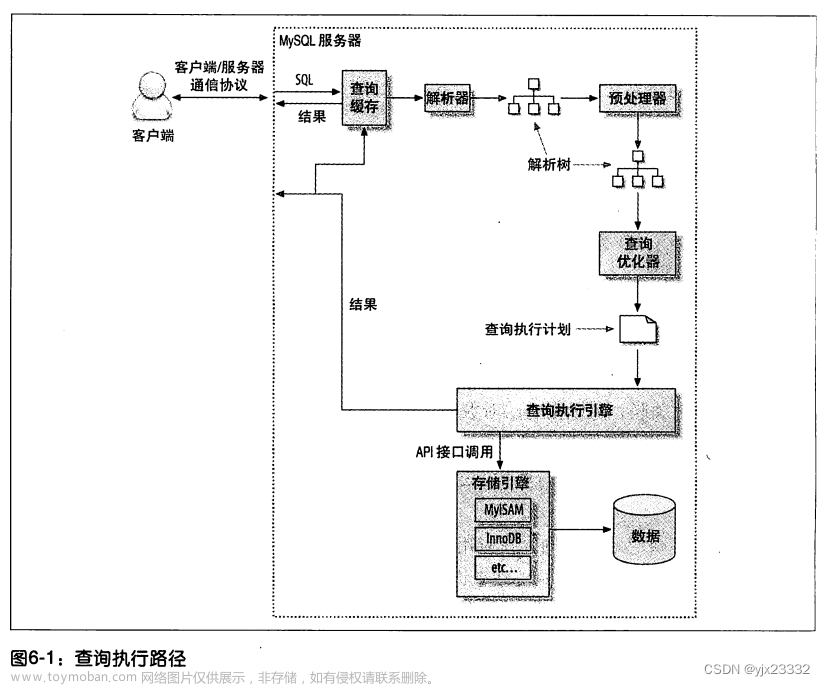
文章来源地址https://www.toymoban.com/news/detail-650169.html
文章来源地址https://www.toymoban.com/news/detail-650169.html
1. 事务日志
1.1. 事务日志有助于提高事务的效率
1.1.1. 存储引擎只需要更改内存中的数据副本,而不用每次修改磁盘中的表,这会非常快
1.1.2. 更改的记录写入事务日志中,事务日志会被持久化保存在硬盘上
1.2. 事务日志采用的是追加写操作,是在硬盘中一小块区域内的顺序I/O,而不是需要写多个地方的随机I/O,所以写入事务日志是一种相对较快的操作
1.3. 大多数使用这种技术(write-ahead logging,预写式日志)的存储引擎修改数据最终需要写入磁盘两次
1.4. 如果修改操作已经写入事务日志,那么即使系统在数据本身写入硬盘之前发生崩溃,存储引擎仍可在重新启动时恢复更改
2. MySQL中的事务
2.1. 自动提交模式
2.1.1. AUTOCOMMIT
2.1.2. 通过禁用此模式,可以在事务中执行一系列语句,并在结束时执行COMMIT提交事务或ROLLBACK回滚事务
2.2. 可以使用SET命令设置AUTOCOMMIT变量来启用或禁用自动提交模式
2.2.1. 启用可以设置为1或者ON
2.2.2. 禁用可以设置为0或者OFF
2.3. AUTOCOMMIT=0,则当前连接总是会处于某个事务中,直到发出COMMIT或者ROLLBACK,然后MySQL会立即启动一个新的事务
2.4. 除了在禁用AUTOCOMMIT的事务中可以使用之外,其他任何时候都不要显式地执行LOCK TABLES,不管使用的是什么存储引擎
2.5. 执行SET TRANSACTION ISOLATION LEVEL命令来设置隔离级别
2.5.1. 新的隔离级别会在下一个事务开始的时候生效
2.5.2. 最好在服务器级别设置最常用的隔离,并且只在显式情况下修改
2.6. MySQL不在服务器层管理事务,事务是由下层的存储引擎实现的
2.6.1. 在同一个事务中,混合使用多种存储引擎是不可靠的
2.6.2. 为每张表选择合适的存储引擎,并不惜一切代价避免在应用中混合使用存储引擎是非常重要的
2.6.3. 在非事务表中执行事务相关操作的时候,MySQL通常不会发出提醒,也不会报错
2.6.4. 最好不要在应用程序中混合使用存储引擎
2.6.4.1. 失败的事务可能导致不一致的结果,因为某些部分可以回滚,而其他部分不能回滚
2.7. InnoDB使用两阶段锁定协议
2.7.1. two-phase locking protocol
2.7.2. 在事务执行期间,随时都可以获取锁
2.7.3. 但锁只有在提交或回滚后才会释放,并且所有的锁会同时释放
2.8. InnoDB还支持通过特定的语句进行显式锁定
2.8.1. 不属于SQL规范
2.9. 支持LOCK TABLES和UNLOCK TABLES命令,这些命令在服务器级别而不在存储引擎中实现
2.10. 应该使用支持事务的存储引擎
2.10.1. InnoDB支持行级锁,所以没必要使用LOCKTABLES
3. 多版本并发控制
3.1. MVCC
3.2. 行级锁的一个变种
3.2.1. 在很多情况下避免了加锁操作,因此开销更低
3.2.2. 不仅实现了非阻塞的读操作,写操作也只锁定必要的行
3.3. Undo日志写入是服务器崩溃恢复过程的一部分,并且是事务性的
3.3.1. 所有Undo日志写入也都会写入Redo日志
3.3.2. Redo日志和Undo日志的大小也是高并发事务工作机制中的重要影响因素
3.4. 仅适用于REPEATABLE READ和READ COMMITTED隔离级别
3.5. READ UNCOMMITTED与MVCC不兼容
3.5.1. 查询不会读取适合其事务版本的行版本,而是不管怎样都读最新版本
3.6. SERIALIZABLE与MVCC也不兼容
3.6.1. 读取会锁定它们返回的每一行
4. 复制
4.1. 一种原生方式来将一个节点执行的写操作分发到其他节点
4.2. 对于在生产环境中运行的任何数据,都应该使用复制并至少有三个以上的副本
4.3. 理想情况下应该分布在不同的地区(在云托管环境中,称为region)用于灾难恢复计划
5. 数据文件结构
5.1. 在8.0版本中
5.1.1. 将表的元数据重新设计为一种数据字典
5.1.1.1. 在表的.ibd文件中
5.1.1.2. 减少了I/O,非常高效
5.1.2. 删除了基于文件的表元数据存储
5.2. 引入了字典对象缓存
5.2.1. 基于最近最少使用(LRU)的内存缓存
5.2.1.1. 分区定义
5.2.1.2. 表定义
5.2.1.3. 存储程序定义
5.2.1.4. 字符集
5.2.1.5. 排序信息
5.2.2. 当前访问最活跃的那些表,在缓存中最常出现
5.2.2.1. 每个表的.ibd和.frm文件被替换为已经被序列化的字典信息(.sdi)
5.3. 原子DDL
5.3.1. MySQL 8.0引入了原子数据定义更改
5.3.2. 数据定义语句现在要么全部成功完成,要么全部失败回滚
6. InnoDB引擎
6.1. MySQL主要的改进核心在于InnoDB的演进
6.1.1. 表元数据、用户认证、身份鉴权这些内部统计信息的管理也已经调整为使用InnoDB表来实现
6.2. MySQL的默认事务型存储引擎
6.2.1. 现在已经成为金标准,是推荐使用的引擎
6.2.2. 最重要、使用最广泛的引擎
6.2.3. 为处理大量短期事务而设计的,这些事务通常是正常提交的,很少会被回滚
6.2.4. 几乎能覆盖每一种使用场景
6.3. 最佳实践是使用InnoDB存储引擎作为所有应用程序的默认引擎
6.4. 将数据存储在一系列的数据文件中,这些文件统被称为表空间(tablespace)
6.4.1. 表空间本质上是一个由InnoDB自己管理的黑盒
6.5. 使用MVCC来实现高并发性,并实现了所有4个SQL标准隔离级别
6.5.1. 默认为REPEATABLE READ隔离级别
6.5.2. 通过间隙锁(next-key locking)策略来防止在这个隔离级别上的幻读
6.5.2.1. 不只锁定在查询中涉及的行,还会对索引结构中的间隙进行锁定,以防止幻行被插入
6.6. InnoDB表是基于聚簇索引构建的
6.6.1. 聚簇索引提供了非常快速的主键查找
6.7. 通过一些机制和工具支持真正的在线“热”备份
6.7.1. Oracle专有的MySQL Enterprise Backup
6.7.2. 开源的Percona XtraBackup
6.8. 引入了SQL函数来支持在JSON文档上的丰富操作
文章来源:https://www.toymoban.com/news/detail-650169.html
到了这里,关于读高性能MySQL(第4版)笔记02_MySQL架构(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!