diskqueue是nsq消息持久化的核心,内容较多,故分为多篇
1. diskqueue第一篇 - 是什么,为什么需要它,整体架构图,对外接口
2. diskqueue第二篇 - 元数据文件,数据文件,启动入口,元数据文件的读写及保存
3. diskqueue第三篇 - 数据定义详解,运转核心ioloop()源码详解
4. diskqueue第四篇 - 怎么写入消息,怎么对外发送消息
5. diskqueue第五篇 - 追尾检测,错误处理,如何正常关闭
6. diskqueue第六篇 - 如何使用diskqueue
一、diskqueue是什么,为什么需要它
在nsq中消息主要存在于两种队列
一种是内存队列,内部是用go的通道实现,所以处理速度很快,缺点是一旦nsqd进程挂掉消息就真的丢失了,这让人难以接受,数据丢了不得被用户骂死?
一种是持久化队列,内部实现是把消息保存在磁盘文件中,即使nsqd进程突然挂掉或者物理服务器重启,但是文件仍然存在,只需重启nsqd进程即可,nsqd进程启动时会重新从文件中加载消息然后再进行投递。可以说,持久化队列是nsq能保证消息可靠投递的重要原因之一
贴出来源码,给大家看下nsqd中的两种队列,以Topic举例,文件在nsq/nsqd/topic.go(已加注释)
type Topic struct {
// 省略无关代码......
backend BackendQueue // 持久化队列
memoryMsgChan chan *Message // 内存中的消息队列
// 省略无关代码......
}字段 memoryMsgChan 即内存队列,使用go语言的chan来实现,内部元素为Message,也就是消息对象
字段 backend 即持久化队列,类型为BackendQueue,是接口类型,每个人可以提供自己喜欢的实现。nsq作者为该接口实现的是diskqueue包,就是我们接下来两篇博客要详细讲的了
二、diskqueue地址
可能基于替换性考虑,也为了把diskqueue包提供给有数据持久化需求的人用,nsq作者并没有把代码嵌入到nsq中,而是把disqueue做成了一个独立的包,大家可以很方便地嵌入到自己的项目中
官方github地址为:GitHub - nsqio/go-diskqueue: A Go package providing a filesystem-backed FIFO queue
建议大家下载下来,边看博客,边看代码,这样效率更高
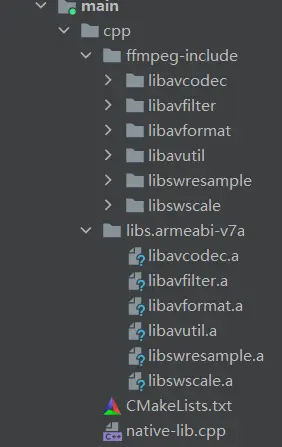
三、代码目录
大家先看下diskqueue的整体代码,有个感觉,如下图
整个包只有两个有用的文件,
diskqueue.go 这个文件是整个diskqueue的实现代码
diskqueue_test.go 这个文件是对diskqueue的测试代码
四、diskqueue整体实现流程
有的博客一上来直接对着源码一通讲,连diskqueue是什么,做什么用,整体实现都没讲,让人看得云里雾里,这样效果很差。为了让大家更好更快地理解diskqueue的实现,我专门画了它的架构图和实现流程,大家可以先了解下它的整体结构,如下图
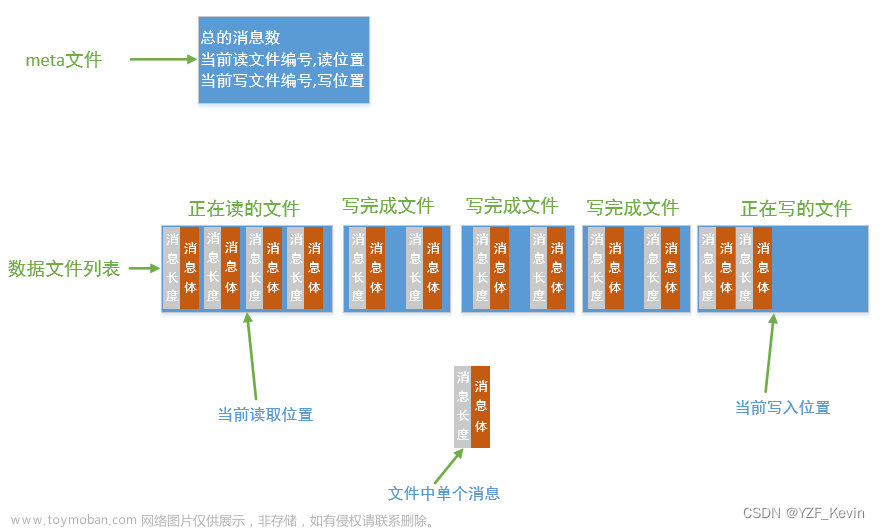
对上面模型图解释下:
1. diskqueue为每个队列保存一份meta文件(以.meta结尾),这个文件一共就3行,描述了队列的整体信息(第一行:总的消息数,第二行:当前读文件编号,读位置,第三行:当前写文件编号,写位置)
2. diskqueue把队列的消息保存在了一个或多个数据文件(以.dat结尾)中,单个文件写入达到最大限值就新创建一个,比如某个topic的名字为TestTopic,那么最终文件名字格式如下
TestTopic.diskqueue.000001.dat
TestTopic.diskqueue.000002.dat
TestTopic.diskqueue.000003.dat
即前面是topic的名字,最后是文件编号从1开始增加
3. 这些消息文件组成了一个单向的消息队列,前面在接收写入,后面在读取处理,处理结束的文件就删掉,这也就是为什么diskqueue可以宣称自己是FIFO的持久化队列,因为确实是队列的处理模型
4. 单个消息的格式:前面4个字节表消息体大小,后面是消息体的数据。单个文件内所有消息按数组的格式紧密排列,虽然上面图中两个消息之间有空隙,这只是方便大家看,实际是紧挨着的
5. 队列头是正在写的文件,队列尾是正在读的文件
如果写快读慢,那文件队列长度就会一直增长
如果写慢读快,那最终会读的位置等于写的位置,像汽车追尾一样
6. nsq给每个消息文件限制最大为100M,但也有可能写入了99.97M的时候,再尝试写消息时发现若写了就超过文件最大限制,这个时候只能新创建文件,旧文件最终只保存了99.97M的数据。所以一个文件最终可读多少字节,要以文件的实际大小为准
五、接口介绍
diskqueue的对外接口没几个,我用的代码取自官方github,日期2023/08/08,如下(已添加注释)
// 持久化队列的所有接口,在nsq中该接口名为BackendQueue,下面的diskQueue会实现这些接口
type Interface interface {
Put([]byte) error // 向队列中存一个消息
ReadChan() <-chan []byte // 获取一个无缓冲的只读通道(真正弹出了消息),外部使用者可以多协程读取处理
PeekChan() <-chan []byte // 获取一个无缓冲的只读通道(本通道仅查看,并不算弹出消息),外部使用者可以多协程读取处理
Close() error // 关闭队列(退出,有保存数据)
Delete() error // 删除队列(退出,无保存数据,注意本函数并不是真正删除消息或文件,仅仅是退出。所以想真正删除数据时需先调用Empty()再调用Delete())
Depth() int64 // 当前未处理的消息数
Empty() error // 清空队列(删除所有文件)
}一共只有7个函数,我已经写了详细的注释,这里介绍下几个特别要注意的:
Put() : 新写进一个消息,立刻有结果
ReadChan() : 获取只读通道,只要还有消息,就能从该通道读消息,没有消息时该通道为nil
Empty() : 清空队列
Delete() : 无保存退出,并非真正的删除,函数名有点坑人啊
特别切记:如果想删除某个队列,必须先调用Empty()再调用Delete()
nsq中就是这样做的,无论是删除topic还是删除channel,对于持久化队列的处理都是先调用Empty()再调用Delete()
redis代码举例:删除topic时会调用Delete()函数,如下(已添加注释)
// 删除topic的处理(先清空所有队列,channel中的队列,再执行删除)
func (t *Topic) Delete() error {
return t.exit(true)
}也就是调用了t.exit()函数,exit()如下(已添加注释)
// topic删除/关闭的处理
// deleted : true表删除topic,false表nsqd正常关闭
func (t *Topic) exit(deleted bool) error {
// 省略无关代码......
// 删除topic
if deleted {
t.Lock()
for _, channel := range t.channelMap { // 删除本topic下的所有channel
delete(t.channelMap, channel.name)
channel.Delete()
}
t.Unlock()
// 清空队列(内存队列,调用bckend.Empty())
t.Empty()
return t.backend.Delete() // 再删除持久化队列
}
// 省略无关代码......
}可以看到exit()函数中判断deleted为true时,
1. 对该topic下的所有channel执行Delete()
2. 再执行Empty(),该函数会对持久化队列backend执行Empty()
3. 最后对backend执行Delete()
所以大家要谨记:如果想删除某个队列,必须先调用Empty()再调用Delete()
好了,这篇博客大家先对diskqueue有个整体印象,了解其实现原理。下一篇博客我们会从源码角度进行分析diskqueue是如何实现的,它是怎么维持FIFO队列的,有哪些要注意的点等等文章来源:https://www.toymoban.com/news/detail-648567.html
diskqueue的元数据文件,数据文件,启动入口,元数据文件读写和保存_YZF_Kevin的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-648567.html
到了这里,关于nsq中diskqueue详解 - 第一篇的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!