Unity 工具 之 Azure 微软SSML语音合成TTS流式获取音频数据的简单整理
目录
Unity 工具 之 Azure 微软SSML语音合成TTS流式获取音频数据的简单整理
一、简单介绍
二、实现原理
三、实现步骤
四、关键代码
一、简单介绍
Unity 工具类,自己整理的一些游戏开发可能用到的模块,单独独立使用,方便游戏开发。
本节介绍,这里在使用微软的Azure 进行语音合成的两个方法的做简单整理,这里简单说明,如果你有更好的方法,欢迎留言交流。
语音合成标记语言 (SSML) 是一种基于 XML 的标记语言,可用于微调文本转语音输出属性,例如音调、发音、语速、音量等。 与纯文本输入相比,你拥有更大的控制权和灵活性。
可以使用 SSML 来执行以下操作:
- 定义输入文本结构,用于确定文本转语音输出的结构、内容和其他特征。 例如,可以使用 SSML 来定义段落、句子、中断/暂停或静音。 可以使用事件标记(例如书签或视素)来包装文本,这些标记可以稍后由应用程序处理。
- 选择语音、语言、名称、样式和角色。 可以在单个 SSML 文档中使用多个语音。 调整重音、语速、音调和音量。 还可以使用 SSML 插入预先录制的音频,例如音效或音符。
- 控制输出音频的发音。 例如,可以将 SSML 与音素和自定义词典配合使用来改进发音。 还可以使用 SSML 定义单词或数学表达式的具体发音。
下面是 SSML 文档的基本结构和语法的子集:
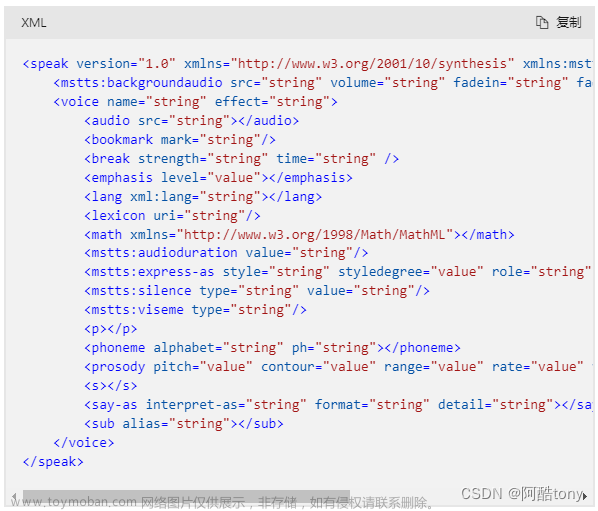
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="string"> <mstts:backgroundaudio src="string" volume="string" fadein="string" fadeout="string"/> <voice name="string" effect="string"> <audio src="string"></audio> <bookmark mark="string"/> <break strength="string" time="string" /> <emphasis level="value"></emphasis> <lang xml:lang="string"></lang> <lexicon uri="string"/> <math xmlns="http://www.w3.org/1998/Math/MathML"></math> <mstts:audioduration value="string"/> <mstts:express-as style="string" styledegree="value" role="string"></mstts:express-as> <mstts:silence type="string" value="string"/> <mstts:viseme type="string"/> <p></p> <phoneme alphabet="string" ph="string"></phoneme> <prosody pitch="value" contour="value" range="value" rate="value" volume="value"></prosody> <s></s> <say-as interpret-as="string" format="string" detail="string"></say-as> <sub alias="string"></sub> </voice> </speak>SSML 语音和声音
语音合成标记语言 (SSML) 的语音和声音 - 语音服务 - Azure AI services | Microsoft Learn
官网注册:
面向学生的 Azure - 免费帐户额度 | Microsoft Azure
官网技术文档网址:
技术文档 | Microsoft Learn
官网的TTS:
文本转语音快速入门 - 语音服务 - Azure Cognitive Services | Microsoft Learn
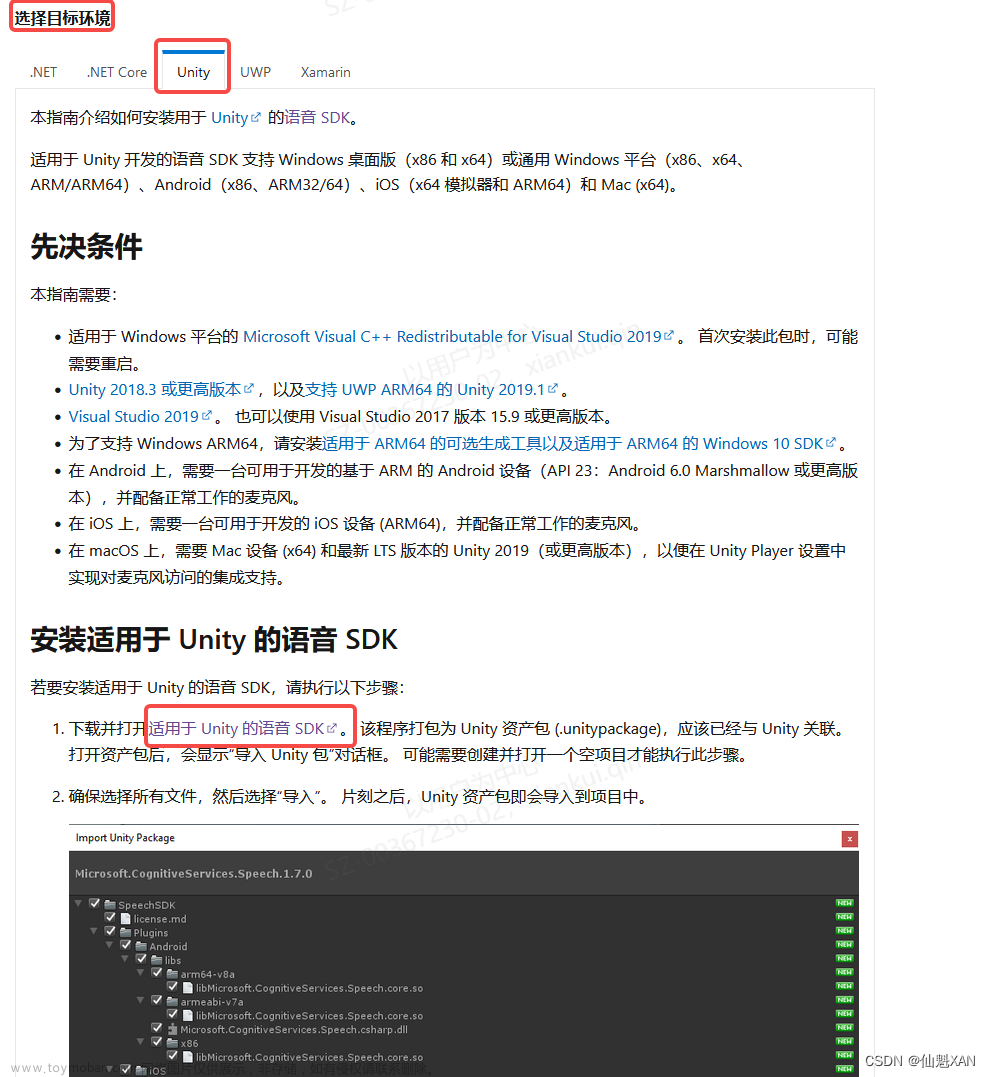
Azure Unity SDK 包官网:
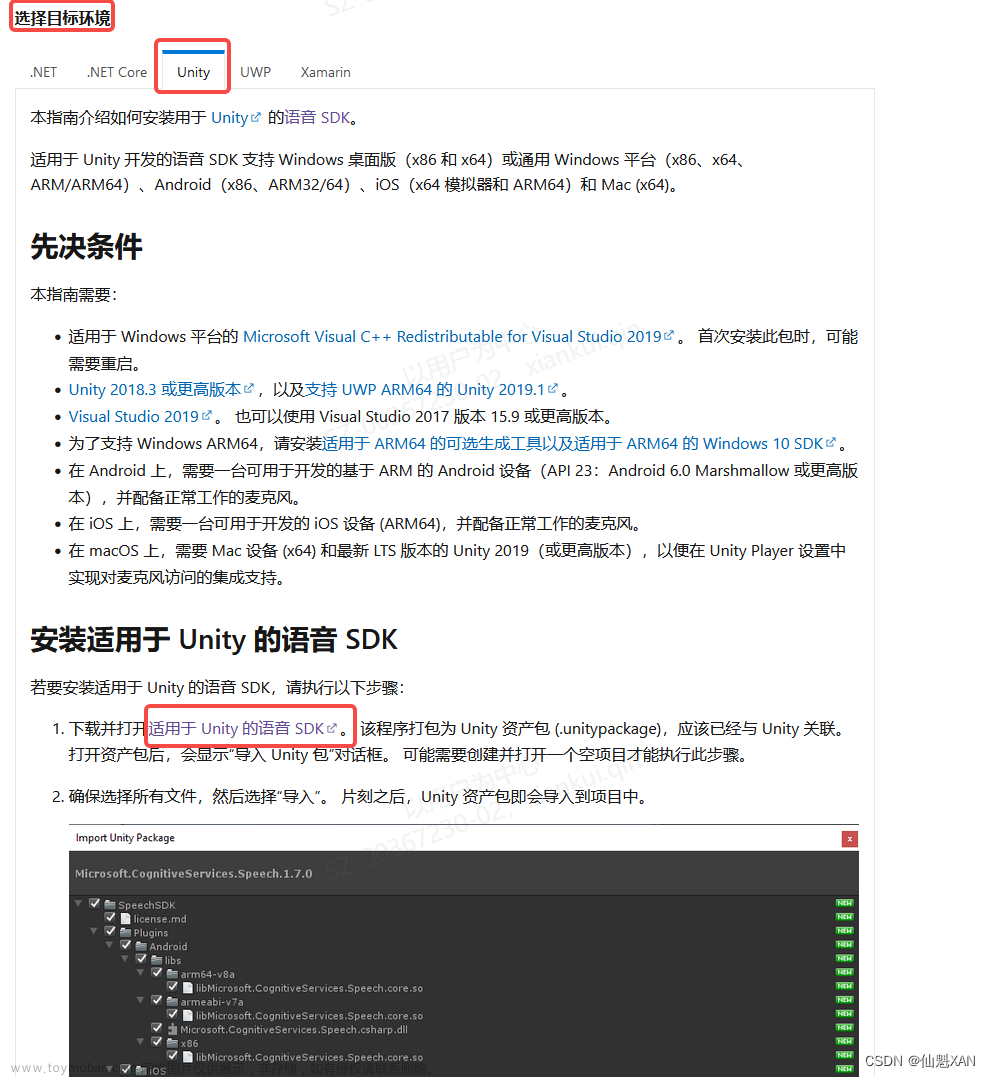
安装语音 SDK - Azure Cognitive Services | Microsoft Learn
SDK具体链接:
https://aka.ms/csspeech/unitypackage
二、实现原理
1、官网申请得到语音合成对应的 SPEECH_KEY 和 SPEECH_REGION
2、然后对应设置 语言 和需要的声音 配置
3、使用 SSML 带有流式获取得到音频数据,在声源中播放或者保存即可,样例如下
public static async Task SynthesizeAudioAsync()
{
var speechConfig = SpeechConfig.FromSubscription("YourSpeechKey", "YourSpeechRegion");
using var speechSynthesizer = new SpeechSynthesizer(speechConfig, null);
var ssml = File.ReadAllText("./ssml.xml");
var result = await speechSynthesizer.SpeakSsmlAsync(ssml);
using var stream = AudioDataStream.FromResult(result);
await stream.SaveToWaveFileAsync("path/to/write/file.wav");
}三、实现步骤
基础的环境搭建参照:Unity 工具 之 Azure 微软语音合成普通方式和流式获取音频数据的简单整理_unity 语音合成
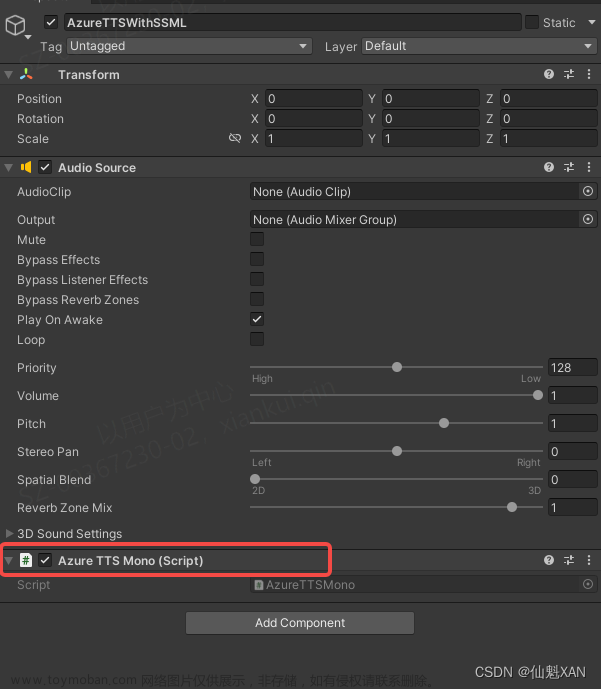
1、脚本实现,挂载对应脚本到场景中
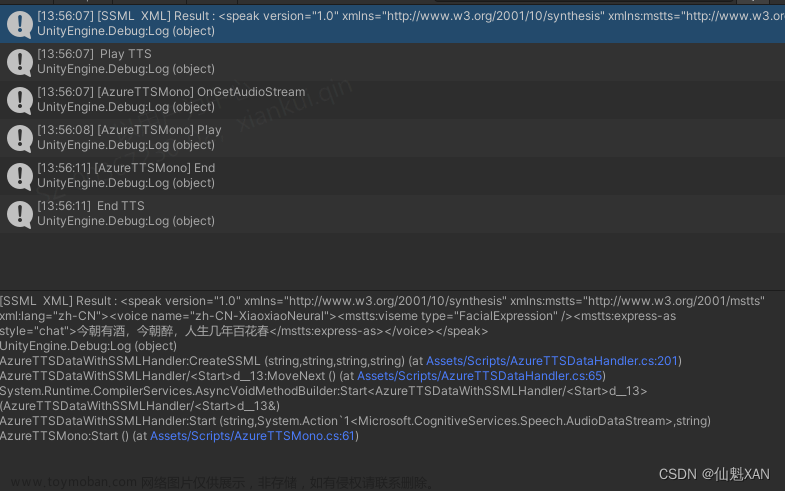
2、运行场景,会使用 SSML方式合成TTS,并播放
四、关键代码
1、AzureTTSDataWithSSMLHandler文章来源:https://www.toymoban.com/news/detail-650248.html
using Microsoft.CognitiveServices.Speech;
using System;
using System.Threading;
using System.Threading.Tasks;
using System.Xml;
using UnityEngine;
/// <summary>
/// 使用 SSML 方式语音合成
/// </summary>
public class AzureTTSDataWithSSMLHandler
{
/// <summary>
/// Azure TTS 合成 必要数据
/// </summary>
private const string SPEECH_KEY = "YOUR_SPEECH_KEY";
private const string SPEECH_REGION = "YOUR_SPEECH_REGION";
private const string SPEECH_RECOGNITION_LANGUAGE = "zh-CN";
private string SPEECH_VOICE_NAME = "zh-CN-XiaoxiaoNeural";
/// <summary>
/// 创建 TTS 中的参数
/// </summary>
private CancellationTokenSource m_CancellationTokenSource;
private AudioDataStream m_AudioDataStream;
private Connection m_Connection;
private SpeechConfig m_Config;
private SpeechSynthesizer m_Synthesizer;
/// <summary>
/// 音频获取事件
/// </summary>
private Action<AudioDataStream> m_AudioStream;
/// <summary>
/// 开始播放TTS事件
/// </summary>
private Action m_StartTTSPlayAction;
/// <summary>
/// 停止播放TTS事件
/// </summary>
private Action m_StartTTSStopAction;
/// <summary>
/// 初始化
/// </summary>
public void Initialized()
{
m_Config = SpeechConfig.FromSubscription(SPEECH_KEY, SPEECH_REGION);
m_Synthesizer = new SpeechSynthesizer(m_Config, null);
m_Connection = Connection.FromSpeechSynthesizer(m_Synthesizer);
m_Connection.Open(true);
}
/// <summary>
/// 开始进行语音合成
/// </summary>
/// <param name="msg">合成的内容</param>
/// <param name="stream">获取到的音频流数据</param>
/// <param name="style"></param>
public async void Start(string msg, Action<AudioDataStream> stream, string style = "chat")
{
this.m_AudioStream = stream;
await SynthesizeAudioAsync(CreateSSML(msg, SPEECH_RECOGNITION_LANGUAGE, SPEECH_VOICE_NAME, style));
}
/// <summary>
/// 停止语音合成
/// </summary>
public void Stop()
{
m_StartTTSStopAction?.Invoke();
if (m_AudioDataStream != null)
{
m_AudioDataStream.Dispose();
m_AudioDataStream = null;
}
if (m_CancellationTokenSource != null)
{
m_CancellationTokenSource.Cancel();
}
if (m_Synthesizer != null)
{
m_Synthesizer.Dispose();
m_Synthesizer = null;
}
if (m_Connection != null)
{
m_Connection.Dispose();
m_Connection = null;
}
}
/// <summary>
/// 设置语音合成开始播放事件
/// </summary>
/// <param name="onStartAction"></param>
public void SetStartTTSPlayAction(Action onStartAction)
{
if (onStartAction != null)
{
m_StartTTSPlayAction = onStartAction;
}
}
/// <summary>
/// 设置停止语音合成事件
/// </summary>
/// <param name="onAudioStopAction"></param>
public void SetStartTTSStopAction(Action onAudioStopAction)
{
if (onAudioStopAction != null)
{
m_StartTTSStopAction = onAudioStopAction;
}
}
/// <summary>
/// 开始异步请求合成 TTS 数据
/// </summary>
/// <param name="speakMsg"></param>
/// <returns></returns>
private async Task SynthesizeAudioAsync(string speakMsg)
{
Cancel();
m_CancellationTokenSource = new CancellationTokenSource();
var result = m_Synthesizer.StartSpeakingSsmlAsync(speakMsg);
await result;
m_StartTTSPlayAction?.Invoke();
m_AudioDataStream = AudioDataStream.FromResult(result.Result);
m_AudioStream?.Invoke(m_AudioDataStream);
}
private void Cancel()
{
if (m_AudioDataStream != null)
{
m_AudioDataStream.Dispose();
m_AudioDataStream = null;
}
if (m_CancellationTokenSource != null)
{
m_CancellationTokenSource.Cancel();
}
}
/// <summary>
/// 生成 需要的 SSML XML 数据
/// (格式不唯一,可以根据需要自行在增加删减)
/// </summary>
/// <param name="msg">合成的音频内容</param>
/// <param name="language">合成语音</param>
/// <param name="voiceName">采用谁的声音合成音频</param>
/// <param name="style">合成时的语气类型</param>
/// <returns>ssml XML</returns>
private string CreateSSML(string msg, string language, string voiceName, string style = "chat")
{
// XmlDocument
XmlDocument xmlDoc = new XmlDocument();
// 设置 speak 基础元素
XmlElement speakElem = xmlDoc.CreateElement("speak");
speakElem.SetAttribute("version", "1.0");
speakElem.SetAttribute("xmlns", "http://www.w3.org/2001/10/synthesis");
speakElem.SetAttribute("xmlns:mstts", "http://www.w3.org/2001/mstts");
speakElem.SetAttribute("xml:lang", language);
// 设置 voice 元素
XmlElement voiceElem = xmlDoc.CreateElement("voice");
voiceElem.SetAttribute("name", voiceName);
// 设置 mstts:viseme 元素
XmlElement visemeElem = xmlDoc.CreateElement("mstts", "viseme", "http://www.w3.org/2001/mstts");
visemeElem.SetAttribute("type", "FacialExpression");
// 设置 语气 元素
XmlElement styleElem = xmlDoc.CreateElement("mstts", "express-as", "http://www.w3.org/2001/mstts");
styleElem.SetAttribute("style", style.ToString().Replace("_", "-"));
// 创建文本节点,包含文本信息
XmlNode textNode = xmlDoc.CreateTextNode(msg);
// 设置好的元素添加到 xml 中
voiceElem.AppendChild(visemeElem);
styleElem.AppendChild(textNode);
voiceElem.AppendChild(styleElem);
speakElem.AppendChild(voiceElem);
xmlDoc.AppendChild(speakElem);
Debug.Log("[SSML XML] Result : " + xmlDoc.OuterXml);
return xmlDoc.OuterXml;
}
}
2、AzureTTSMono文章来源地址https://www.toymoban.com/news/detail-650248.html
using Microsoft.CognitiveServices.Speech;
using System;
using System.Collections.Concurrent;
using System.IO;
using UnityEngine;
[RequireComponent(typeof(AudioSource))]
public class AzureTTSMono : MonoBehaviour
{
private AzureTTSDataWithSSMLHandler m_AzureTTSDataWithSSMLHandler;
/// <summary>
/// 音源和音频参数
/// </summary>
private AudioSource m_AudioSource;
private AudioClip m_AudioClip;
/// <summary>
/// 音频流数据
/// </summary>
private ConcurrentQueue<float[]> m_AudioDataQueue = new ConcurrentQueue<float[]>();
private AudioDataStream m_AudioDataStream;
/// <summary>
/// 音频播放完的事件
/// </summary>
private Action m_AudioEndAction;
/// <summary>
/// 音频播放结束的布尔变量
/// </summary>
private bool m_NeedPlay = false;
private bool m_StreamReadEnd = false;
private const int m_SampleRate = 16000;
//最大支持60s音频
private const int m_BufferSize = m_SampleRate * 60;
//采样容量
private const int m_UpdateSize = m_SampleRate;
//audioclip 设置过的数据个数
private int m_TotalCount = 0;
private int m_DataIndex = 0;
#region Lifecycle function
private void Awake()
{
m_AudioSource = GetComponent<AudioSource>();
m_AzureTTSDataWithSSMLHandler = new AzureTTSDataWithSSMLHandler();
m_AzureTTSDataWithSSMLHandler.SetStartTTSPlayAction(() => { Debug.Log(" Play TTS "); });
m_AzureTTSDataWithSSMLHandler.SetStartTTSStopAction(() => { Debug.Log(" Stop TTS "); AudioPlayEndEvent(); });
m_AudioEndAction = () => { Debug.Log(" End TTS "); };
m_AzureTTSDataWithSSMLHandler.Initialized();
}
// Start is called before the first frame update
void Start()
{
m_AzureTTSDataWithSSMLHandler.Start("今朝有酒,今朝醉,人生几年百花春", OnGetAudioStream);
}
// Update is called once per frame
private void Update()
{
UpdateAudio();
}
#endregion
#region Audio handler
/// <summary>
/// 设置播放TTS的结束的结束事件
/// </summary>
/// <param name="act"></param>
public void SetAudioEndAction(Action act)
{
this.m_AudioEndAction = act;
}
/// <summary>
/// 处理获取到的TTS流式数据
/// </summary>
/// <param name="stream">流数据</param>
public async void OnGetAudioStream(AudioDataStream stream)
{
m_StreamReadEnd = false;
m_NeedPlay = true;
m_AudioDataStream = stream;
Debug.Log("[AzureTTSMono] OnGetAudioStream");
MemoryStream memStream = new MemoryStream();
byte[] buffer = new byte[m_UpdateSize * 2];
uint bytesRead;
m_DataIndex = 0;
m_TotalCount = 0;
m_AudioDataQueue.Clear();
// 回到主线程进行数据处理
Loom.QueueOnMainThread(() =>
{
m_AudioSource.Stop();
m_AudioSource.clip = null;
m_AudioClip = AudioClip.Create("SynthesizedAudio", m_BufferSize, 1, m_SampleRate, false);
m_AudioSource.clip = m_AudioClip;
});
do
{
bytesRead = await System.Threading.Tasks.Task.Run(() => m_AudioDataStream.ReadData(buffer));
if (bytesRead <= 0)
{
break;
}
// 读取写入数据
memStream.Write(buffer, 0, (int)bytesRead);
{
var tempData = memStream.ToArray();
var audioData = new float[memStream.Length / 2];
for (int i = 0; i < audioData.Length; ++i)
{
audioData[i] = (short)(tempData[i * 2 + 1] << 8 | tempData[i * 2]) / 32768.0F;
}
try
{
m_TotalCount += audioData.Length;
// 把数据添加到队列中
m_AudioDataQueue.Enqueue(audioData);
// new 获取新的地址,为后面写入数据
memStream = new MemoryStream();
}
catch (Exception e)
{
Debug.LogError(e.ToString());
}
}
} while (bytesRead > 0);
m_StreamReadEnd = true;
}
/// <summary>
/// Update 播放音频
/// </summary>
private void UpdateAudio() {
if (!m_NeedPlay) return;
//数据操作
if (m_AudioDataQueue.TryDequeue(out float[] audioData))
{
m_AudioClip.SetData(audioData, m_DataIndex);
m_DataIndex = (m_DataIndex + audioData.Length) % m_BufferSize;
}
//检测是否停止
if (m_StreamReadEnd && m_AudioSource.timeSamples >= m_TotalCount)
{
AudioPlayEndEvent();
}
if (!m_NeedPlay) return;
//由于网络,可能额有些数据还没有过来,所以根据需要判断是否暂停播放
if (m_AudioSource.timeSamples >= m_DataIndex && m_AudioSource.isPlaying)
{
m_AudioSource.timeSamples = m_DataIndex;
//暂停
Debug.Log("[AzureTTSMono] Pause");
m_AudioSource.Pause();
}
//由于网络,可能有些数据过来比较晚,所以这里根据需要判断是否继续播放
if (m_AudioSource.timeSamples < m_DataIndex && !m_AudioSource.isPlaying)
{
//播放
Debug.Log("[AzureTTSMono] Play");
m_AudioSource.Play();
}
}
/// <summary>
/// TTS 播放结束的事件
/// </summary>
private void AudioPlayEndEvent()
{
Debug.Log("[AzureTTSMono] End");
m_NeedPlay = false;
m_AudioSource.timeSamples = 0;
m_AudioSource.Stop();
m_AudioEndAction?.Invoke();
}
#endregion
}
到了这里,关于Unity 工具 之 Azure 微软SSML语音合成TTS流式获取音频数据的简单整理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[chatgpt+Azure]unity AI二次元小女友之使用微软Azure服务实现RestfulApi->语音识别+语音合成](https://imgs.yssmx.com/Uploads/2024/02/757461-1.png)


![[Unity+OpenAI TTS] 集成openAI官方提供的语音合成服务,构建海王暖男数字人](https://imgs.yssmx.com/Uploads/2024/02/761897-1.png)



