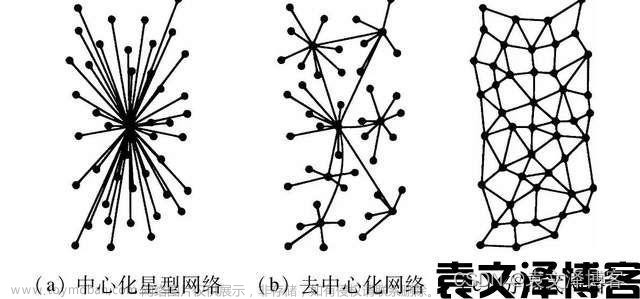
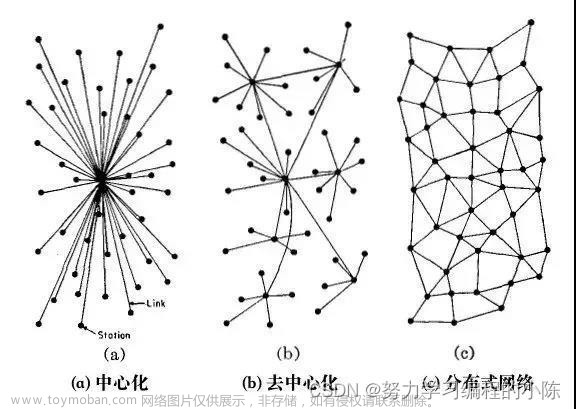
在当今数据密集型的业务环境下,传统的集中式架构已经难以满足高可用性和高并发性的要求。而去中心化微服务集群则通过分散式的架构,将系统划分为多个小型的、独立部署的微服务单元,每个微服务负责特定的业务功能,实现了系统的高度模块化。下面,我们将深入探讨这一架构的优势及其在数据集成中的应用场景。

1. 去中心化微服务集群的优势
1.1 高可用性与容错性
去中心化的架构使得微服务集群可以在分布式环境中运行,从而实现高可用性。每个微服务单元都是相对独立的,因此在一个微服务发生故障时,其他微服务仍然可以继续运行,避免了整个系统的崩溃。此外,容错机制可以保障在微服务失败时进行自动重试,确保数据集成任务的连续性。
1.2 弹性扩展与动态调整
微服务集群架构支持根据实际负载需求进行弹性扩展。当数据集成任务的需求增长时,可以动态地增加微服务实例,以应对高并发情况。反之,在需求减少时可以缩减实例,从而实现资源的最优利用。
1.3 自定义负载均衡与性能优化
去中心化微服务集群允许使用自定义的负载均衡策略,根据任务类型、数据量等因素进行动态调整。这样可以确保不同任务在集群中的分配均衡,从而提高整体性能。
1.4 数据隔离与安全性增强
每个微服务单元都运行在独立的容器中,这意味着不同任务的数据被隔离开来,降低了数据泄露和安全风险。此外,微服务集群支持按需进行访问控制和权限管理,进一步增强数据集成的安全性。

2. 去中心化微服务集群的应用场景
2.1 大数据批处理任务
在处理大规模数据批处理任务时,去中心化微服务集群可以将数据分片处理,提高任务执行效率。每个微服务负责一部分数据处理,通过并行计算缩短任务完成时间。
2.2 实时数据流集成
对于实时数据集成,微服务集群可以分别处理不同数据源的数据,并将其实时汇总。这种架构能够应对多样的数据格式和频率,确保数据流的准确性和实时性。
2.3 跨系统数据同步
在跨多个系统进行数据同步时,微服务集群可以分别处理不同系统的数据映射与转换,保证数据在不同系统间的一致性。同时,由于微服务的独立性,单个系统的故障不会影响整体数据同步流程。

3. 总结
去中心化微服务集群作为数据集成工具领域的一项创新,带来了高可用性、弹性扩展、自定义负载均衡和安全性增强等诸多优势。在大数据批处理、实时数据流集成和跨系统数据同步等应用场景下,这一架构展现出巨大的潜力。通过将任务分解为独立的微服务单元,去中心化微服务集群为数据集成工作赋予了新的活力,助力企业应对日益复杂的数据挑战。
是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业提高数据治理效率和质量。满足了去中心化微服务集群,能同时满足高可用、高并发等要求,并支持各模块微服务部署、动态扩缩、故障迁移、自定义负载均衡、任务容错与重试等各类场景。
了解更多数据仓库与数据集成关干货内容请关注>>>
https://www.finedatalink.com/tb/
免费试用、获取更多信息,点击了解更多>>>文章来源:https://www.toymoban.com/news/detail-650769.html
https://www.finedatalink.com/?utm_source=baijiahao&utm_medium=csdn&utm_term=seo437文章来源地址https://www.toymoban.com/news/detail-650769.html
到了这里,关于数据集成革新:去中心化微服务集群的无限潜能的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!