计算服务Nova
每个组件对应有很多服务的,[root@controller ~]# systemctl list-unit-files |grep nova
openstack-nova-api.service disabled
openstack-nova-compute.service enabled
openstack-nova-conductor.service enabled
openstack-nova-metadata-api.service disabled
openstack-nova-novncproxy.service enabled
openstack-nova-os-compute-api.service disabled
openstack-nova-scheduler.service enabled

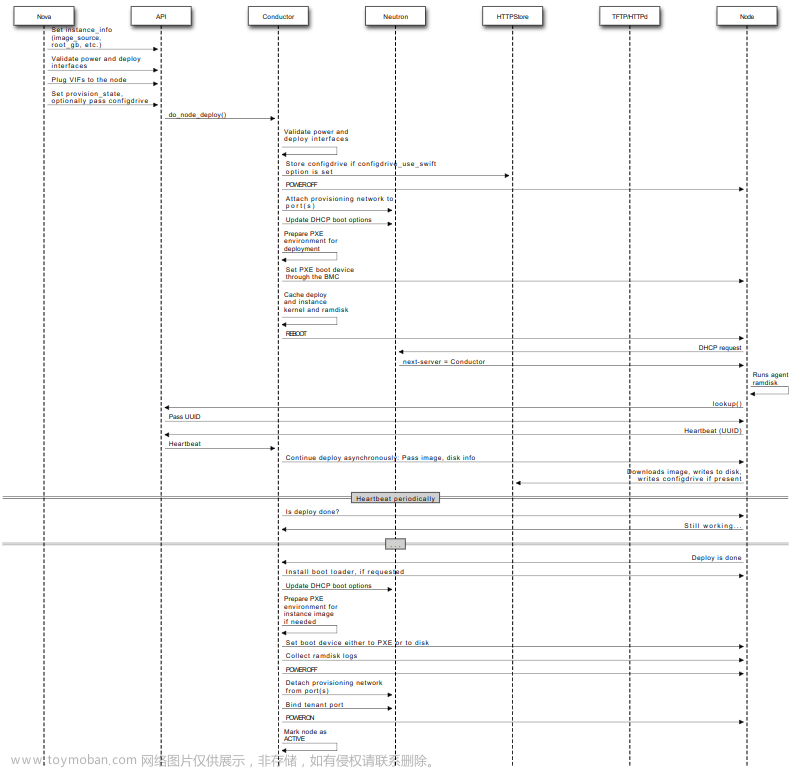
发放云主机,控制节点的nova-api接收请求,给nova-scheduler处理做计算调度后,发放给某个计算节点的nova-compute处理(实验环境把控制节点当计算节点使用了)。
创建云硬盘,控制节点的cinder-api接收请求,给cinder-scheduler处理做计算调度后(通过过滤和权重筛选出合适的后端存储),发放给后端某个存储节点cinder-volume处理(添加不同厂商的Drivers驱动支持不同类型的存储设备,调对应的存储接口Driver驱动,将存储设备转化成块存储池,在后端存储创建实际的卷)(生产环境有独立的存储节点的,实验环境是将存储部署在控制节点)。Cinder默认使用LVM作为后端存储,Cinder以驱动的形式支持不同存储设备作为后端存储,如SAN、Ceph等存储设备,Cinder默认的后端驱动是LVM。
nova-api:对外提供REST接口,接收处理请求
nova-conductor:解耦数据库连接,nova-api查询可直接从数据库查询,但是写入数据库时需要经过nova-conductor再到数据库。
nova-scheduler:确定将虚拟机实例分配到哪一台物理机,分配过程主要分为两步,过滤和权重:通过过滤器选择满足条件的计算节点,通过权重选择最优的节点。
nova-compute:创建虚拟机,负责虚拟机资源和生命周期的管理。
rabbitmq
通过rabbitmq消息队列处理请求,按照规则排队处理互不影响,不会说因为cinder-scheduler调度慢而影响cinder-api接收请求性能,也不会因为cinder-volume处理慢而影响cinder-scheduler调度性能,把这些服务解耦了提升性能了。
rabbitmq基于AMQP协议,rabbitmq来处理消息队列的,每个组件都会生成自己组件的队列,在这个队列里面去消费就行,产生需求信息的叫生产端(如nova-api、cinder-api产生新需求的),把生产端的需求拿过来放到对应队列里面,再由相应组件去对应队列里面取用消费。用rabbitmq为了实现消息的传递互通,能解决并发问题、rabbitmq并发量是毫秒级的,性能很好,不管并发量多大直接扔给rabbitmq,再由其它组件进行消费就行,把这些组件服务充分进行解耦了。
rabbitmq默认部署在控制节点,rabbitmq掌握各个组件的互通,rabbitmq服务停了发放云主机会有问题的,不知哪有问题,就按照组件单个组件查日志,发放云主机先经过nova组件,就先查看nova组件日志,比如查看nova-api.log日志找到error发现rabbitmq连接不上。systemctl status rabbitmq-server.service
控制节点上已经安装了rabbitmq,rabbitmq默认部署在控制节点
rabbitmq-plugins list 列出所有rabbitmq模块,能查看rabbitmq模块是否启用
rabbitmq-plugins enable rabbitmq_management 启用rabbitmq_management模块就能网页登录rabbitmq
默认只有25672端口给内部rabbitmq互通的,15672 端口是启用rabbitmq_management模块开通的,给用户网页登录rabbitmq用的。
# netstat -utlnp |grep 56
tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 6681/beam.smp
tcp 0 0 0.0.0.0:25672 0.0.0.0:* LISTEN 6681/beam.smp
tcp6 0 0 :::5672 :::* LISTEN 6681/beam.smp
通过ip:15672 尝试网页登录rabbitmq有问题,telnet看15672端口是否通,如果无法登录,添加一条iptables规则,iptables -I INPUT 1 -p tcp --dport 15672 -j ACCEPT

认证服务Keystone
用户发送用户名和密码给Keystone,Keystone经过验证后会返回一个Token给用户,用户向nova发送创建虚拟机请求(向cinder发送创建硬盘请求),并携带Token信息,nova接收到请求后,会拿着Token去Keystone进行验证Token有效性,验证成功后开始执行创建VM操作,Nova会向Glance发送申请镜像信息并携带Token,会向Neutron发送申请网络信息也会携带Token,Glance和Neutron组件接收到请求后,都会向Keystone验证Token的有效性。
用户向keystone发送用户名密码,keystone校验用户名密码(credential凭证校验用户名密码)并生成token(旧版本token用uuid实现,现在是fernet),将token发送给客户端并把token存放在keystone数据库token表中,客户端也会缓存这个token,客户端得到这个token令牌后会发起API请求携带这个token,发送给某个服务(如nova)的API,这个服务的API就会从这个请求中解压出token,然后这个服务(如nova)的API会检查这个token的有效性判断这个token是否过期(服务会向keystone发请求验证token有效性、keystone把验证信息告诉这个服务,服务自身没法验证token的有效性,所有服务都需要知道keystone在哪,所有组件服务都指向了keystone的,如查看/etc/glance/glance-api.conf或/etc/nova/nova.conf找到kestone_authtoken),请求通过返回200,不通过返回401(用户名密码错误或token过期了)
Endpoint
其他服务都通过Keystone来注册其服务的Endpoint,针对这些服务的任何调用都需要经过Keystone的身份认证,并获得服务的Endpoint来进行访问。不是通过服务名访问的,是通过Endpoint来访问的。
用户与OpenStack中的服务可以通过Catalog来获取其他服务的Endpoint,这些Endpoint是服务通过Keystone进行注册时由Keystone进行维护的,Catalog就是Endpoint的一个集合,提供用于查询端点(Endpoint)的端点注册表,以便外部访问OpenStack服务。
Endpoint本质上是一个URL,提供服务的入口,每个服务可以有一个或多个Endpoint,通过认证的外部请求,如果需要访问某个服务,只需要知道服务的Endpoint即可。
Endpoint分为Admin、Internal和Public,这些不同类型的Endpoint分别开放给不同的用户或服务。例如,对于Public URL,一般会对所有用户开放,允许用户通过外部网络进行访问,通常是在公共网络接口上使用;Admin URL会对一些用户或URL进行限定,只允许具有特定操作权限的用户访问,通常只提供给有管理权限的用户使用,是在安全的网络接口上使用的;Internal URL限定于那些安装有OpenStack的主机才可以访问,一般是内部组件互通,通常在未计量的内部网络接口上使用。
Endpoint是每个openstack服务的访问api地址,当nova要去调用glance组件时,其实就是访问glance-api地址,glance-api地址就是endpoint地址,为了区分每个组件,分别使用了不同的端口来表示。
Token
考虑到token(uuid)在传输过程中不安全,就加了token有效期(默认3600秒即1小时,cache_time=3600,在/etc/keystone/keystone.conf改),但考虑到uuid是一种不安全方式,后面就有了pki token(pki 是个公钥,采用非对称加密,用户将用户名和密码发送给Keystone,Keystone使用私钥加密秘钥生成令牌返回给客户端。客户每次向OpenStack 发送调用资源和服务请求时会携带这个Token令牌,OpenStack 服务API会使用本地公钥对令牌进行验证),pki携带信息过多,当OpenStack的规模较大时,Token所占的字节数据就超过了HTTP标准头的大小,有可能导致认证失败。
UUID,PKI令牌都会持久存放在数据库中,累积的令牌容易导致数据库性能下降,用户需定期清理数据库中的令牌。为避免该问题,OpenStack目前版本都默认使用Fernet令牌,携带少量的用户信息,采用对称加密,无需存于数据库中,但需定期更换秘钥。
用户将用户名和密码发送给Keystone,Keystone使用秘钥生成临时令牌并返回给客户端。客户每次向OpenStack发送调用资源和服务请求时,会携带这个Token令牌,OpenStack服务API接收到请求后会将Token发送到Keystone进行验证,由Keystone验证其有效性和合法性。这个过程看似与UUID一样,但是其实是有区别的,UUID由于没有加密和解密过程,Keystone在生成token之后要本地缓存Token,方便后面验证。但是Fernet进行对等验证,无需缓存token,每次验证只需要进行解密验证即可,无需持久化存储,大小也合适,比较适合多数据中心的场景。
基于角色的访问控制,权限赋予给角色,角色赋予给用户。
创建云主机是向nova-api发请求,创建云硬盘是向cinder-api发请求,用token访问这个服务,这个服务会向keystone验证token有效性,有无权限操作由policy.json策略配置文件决定的不是由keystone决定的。
每个OpenStack服务(nova、cinder等)都在相关的策略文件中定义其资源的访问策略,即不同角色的用户有不同的操作权限,policy.json策略配置文件,例如/etc/keystone/policy.json
每个组件都有个策略文件policy.json来控制权限的(修改文件先备份),当访问glance会先验证身份,验证身份通过后会判断有无权限(在/etc/openstack-dashboard/glance_policy.json中设置权限,把这个文件拷贝并重命名/etc/glance/policy.json,后修改policy.json文件权限644(会以glance用户身份读取policy.json文件,把policy.json文件拥有者改成glance更安全),改完配置文件要重启服务,有问题就查看日志,tail -f /var/log/glance/api.log
/etc/openstack-dashboard存放了所有组件的policy.json文件模板,真正服务读取的是自己服务目录下的policy.json文件,默认自己服务目录下的policy.json文件是空的,可参照/etc/openstack-dashboard下各自组件的policy.json文件模板来编写(复制过来修改),在服务的配置文件中指向了policy_file=/etc/glance/policy.json文件,如查看/etc/glance/glance-api.conf
系统有个默认的全局配置(默认设置在/etc/openstack-dashboard),不在/etc/glance/写policy.json文件也行,系统会读取全局的默认文件/etc/openstack-dashboard/glance_policy.json(优先读取自己服务目录下的policy.json再读取默认的全局配置)
多域管理,通过domain(域)逻辑隔离不同的租户/项目以及用户,但角色是全局通用的。
如果是管理员角色权限,那么所有的域下面的资源都可以看到。如果是普通用户,只能看到当前所在域下面的资源。
查看域,[root@controller ~(admin)]# openstack domain list
创建域,[root@controller ~(admin)]# openstack domain create memeda
删除域,[root@controller ~(admin)]# openstack domain delete memeda
Failed to delete domain with name or ID 'memeda': Cannot delete a domain that is enabled, please disable it first. (HTTP 403) (Request-ID: req-2b24ee89-3200-4e07-bbb9-3265c131910a)
1 of 1 domains failed to delete.
删除域失败,得先禁用域disable再删除
查看域的详情信息,[root@controller ~(admin)]# openstack domain show memed
发现域是enabled启用的,得先禁用域disable再删除
禁用域,[root@controller ~(admin)]# openstack domain set --disable memeda
查看域的详情信息,[root@controller ~(admin)]# openstack domain show memeda
删除域,[root@controller ~(admin)]# openstack domain delete memeda
查看memeda域下面的项目[root@controller ~(admin)]# openstack project list --domain memeda
查看memeda域下面的用户,[root@controller ~(admin)]# openstack user list --domain memeda
在memeda域里面创建项目和用户再关联角色
在memeda域里面创建项目
[root@controller ~(admin)]# openstack project create memeda --domain memeda
在memeda域里面创建用户
[root@controller ~(admin)]# openstack user create --password redhat --domain memeda memeda
关联角色,给哪个域哪个项目哪个用户关联角色(项目和用户最好用id唯一的,防止多个域内用户项目名重复)这里给关联了admin角色权限
[root@controller ~(admin)]# openstack role add --project 333d5d01d0074b8c854d6c8e7de67bc5 --user f6e8c320a6e8482e8c967d5036bab143 admin
启用多域,修改配置文件,vim /etc/openstack-dashboard/local_settings
[root@controller openstack-dashboard(admin)]# vim local_settings
#OPENSTACK_KEYSTONE_MULTIDOMAIN_SUPPORT = False
OPENSTACK_KEYSTONE_MULTIDOMAIN_SUPPORT = True 启用多域 ,默认禁用多域
# Overrides the default domain used when running on single-domain model
# with Keystone V3. All entities will be created in the default domain.
#OPENSTACK_KEYSTONE_DEFAULT_DOMAIN = 'Default'
OPENSTACK_KEYSTONE_DEFAULT_DOMAIN = 'Default' 默认使用Default域
启用多域了,想使用默认的Default域登入时也必须手工输入Default
重启apache服务,[root@controller ~(admin)]# systemctl restart httpd
重新登录,输入对应的域,用户名和密码进行登录。

镜像服务Glance
任何服务都有个api,当用户访问一个服务时会把这个请求丢给api,api就是服务访问入口,通常访问入口api是放在控制节点的。当用户上传一个镜像时glance-api把这个请求丢给glance-registry再和数据库相连(通过api直接写入数据库不安全,解耦数据库连接)glance-api可直连数据库查询,写的性能差要经过rabbitmq消息队列排队处理,通过registry写入数据库的,类似nova-api查询可直接从数据库查询,但是写入数据库时需要经过nova-conductor再到数据库。
glance-store负责与外部后端存储或本地文件系统的交互,持久化存储镜像文件,glance-store提供一个统一的接口来访问后端存储,屏蔽不同后端存储的差异。
通过Nova模块创建虚拟机实例,Nova调用Glance模块提供的镜像服务,Glance提供的镜像可以通过Swift对象存储机制进行保存。
Glance提供镜像服务的,不是提供镜像存储的,现在实验环境提供的虚拟机实例镜像默认存储在本地文件系统,也可放到cinder块存储或swift对象存储中,华为私有云hcs默认放在swift对象存储。在/etc/glance/glance-api.conf查看找到filesystem_store_datadir=/var/lib/glance/images镜像存储位置。
可以把glance对接到swift对象存储,现在实验环境swift对象存储对接的后端存储是在本地文件系统。
swift对象存储本身不提供存储,是要对接到后端存储的,实验环境后端存储对接的是控制节点的本地文件系统。
把镜像存在swift对象存储中,对象存储中存储的内容一般是不改动的数据,读取性能好,适合大量永久存储。
/dev/loop1 ext4 1.9G 28K 1.7G 1% /srv/node/swiftloopback

glance对接swift对象存储,需要修改配置文件,修改配置文件前先备份。
[root@controller glance(admin)]# cp glance-api.conf glance-api.conf.bak
[root@controller glance(admin)]# vim glance-api.conf
3057 stores=file,http,swift glance支持的选项
3111 default_store=swift glance默认使用的选项,默认是file对接的本地文件系统
3982 swift_store_region = RegionOne 默认存储的区域
4032 swift_store_endpoint_type = publicURL 端点类型public,走哪个endpoint去连接
4090 swift_store_container = glance 名字可以自定义,未来上传镜像后,会自动创建一个以glance开头的容器名。
4118 swift_store_large_object_size = 5120 限制最大单个上传的对象为5G大小。
4142 swift_store_large_object_chunk_size = 200 类似于条带化大小,不能超过200个chunk块
4160 swift_store_create_container_on_put = true 要不要自动给你创建一个容器
4182 swift_store_multi_tenant = true 是否支持多租户/项目
4230 swift_store_admin_tenants = services swift对应的租户/项目名称
4382 swift_store_auth_version = 2 身份认证版本
4391 swift_store_auth_address = http://192.168.100.151:5000/v3 身份认证地址(keystonerc_admin环境变量文件里面的OS_AUTH_URL)
4399 swift_store_user = swift 对象存储使用的默认用户swift
4408 swift_store_key = 6424bb8bc0e04f6c swift用户的密码(去应答文件里面搜索SWIFT_KS_PW)
修改完配置文件后,重启glance服务。
[root@controller glance(admin)]# systemctl restart openstack-glance-*

自定义手工创建镜像:现成的iso镜像不行,kvm虚拟化支持qcow2镜像,利用kvm去创建一台linux,之后将kvm虚拟机磁盘导出qcow2镜像,并上传到openstack平台里面,进行云主机创建。
流程参考:https://blog.51cto.com/cloudcs/5509044 注意:开源openstack无法调出admin密码重置选项。
# cat /etc/yum.repos.d/local.repo 用本地yum源
[local_repo]
name = local
baseurl = file:///mnt/
gpgcheck = 0
在外面的虚拟机安装虚拟化软件包及虚拟机镜像管理工具
# yum groupinstall -y "Virtualization*"
# yum install -y libguestfs-tools-c.x86_64
创建10G的kvm虚拟机,创建kvm虚拟机使用的磁盘文件,/var/lib/libvirt/images/centos7.0.qcow2 10G
修改里面kvm虚拟机网卡配置文件,改完不用重启直接安装软件包
# cat /etc/sysconfig/network-scripts/ifcfg-eth0
TYPE=Ethernet
BOOTPROTO=dhcp
DEVICE=eth0
NAME=eth0
ONBOOT=yes
安装cloud-init 软件包,kvm虚拟机可连通外网,使用自带的在线yum源
# yum install -y cloud-utils-growpart cloud-init
编辑 /etc/cloud/cloud.cfg 配置文件,在 cloud_init_modules 下添加 - resolv-conf(注意格式一致)
# cat /etc/cloud/cloud.cfg (截取了部分内容)
cloud_init_modules:
- disk_setup
- migrator
- bootcmd
- write-files
- growpart
- resizefs
- set_hostname
- update_hostname
- update_etc_hosts
- rsyslog
- users-groups
- ssh
- resolv-conf
编辑 /etc/sysconfig/network 配置文件,添加 NOZEROCONF=yes
# cat /etc/sysconfig/network
#Created by anaconda
NOZEROCONF=yes
编辑 /etc/default/grub 配置文件,添加 GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8"
# cat /etc/default/grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8"
GRUB_DISABLE_RECOVERY="true"
执行命令使参数生效,# grub2-mkconfig -o /boot/grub2/grub.cfg
关闭 KVM 虚拟机,# init 0
在外面的虚拟机重置并清理镜像
# virsh list --all 查看所有kvm虚拟机
清理个性化数据,# virt-sysprep -d centos7.0 centos7.0指的是kvm虚拟机名字
查找centos7.0 kvm虚拟机对应的磁盘文件,# virsh domblklist centos
/var/lib/libvirt/images/centos7.0.qcow2
创建并清理压缩镜像,# virt-sparsify --compress /var/lib/libvirt/images/centos7.0.qcow2 /tmp/centos7.qcow2
在openstack使用自定义镜像,创建实例规格给多大,和当时创建kvm虚拟机时给多大磁盘一致,建议10G。
opnstack官方镜像(qcow2格式),https://docs.openstack.org/image-guide/obtain-images.html
对象存储服务Swift
cinder块存储,适合大量增删改数据库场景,适合实时更新动态数据场景。
swift对象存储,读取大量不改动的静态数据、文件共享,对接的后端存储真正的存储落脚点还是在底层的磁盘。
swift对象存储本身不提供存储,是要对接到后端存储的,实验环境后端存储对接的是控制节点的本地文件系统。
把镜像存在swift对象存储中,对象存储中存储的内容一般是不改动的数据,读取性能好,适合大量永久存储。
/dev/loop1 ext4 1.9G 28K 1.7G 1% /srv/node/swiftloopback
桶(容器)中存储的对象如何保存到底层的磁盘中,针对桶中存储的对象计算出一个hash值,hash值会落在中间的ring环中,ring环中每个分区会对应一个虚拟节点zone,虚拟节点zone又和底层存储是关联的。
ring环将虚拟节点(partition)映射到实际的物理存储设备上,完成寻址过程。ring环使用zone来保证数据的物理隔离,每个partition都放在不同的zone中。

swift对象存储实验环境后端存储默认使用的是控制节点的2G大小的虚拟设备(/srv/node/swiftloopback ),更换swift后端对接的存储,现在对接到控制节点的本地文件系统(lvm)。
swift对接本地文件系统实验步骤:
1.控制节点新增一块20G磁盘
2.对磁盘做分区(分两个分区,每个分区10G)
[root@controller ~]# fdisk /dev/nvme0n2
3.对分区格式化
[root@controller ~]# mkfs.xfs /dev/nvme0n2p1
[root@controller ~]# mkfs.xfs /dev/nvme0n2p2
4.卸载原有的swift虚拟设备
[root@controller ~]# umount /srv/node/swiftloopback
在/etc/fstab中禁止/srv/node/swiftloopback 开机自动挂载,再用# mount -a 刷新下
5.删除原有目录swiftloopback,创建两个目录并在/etc/fstab中永久挂载
[root@controller ~]# cd /srv/node/
[root@controller node]# ls
swiftloopback
[root@controller node]# rm -rf swiftloopback/
[root@controller node]# ls
[root@controller node]# mkdir ob1 ob2
[root@controller node]# ls
ob1 ob2
6、更换文件拥有者和所属组
[root@controller node]# pwd
/srv/node
[root@controller node]# chown swift:swift ob*
7、删除原有ring和builder再创建
用man求帮助,man swift-ring-builder
swift-ring-builder <builder_file> <…>
create <part_power> <min_part_hours>
[root@controller swift]# swift-ring-builder account.builder create 12 2 1
[root@controller swift]# swift-ring-builder container.builder create 12 2 1
[root@controller swift]# swift-ring-builder object.builder create 12 2 1
12:代表2 的多少次方,未来要ring要切分多少个分区
2:代表的是多少副本数,未来一个对象要保存几份数据
1: 代表小时数,当ring创建好之后,不能在1个小时内进行修改
8、创建ring
swift-ring-builder <builder_file> <…>
add z-:/<device_name>_
分别创建account/container/object 这三个ring
去对应的account-server.conf/container-server.conf/object-server.conf查看ip和端口号
weight值多少无所谓,做多副本保存多个zone的weight值要一样,哪个zone权重大文件会更多的保存在该zone
查看swift-ring-builder object.builder account.builder/container.builder/object.builder
9、再平衡rebalance
[root@controller swift]# swift-ring-builder account.builder rebalance
[root@controller swift]# swift-ring-builder container.builder rebalance
[root@controller swift]# swift-ring-builder object.builder rebalance
查看有了3个ring
10、测试
之前的文件

glance对接swift,上传一个镜像,这个镜像被放置swift对象存储里面,而swift对象存储又对接到了后端的本地存储(自定义双副本机制),最终在底层查询镜像的时候,是两份数据。
swift对象存储的容器里面保存的对象一共是3个文件
底层查询为6个文件(双副本机制)
块存储服务Cinder
创建云硬盘,控制节点的cinder-api接收请求,给cinder-scheduler处理做计算调度后(通过过滤和权重筛选出合适的后端存储),发放给后端某个存储节点cinder-volume处理(添加不同厂商的Drivers驱动支持不同类型的存储设备,调对应的存储接口Driver驱动,将存储设备转化成块存储池,在后端存储创建实际的卷)(生产环境有独立的存储节点的,实验环境是将存储部署在控制节点)。Cinder默认使用LVM作为后端存储,Cinder以驱动的形式支持不同存储设备作为后端存储,如SAN、Ceph等存储设备,Cinder默认的后端驱动是LVM。(应答文件参数CONFIG_CINDER_BACKEND=lvm)
给云主机加硬盘,/etc/libvirt/qemu目录下有个xml配置文件,将物理机的/dev/sda映射给虚拟机的/vda,先在物理机挂载分区再通过xml配置文件映射给虚拟机使用。
Cinder对接NFS挂载的外部存储,具体操作流程参照https://blog.51cto.com/cloudcs/5387939
cinder-api接收外部请求,放到消息队列中由cinder-scheduler消费,cinder-api和cinder-scheduler服务位于控制节点,cinder-volume在存储节点(这里有3台linux主机存储节点,cinder-scheduler根据调度选择合适linux主机存储),在下面有驱动,不同的存储驱动driver对接不同类型的存储设备,存储设备类型不同所执行的命令不同,通过驱动进行翻译在后端存储创建实际的卷。
通过Nova创建虚拟机实例,Cinder为虚拟机实例提供持久化块存储,OpenStack的持久存储包括:块存储、对象存储和文件系统存储。Cinder是OpenStack 块存储服务,为Nova虚拟机、Ironic裸机、容器提供卷,Cinder为后端不同的存储设备提供了统一的接口,不同的块设备服务厂商在Cinder中实现其驱动,Cinder调用不同存储接口驱动,将存储设备转化成块存储池。Cinder在虚拟机与具体存储设备之间引入了一层“逻辑存储卷”的抽象,Cinder本身不是一种存储技术,并没有实现对块设备的实际管理和服务。Cinder只是提供了一个中间的抽象层,为后端不同的存储技术如NAS、SAN、对象存储及分布式文件系统等,提供了统一的接口,不同的块设备服务厂商在Cinder中以驱动的形式实现上述接口与OpenStack进行整合。
openstack本身不提供存储,openstack对接了后端底层的存储,对接后端存储需要存储设备的驱动程序,当执行openstack标准指令,通过驱动将openstack指令转化为存储指令,如创建一个100G卷,这个openstack指令被转化为创建lun指令扔到存储中执行。cinder create –volume-name vol100 100 create lun --lun-size 100G --lun-name vol100
编排服务Heat
参考,https://blog.51cto.com/cloudcs/6616896
1.admin创建一些公共资源
创建租户/用户/公网/规格/镜像
2.编写yaml文件
自动实现创建私网/安全组和规则/密钥/发放云主机/分配浮动ip/绑定浮动ip/创建路由/分配网关/创建子接口连接私网。如创建instance.yaml 来发放一台云主机,并可以ping通外网。这里的yaml文件只用改3个地方,image id和network id和实例类型的规格名,openstack image list 查看id,openstack network list 查看id。
创建的instance.yaml内容如下所示:文章来源:https://www.toymoban.com/news/detail-651087.html
heat_template_version: 2018-08-31
description: Simple template to deploy a stack with two virtual machine instances
parameters:
image_name_1:
type: string
label: Image ID
description: SCOIMAGE Specify an image name for instance1
default: 08ec9068-b833-42e2-8410-e1bf15d78292
public_net:
type: string
label: Network ID
description: SCONETWORK Network to be used for the compute instance
default: 91488328-3886-4f1a-944a-e84ff5864d9c
resources:
mykey:
type: OS::Nova::KeyPair
properties:
save_private_key: true
name: key666
web_secgroup:
type: OS::Neutron::SecurityGroup
properties:
rules:
- protocol: tcp
remote_ip_prefix: 0.0.0.0/0
port_range_min: 22
port_range_max: 22
- protocol: icmp
private_net:
type: OS::Neutron::Net
properties:
name: private_net
private_subnet:
type: OS::Neutron::Subnet
properties:
network_id: { get_resource: private_net }
cidr: "192.168.66.0/24"
ip_version: 4
vrouter:
type: OS::Neutron::Router
properties:
external_gateway_info:
network: { get_param: public_net }
vrouter_interface:
type: OS::Neutron::RouterInterface
properties:
router_id: { get_resource: vrouter }
subnet_id: { get_resource: private_subnet }
instance_port:
type: OS::Neutron::Port
properties:
network: { get_resource: private_net }
security_groups:
- default
- { get_resource: web_secgroup }
fixed_ips:
- subnet_id: { get_resource: private_subnet }
floating_ip:
type: OS::Neutron::FloatingIP
properties:
floating_network_id: { get_param: public_net }
association:
type: OS::Neutron::FloatingIPAssociation
properties:
floatingip_id: { get_resource: floating_ip }
port_id: { get_resource: instance_port }
instance1:
type: OS::Nova::Server
properties:
image: { get_param: image_name_1 }
key_name: { get_resource: mykey }
flavor: m2.meme
networks:
- port : { get_resource : instance_port }
outputs:
private_key:
description: Private key
value: { get_attr: [ mykey, private_key ] }


增加yaml内容如创建磁盘
https://docs.openstack.org/heat/latest/template_guide/basic_resources.html#create-a-key-pair文章来源地址https://www.toymoban.com/news/detail-651087.html
到了这里,关于HCIP-OpenStack组件介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!