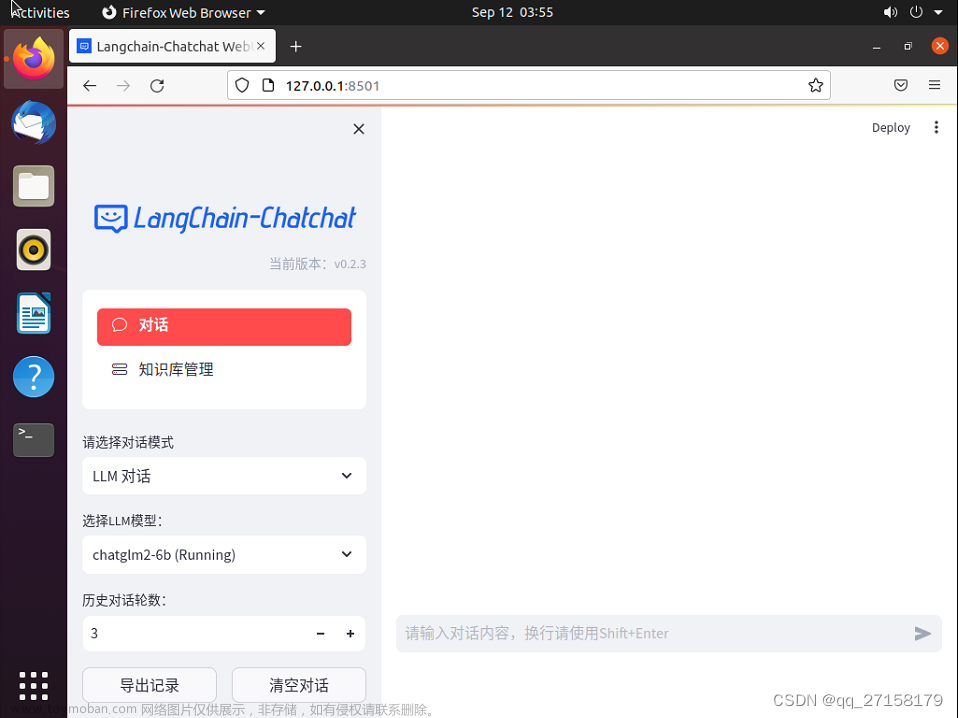
前情提要
怎么将 AI 应用到工作中呢?比如让 AI 帮忙写代码,自己通过工程上的思维将代码整合排版,我挺烦什么代码逻辑严谨性的问题,但是我又不得不承认这样的好处,我们要开始将角色转换出来,不应该是一个工具人,而成为决策者,这是从 AI 爆发中看到的发展趋势,人们逐渐从流水线的工作中解放出来,逐渐成为可以独立思考的自由人,这是科技革命带给普通人最大的时代红利;
但是从另外一个方面看这个问题的时候,每次科技革命到来时,抓不住时代机会的人总会被淘汰一批,当社会的体制的管理逻辑停滞不前,必然会爆发出不可避免的社会矛盾和流血革命,阶级固化不是理想和口号能解决的,有人做狼必然需要很多羊,这是自然法则,妄图通过口号改变这个规则的要么是空想家要么就是既得利益者,空想家干不成,既得利益者不会干。
只要人类还有欲望,就注定了我们的奴性;第一次知道笑贫不笑娼是在大学的日语课堂上,从那时起我便不再对人性抱太大的希望了,没那么恶就行了。
需求目标
a. 基于"闻达"项目进行改造;
b. 训练目标知识库;
c. 远期规划;
实践操作
1. 下载项目
git clone https://github.com/mateclouder/mate-wenda.git
# 下载相关依赖
cd mate-wenda
pip install -r requirements/requirements.txt
2. 参数配置
将 example.config.yml 复制一个新文件 config.yml ,更改其中参数信息
logging: False
#日志"
port: 17860
#webui 默认启动端口号"
library:
#strategy: "calc:2 rtst:2 agents:0"
strategy: "rtst:5 agents:0"
#库参数,每组参数间用空格分隔,冒号前为知识库类型,后为抽取数量。
#知识库类型:
#bing cn.bing搜索,仅国内可用,目前处于服务降级状态
#sogowx sogo微信公众号搜索,可配合相应auto实现全文内容分析
#fess fess搜索引擎
#rtst 支持实时生成的sentence_transformers
#remote 调用远程闻达知识库,用于集群化部署
#kg 知识图谱,暂未启用
#特殊库:
#mix 根据参数进行多知识库融合
#agents 提供网络资源代理,没有知识库查找功能,所以数量为0
# (目前stable-diffusion的auto脚本需要使用其中功能,同时需开启stable-diffusion的api功能)
count: 5
#最大抽取数量(所有知识库总和)
step: 2
#知识库默认上下文步长
librarys:
bing:
count:
5
#最大抽取数量
bingsite:
count: 5
#最大抽取数量
site: "www.vpc123.cn"
#搜索网站
fess:
#fess版本,默认采用14.8以上
version: 14.8
count: 1
#最大抽取数量
fess_host: "127.0.0.1:8080"
#fess搜索引擎的部署地址
remote:
host:
"http://127.0.0.1:17860/api/find"
#远程知识库地址地址
rtst:
count: 3
#最大抽取数量
# backend: Annoy
size: 20
#分块大小"
overlap: 0
#分块重叠长度
model_path: "model/m3e-base"
#向量模型存储路径
device: cuda
#embedding运行设备
llm_type: glm6b
#llm模型类型:glm6b、rwkv、llama、replitcode等,详见相关文件
llm_models:
glm6b:
path: "model\\ChatGLM2-6B"
#glm模型位置"
strategy: "cuda fp16i4"
#cuda fp16 所有glm模型 要直接跑在gpu上都可以使用这个参数
#cuda fp16i8 fp16原生模型 要自行量化为int8跑在gpu上可以使用这个参数
#cuda fp16i4 fp16原生模型 要自行量化为int4跑在gpu上可以使用这个参数
#cuda:0 fp16 *14 -> cuda:1 fp16 多卡流水线并行,使用方法参考RWKV的strategy介绍。总层数28
# lora: "model/lora-450"
#glm-lora模型位置
3. 知识库训练
知识点: 《伤寒杂病论》
首先在main/txt文件夹下新建了一个名为《伤寒杂病论》的文本文档,进行训练:

数据训练: 双击运行
buils_rtst_default_index.bat


4. 启动运行
** 启动 **
run_GLM6B.bat

** 问答 ** 文章来源:https://www.toymoban.com/news/detail-650840.html
文章来源:https://www.toymoban.com/news/detail-650840.html
总结
前前后后搞了一周左右,周六早起都在弄这个,这个真的比打游戏好玩多了,虽然我不玩游戏,那种克服困难搞成一件事的愉悦是难以诉说的,人工智能的事情先到此打住,进入备考了,不能沉迷 AI ,不然我就是被她奴役了。文章来源地址https://www.toymoban.com/news/detail-650840.html
附录
到了这里,关于AI 智能对话 - 基于 ChatGLM2-6B 训练对话知识库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!