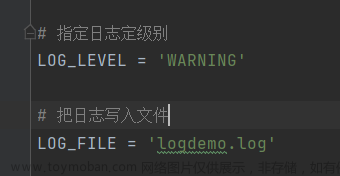
- 引擎向spiders要url
- 引擎把将要爬取的url给调度器
- 调度器会将url生成的请求对象放入到指定的队列中
- 从队列中出队一个请求
- 引擎将请求交给下载器进行处理
- 下载器发送请求获取互联网数据
- 下载器将数据返回给引擎
- 引擎将数据再次给到spiders
- spiders通过xpath解析该数据,得到数据或者url
- spiders将数据或者url给到引擎
- 引擎判断改数据是url,还是数据,是数据的话就交给管道(itempipeline)处理,是url的话就交给调度器处理

文章来源地址https://www.toymoban.com/news/detail-650513.html
文章来源:https://www.toymoban.com/news/detail-650513.html
到了这里,关于Python爬虫——scrapy_工作原理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!