type": "middle"}) middlename = middlename.text.strip() if middlename is not None else "" lastname = author.find("surname") lastname = lastname.text.strip() if lastname is not None else "" # 根据是否有中间名来组合作者的全名 if middlename is not "": authors.append(firstname + " " + middlename + " " + lastname) else: authors.append(firstname + " " + lastname) authors = "; ".join(authors) # 将所有作者连接为一个字符串 # 将标题、期刊、年份和作者添加到引用列表中 reference_list.append( {"title": title, "journal": journal, "year": year, "authors": authors} ) return reference_list # 返回引用列表
1.2.5 解析图形和表格、公式
-
parse_figure_caption(article)
功能:从给定的BeautifulSoup对象中解析图形和表格
主要步骤:
搜索所有图形
对于每个图形或表格,提取标签、类型、ID、标题和数据
返回包含所有图形/表格信息的列表def parse_figure_caption(article): """ 从给定的BeautifulSoup文章中解析图表列表 """ figures_list = [] # 初始化图表列表 # 在文章中查找所有的"figure"标签 figures = article.find_all("figure") for figure in figures: # 获取图标的类型(可能是图或表)和ID figure_type = figure.attrs.get("type") or "" figure_id = figure.attrs.get("xml:id") or "" # 获取图标的标签(如"图1") label = figure.find("label").text if figure_type == "table": # 如果图形类型为表,则获取表的标题和数据 caption = figure.find("figdesc").text data = figure.table.text else: # 否则,只获取图形的标题,并将数据设置为空字符串 caption = figure.text data = "" # 将标签、类型、ID、标题和数据添加到图形列表中 figures_list.append( { "figure_label": label, "figure_type": figure_type, "figure_id": figure_id, "figure_caption": caption, "figure_data": data, } ) return figures_list # 返回图表列表
-
parse_figures(...):
功能:使用pdffigures2工具从给定的科学PDF中解析图形
主要步骤:
检查输出文件夹是否存在,如果不存在则创建它
在输出文件夹中创建子文件夹来保存数据和图形
使用Java运行pdffigures2工具解析图形
打印完成消息def parse_figures( pdf_folder: str, jar_path: str = PDF_FIGURES_JAR_PATH, resolution: int = 300, output_folder: str = "figures", ): """ 使用pdffigures2从给定的科学PDF中提取图形。 参数 ========== pdf_folder: str, 包含PDF文件的文件夹的路径。一个文件夹必须只包含PDF文件。 jar_path: str, pdffigures2-assembly-0.0.12-SNAPSHOT.jar文件的默认路径。 resolution: int, 输出图形的分辨率。 output_folder: str, 我们希望保存解析数据(与图形相关)和图形的文件夹的路径。 输出 ====== folder: 在output_folder/data和output_folder/figures中创建文件夹,分别包含解析数据和图形。 """ # 检查output_folder是否存在,如果不存在,则创建它。 if not op.isdir(output_folder): os.makedirs(output_folder) # 在output_folder内创建“data”和“figures”子文件夹。 data_path = op.join(output_folder, "data") figure_path = op.join(output_folder, "figures") if not op.exists(data_path): os.makedirs(data_path) if not op.exists(figure_path): os.makedirs(figure_path) # 如果data和figures文件夹存在,则执行pdffigures2命令。 if op.isdir(data_path) and op.isdir(figure_path): args = [ "java", "-jar", jar_path, pdf_folder, "-i", str(resolution), "-d", op.join(op.abspath(data_path), ""), "-m", op.join(op.abspath(figure_path), ""), # end path with "/" ] _ = subprocess.run( args, stdout=subprocess.PIPE, stderr=subprocess.PIPE, timeout=20 ) print("完成从PDFs中提取图形!") else: print( "您可能需要检查output文件夹路径中的``data``和``figures``。" ) - parse_formulas(article):解析公式
功能:从给定的BeautifulSoup对象中解析公式
主要步骤:
搜索所有公式
提取公式的ID、文本和坐标
返回包含所有公式信息的列表def parse_formulas(article): """ 从给定的BeautifulSoup文章中解析公式列表 """ formulas_list = [] # 初始化公式列表 # 在文章中查找所有的"formula"标签 formulas = article.find_all("formula") for formula in formulas: # 获取公式的ID formula_id = formula.attrs["xml:id"] or "" # 获取公式的文本内容 formula_text = formula.text # 尝试获取公式的坐标 formula_coordinates = formula.attrs.get("coords") or "" if formula_coordinates is not "": # 如果有坐标,将它们转换为浮点数列表 formula_coordinates = [float(x) for x in formula_coordinates.split(",")] # 将ID、文本和坐标添加到公式列表中 formulas_list.append( { "formula_id": formula_id, "formula_text": formula_text, "formula_coordinates": formula_coordinates, } ) return formulas_list # 返回公式列表
1.2.6 把标题/作者/摘要/图形/公式等转换为JSON格式的字典
-
convert_article_soup_to_dict(article, as_list=False):
功能:将BeautifulSoup对象转换为JSON格式的字典,类似于某些开源项目的输出
主要步骤:
提取文章的标题、作者、发布日期、摘要、部分、引用、图形和公式
返回一个包含所有这些信息的字典def convert_article_soup_to_dict(article, as_list: bool = False): """ 将BeautifulSoup对象转换为JSON格式的函数 与https://github.com/allenai/science-parse/ 的输出类似 参数 ========== article: BeautifulSoup 输出 ====== article_json: dict, 给定文章的解析字典,格式如下: { 'title': ..., 'abstract': ..., 'sections': [ {'heading': ..., 'text': ...}, {'heading': ..., 'text': ...}, ... ], 'references': [ {'title': ..., 'journal': ..., 'year': ..., 'authors': ...}, {'title': ..., 'journal': ..., 'year': ..., 'authors': ...}, ... ], 'figures': [ {'figure_label': ..., 'figure_type': ..., 'figure_id': ..., 'figure_caption': ..., 'figure_data': ...}, ... ] } """ article_dict = {} # 初始化文章字典 if article is not None: # 从文章中获取主标题 title = article.find("title", attrs={"type": "main"}) title = title.text.strip() if title is not None else "" article_dict["title"] = title # 解析文章的作者 article_dict["authors"] = parse_authors(article) # 解析文章的发布日期 article_dict["pub_date"] = parse_date(article) # 解析文章的摘要 article_dict["abstract"] = parse_abstract(article) # 解析文章的各个部分 article_dict["sections"] = parse_sections(article, as_list=as_list) # 解析文章的参考文献 article_dict["references"] = parse_references(article) # 解析文章的图表 article_dict["figures"] = parse_figure_caption(article) # 解析文章的公式 article_dict["formulas"] = parse_formulas(article) # 从文章中获取DOI doi = article.find("idno", attrs={"type": "DOI"}) doi = doi.text if doi is not None else "" article_dict["doi"] = doi return article_dict else: return None # 如果文章不存在,返回None -
parse_pdf_to_dict(...)
功能:解析给定的PDF并返回解析后的文章的字典
主要步骤:
使用外部工具或服务(如GROBID)解析PDF
将解析后的BeautifulSoup对象转换为字典格式
返回该字典
这个函数的目的是解析给定的PDF文件,并将其转换为一个结构化的字典。首先,它使用parse_pdf函数来解析PDF,然后使用convert_article_soup_to_dict函数将解析后的BeautifulSoup对象转换为字典def parse_pdf_to_dict( pdf_path: str, fulltext: bool = True, soup: bool = True, as_list: bool = False, return_coordinates: bool = True, grobid_url: str = GROBID_URL, ): """ 解析给定的PDF并返回解析后的文章字典 参数 ========== pdf_path: str, 出版物或文章的路径 fulltext: bool, 是否提取完整文本 soup: bool, 是否返回BeautifulSoup as_list: bool, 是否返回部分列表 return_coordinates: bool, 是否返回坐标 grobid_url: str, grobid服务器的url,默认为`GROBID_URL` 可更改为 "https://cloud.science-miner.com/grobid/" 使用云服务 输出 ===== article_dict: dict, 文章的字典 """ # 使用parse_pdf函数解析PDF parsed_article = parse_pdf( pdf_path, fulltext=fulltext, soup=soup, return_coordinates=return_coordinates, grobid_url=grobid_url, ) # 将BeautifulSoup对象转换为字典 article_dict = convert_article_soup_to_dict(parsed_article, as_list=as_list) return article_dict # 返回解析后的文章字典
1.3 论文检索:ChatPaper/auto_survey/utils
具体包含如下功能(这个基于GPT4的文献总结工具的项目auto-draft也提供类似的功能)
- 自动搜索相关文献, 提供真实有出处的引用
- 自动生成LaTeX格式,markdown格式的调研结果
1.3.1 /utils/knowledge_databases/ml_textbook_test
// 待更
1.3.2 /utils/embeddings.py
# 导入HuggingFace的文本嵌入功能
from langchain.embeddings import HuggingFaceEmbeddings
# 导入操作系统相关的模块,用于获取环境变量等操作
import os
# 从环境变量中获取OpenAI的API密钥
openai_api_key = os.getenv("OPENAI_API_KEY")
# 如果获取到了OpenAI的API密钥
if openai_api_key is not None:
# 导入OpenAI的文本嵌入功能
from langchain.embeddings.openai import OpenAIEmbeddings
# 使用获取到的API密钥初始化OpenAI的文本嵌入
openai_embedding = OpenAIEmbeddings(model="text-embedding-ada-002", openai_api_key=openai_api_key)
else:
# 如果没有获取到API密钥,则将OpenAI的文本嵌入设为None
openai_embedding = None
# 定义HuggingFace的模型名称
model_name = 'sentence-transformers/all-MiniLM-L6-v2'
# 设置模型的参数,这里是将模型放在CPU上运行
model_kwargs = {'device': 'cpu'}
# 设置文本嵌入的参数,这里是不对嵌入进行归一化
encode_kwargs = {'normalize_embeddings': False}
# 使用上述参数初始化HuggingFace的文本嵌入
all_minilm_l6_v2 = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs)
# 创建一个字典来存储上述两种文本嵌入,方便后续调用
EMBEDDINGS = {"text-embedding-ada-002": openai_embedding, "all-MiniLM-L6-v2": all_minilm_l6_v2}1.3.3 /utils/gpt_interaction.py
// 待更
1.3.4 /utils/knowledge.py
定义了一个Knowledge类,该类使用关键词字典从数据库中搜索相关内容,并可以将这些内容转化为提示文本或JSON格式
import tiktoken # 导入tiktoken模块,用于计算tokens数量
from random import shuffle # 从random模块导入shuffle函数,用于随机打乱列表
# 使用`tiktoken`来计算文本中的tokens数量
tokenizer_name = tiktoken.encoding_for_model('gpt-4') # 为"gpt-4"模型获取相应的编码器名称
tokenizer = tiktoken.get_encoding(tokenizer_name.name) # 获取编码器实例
def tiktoken_len(text):
# 计算给定文本中的tokens数量
tokens = tokenizer.encode(text, disallowed_special=()) # 对文本进行编码并返回tokens
return len(tokens) # 返回tokens的数量
class Knowledge:
# 定义一个Knowledge类来处理知识数据库相关操作
def __init__(self, db):
self.db = db # 数据库实例
self.contents = [] # 用于存放内容的列表
def collect_knowledge(self, keywords_dict, max_query):
"""
根据给定的关键词字典,从数据库中搜索并收集相关的知识。
keywords_dict:
示例: {"machine learning": 5, "language model": 2};
"""
db = self.db
if max_query > 0:
for kw in keywords_dict:
docs = db.similarity_search_with_score(kw, k=max_query) # 使用关键词在数据库中进行相似度搜索
for i in range(max_query):
content = {"content": docs[i][0].page_content.replace('\n', ' '), # 移除换行符
"score": docs[i][1]} # 为每个文档添加评分
self.contents.append(content) # 将内容添加到contents列表中
shuffle(self.contents) # 随机打乱contents列表
def to_prompts(self, max_tokens=2048):
# 将收集到的知识内容转化为提示文本,且tokens总数不超过max_tokens
if len(self.contents) == 0:
return ""
prompts = []
tokens = 0
for idx, content in enumerate(self.contents):
prompt = "Reference {}: {}\n".format(idx, content["content"])
tokens += tiktoken_len(prompt)
if tokens >= max_tokens:
break
else:
prompts.append(prompt) # 将提示文本添加到prompts列表中
return "".join(prompts) # 返回连接后的提示文本
def to_json(self):
# 将收集到的知识内容转化为JSON格式
if len(self.contents) == 0:
return {}
output = {}
for idx, content in enumerate(self.contents):
output[str(idx)] = {
"content": content["content"],
"score": str(content["score"])
}
print(output)
return output1.3.5 /utils/references.py
这个代码文件主要注意实现了以下功能
1.3.5.1 第一部分:References 类之外
-
Reference类的说明
- 从给定的
.bib文件中读取论文,并用search_paper_abstract方法填充缺失的摘要 - 根据一些关键词使用Semantic Scholar API查找相关论文
- 从所选论文中生成Bibtex引用格式
- 从所选论文中生成提示(prompts)。示例提示格式为:
{"paper_id": "paper summary"}。
- 从给定的
-
待完成的任务(todo)
- 加载预定义的论文;
- 使用Semantic Scholar API查找所有相关作品;
- 将所有引文添加到
bib_papers; - 将所有被引文添加到
bib_papers; - 使用Semantic Scholar查找它们的嵌入;
- 将引文分组以减少tokens的数量
-
一些基本的工具
-
evaluate_cosine_similarity:计算两个向量的余弦相似性
def evaluate_cosine_similarity(v1, v2): try: return np.dot(v1, v2)/(norm(v1)*norm(v2)) except ValueError: return 0.0 -
chunks 将一个较长的列表分割为较小的批次,以便于处理;
def chunks(lst, chunk_size=MAX_BATCH_SIZE): """Splits a longer list to respect batch size""" for i in range(0, len(lst), chunk_size): yield lst[i : i + chunk_size] -
embed 通过向Semantic Scholar的API发送请求,为一组论文计算嵌入(即将论文映射到一个向量空间中)
def embed(papers): embeddings_by_paper_id: Dict[str, List[float]] = {} for chunk in chunks(papers): # Allow Python requests to convert the data above to JSON response = requests.post(URL, json=chunk) if response.status_code != 200: raise RuntimeError("Sorry, something went wrong, please try later!") for paper in response.json()["preds"]: embeddings_by_paper_id[paper["paper_id"]] = paper["embedding"] return embeddings_by_paper_id -
get_embeddings 为给定的论文标题和描述获取嵌入
def get_embeddings(paper_title, paper_description): output = [{"title": paper_title, "abstract": paper_description, "paper_id": "target_paper"}] emb_vector = embed(output)["target_paper"] target_paper = output[0] target_paper["embeddings"] = emb_vector return target_paper -
get_top_k 获取与给定论文最相关的
k篇论文
具体而言,从提供的papers_dict 中找到与给定的paper_title和paper_description最相似的前k篇论文,并返回。至于相似性是通过计算两篇论文嵌入向量的余弦相似度来确定的def get_top_k(papers_dict, paper_title, paper_description, k=None): # 获取目标论文的嵌入向量 target_paper = get_embeddings(paper_title, paper_description) # 存放所有的论文信息,其中应包含嵌入向量 papers = papers_dict # 如果k小于papers的数量,返回k篇最相关的论文 # 如果k大于等于papers的数量或k为None,返回所有论文 max_num_papers = len(papers) # 获取论文总数 if k is None: # 如果k为None,设置k为论文总数 k = max_num_papers num_papers = min(k, max_num_papers) # 确定需要返回的论文数量 # 获取目标论文的嵌入向量 target_embedding_vector = target_paper["embeddings"] # 计算每篇论文与目标论文的余弦相似度 for k in papers: v = papers[k] embedding_vector = v["embeddings"] # 获取当前论文的嵌入向量 cos_sim = evaluate_cosine_similarity(embedding_vector, target_embedding_vector) # 计算余弦相似度 papers[k]["cos_sim"] = cos_sim # 存储余弦相似度到papers中 # 返回相似度最高的前k篇论文 sorted_papers = {k: v for k, v in sorted(papers.items(), key=lambda x: x[1]["cos_sim"], reverse=True)[:num_papers]} # 从返回的论文中移除嵌入向量信息 for key in sorted_papers: sorted_papers[key].pop("embeddings", None) return sorted_papers -
remove_newlines 去除摘要中的换行符,减少提示的长度
def remove_newlines(serie): # This function is applied to the abstract of each paper to reduce the length of prompts. serie = serie.replace('\n', ' ') serie = serie.replace('\\n', ' ') serie = serie.replace(' ', ' ') serie = serie.replace(' ', ' ') return serie
-
evaluate_cosine_similarity:计算两个向量的余弦相似性
-
从.bib文件加载论文信息
- 读取.bib文件,并将其解析为一个python对象;
- 通过load_papers_from_bibtex 函数遍历这个对象,从中提取论文的各种属性(如ID、标题、期刊、年份、作者、摘要等);
def load_papers_from_bibtex(bib_file_path): with open(bib_file_path) as bibtex_file: bib_database = bibtexparser.load(bibtex_file) if len(bib_database.entries) == 0: return [] else: bib_papers = [] for bibitem in bib_database.entries: # Add each paper to `bib_papers` paper_id = bibitem.get("ID") title = bibitem.get("title") if title is None: continue journal = bibitem.get("journal") year = bibitem.get("year") author = bibitem.get("author") abstract = bibitem.get("abstract") if abstract is None: abstract = search_paper_abstract(title) result = { "paper_id": paper_id, "title": title, "link": "", "abstract": abstract, "authors": author, "year": year, "journal": journal } bib_papers.append(result) return bib_papers - 对于缺失摘要的论文,使用
search_paper_abstract函数查询摘要def search_paper_abstract(title): pg = ProxyGenerator() success = pg.FreeProxies() # pg.ScraperAPI("921b16f94d701308b9d9b4456ddde155") if success: try: scholarly.use_proxy(pg) # input the title of a paper, return its abstract search_query = scholarly.search_pubs(title) found_paper = next(search_query) except: return "" else: return "" # raise RuntimeError("ScraperAPI fails.") return remove_newlines(found_paper['bib']['abstract'])
-
计算文本的tokens数量
- 使用
tokenizer对象来计算给定文本的tokens的数量# `tokenizer`: used to count how many tokens tokenizer_name = tiktoken.encoding_for_model('gpt-4') tokenizer = tiktoken.get_encoding(tokenizer_name.name) def tiktoken_len(text): # evaluate how many tokens for the given text tokens = tokenizer.encode(text, disallowed_special=()) return len(tokens)
- 使用
-
使用Semantic Scholar (SS) API搜索论文
- 使用Semantic Scholar API搜索指定关键词的论文;
- 从API返回的数据中提取论文的各种属性
-
parse_search_results函数这部分主要关于从搜索结果中提取学术论文的相关信息:
该函数的目的是对传入的搜索结果进行解析,并将其转换为一个论文信息列表。- 首先检查传入的搜索结果是否为空。
- 逐个解析每篇论文的内容,包括作者信息、年份、标题等。
- 对某些字段进行特殊处理,如将日志名中的
&替换为\&。 - 如果存在摘要的“tldr”(即“过长不读”)版本,它会被优先使用,否则会使用原始摘要。
- 最后,所有提取出的信息将被组合成一个字典并添加到结果列表中
且函数下方的代码调用了一个假设的ss_search方法,然后使用上述函数处理这些搜索结果def parse_search_results(search_results_ss): # 判断搜索结果是否为空 if len(search_results_ss) == 0: return [] # 将搜索结果转换为论文字典的列表 papers_ss = [] for raw_paper in search_results_ss: # 如果论文没有摘要,跳过此论文 if raw_paper["abstract"] is None: continue # 提取作者信息 authors_str, last_name = extract_author_info(raw_paper['authors']) # 获取论文的发表年份 year_str = str(raw_paper['year']) # 获取论文标题 title = raw_paper['title'] # 有些期刊的名字可能包含"&"字符;将其替换掉 journal = raw_paper['venue'].replace("&", "\\&") # 如果没有提供期刊名,就默认为“arXiv preprint” if not journal: journal = "arXiv preprint" # 根据作者姓、发表年份和标题提取论文ID paper_id = extract_paper_id(last_name, year_str, title).lower() # 转换外部ID为链接 link = externalIds2link(raw_paper['externalIds']) # 如果存在tldr摘要,使用tldr摘要;否则,使用原始摘要并移除其中的换行符 if tldr and raw_paper['tldr'] is not None: abstract = raw_paper['tldr']['text'] else: abstract = remove_newlines(raw_paper['abstract']) # 有些论文可能没有嵌入;处理这种情况 embeddings_dict = raw_paper.get('embedding') if embeddings_dict is None: continue else: embeddings = raw_paper['embedding']['vector'] # 组合结果 result = { "paper_id": paper_id, "title": title, "abstract": abstract, "link": link, "authors": authors_str, "year": year_str, "journal": journal, "embeddings": embeddings } # 将结果添加到论文列表中 papers_ss.append(result) # 返回论文列表 return papers_ss # 使用关键字进行搜索 raw_results = ss_search(keyword, limit=counts) # 如果获取到了原始搜索结果 if raw_results is not None: # 提取搜索结果数据 search_results = raw_results.get("data") # 如果搜索结果是空的,设置为空列表 if search_results is None: search_results = [] # 如果没有获取到原始搜索结果,设置为空列表 else: search_results = [] # 解析搜索结果并返回 results = parse_search_results(search_results) return results
1.3.5.2 第二部分:References 类
该类用于管理论文引用:
- 初始化方法:当创建一个References对象时,可以选择为其提供标题、论文列表、关键词以及描述
- load_papers 方法:加载给定BibTeX格式的论文到引用类中
- generate_keywords_dict 方法:生成一个关键词字典,其中每个关键词都关联一个论文数量
- collect_papers 方法:使用给定的关键词字典收集尽可能多的论文。这个方法尝试收集给定关键词的相关论文,并添加到类的内部存储中
- to_bibtex 方法:将保存的论文列表转换为BibTeX格式的文件
- _get_papers 方法:一个内部方法,用于从内部存储中获取论文列表
- to_prompts 方法:将引用转换为提示格式,这可能是为了后续使用某种机器学习模型
- to_json 方法:将论文列表转换为JSON格式
- 代码的最后部分(在if __name__ == "__main__":之后)是一个简单的测试部分,用于测试上述代码的功能
//待更
1.4 ChatPaper/chat_paper.py
chat_paper.py,包含一个Paper类、Reader类和chat_paper_mian函数。该程序功能为根据读者输入的搜索查询和感兴趣的关键词,从Arxiv数据库中获取文章,并对文章进行摘要和总结。程序使用了OpenAI的GPT-3模型生成文本摘要,使用了arxiv包获取Arxiv数据库中的文章。程序会将摘要和总结以markdown文件的形式保存下来。
1.4.1 Paper类
- Paper 类代表了一篇论文,它可以从 PDF 文件中解析出论文的元信息和内容,并提供了一些函数用于获取论文信息,如获取文章标题,获取章节名称及内容等。主要方法有:
- parse_pdf:解析PDF文件
其中的self._get_all_page_index() 和self._get_all_page() 这两个方法 下文很快会定义def parse_pdf(self): # 定义一个方法来解析PDF文件 self.pdf = fitz.open(self.path) # 使用fitz库打开指定路径的pdf文件 self.text_list = [page.get_text() for page in self.pdf] # 从每一页中提取文本并存放到列表中 self.all_text = ' '.join(self.text_list) # 将每一页的文本连接成一个完整的字符串 self.section_page_dict = self._get_all_page_index() # 获取段落与其对应的页码字典 print("section_page_dict", self.section_page_dict) # 打印该段落与页码的对应字典 self.section_text_dict = self._get_all_page() # 获取段落与其对应的内容字典 self.section_text_dict.update({"title": self.title}) # 将标题添加到段落内容字典中 self.section_text_dict.update({"paper_info": self.get_paper_info()}) # 获取论文的信息并添加到字典中 self.pdf.close() # 关闭pdf文件 - get_all_page_index:各个部分与页码的对应字典
def _get_all_page_index(self): # 定义需要寻找的章节名称列表 section_list = ["Abstract", 'Introduction', 'Related Work', 'Background', "Preliminary", "Problem Formulation", 'Methods', 'Methodology', "Method", 'Approach', 'Approaches', # exp "Materials and Methods", "Experiment Settings", 'Experiment', "Experimental Results", "Evaluation", "Experiments", "Results", 'Findings', 'Data Analysis', "Discussion", "Results and Discussion", "Conclusion", 'References'] # 初始化一个字典来存储找到的章节和它们在文档中出现的页码 section_page_dict = {} # 遍历每一页文档 for page_index, page in enumerate(self.pdf): # 获取当前页面的文本内容 cur_text = page.get_text() # 遍历需要寻找的章节名称列表 for section_name in section_list: # 将章节名称转换成大写形式 section_name_upper = section_name.upper() # 如果当前页面包含"Abstract"这个关键词 if "Abstract" == section_name and section_name in cur_text: # 将"Abstract"和它所在的页码加入字典中 section_page_dict[section_name] = page_index # 如果当前页面包含章节名称,则将章节名称和它所在的页码加入字典中 else: if section_name + '\n' in cur_text: section_page_dict[section_name] = page_index elif section_name_upper + '\n' in cur_text: section_page_dict[section_name] = page_index # 返回所有找到的章节名称及它们在文档中出现的页码 return section_page_dict - get_all_page:各个部分与内容对应的字典
def _get_all_page(self): """ 获取PDF文件中每个页面的文本信息,并将文本信息按照章节组织成字典返回。 """ text = '' # 初始化空字符串用于临时储存文本 text_list = [] # 初始化列表用于储存每一页的文本 section_dict = {} # 初始化章节字典 text_list = [page.get_text() for page in self.pdf] # 从每一页获取文本 for sec_index, sec_name in enumerate(self.section_page_dict): # 遍历章节页码字典 print(sec_index, sec_name, self.section_page_dict[sec_name]) # 打印章节索引、章节名和章节起始页码 if sec_index <= 0 and self.abs: # 如果是第一个章节并且存在摘要,则跳过 continue else: start_page = self.section_page_dict[sec_name] # 获取章节的起始页码 # 如果当前章节不是最后一个,则获取下一个章节的起始页码作为当前章节的结束页码 if sec_index < len(list(self.section_page_dict.keys()))-1: end_page = self.section_page_dict[list(self.section_page_dict.keys())[sec_index+1]] else: # 否则当前章节的结束页码为PDF的最后一页 end_page = len(text_list) print("start_page, end_page:", start_page, end_page) # 打印起始和结束页码 cur_sec_text = '' # 初始化当前章节的文本 # 如果起始页码和结束页码相同,说明章节在同一页内 if end_page - start_page == 0: next_sec = list(self.section_page_dict.keys())[sec_index+1] # 下面的代码是为了确定当前章节的文本的起始和结束位置 # 这部分代码处理可能存在的大小写不一致的问题 start_i = text_list[start_page].find(sec_name) if text_list[start_page].find(sec_name) != -1 else text_list[start_page].find(sec_name.upper()) end_i = text_list[start_page].find(next_sec) if text_list[start_page].find(next_sec) != -1 else text_list[start_page].find(next_sec.upper()) cur_sec_text += text_list[start_page][start_i:end_i] else: # 否则,章节可能跨越多页 for page_i in range(start_page, end_page): # 下面的代码是为了确定在每一页中章节文本的起始和结束位置 if page_i == start_page: start_i = text_list[start_page].find(sec_name) if text_list[start_page].find(sec_name) != -1 else text_list[start_page].find(sec_name.upper()) cur_sec_text += text_list[page_i][start_i:] elif page_i < end_page: cur_sec_text += text_list[page_i] elif page_i == end_page: next_sec = list(self.section_page_dict.keys())[sec_index+1] end_i = text_list[start_page].find(next_sec) if text_list[start_page].find(next_sec) != -1 else text_list[start_page].find(next_sec.upper()) cur_sec_text += text_list[page_i][:end_i] # 在当前章节的文本中去除多余的换行符 section_dict[sec_name] = cur_sec_text.replace('-\n', '').replace('\n', ' ') return section_dict # 返回章节字典 - get_paper_info:获取论文的摘要信息
首先尝试从self.section_text_dict 字典中获取摘要,如果没有,则使用self.abs。最后,它从标题页的文本中移除摘要的内容并返回def get_paper_info(self): # 定义一个方法获取论文的信息 first_page_text = self.pdf[self.title_page].get_text() # 从PDF的标题页中提取文本 if "Abstract" in self.section_text_dict.keys(): # 如果"Abstract"(摘要)在字典的关键字中 abstract_text = self.section_text_dict['Abstract'] # 从字典中获取摘要的文本 else: # 否则 abstract_text = self.abs # 使用self.abs作为摘要的文本 first_page_text = first_page_text.replace(abstract_text, "") # 从首页面文本中移除摘要内容 return first_page_text # 返回处理后的首页面文本 - get_chapter_names:根据字体大小,识别每个章节名称,并返回一个列表
- get_title:获取论文标题
def get_title(self): doc = self.pdf # 打开pdf文件 max_font_size = 0 # 初始化最大字体大小为0 max_string = "" # 初始化最大字体大小对应的字符串为空 max_font_sizes = [0] for page_index, page in enumerate(doc): # 遍历每一页 text = page.get_text("dict") # 获取页面上的文本信息 blocks = text["blocks"] # 获取文本块列表 for block in blocks: # 遍历每个文本块 if block["type"] == 0 and len(block['lines']): # 如果是文字类型 if len(block["lines"][0]["spans"]): font_size = block["lines"][0]["spans"][0]["size"] # 获取第一行第一段文字的字体大小 max_font_sizes.append(font_size) if font_size > max_font_size: # 如果字体大小大于当前最大值 max_font_size = font_size # 更新最大值 max_string = block["lines"][0]["spans"][0]["text"] # 更新最大值对应的字符串 max_font_sizes.sort() print("max_font_sizes", max_font_sizes[-10:]) cur_title = '' for page_index, page in enumerate(doc): # 遍历每一页 text = page.get_text("dict") # 获取页面上的文本信息 blocks = text["blocks"] # 获取文本块列表 for block in blocks: # 遍历每个文本块 if block["type"] == 0 and len(block['lines']): # 如果是文字类型 if len(block["lines"][0]["spans"]): cur_string = block["lines"][0]["spans"][0]["text"] # 更新最大值对应的字符串 font_flags = block["lines"][0]["spans"][0]["flags"] # 获取第一行第一段文字的字体特征 font_size = block["lines"][0]["spans"][0]["size"] # 获取第一行第一段文字的字体大小 # print(font_size) if abs(font_size - max_font_sizes[-1]) < 0.3 or abs(font_size - max_font_sizes[-2]) < 0.3: # print("The string is bold.", max_string, "font_size:", font_size, "font_flags:", font_flags) if len(cur_string) > 4 and "arXiv" not in cur_string: # print("The string is bold.", max_string, "font_size:", font_size, "font_flags:", font_flags) if cur_title == '' : cur_title += cur_string else: cur_title += ' ' + cur_string self.title_page = page_index # break title = cur_title.replace('\n', ' ') return title
1.4.2 Reader类
Reader类包含了下载文章、筛选文章以及使用OpenAI的GPT-3模型生成文本摘要和总结的方法。主要方法有:
- get_arxiv(): 使用Arxiv的API获取搜索结果
- filter_arxiv(): 筛选文章,并返回筛选后的结果
- download_pdf(): 从Arxiv下载筛选后的文章
- summary_with_chat(): 对每一篇下载下来的文章进行文本摘要和总结,并将结果以markdown文件的形式保存
该函数的实现主要分为三个部分
首先,第一步:用title,abs和introduction进行总结
其次,第二步:总结方法# 遍历论文列表 for paper_index, paper in enumerate(paper_list): # 第一步:用title,abs和introduction进行总结 text = '' text += 'Title:' + paper.title text += 'Url:' + paper.url text += 'Abstract:' + paper.abs text += 'Paper_info:' + paper.section_text_dict['paper_info'] # 添加introduction text += list(paper.section_text_dict.values())[0] chat_summary_text = "" # 尝试与聊天机器人对话以获取摘要 try: chat_summary_text = self.chat_summary(text=text) except Exception as e: # 捕获所有异常 print("summary_error:", e) import sys exc_type, exc_obj, exc_tb = sys.exc_info() # 获取异常信息 fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1] print(exc_type, fname, exc_tb.tb_lineno) if "maximum context" in str(e): # 如果错误信息中包含特定字符串 current_tokens_index = str(e).find("your messages resulted in") + len( "your messages resulted in") + 1 offset = int(str(e)[current_tokens_index:current_tokens_index + 4]) summary_prompt_token = offset + 1000 + 150 chat_summary_text = self.chat_summary(text=text, summary_prompt_token=summary_prompt_token) # 添加到html列表中 htmls.append('## Paper:' + str(paper_index + 1)) htmls.append('\n\n\n') htmls.append(chat_summary_text)
最后,第三步:总结全文并打分# 第二步:总结方法。 # 由于有些文章的方法章节名是算法名,所以简单的通过关键词来筛选很难获取 method_key = '' for parse_key in paper.section_text_dict.keys(): if 'method' in parse_key.lower() or 'approach' in parse_key.lower(): method_key = parse_key break # 如果找到方法关键词 if method_key != '': text = '' method_text = '' summary_text = '' summary_text += "<summary>" + chat_summary_text method_text += paper.section_text_dict[method_key] text = summary_text + "\n\n<Methods>:\n\n" + method_text chat_method_text = "" try: chat_method_text = self.chat_method(text=text) except Exception as e: print("method_error:", e) import sys exc_type, exc_obj, exc_tb = sys.exc_info() fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1] print(exc_type, fname, exc_tb.tb_lineno) if "maximum context" in str(e): current_tokens_index = str(e).find("your messages resulted in") + len( "your messages resulted in") + 1 offset = int(str(e)[current_tokens_index:current_tokens_index + 4]) method_prompt_token = offset + 800 + 150 chat_method_text = self.chat_method(text=text, method_prompt_token=method_prompt_token) htmls.append(chat_method_text) else: chat_method_text = '' htmls.append("\n" * 4)# 第三步:总结全文并打分。 conclusion_key = '' for parse_key in paper.section_text_dict.keys(): if 'conclu' in parse_key.lower(): conclusion_key = parse_key break text = '' conclusion_text = '' summary_text = '' summary_text += "<summary>" + chat_summary_text + "\n <Method summary>:\n" + chat_method_text if conclusion_key != '': conclusion_text += paper.section_text_dict[conclusion_key] text = summary_text + "\n\n<Conclusion>:\n\n" + conclusion_text else: text = summary_text chat_conclusion_text = "" try: chat_conclusion_text = self.chat_conclusion(text=text) except Exception as e: print("conclusion_error:", e) import sys exc_type, exc_obj, exc_tb = sys.exc_info() fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1] print(exc_type, fname, exc_tb.tb_lineno) if "maximum context" in str(e): current_tokens_index = str(e).find("your messages resulted in") + len( "your messages resulted in") + 1 offset = int(str(e)[current_tokens_index:current_tokens_index + 4]) conclusion_prompt_token = offset + 800 + 150 chat_conclusion_text = self.chat_conclusion(text=text, conclusion_prompt_token=conclusion_prompt_token) htmls.append(chat_conclusion_text) htmls.append("\n" * 4) # 整合成一个文件并保存 date_str = str(datetime.datetime.now())[:13].replace(' ', '-') export_path = os.path.join(self.root_path, 'export') if not os.path.exists(export_path): os.makedirs(export_path) mode = 'w' if paper_index == 0 else 'a' file_name = os.path.join(export_path, date_str + '-' + self.validateTitle(paper.title[:80]) + "." + self.file_format) self.export_to_markdown("\n".join(htmls), file_name=file_name, mode=mode) htmls = [] -
chat_summary():第一次提取title,abs,和introduction,设定prompt通过调用API的方式得到对应的总结
def chat_summary(self, text, summary_prompt_token=1100): # 设置OpenAI API密钥 openai.api_key = self.chat_api_list[self.cur_api] # 更新API密钥索引,用于循环使用多个API密钥(如果有) self.cur_api += 1 self.cur_api = 0 if self.cur_api >= len(self.chat_api_list) - 1 else self.cur_api # 计算输入文本的token数量 text_token = len(self.encoding.encode(text)) # 计算截断文本的索引,确保总的token数量不超过限制 clip_text_index = int(len(text) * (self.max_token_num - summary_prompt_token) / text_token) # 获取截断后的文本 clip_text = text[:clip_text_index] # 定义聊天机器人的交互消息 messages = [ {"role": "system", "content": "You are a researcher in the field of [" + self.key_word + "] who is good at summarizing papers using concise statements"}, {"role": "assistant", "content": "This is the title, author, link, abstract and introduction of an English document. I need your help to read and summarize the following questions: " + clip_text}, {"role": "user", "content": """ ...(这部分是详细的指示内容,为了简洁我略过了)... """.format(self.language, self.language, self.language)}, ] # 根据API类型调用相应的方法 if openai.api_type == 'azure': response = openai.ChatCompletion.create( engine=self.chatgpt_model, messages=messages, ) else: response = openai.ChatCompletion.create( model=self.chatgpt_model, messages=messages, ) # 从响应中提取机器人的回复 result = '' for choice in response.choices: result += choice.message.content # 打印结果和使用的token数量以及响应时间 print("summary_result:\n", result) print("prompt_token_used:", response.usage.prompt_tokens, "completion_token_used:", response.usage.completion_tokens, "total_token_used:", response.usage.total_tokens) print("response_time:", response.response_ms / 1000.0, 's') # 返回结果 return result -
chat_method():提取上面chat_summary()得到的结果,加上method或approach部分的内容,设定prompt通过调用API的方式得到对应的总结
def chat_method(self, text, method_prompt_token=800): # 设置OpenAI的API key openai.api_key = self.chat_api_list[self.cur_api] # 将当前API索引递增,以便下次使用不同的API key self.cur_api += 1 # 如果当前API索引超出API key列表的长度,则将其重置为0(实现循环使用API key列表) self.cur_api = 0 if self.cur_api >= len(self.chat_api_list) - 1 else self.cur_api # 使用encoding方法计算输入文本的token数量 text_token = len(self.encoding.encode(text)) # 根据最大token数量和方法提示token计算需要裁剪的文本长度 clip_text_index = int(len(text) * (self.max_token_num - method_prompt_token) / text_token) # 根据上面计算的索引裁剪文本 clip_text = text[:clip_text_index] # 定义要发送到ChatGPT的消息列表 messages = [ # 定义系统角色的消息,描述用户的专业背景和能力 {"role": "system", "content": "You are a researcher in the field of [" + self.key_word + "] who is good at summarizing papers using concise statements"}, # 定义助手角色的消息,描述要助手完成的任务 {"role": "assistant", "content": "This is the <summary> and <Method> part of an English document, where <summary> you have summarized, but the <Methods> part, I need your help to read and summarize the following questions." + clip_text}, # 定义用户角色的消息,给出具体的问题和期望格式 {"role": "user", "content": """ 7. Describe in detail the methodological idea of this article. Be sure to use {} answers (proper nouns need to be marked in English). For example, its steps are. - (1):... - (2):... - (3):... - ....... Follow the format of the output that follows: 7. Methods: \n\n - (1):xxx;\n - (2):xxx;\n - (3):xxx;\n ....... \n\n Be sure to use {} answers (proper nouns need to be marked in English), statements as concise and academic as possible, do not repeat the content of the previous <summary>, the value of the use of the original numbers, be sure to strictly follow the format, the corresponding content output to xxx, in accordance with \n line feed, ....... means fill in according to the actual requirements, if not, you can not write. """.format(self.language, self.language)}, ] # 根据API类型选择适当的调用方法 if openai.api_type == 'azure': response = openai.ChatCompletion.create( engine=self.chatgpt_model, messages=messages, ) else: response = openai.ChatCompletion.create( model=self.chatgpt_model, messages=messages, ) # 从返回的答案中初始化一个空字符串用于保存结果 result = '' # 遍历返回的选择,将内容添加到结果字符串中 for choice in response.choices: result += choice.message.content # 打印方法的结果和相关的token使用情况 print("method_result:\n", result) print("prompt_token_used:", response.usage.prompt_tokens, "completion_token_used:", response.usage.completion_tokens, "total_token_used:", response.usage.total_tokens) # 打印响应时间 print("response_time:", response.response_ms / 1000.0, 's') # 返回结果字符串 return result - chat_conclusion():提取上面两部分:chat_summary()和chat_method()得到的结果(API给的回复),加上conclusion部分的内容,设定prompt通过调用API的方式得到对应的总结
def chat_conclusion(self, text, conclusion_prompt_token=800): # 设置OpenAI的API密钥 openai.api_key = self.chat_api_list[self.cur_api] # 使当前API索引递增,以便下次使用不同的API密钥 self.cur_api += 1 # 如果当前API索引超过API密钥列表的长度,将其重置为0 self.cur_api = 0 if self.cur_api >= len(self.chat_api_list) - 1 else self.cur_api # 使用encoding方法计算输入文本的token数量 text_token = len(self.encoding.encode(text)) # 计算需要裁剪的文本长度,以适应模型的最大token限制 clip_text_index = int(len(text) * (self.max_token_num - conclusion_prompt_token) / text_token) # 裁剪文本 clip_text = text[:clip_text_index] # 定义要发送给ChatGPT的消息列表 messages = [ # 系统角色的消息,描述用户作为一个审稿人的背景 {"role": "system", "content": "You are a reviewer in the field of [" + self.key_word + "] and you need to critically review this article"}, # 助手角色的消息,描述要助手完成的任务 {"role": "assistant", "content": "This is the <summary> and <conclusion> part of an English literature, where <summary> you have already summarized, but <conclusion> part, I need your help to summarize the following questions:" + clip_text}, # 用户角色的消息,提供具体问题和预期的答案格式 {"role": "user", "content": """ 8. Make the following summary.Be sure to use {} answers (proper nouns need to be marked in English). - (1):What is the significance of this piece of work? - (2):Summarize the strengths and weaknesses of this article in three dimensions: innovation point, performance, and workload. ....... Follow the format of the output later: 8. Conclusion: \n\n - (1):xxx;\n - (2):Innovation point: xxx; Performance: xxx; Workload: xxx;\n Be sure to use {} answers (proper nouns need to be marked in English), statements as concise and academic as possible, do not repeat the content of the previous <summary>, the value of the use of the original numbers, be sure to strictly follow the format, the corresponding content output to xxx, in accordance with \n line feed, ....... means fill in according to the actual requirements, if not, you can not write. """.format(self.language, self.language)}, ] # 根据API类型选择适当的方法来获取模型的答案 if openai.api_type == 'azure': response = openai.ChatCompletion.create( engine=self.chatgpt_model, messages=messages, ) else: response = openai.ChatCompletion.create( model=self.chatgpt_model, messages=messages, ) # 初始化结果字符串 result = '' # 遍历模型返回的答案,将其添加到结果字符串中 for choice in response.choices: result += choice.message.content # 打印结论部分的结果和token使用情况 print("conclusion_result:\n", result) print("prompt_token_used:", response.usage.prompt_tokens, "completion_token_used:", response.usage.completion_tokens, "total_token_used:", response.usage.total_tokens) # 打印响应时间 print("response_time:", response.response_ms / 1000.0, 's') # 返回结果字符串 return result
1.4.3 chat_paper_main
// 待更
1.5 RUN一下:ChatPaper代码整体运行后得到的部分结果
chatpaper代码运行后得到的部分结果 输出:标题、作者、单位、 关键词、相关链接及 Summary。其中
- Summary为总结 得到的摘要

- method_result:对论文方法(method或approach)的总结

- Conclusion_result:对论文全文的总结(包含工作意义及创新点等)

//待更
第二部分 gpt_academic源码解读
// 待更
第三部分 七月论文审稿GPT第1版:基于论文审稿语料微调RWKV
3.1 项目背景:API做论文摘要/对话/翻译可以,但做论文审稿不行
自从去年11月,ChatGPT火爆全球之后,大模型技术正在赋能千行百业,而身处当下的大模型时代,如果不利用大模型做点事情,则深感有负于时代,所以我司七月在线
- 一方面,谋划了35个大模型课程(由我远程带领北京的教育团队研发),帮助各行各业通过大模型技术提升各自的业务
- 二方面,则开始围绕“论文、文档、代码”做一系列LLM项目(由我司的长沙LLM项目团队负责,我目前base长沙兼管该项目团队,目前正在扩人,有兴趣者欢迎私我了解或加入)
对于论文,如本文前两个部分所述,市面上已有几个学术论文GPT了,但实话说,对于论文的摘要/总结、对话、翻译、语法检查而言,市面上的学术论文GPT的效果虽暂未有多好,可至少还过得去,而如果涉及到论文的修订/审稿,则市面上已有的学术论文GPT的效果则大打折扣。
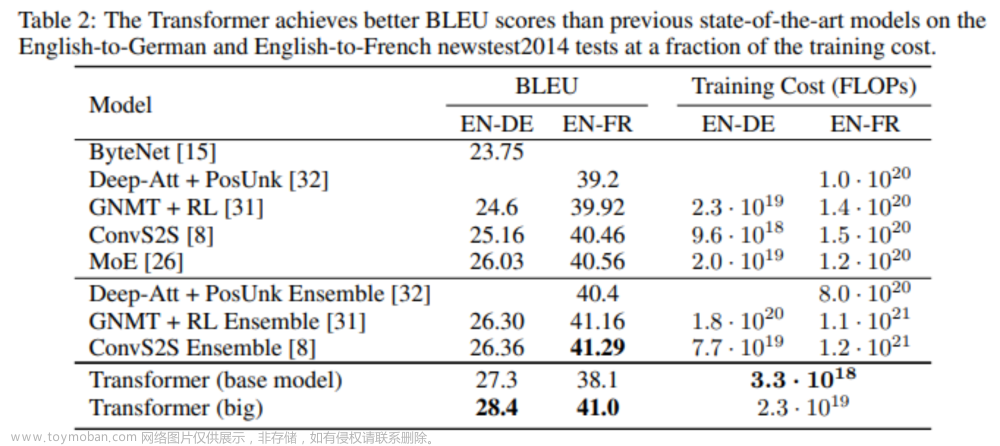
原因在哪呢?本质原因在于无论什么功能,它们基本都是基于OpenAI的API实现的,而关键是API毕竟不是万能的,API做翻译/总结/对话还行,但如果要对论文提出审稿意见,则API就捉襟见肘了。比如当让基于GPT3.5的ChatGPT初版,为经典论文《Attention Is All You Need》提出审稿意见,API(gpt-3.5-turbo,4,097的上下文)最终提出了三点建议(测试时间:23年8月27日),如下图所示:

- 是否可提供更多训练参数细节?
- 是否进行足够的消融实验?
- 是否提供可复现代码?
然而实际情况是,《Attention Is All You Need》中已经给出了模型参数、甚至学习率设置等具体的训练细节,消融实验也是与当时的SOTA进行比较,更是在文末提供了可用的训练、推理代码


so,为实现更好的review效果,需要使用特定的对齐数据集进行微调来获得具备优秀review能力的模型
3.2 数据处理:爬取、PDF解析、清洗、组织
做大模型工作的第一步永远是需要先解决数据的问题
一开始,我们本打算直接用GitHub上相关项目代码及其review数据,但已有的项目存在诸多问题
- 都仅支持爬取单会议单年的数据,数据规模严重不足
- 且部分还是基于Selenium(一个python自动化框架,通过解析网页页面元素,模拟人工点击的操作从网页中取数据)实现的爬虫,该方法效率过低,需要实际打开网页,等待页面元素加载完毕才能进行解析爬取
- 时效性无法保证,项目最近更新时间至今已有些年份,期间review数据难免出现变化,代码是否可用仍存疑
既然GitHub上已有的review数据没法用,那没办法,我们只能从零开始爬取我们需要的数据,那我们需要爬取的数据具体长什么样呢?
3.2.1 数据爬取:论文审稿数据是什么样子的(涵盖paper和review数据)
该例取自Natural Language Descriptions of Deep Visual Features,具体可结合下方的数据字段释义进行对照查看。
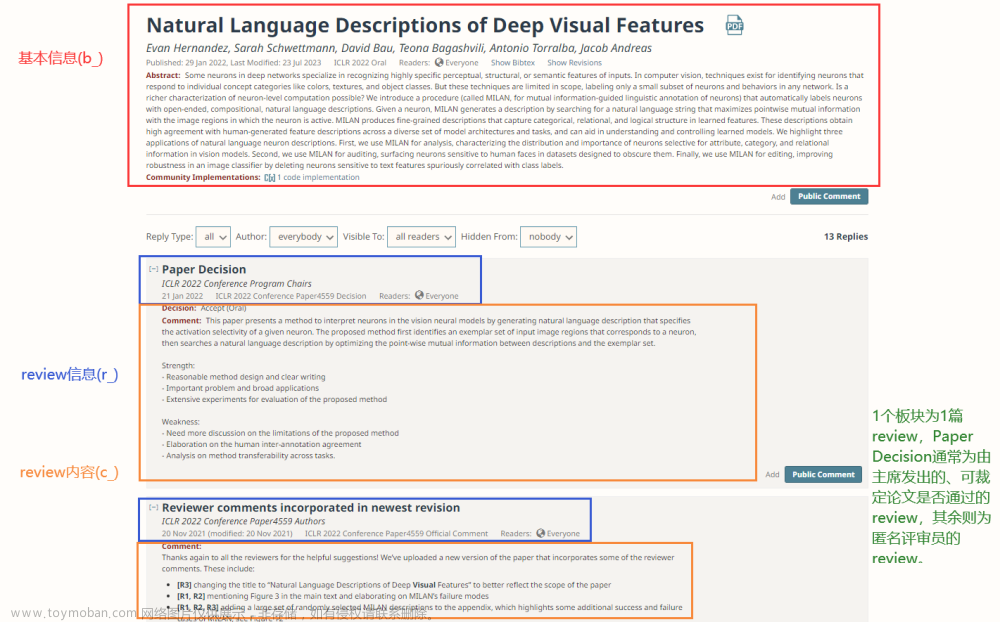
上图中各个数据字段的释义(仅展示关键字段)如下:
| 字段类别 | 字段名称 | 字段释义 |
|---|---|---|
| basic(基础信息) | b_forum | 论文讨论页的id |
| b_title | 论文的标题 | |
| b_url | 论文讨论页的链接 | |
| b_abstract | 论文的摘要 | |
| b_TL;DR | 论文的极简描述 | |
| b_authors | 论文的作者 | |
| b_keywords | 论文的关键词 | |
| b_venue | 论文所属会议 | |
| b_venue_id | 论文所属会议的id | |
| b_pdf_url | 论文pdf文件页的链接 | |
| b_venue_id | 论文所属会议的id | |
| review(review信息,部分论文没有review时此处则均为nan) | r_id | review的id |
| r_replyto | review所指向的论文页id | |
| r_invitation | review提出者的所属类别(通常为Decision或Official) | |
| r_signatures | review提出者的签名(可以理解为提出者在当前paper讨论中的id) | |
| content(review具体内容,部分论文没有review时此处则均为nan) | c_content | 完整的review内容(下述字段内容均由此处内容拆分得到) |
| c_title | review内容的标题 | |
| c_rating | 评级 | |
| c_review | 概览性review内容 | |
| c_confidence | 可信程度 | |
| c_decision | 由主席提出的采纳意见 | |
| c_comment | 评论 | |
| ⋯⋯ | 篇幅所限不再赘述,其余字段可根据字段名称知悉释义 |
论文是有了,但论文这么多篇,怎么批量下载到或爬取下来呢,毕竟我们不可能一篇篇去点击下载
好在论文审稿网站的单篇论文页中,提供了相应PDF文件的跳转链接(如https://julyreview.com/pdf?id=09QFnDWPF8),分析PDF页可知其链接构成与该篇论文在网站中的ID(即字段“b_forum”,上例中即为“09QFnDWPF8”)有关
从而可以通过论文ID,然后去拼出它的PDF所在的网页链接,之后用requests库爬下对应网页的二进制内容,再使用python的文件写入方法将PDF写入本地文件即可,具体如下所示
- 爬取审稿数据:utils/julyreview_crawler.py
通过这份代码来获取review及其paper信息import julyreview import time import requests import jsonlines class JulyreviewCrawler: def __init__(self, baseurl='https://api.julyreview.net'): """后台需挂载代理""" self.client = julyreview.Client(baseurl=baseurl) self.venues = self.client.get_group(id='venues').members def get_and_save_venue(self, venue_id): results_list = self._get_venue_papers(venue_id) if results_list: self._save_results(results_list) return results_list def get_and_save_total(self): total_results_list = [] for idx, venue_id in enumerate(self.venues): print('{}/{}: {}, total_results_list_length: {}'.format(idx + 1, len(self.venues), venue_id, len(total_results_list))) results_list = self._get_venue_papers(venue_id) total_results_list += results_list time.sleep(1) self._save_results(total_results_list, spec_name='total_notes') print('The number of papers is {}.'.format(len(total_results_list))) return total_results_list def _get_venue_papers(self, venue_id): """ 从venues(venues=client.get_group(id='venues').members)中获取指定venue的id来传入, 该函数将返回对应venue_id的论文信息并存储 """ # assert self._existence_check(venue_id), \ # 'This item "{}" is not available in julyviewer.net!'.format(venue_id) # 获取当前venue_id对应的提交论文(双盲) submissions = self.client.get_all_notes(invitation='{}/-/Blind_Submission'.format(venue_id), details='directReplies') # 获取当前venue_id下的论文id specified_forum_ids = self._get_all_forum_ids(submissions) # dict list results_list = [self._format_note(note, venue_id) for note in submissions if note.forum in specified_forum_ids] # if results_list: # for i in range(3): # print(results_list[i]['basic_dict']['forum']) return results_list def _get_specified_forum_ids(self, submissions): forum_ids = set() for note in submissions: for reply in note.details["directReplies"]: forum_ids.add(reply['forum']) return forum_ids def _get_all_forum_ids(self, submissions): """获取所有论文页id,无论是否有reply""" forum_ids = set() for note in submissions: forum_ids.add(note.forum) return forum_ids def _format_note(self, note, venue_id): """单条note的处理方法:提取note中的指定信息""" basic_dict = {} reviews_msg = [] authors_string = ','.join(note.content.get('authors', '--')) keywords_string = ','.join(note.content.get('keywords', '--')) localtime_string = time.strftime('%Y-%m-%d', time.localtime(note.pdate / 1000)) if note.pdate else '--' # basic message basic_dict['forum'] = note.forum if note.forum else '--' basic_dict['title'] = note.content.get('title', '--') basic_dict['url'] = 'https://julyreview.net/forum?id=' + note.forum basic_dict['pub_date'] = localtime_string basic_dict['abstract'] = note.content.get('abstract', '--') basic_dict['TL;DR'] = note.content.get('TL;DR', '--') basic_dict['authors'] = authors_string basic_dict['keywords'] = keywords_string basic_dict['venue'] = note.content.get('venue', '--') basic_dict['venue_id'] = note.content.get('venueid', '--') basic_dict['number'] = note.number if note.number else '--' basic_dict['pdf_url'] = 'https://julyreview.net/pdf?id=' + note.forum basic_dict['signatures'] = note.signatures if note.signatures else '--' basic_dict['bibtex'] = note.content.get('_bibtex', '--') basic_dict['from_venue_id'] = venue_id # reviews message reviews_msg = note.details["directReplies"] result_dict = {'basic_dict': basic_dict, 'reviews_msg': reviews_msg} return result_dict def _existence_check(self, item_id): if requests.get("https://julyreview.net/group?id={}".format(item_id)).status_code == 200: return True else: return False def _save_results(self, results_list, spec_name=None): if spec_name: venue_id = spec_name jsonl_file_name = '{}.jsonl'.format(spec_name) else: venue_id = results_list[0]['basic_dict']['venue_id'] jsonl_file_name = '{}.jsonl'.format(venue_id.replace(r'/', '--').replace(r'.', '__')) for result in results_list: with jsonlines.open(jsonl_file_name, mode='a') as file: file.write(result) print('The item "{}" saved successfully!'.format(venue_id)) return if __name__ == '__main__': orc = JulyreviewCrawler() results_list = orc.get_and_save_venue('ICLR.cc/2023/Workshop/TSRL4H') print(results_list[:3]) - 爬取论文PDF:download_pdfs
具体是通过上步获取到的paper信息里取出对应的论文id,拼成pdf_url,然后爬论文pdf
以下是核心代码,完整代码暂只放在我司针对B端客户的线下公司内训,或我司七月的大模型线上营中import requests import time # 函数用于从给定的URL下载PDF,并以特定论坛名称格式保存 def get_paper_pdf(forum, pdf_url): # 向给定的PDF URL发送请求 response = requests.get(pdf_url) # 打开一个文件用于写入PDF内容,文件名格式为'papers_pdf/{论坛名}.pdf' with open('papers_pdf/{}.pdf'.format(forum), 'wb') as f: # 将请求到的内容写入文件 f.write(response.content) # 函数结束,没有返回值 return # 初始化一个空字典用于存放PDF信息(这部分代码中未使用此字典) pdf_dict = {} # 设定开始索引 start_idx = 5501 # 设定结束索引 end_idx = 5555555 # 获取论坛数据的行数 df_dup_length = df_dup_forum.shape[0] # 遍历论坛数据 for idx, row in df_dup_forum.iterrows(): # 如果当前索引小于开始索引,则跳过当前循环 if idx < start_idx: continue # 每10个索引打印一次进度信息 if idx % 10 == 0: # time.sleep(1.5) # 可以取消注释来减缓请求速度 print('{}/{}'.format(idx, df_dup_length)) try: # 尝试下载PDF get_paper_pdf(row['b_forum'], row['b_pdf_url']) except: # 如果遇到错误,则等待5秒后重试 time.sleep(5) get_paper_pdf(row['b_forum'], row['b_pdf_url']) # 如果达到结束索引,则终止循环 if idx == end_idx: break - 读取并整理审稿数据: utils/openreview_processor.py
import jsonlines import pandas as pd class JulyreviewProccessor: def __init__(self, jsonl_path): self.df = self._load_jsonl_to_dataframe(jsonl_path) self.df_sub = pd.DataFrame() def _load_jsonl_to_dataframe(self, jsonl_path): msg_list = [] with open(jsonl_path, 'r', encoding='utf-8') as file: for line_dict in jsonlines.Reader(file): msg_dict = {} for k, v in line_dict['basic_dict'].items(): msg_dict['b_' + k] = v msg_list.append(msg_dict) for review_msg in line_dict["reviews_msg"]: msg_dict_copy = msg_dict.copy() pure_review_msg = { 'r_id': review_msg.get('id', None), 'r_number': review_msg.get('number', None), 'r_replyto': review_msg.get('replyto', None), 'r_invitation': review_msg.get('invitation', None), 'r_signatures': ','.join(review_msg['signatures']) if review_msg.get('signatures', None) else None, 'r_readers': review_msg.get('readers', None), 'r_nonreaders': review_msg.get('nonreaders', None), 'r_writers': review_msg.get('writers', None) } pure_content_msg = {} pure_content_msg['c_content'] = review_msg['content'] for k, v in review_msg['content'].items(): pure_content_msg['c_' + k] = v pure_review_msg.update(pure_content_msg) msg_dict_copy.update(pure_review_msg) msg_list.append(msg_dict_copy) dataframe = pd.DataFrame(msg_list) dataframe['c_final_decision'] = self._fill_decision(dataframe) return dataframe def _fill_decision(self, dataframe): return dataframe['c_decision'].map(lambda x: x if pd.isnull(x) else 'Accepted' if 'accept' in x.lower() else 'Rejected' if 'reject' in x.lower() else "Unknown") def get_sub(self, mode=None): # 仅带有review的df df_sub = self.df.dropna(subset=self.df.filter(regex='^(?!b_*)').columns, how='all') if mode == 'decision': # review类型仅为decision的df df_sub = df_sub[df_sub['r_invitation'].str.contains('Decision')] elif mode == 'other': # review类型仅为非decision的df df_sub = df_sub[~df_sub['r_invitation'].str.contains('Decision')] elif mode == 'accepted': # decision中被采纳的df df_sub = df_sub[df_sub['c_final_decision'].isin(['Accepted'])] elif mode == 'rejected': # decision中未被采纳的df df_sub = df_sub[df_sub['c_final_decision'].isin(['Rejected'])] self.df_sub = df_sub return def get_total_shape(self): return self.df.shape def get_sub_shape(self): return self.df_sub.shape if __name__ == '__main__': orp = JulyreviewProccessor('../total_notes.jsonl') orp.get_sub() print(orp.df_sub.iloc[0])
3.2.2 对论文PDF的解析
考虑到论文是PDF形式的,所以爬取完全部论文PDF之后,下一步就涉及到论文PDF的解析了
从头开始编写PDF解析器是一个耗时且需要反复测试的复杂工作,因此在项目周期较为紧凑的情况下倾向于采用开源的解析器来完成PDF解析工作
关于PDF解析器的选型主要考虑有两点:
- 一是PDF发展时至今日仍有效的解析器;
- 二是期望解析器对解析论文类PDF能有所特化
最终参考了ChatPaper中提及的SciPDF Parser以及ChatPaper项目自身实现的ChatPaper Parser。两种解析器各有优劣
- SciPDF切分的粒度更细,甚至独属于某篇论文的小标题都可以识别出来并且以列表的形式进行返回,内容稍显混乱复杂,但保留了小标题间的顺序关系
- ChatPaper根据文章的title、experiment等重要节点关键词来识别并切分正文,切分的粒度更粗,内容更为统一,但提取出的节点内容没有顺序信息
同时两种解析器也都有没法完美识别的地方(比如PDF的title、abstract会因识别不出而为空)。考虑到文本顺序对模型具有指导意义,最终使用上文分析过的SciPDF Parser进行解析
具体代码如下(scipdf_parser.py)
import scipdf
import argparse
from pathlib import Path
import json
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
parser = argparse.ArgumentParser()
parser.add_argument("--dir_path", type=str, default=None, help="The path of the folder about paper pdf.")
args = parser.parse_args()
org_dir_path = Path(args.dir_path).resolve()
trg_dir_path = org_dir_path.with_name("scipdf_parser_results")
error_log = {}
if not trg_dir_path.exists():
trg_dir_path.mkdir()
for pdf_file in tqdm(org_dir_path.glob("*.pdf")):
trg_path = trg_dir_path.joinpath(pdf_file.name).with_suffix(".json")
if trg_path.exists():
continue
try:
article_dict = scipdf.parse_pdf_to_dict(str(pdf_file)) # return dictionary
with open(trg_path, "w") as f:
json.dump(article_dict, f)
except Exception as e:
error_log[str(pdf_file.name)] = str(e)
continue
error_log_path = trg_dir_path.with_name("error_log_scipdf.json")
with open(error_log_path, "w") as fe:
json.dump(error_log, fe)举个例子,针对下面这篇论文

解析后的论文数据如下
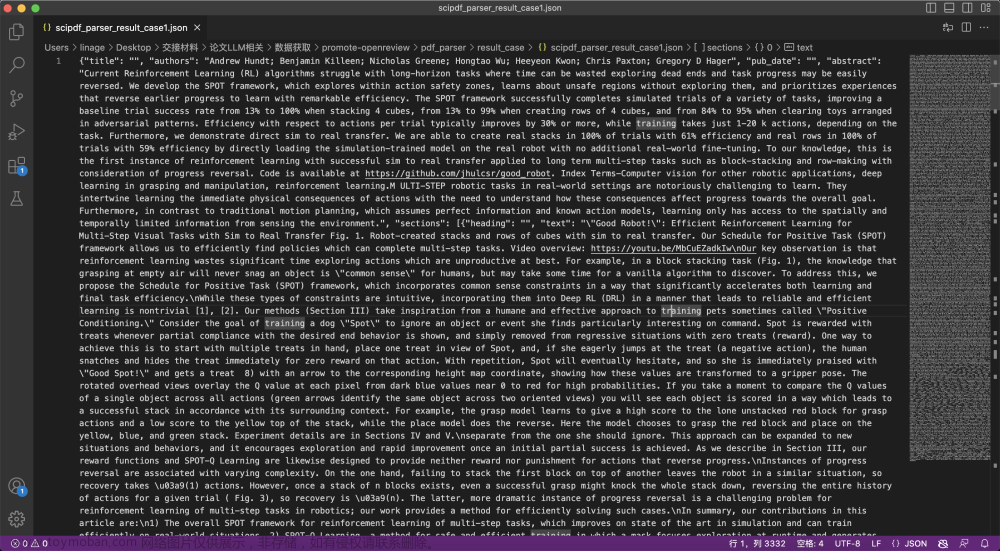
最终,下图是解析后的数据集情况

相当于数据形式分为input和output,其中input为paper数据,output为review数据,其中
- paper数据
原共有30380条paper数据,去除有损文件后解析得到30176条paper数据 - review数据
原共有122892条review数据
对于这个数据集而言,“paper-review”是天然的QA对形式数据,无需借助其他工具构成QA对; 内容专业倾向强,属于领域优质数据,无需采用self-instruct等方法进行专家角色扩写、续写等额外操作; 数据清洗的角度更多在于具体的文本内部,如剔除无效信息等
3.2.3 数据处理:去重、去除无关项/长尾内容/极端项、剔除无效信息
之后做了一系列数据处理,如下图所示,最终得到的paper数从30176变为22966,review数从122892变为106271,数据量虽然变少了,但质量提高了许多
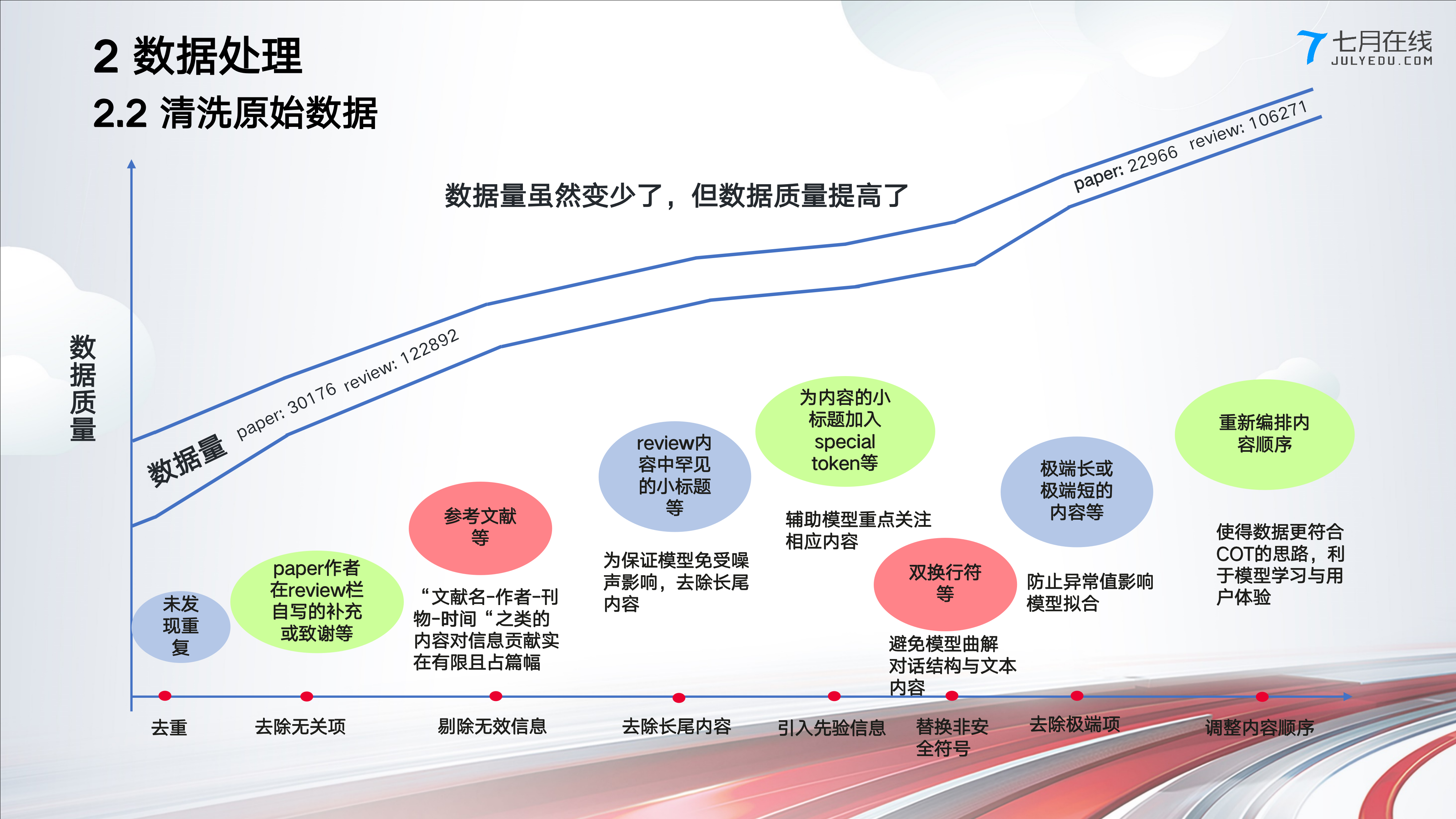
至于上图中各种数据处理如何写代码实现,以及各种细节问题,暂在七月的「大模型项目开发线上营」中见
3.2.4 组织训练格式:单轮与多轮
3.2.4.1 单轮数据组织
当前已设计的数据组织格式如下,需将文本根据该数据格式进行处理:
User: please reivew this paper or give some sugguestion
Assistant: ok, please provide detailed infomation or provide paper to review
User: this is paper/content :\n{paper}
Assistant: this is review/suggestion:\n{reivew}将paper和review内容填入相应的部分,其中paper的文本内容还可进一步细分为“title: xxxx, abstract: xxxxx, keyword: xxxxx, main: xxxxxxx”,需将paper文本进一步处理成相关的subtitle格式,使得模型更容易辨析相关部分
3.2.4.2 多轮数据组织
当前已设计的数据组织格式如下,需将文本根据该数据格式进行处理:
User: please reivew this paper or give some sugguestion.
Assistant: ok, please provide detailed infomation or provide paper to review.
User: this is paper:\n{paper}
Assistant: this is review/suggestion:\n{reivew1}
User: Any more?
Assistant: this is some more review/suggestion:\n{reivew2}
User: Any more?
Assistant: this is some more review/suggestion:\n{reivew3}
...现有的数据是多是单paper对应多review的情况「如{paperA-reviewA1, paperA-reviewA2, paperA-reviewA3, ...}, {paperB-reviewB1, paperB-reviewB2, ..}, ...」,考虑能否设计成使用类似“Any more suggestions?”表达希求更多的句子引出另一篇review的多轮场景,其中“希求更多的问句”可以考虑使用ChatGPT来进行同义问句扩充。
至于训练数据的存储,可以是以 jsonl 格式存储组织好的数据
3.3 Q3第1版之模型的选型、微调:基于RWKV
3.3.1 模型的选型:RWKV PK LLaMA2
在我们得到处理好的数据之后,有3类模型 选择
- LLaMA2
Llama2 虽于23年7月份便已推出,但其上下文长度不够(仅4K)
当然,第二版会尝试LLaMA2-long,LongAlpaca - RWKV
之所以第一版选用这个RWKV,原因在于23年Q3时的长上下文解决方案比较罕见,经典Transformer对16k的长度支持需要耗费很大的资源,而RNN的结构训练和推理占用相对比较便宜(或者说线性Transformer结构占用恒定)
关于什么是RWKV,详见此文《一文通透想颠覆Transformer的Mamba:从SSM、S4到mamba、线性transformer(含RWKV解析)》的3.2节,或RWKV GitHub、RWKV Wiki
关于如何基于RWKV微调,可以用这个RWKV微调库:RWKV-infctx-trainer (for training arbitary context sizes, to 10k and beyond)
但缺点是对于论文这种带有密集知识点的对象而言,遗忘机制比较严重,故最终效果不达预期 - ChatGPT的微调接口,不过其开放的微调接口的上下文长度,截止到10月底暂只有4K
(当然,2023年11.6日,OpenAI在其举办的首届开发者大会上,宣布开放GPT3.5 16K的微调接口)
3.3.2 模型的具体训练
以下是训练的一些细节
- 所用GPU:用了8块A800
- 训练时间:4天左右
3.4 针对推理数据的处理与最终推理:给定paper,让训练好的模型输出审稿意见
3.4.1 推理数据处理-主要针对paper
Paper内容主要被明确划分为了3部分:
- Title:论文标题
- Abstract:论文摘要
- Main:论文正文,包括Introduction、Methodology、Conclusion等内容
故可依赖3种途径接收用户传入的Paper内容:
- 纯解析:预留上传框支持用户上传论文的PDF,使用SciPDF解析出Title、Abstract以及Main(其他部分)
- 纯输入:预留输入框支持用户手动输入论文的Title、Abstract以及Main(其他部分)
- 输入+解析(推荐):预留上述两者,鼓励用户手动输入Title和Abstract,并同时上传论文PDF文件,这样设计是考虑到解析器可能无法准确解析出Title和Abstract,通过用户手动输入来获取Title和Abstract即可,故最终Paper文本的Title和Abstract以用户输入为准、Main以解析为准
3.4.2 RWKV-light推理
相关代码的具体实现,暂在七月的大模型项目开发线上营中见
总之,我们在第一版中,做了以下三件事文章来源:https://www.toymoban.com/news/detail-648112.html
- 爬取了3万多篇paper、十几万的review数据,并对3万多篇PDF形式的paper做解析(review数据爬下来之后就是文本数据,不用做解析)
当然,paper中有被接收的、也有被拒绝的 - 为提高数据质量,针对paper和review做了一系列数据处理
当然,主要是针对review数据做处理 - 基于RWKV进行微调,然因其遗忘机制比较严重,故最终效果不达预期
所以我们后续马上开始做论文审稿GPT第二版:《七月论文审稿GPT第2版:用一万多条paper-review数据集微调LLaMA2最终反超GPT4》,再更多则暂在七月的「大模型项目开发线上营」中见文章来源地址https://www.toymoban.com/news/detail-648112.html
到了这里,关于学术论文GPT源码解读:从chatpaper、chatwithpaper到gpt_academic的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!