一 多线程
1.1 进程和线程
- 进程: 就是一个程序,运行在系统之上,称这个程序为一个运行进程,并分配进程ID方便系统管理。
- 线程:线程是归属于进程的,一个进程可以开启多个线程,执行不同的工作,是进程的实际工作最小单位。
- 操作系统中可以运行多个进程,即多任务运行
- 一个进程内可以运行多个线程,即多线程运行
- 进程之间是内存隔离的, 即不同的进程拥有各自的内存空间。
- 线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的。

1.2 并行、并发执行概念
-
在Python中,多线程用于实现并行和并发执行任务。虽然多线程可以让你同时执行多个任务,但由于Python的全局解释锁(Global Interpreter Lock,GIL)的存在,多线程并不能实现真正的多核并行。然而,多线程仍然可以用于执行I/O密集型任务,因为在这些任务中,线程可能会在等待I/O操作完成时释放GIL,从而允许其他线程运行。
-
并行执行:
- 并行执行是指多个任务在同一时刻同时运行,各自独立地占用一个CPU核心。
- 在Python中,由于GIL的存在,多线程并不适合用于CPU密集型任务的并行执行。
- 多个进程同时在运行,即不同的程序同时运行,称之为:多任务并行执行
- 一个进程内的多个线程同时在运行,称之为:多线程并行执行
-
并发执行:
- 并发执行是指多个任务交替执行,通过快速切换执行任务的上下文来实现“同时”执行的错觉。
- 这在处理I/O密集型任务时非常有效,因为线程可能会在等待I/O完成时让出CPU资源给其他线程。
1.3 多线程编程
-
在Python中,可以使用
threading模块来创建和管理多线程。 -
threading.Thread类可以创建一个线程对象,用于执行特定的任务函数。 -
threading.Thread类的一般语法和一些常用参数:thread_obj = threading.Thread(target=function_name, args=(), kwargs={}, daemon=False) # 启动线程 thread_obj.start() -
target: 必需的参数,用于指定线程要执行的函数(任务)。函数会在新线程中运行。 -
args: 可选参数,用于传递给目标函数的位置参数,以元组形式提供。如果函数不需要参数,可以传递一个空元组或省略这个参数。 -
kwargs: 可选参数,用于传递给目标函数的关键字参数,以字典形式提供。如果函数不需要关键字参数,可以传递一个空字典或省略这个参数。 -
daemon: 可选参数,布尔值,用于指定线程是否为守护线程。守护线程会在主线程结束时被终止,而非守护线程会等待所有线程完成后再终止。 -
使用
threading.Thread类创建线程对象并启动线程
import threading
import time
def print_numbers():
for i in range(1, 6):
print(f"Number: {i}")
time.sleep(1)
def print_letters():
for letter in ['a', 'b', 'c', 'd', 'e']:
print(f"Letter: {letter}")
time.sleep(1)
if __name__ == "__main__":
thread1 = threading.Thread(target=print_numbers)
thread2 = threading.Thread(target=print_letters)
thread1.start() # Start the first thread
thread2.start() # Start the second thread
thread1.join() # 用于阻塞当前线程,直到被调用的线程完成其执行
thread2.join() # 用于阻塞当前线程,直到被调用的线程完成其执行
print("All threads completed")
-
在这个示例中,创建了两个线程对象,每个线程对象都关联一个不同的任务函数(
print_numbers和print_letters)。然后启动这两个线程,并等待它们完成。最后,我们输出一个提示,表示所有线程都已完成。 -
thread1和thread2是两个线程对象,而thread1.join()和thread2.join()是在主线程中调用的。当调用这些方法时,主线程会阻塞,直到对应的线程(thread1或thread2)完成了它们的执行。 -
thread1.join()和thread2.join()语句确保在两个子线程执行完成后,主线程才会输出 “All threads completed” 这条消息。如果不使用join(),主线程可能会在子线程还没有完成时就继续执行,导致输出消息的时机不确定。
1.4 补充:join()方法
-
在多线程编程中,
join()方法用于阻塞当前线程,直到被调用的线程完成其执行。具体来说,thread1.join()表示当前线程(通常是主线程)会等待thread1线程完成后再继续执行。 -
这种等待的机制可以确保主线程在所有子线程执行完成后再继续执行,从而避免可能出现的线程之间的竞争条件和不确定性。这在需要等待所有线程完成后进行进一步操作或获取线程执行结果时非常有用。
1.5 并行、并发实现演示
- 并行执行多个任务演示:
import threading
def task1():
print("Task 1 started")
# ... some code ...
print("Task 1 finished")
def task2():
print("Task 2 started")
# ... some code ...
print("Task 2 finished")
if __name__ == "__main__":
thread1 = threading.Thread(target=task1)
thread2 = threading.Thread(target=task2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("All tasks completed")
- 并发执行演示:
import threading
import time
def task1():
print("Task 1 started")
time.sleep(2) # Simulate I/O operation
print("Task 1 finished")
def task2():
print("Task 2 started")
time.sleep(1) # Simulate I/O operation
print("Task 2 finished")
if __name__ == "__main__":
thread1 = threading.Thread(target=task1)
thread2 = threading.Thread(target=task2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("All tasks completed")
1.6 Thread参数传递使用演示
- 当使用
threading.Thread创建线程对象时,可以通过args、kwargs和daemon参数传递不同类型的信息给线程。 - 以下是针对每种参数的示例:
- 使用
args参数传递位置参数:
import threading
def print_numbers(start, end):
for i in range(start, end + 1):
print(f"Number: {i}")
if __name__ == "__main__":
thread1 = threading.Thread(target=print_numbers, args=(1, 5))
thread2 = threading.Thread(target=print_numbers, args=(6, 10))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("All threads completed")
- 使用
kwargs参数传递关键字参数:
import threading
def greet(name, message):
print(f"Hello, {name}! {message}")
if __name__ == "__main__":
thread1 = threading.Thread(target=greet, kwargs={"name": "Alice", "message": "How are you?"})
thread2 = threading.Thread(target=greet, kwargs={"name": "Bob", "message": "Nice to meet you!"})
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print("All threads completed")
- 使用
daemon参数设置守护线程:
import threading
import time
def count_seconds():
for i in range(5):
print(f"Elapsed: {i} seconds")
time.sleep(1)
if __name__ == "__main__":
thread = threading.Thread(target=count_seconds)
thread.daemon = True # 设置线程为守护线程
thread.start()
# No need to join daemon threads, they will be terminated when the main thread ends
print("Main thread completed")
- 将线程
thread设置为守护线程(daemon = True)。这意味着当主线程结束时,守护线程也会被终止,而无需使用join()等待它完成。
二 网络编程
2.1 Socket初识
- Python的套接字(Socket)编程是一种基本的网络编程技术,它可以在网络上建立连接并进行数据传输。
- socket (简称 套接字) 是进程之间通信一个工具,进程之间想要进行网络通信需要socket。Socket负责进程之间的网络数据传输,是数据的搬运工。

2.2 客户端和服务端
- 2个进程之间通过Socket进行相互通讯,就必须有服务端和客户端
- Socket服务端:等待其它进程的连接、可接受发来的消息、可以回复消息
- Socket客户端:主动连接服务端、可以发送消息、可以接收回复

2.3 创建socket对象详解
-
在创建套接字对象时,通常是可以不指定参数的。如果没有指定参数,将会使用默认的参数,这些参数在
socket模块中预先定义。默认情况下,socket函数将创建一个 IPv4 的流式套接字。 -
例如,以下代码将创建一个默认的 IPv4 TCP 套接字:
import socket # 创建一个默认的 IPv4 TCP 套接字 default_socket = socket.socket() # 后续代码中可以使用 default_socket 进行操作 -
这种方式在很多情况下都是适用的,特别是当你只需要一个简单的 IPv4 TCP 套接字时。
socket.socket(socket.AF_INET, socket.SOCK_STREAM)-
socket:Python 的内置套接字模块,它提供了在网络上进行通信的基本功能。 -
socket.AF_INET:表示套接字地址簇(Address Family),用于指定套接字使用的地址类型。AF_INET表示使用 IPv4 地址。还可以使用AF_INET6来表示 IPv6 地址。 -
socket.SOCK_STREAM:表示套接字的类型。SOCK_STREAM表示这是一个流式套接字,它基于 TCP 协议提供了可靠的、面向连接的、双向的数据流传输。
-
-
综合起来,
socket.socket(socket.AF_INET, socket.SOCK_STREAM)创建了一个基于 IPv4 地址和 TCP 协议的流式套接字对象,你可以使用这个套接字对象来建立连接、发送和接收数据。 -
如果需要创建基于 UDP 协议的套接字,可以使用
socket.SOCK_DGRAM,例如:udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
2.4 accept()方法详解
-
accept()方法是在服务器端套接字上调用的方法,用于接受客户端的连接请求。它会阻塞程序,直到有客户端尝试连接到服务器,然后返回一个新的套接字用于与该客户端进行通信,以及客户端的地址信息。client_socket, client_address = server_socket.accept()-
accept():接受客户端的连接请求。当调用这个方法时,它会阻塞程序,直到有客户端连接到服务器。一旦有连接请求到达,该方法将返回两个值:一个是表示与客户端通信的新套接字对象,另一个是客户端的地址信息。 -
client_socket:新创建的套接字对象,用于与连接的客户端进行通信(可以使用这个套接字来接收和发送数据) -
client_address:元组类型,包含客户端的 IP 地址和端口号。例如,('192.168.1.100', 54321)。
-
-
一般来说,服务器在一个循环中使用
accept()方法,以便能够接受多个客户端的连接。每当有新的客户端连接到服务器时,accept()方法会返回一个新的套接字和客户端的地址,然后服务器可以将新套接字添加到连接池,与客户端进行通信。 -
注意:
accept()方法在没有连接请求时会一直阻塞程序。如果你希望设置超时或者非阻塞的连接等待,你可以在创建服务器套接字后设置相应的选项。这样,在没有连接请求时调用accept()方法将立即返回,不会阻塞程序的执行。 -
例如,在创建服务器套接字后可以使用以下代码将其设置为非阻塞模式:
server_socket.setblocking(False)
2.5 发送信息方法详解
-
send()方法和sendall()方法都用于在套接字上发送数据,但它们有一些不同之处。
send(data) 方法:
-
send()方法是用于发送数据的基本方法,它接受一个字节流(bytes)作为参数,并尝试将数据发送到连接的对方。 - 如果成功发送全部数据,该方法将返回发送的字节数。如果没有发送完全部数据,可能返回一个小于请求发送数据的字节数。
- 如果在发送过程中出现问题(例如连接中断),
send()方法可能会引发异常。
sendall(data) 方法:
-
sendall()方法也用于发送数据,但它更加健壮,会自动处理数据分片和重试。 -
无论数据有多大,
sendall()方法会尽力将所有数据都发送出去,直到全部数据都被发送成功或发生错误。 -
方法不会立即返回,而是在所有数据都发送成功后才返回
None。如果发生错误,它可能引发异常。 -
sendall()方法在发送数据时会自动处理数据的分片,确保数据都被正确发送。 -
在大多数情况下,如果想要简单地发送一小段数据,可以使用
send()方法。然而,如果需要发送大量数据或者确保数据被完整、可靠地发送,那么使用sendall()方法会更好,因为它会自动处理数据分片和错误处理。 -
使用
send()方法:client_socket.send(b"Hello, server!") -
使用
sendall()方法:data = b"Hello, server!" client_socket.sendall(data)
2.6 Socket编程演示
-
服务器端代码:
import socket # 1. 创建Socket对象 server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2. 绑定服务器地址和端口 server_address = ('127.0.0.1', 12345) server_socket.bind(server_address) # 3. 开始监听端口 backlog=5 标识允许的连接数量,超出的会等待,可以不填,不填自动设置一个合理的值 server_socket.listen(5) print("Waiting for a connection...") # 4. 接收客户端连接,获得连接对象 client_socket, client_address = server_socket.accept() print(f"Connected to {client_address}") # 5. 客户端连接后,通过recv方法 接收并发送数据 while True: data = client_socket.recv(1024).decode('utf-8') # recv接受的参数是缓冲区大小,一般给1024即可 # recv方法的返回值是一个字节数组也就是bytes对象,不是字符串,可以通过decode方法通过UTF-8编码,将字节数组转换为字符串对象 if not data: break print(f"Received: {data}") # 6. 通过client_socket对象(客户端再次连接对象),调用方法,发送回复消息 msg = input("请输入你要和客户端回复的消息:") if msg == 'exit': break client_socket.sendall(msg.eccode("UTF-8")) # 7.关闭连接 client_socket.close() server_socket.close()
-
客户端代码:
import socket # 1.创建socket对象 client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 2.连接服务器地址和端口 server_address = ('127.0.0.1', 12345) client_socket.connect(server_address) # 3.发送数据 while True: # 发送消息 msg = input("请输入要给服务端发送的消息:") if msg == 'exit': break client_socket.sendall(msg.encode("UTF-8")) # 4.接收返回消息 recv_data = client_socket.recv(1024) # 1024是缓冲区的大小,一般1024即可。 同样recv方法是阻塞的 print(f"服务端回复的消息是:{recv_data.decode('UTF-8')}") # 5.关闭连接 client_socket.close()
三 正则表达式
3.1 正则表达式概述
- 正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。
- 正则表达式就是使用:字符串定义规则,并通过规则去验证字符串是否匹配。
- 比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱。通过正则规则:
(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)即可匹配一个字符串是否是标准邮箱格式
3.2 Python正则表达式使用步骤
- 使用正则表达式的一些基本步骤和示例:
- 导入
re模块:
import re
- 使用
re.compile()编译正则表达式:
# `pattern_here`应该替换为实际正则表达式
pattern = re.compile(r'pattern_here')
- 使用编译后的正则表达式进行匹配:
text = "This is an example text for pattern matching."
result = pattern.search(text)
if result:
print("Pattern found:", result.group())
else:
print("Pattern not found.")
3.3 正则的基础方法
-
Python正则表达式,使用re模块,并基于re模块中基础方法来做正则匹配。
-
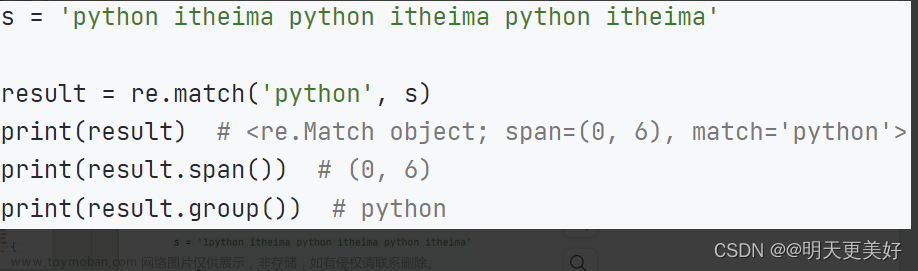
匹配(Match):使用
match()来从字符串的开头开始匹配。匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空
result = pattern.match(text)
-
搜索(Search):使用
search()来查找文本中的第一个匹配项。整个字符串都找不到,返回None
result = pattern.search(text)
-
查找所有(Find All):使用
findall()来找到所有匹配项,并返回一个列表。找不到返回空list: []
results = pattern.findall(text)
-
替换(Replace):使用
sub()来替换匹配项。
# `replacement`应该是希望替换匹配项的内容
new_text = pattern.sub(replacement, text)
-
分割(Split):使用
split()来根据匹配项分割字符串。
parts = pattern.split(text)
-
在正则表达式中,你可以使用不同的元字符(例如
.、*、+、?、[]、()等)来构建复杂的模式,以便进行更精确的匹配。 -
演示使用正则表达式从文本中提取所有的电子邮件地址
import re
text = "Contact us at: john@example.com or jane@example.org for more information."
pattern = re.compile(r'\b[\w.-]+@[\w.-]+\.\w+\b')
email_addresses = pattern.findall(text)
for email in email_addresses:
print(email)
3.4 元字符匹配
- 单字符匹配

示例:
字符串s = "itheima1 @@python2 !!666 ##itcast3" - 找出全部数字:
re.findall(r '\d', s)
- 字符串的r标记,表示当前字符串是原始字符串,即内部的转义字符无效而是普通字符
- 找出特殊字符:
re.findall(r '\W', s) - 找出全部英文字母:
re.findall(r '[a-zA-Z]', s) -
[]内可以写:[a-zA-Z0-9]这三种范围组合或指定单个字符如[aceDFG135]
- 数量匹配

- 边界匹配

- 分组匹配

四 递归
-
递归是一种编程技术(算法),即方法(函数)自己调用自己的一种特殊编程写法。在Python中,可以使用递归来解决许多问题,特别是那些可以被分解为相同或类似子问题的问题。

-
在使用递归时,需要确保定义递归基(base case),这是递归结束的条件,以避免无限循环。每次递归调用都应该将问题规模减小,使其朝着递归基的条件靠近。
-
使用递归计算阶乘:
def factorial(n): if n == 0: return 1 # 递归基 else: return n * factorial(n - 1) # 递归调用 num = 5 result = factorial(num) print(f"The factorial of {num} is {result}")-
factorial函数通过不断地调用自身来计算阶乘。当n达到递归基条件n == 0时,递归结束,不再调用自身。
-
-
然而,递归并不总是最有效的解决方法,因为它可能会导致函数调用的嵌套层数过深,从而消耗大量的内存和处理时间。在一些情况下,使用循环或其他方法可能更有效。文章来源:https://www.toymoban.com/news/detail-651283.html
-
在编写递归函数时,要确保递归调用朝着递归基靠近,避免陷入无限循环,同时考虑性能方面的问题。文章来源地址https://www.toymoban.com/news/detail-651283.html
到了这里,关于探索Python编程的技巧:多线程魔法、网络舞台、正则魔法阵与递归迷宫的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!