G1(Garbage First)收集器 (标记-整理算法): Java堆并行收集器,G1收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆(包括新生代,老年代),而其他收集器回收的范围仅限于新生代或老年代。
G1(Garbage First)收集器 (标记-整理算法): Java堆并行收集器,G1收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。此外,G1收集器不同于之前的收集器的一个重要特点是:G1回收的范围是整个Java堆(包括新生代,老年代),而其他收集器回收的范围仅限于新生代或老年代。
-XX:+UseG1GC -Xmx32g -XX:MaxGCPauseMillis=200
其中,-XX:+UseG1GC用于开启 G1 垃圾收集器,-Xmx32g用于设置堆内存的最大内存为 32G,-XX:MaxGCPauseMillis=200用于设置 GC 的最大暂停时间为 200ms。如果我们需要调优,在内存大小一定的情况下,我们只需要修改最大暂停时间即可。
关键字
LAB
由于分区的思想,每个线程均可以"认领"某个分区用于线程本地的内存分配,而不需要顾及分区是否连续。因此,每个应用线程和GC线程都会独立的使用分区,进而减少同步时间,提升GC效率,这个分区称为本地分配缓冲区(Lab)。
TLAB
应用线程可以独占一个本地缓冲区(TLAB)来创建的对象,而大部分都会落入Eden区域(巨型对象或分配失败除外),因此TLAB的分区属于Eden空间;
GCLAB
每次垃圾收集时,每个GC线程同样可以独占一个本地缓冲区(GCLAB)用来转移对象,每次回收会将对象复制到Suvivor空间或老年代空间;
PLAB
对于从Eden/Survivor空间晋升(Promotion)到Survivor/老年代空间的对象,同样有GC独占的本地缓冲区进行操作,该部分称为晋升本地缓冲区(PLAB)。
G1堆内存结构
堆内存中一个区域 (Region) 的大小,可以通过 -XX:G1HeapRegionSize 参数指定,大小区间最小 1M 、最大 32M ,总之是 2 的幂次方。
默认是将堆内存按照 2048 份均分。
每个 Region 被标记了 E、S、O 和 H,这些区域在逻辑上被映射为 Eden,Survivor 和老年代。
存活的对象从一个区域转移(即复制或移动)到另一个区域。区域被设计为并行收集垃圾,可能会暂停所有应用线程。
此外,还有第四种类型,被称为巨型区域(Humongous Region)。
G1中的region的大小,由参数G1HeapRegionSize定义,如果没有定义,就由xms/2048计算region大小,如果小于1就取1,如果大于32就取32,如果是其他值,就取2,4,8,16相近的数值,总之是2的n次方。
G1中的region的数量不一定是2048,如果内存小于2G,每个region最小为1M,那么数量就小于2048,比如内存超过64g,每个region最大为32M,那么数量也就超过2048,例如,128g,那么region数量就为4096个。
巨形对象Humongous Region
存储超过 50% 标准 region 大小的对象称为巨型对象(Humongous Object)。当线程为巨型分配空间时,不能简单在TLAB进行分配,因为巨型对象的移动成本很高,而且有可能一个分区不能容纳巨型对象。因此,巨型对象会直接在老年代分配,所占用的连续空间称为巨型分区(Humongous Region)。G1内部做了一个优化,一旦发现没有引用指向巨型对象,则可直接在年轻代收集周期中被回收。
巨型对象会独占一个、或多个连续分区,其中第一个分区被标记为开始巨型(StartsHumongous),相邻连续分区被标记为连续巨型(ContinuesHumongous)。由于无法享受Lab带来的优化,并且确定一片连续的内存空间需要扫描整堆,因此确定巨型对象开始位置的成本非常高,如果可以,应用程序应避免生成巨型对象。
如果一个 H 区装不下一个巨型对象,那么 G1 会寻找连续的 H 分区来存储。为了能找到连续的 H 区,有时候不得不启动 Full GC 。
Remember Set:
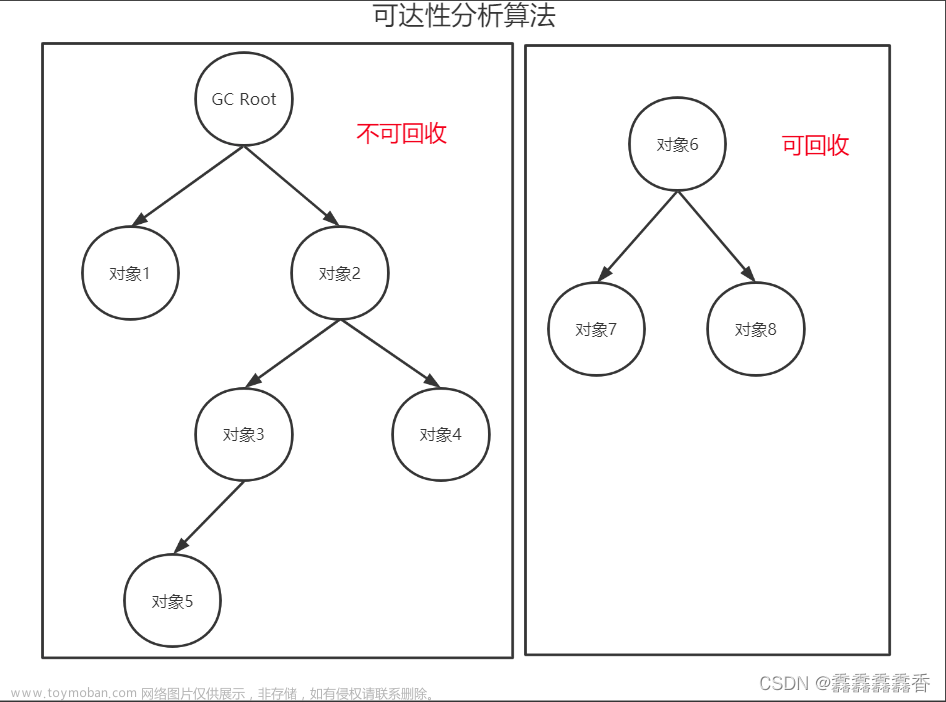
在串行和并行收集器中,GC时是通过整堆扫描来确定对象是否处于可达路径中。然而G1为了避免STW式的整堆扫描,为每个分区各自分配了一个 RSet(Remembered Set),它内部类似于一个反向指针,记录了其它 Region 对当前 Region 的引用情况,这样就带来一个极大的好处:回收某个Region时,不需要执行全堆扫描,只需扫描它的 RSet 就可以找到外部引用,来确定引用本分区内的对象是否存活,进而确定本分区内的对象存活情况,而这些引用就是 initial mark 的根之一。
事实上,并非所有的引用都需要记录在RSet中,如果引用源是本分区的对象,那么就不需要记录在 RSet 中;同时 G1 每次 GC 时,所有的新生代都会被扫描,因此引用源是年轻代的对象,也不需要在RSet中记录;所以最终只需要记录老年代到新生代之间的引用即可。
RSet 的写屏障
写屏障是指,每次 Reference 引用类型在执行写操作时,都会产生 Write Barrier 写屏障暂时中断操作并额外执行一些动作。
对写屏障来说,过滤掉不必要的写操作是十分有必要的,因为写栅栏的指令开销是十分昂贵的,这样既能加快赋值器的速度,也能减轻回收器的负担。G1 收集器的写屏障是跟 RSet 相辅相成的,产生写屏障时会检查要写入的引用指向的对象是否和该 Reference 类型数据在不同的 Region,如果不同,才通过 CardTable 把相关引用信息记录到引用指向对象的所在 Region 对应的 RSet 中,通过过滤就能使 RSet 大大减少。
(1)写前栅栏:即将执行一段赋值语句时,等式左侧对象将修改引用到另一个对象,那么等式左侧对象原先引用的对象所在分区将因此丧失一个引用,那么JVM就需要在赋值语句生效之前,记录丧失引用的对象。但JVM并不会立即维护RSet,而是通过批量处理,在将来RSet更新
(2)写后栅栏:当执行一段赋值语句后,等式右侧对象获取了左侧对象的引用,那么等式右侧对象所在分区的RSet也应该得到更新。同样为了降低开销,写后栅栏发生后,RSet也不会立即更新,同样只是记录此次更新日志,在将来批量处理
G1垃圾回收器进行垃圾回收时,在GC根节点枚举范围加入RSet,就可以保证不进行全局扫描,也不会有遗漏。另外JVM使用的其余的分代的垃圾回收器也都有写屏障,举例来说,每次将一个老年代对象的引用修改为指向年轻代对象,都会被写屏障捕获并记录下来,因此在年轻代回收的时候,就可以避免扫描整个老年代来查找根。
G1的垃圾回收器的写屏障使用一种两级的log buffer结构:
global set of filled buffer:所有线程共享的一个全局的,存放填满了的log buffer的集合文章来源:https://www.toymoban.com/news/detail-649278.html
thread log buffer:每个线程自己的log buffer。所有的线程都会把写屏障的记录先放进去自己的log buffer中,装满了之后,就会把log buffer放到 global set of filled buffer中,而后再申请一个log buffer;文章来源地址https://www.toymoban.com/news/detail-649278.html
到了这里,关于JVM G1垃圾回收机制介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!