为什么需要倒排索引
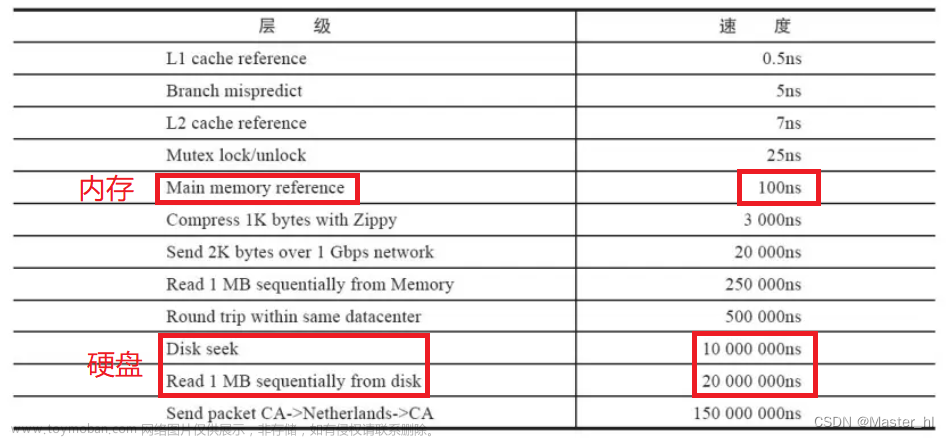
通过前两篇的文章介绍,B+树主要针对的是读多写少的场景,而LSM针对的是写多读少的场景,其实在日常开发中,我们会将数据存储到搜索引擎中,然后进行数据的搜索,这种场景其实针对的是快速根据关键字查询。对于MySQL这种B+树结构来说,其实没有办法保证快速查询。要不然都是select * from x where xx like ‘%xxxx%’,这样的查询,而这种方式是不支持索引快速查询的。
倒排索引
正排索引:页数到内容的关联。而通过关键字查找对应id的关联就是倒排索引。
而这种方式也是利用空间换时间,将关键字进行数据的映射,通过关键字就可以快速搜索到。

Elasticsearch就是利用倒排索引进行数据的查询,但是对于像Google这样的搜索引擎是如何做的呢,虽然ES可以搜索一定的数据,但是当达到一定的数量级 其实没有办法进行快速搜索。
PageRank算法
Google的搜索其实利用PageRank,因为想要在快速的数据检索到对应的内容,并且排在TOP10中的数据,是我们想看的数据。
PageRank的核心就是按照页权重进行分发,权重越大排名越靠前。
默认权重是1,比如如下B网页包含A、D网页,B将自己的权重分发为2分 1/2给A 1/2给B。
D网页包含A网页,C网页包含A、B、C 分别是1/3.所以A的权重就是 1/2+1/3+1 。当递归计算所有的网页之后,就可以得出全部网页的权重。
另一种方式是根据用户点赞数,比如知乎。或者通过文章内容包含的词频
 文章来源:https://www.toymoban.com/news/detail-650641.html
文章来源:https://www.toymoban.com/news/detail-650641.html
小结
本篇主要介绍搜索引擎中倒排索引的机制,以及Google搜索中的PageRank算法。文章来源地址https://www.toymoban.com/news/detail-650641.html
到了这里,关于【分布式存储】数据存储和检索~倒排索引&pageRank的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!