所有权
垃圾回收管理内存
Python,Java这类语言在管理内存时引用了一种叫做垃圾回收的技术,这种技术会为每个变量设置一个引用计数器(reference counter),来统计每个对象的引用次数。
一旦某个对象的引用数为0,垃圾回收器就会择取一个时机将其所占用的空间回收。
以Python为例子
x = [1, 2] # 列表对象[1, 2]被x引用,引用计数为1
y = x # 列表对象[1, 2]被y引用,引用计数为2
del x # 列表对象[1, 2]的引用x被删除,此时并不删除对象,引用计数为1
del y # 列表对象[1, 2]的引用y被删除,此时并不立即删除对象,引用计数为0
# 但此对象将会在下一次垃圾回收时被清理
这种垃圾回收的方式很好的避免了开发者去管理内存,但是也造成了一些列问题。也就是:
- 这种垃圾回收不会立刻进行,而是会选取某个时机进行,这无疑在这段时间内这段内存会被一直占用。
- 垃圾回收对性能的消耗比较大,因为编译器/解释器需要不停的追踪每个对象的引用计数来决定某个变量是否会被回收。
手动管理内存
C/C++就采取了手动管理内存的方式,也就是自己申请内存,自己需要去释放,如果不释放就可能导致内存占用的堆积,这种方式的好处在于可控性和高性能,坏处在于很容易出现各种错误。例如二次释放。
void test(int arr[]){
free(arr); //此时该数组已经被释放
}
int main(){
int *arr = (int *)malloc(sizeof(int) * 10);
test(arr);
free(arr); //这里又进行了第二次释放
return 0;
}
上述代码可能你觉着不会写的这么蠢,但是如果当代码逻辑复杂起来,你很难保证你不会犯这样的错误。
二次释放的危害很大,因为当一块内存被释放时可能会被新的对象再次占用,而地二次释放则会破坏新的对象的存储从而造成一系列严重的错误。
Rust的所有权
Rust采取了一种非传统的做法,即采用了一种叫做所有权的机制,其规则如下:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
来看下面的例子
fn main() {
let x = 4; //x的作用域开始位置
{//y的作用域开始位置
let y = 10;
}//y的作用域结束位置,作用域结束,y被丢弃
}//x的作用域结束位置,作用域结束,x被丢弃
此时就需要提一下堆和栈这两种内存了,其主要的区别如下:
栈是一种后进先出的内存,其内部高度组织化,并且栈内存的数据需要实现知道其大小,堆栈内存的存取速度很快
与栈内存不同,堆可以存储结果(指不能在编译时就确定大小)未知大小的数据,在存取时速度比较慢,OS会寻找一块可以存的下的内存然后分配给对应的进程。对于这块堆内存来说,会有一个指针指向这块,而这个指针是要存在栈中的。
| 堆 | 栈 | |
|---|---|---|
| 存取速度 | 慢 | 快 |
| 分配内存大小 | 可不固定 | 必须固定 |
在Rust中,有以下类型都是存储在栈内存上的,这些类型都实现了一个叫做copy的trait
(图片来自于b站杨旭)
由于这些类型都是存在栈上的,而栈的存储速度远高于堆,所以对于Rust来说,上述的数据在赋值传递时往往会直接进行拷贝,而不需要引用之类的技术。
fn main(){
let x = 10;
let y = x; //此时y有拷贝了一份10
}
所有权转移
由于我们知道上述的类型都是存在栈的,所以体现不出所有权,我们使用另一种存在堆上的类型String来演示所有权。
fn main(){
let s = String::from("hello"); //从字符串字面值得到一个String类型
}
这里需要区分一下String和字符串字面值的区别,这里的String是一个存在堆内存的变量,其大小是可以扩充变化的。而字符串字面值(如let x = “hello”;)是固定的,在编译时就已经确定的了。
来看下面的代码:
fn main(){
let s1 = String::from("hello"); //从字符串字面值得到一个String类型
let s2 = s1;
println!("{}", s); //会报错
}
上述代码报错了,我们来看报错信息:
error[E0382]: borrow of moved value: `s1`
--> src\main.rs:4:17
|
2 | let s1 = String::from("hello"); //从字符串字面值得到一个String类型
| - move occurs because `s` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| - value moved here
4 | println!("{}", s1); //会报错
| ^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
报错的内容说,我们借用了一个已经移动了的值s。
还记着开头所说的所有权规则么:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
String::from(“hello”);这个值最开始被s所拥有,但是当让s2 = s1时,这个值就不在归s所有了,而是发生了move(移动),所有权交给了s2。
这是因为有第二条: 一个值只能同时被一个变量所拥有的缘故,所以s1不再拥有String::from(“hello”);,自然也就无法再被使用了。
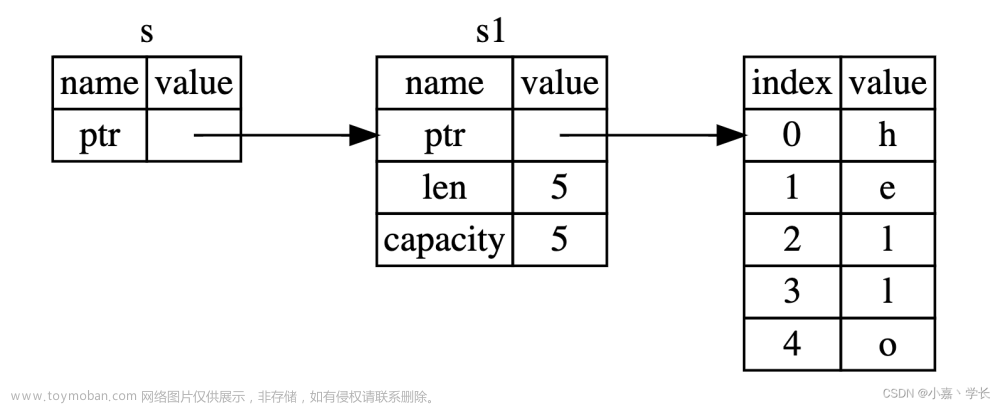
我们从内存上来看是这样的(图片来自于b站杨旭),刚开始s1是一个指针指向了hello这块堆内存
后来由于s2=s1,所以指针得到了复制,得到了如下的场景
但由于一个值只能有一个所有者,所以先前的s1指针将被视为无效,于是得到了如下的场景。
所以最终看起来就好像s1的所有权移动到了s2一样,发生了所有权(对hello这个值的拥有)的移动。
这么做有一个很大的好处,那就是由于一个值在同一时刻只有一个所有者,那么在离开作用域时,对应的值就不会被反复释放
fn main(){
let s1 = String::from("hello"); //s1作用域开始
let s2 = s1;//s2作用域开始,s1失去所有权
}//s1,s2作用域结束,由于s1没有所有权,所以只有s2会释放这块堆内存。
这样就有效的避免了二次释放的的问题,但是同时又给开发者引入了很多新的难题。
函数所有权传递
但一个变量被当做参数传递给函数时,其所有权将会被移交到函数内部的形式参数上。看如下例子:
fn get_len(s: String) -> usize{ //此时,这里的形式参数s得到了外部s1的所有权
return s.len(); //返回s的长度
} //s的作用域结束,而s又具有hello的所有权,所以hello会被释放
fn main(){
let s1 = String::from("hello"); //从字符串字面值得到一个String类型
let len = get_len(s1); //把s1交给函数get_len
println!("{}", s1); //由于此时所有权已经交给了函数内部的形式参数s,所以s1没有所有权,导致报错
}
上面的注释已经说名了具体状况,其发生错误的原因就在于传递参数时会发生所有权的转移,而转移后有没有发生归还,而导致使用了没有所有权的变量。
解决方法1:
使用shadowing这个特性,将使用权再返回回去。
fn get_len(s: String) -> (usize, String){ //返回长度和字符串
return (s.len(), s);
}
fn main(){
let s = String::from("hello"); //从字符串字面值得到一个String类型
let (s, len) = get_len(s); //用Tuple拆包和shadowing的特性归还使用权
println!("{}'s len is {}", s, len);
}
解决方法2:
参看下面的引用部分
如果你不想这么麻烦,你想直接复制一份hello传过去,而不是吧使用权交过去,你可以使用clone方法,这个方法会把堆上的数据克隆一份,然后给传给函数。
fn get_len(s: String) -> usize{ //返回长度和字符串
return s.len();
}
fn main(){
let s = String::from("hello"); //从字符串字面值得到一个String类型
let len = get_len(s.clone()); //把s克隆一份,此时新克隆的部分的使用权将交给形式参数s
println!("{}'s len is {}", s, len);
}
注意,克隆意味着你要在堆上复制一份数据,这是相当耗时的。但好处在于,你可以不用为所有权而烦恼。
引用与借用
每次想要传一个值都会进行所有权转移显然十分的头疼,于是就有了借用,借用实际上就是一种引用,但是它的特殊之处在于他不会拿到所有权。 借用使用&操作符来表示。例子如下:
fn get_len(s: &String) -> usize{ //s是一个借用,而不是转交所有权
return s.len();
}
fn main(){
let s1 = String::from("hello"); //从字符串字面值得到一个String类型
let len = get_len(&s1); //传入s1的引用
println!("{}'s len is {}", s1, len);
}
借用在内存上看是这个样子的:
可以看到引用s只是指向了s1,并不是指向了堆内存所在的位置。所以借用可以看做是变量的引用。因为有这个特性,所以借用并没有拿到了s1的所有权,只是暂时的借了过来。
所以在get_len函数结束之后,由于s只是借用所以无权释放hello。所有权还在s1手中。
可变与不可变引用
上述的借用很好的解决了传参的问题,但是还没完。有时我们希望修改一下对应的值,如果你直接修改就会发现报错这是因为你没加mut关键字。
fn get_len(s: &mut String) -> usize{ //可变字符串引用
return s.len();
}
fn main(){
let mut s = String::from("hello"); //从字符串字面值得到一个String类型
let len = get_len(&mut s);//传入可变字符串引用
println!("{}'s len is {}", s, len);
}
问题似乎解决了,似乎皆大欢喜,但是,更大的问题随之出现了。我们来看下面的例子
fn main(){
let mut s: String = String::from("hello");
let mut re1: &String = &mut s;
let mut re2: &String = &mut s;//此处报错
println!("{} {}", re1, re2);
}
报错的理由很简单,同一作用域内不允许出现两个同一变量的可变引用。Rust这么做是为了防止数据竞争的发生。数据竞争会由一下行为引发:
1. 两个或更多的指针同时访问同一数据
2. 至少有一个指针被用来写入数据
3. 没有同步数据访问的机制
(参考来源: https://course.rs/)
同时为了保证不可变引用不会因为可变引用的修改而发生异常,于是规定,在同一作用域内不可变引用和可变引用不能同时出现。
fn main(){
let mut s: String = String::from("hello");
let mut re1: &String = &s;
let mut re2: &String = &mut s; //不能同时出现
println!("{} {}", re1, re2);
}
但是在同一作用域内,可以同时出现多个不可变引用。
如果实在需要用到多个可变引用,则可以通过大括号来创建新的作用域。
fn main(){
let mut s: String = String::from("hello");
{
let mut re1: &String = &s;
}
let mut re2: &String = &mut s;
println!("{}", re2); //此时已经无法调用re1,因为它的作用域在大括号内,在此处已经失效
}
生命周期
对于Rust来说每个变量都有一个自己的生命周期,也就是说,每个变量有一个有效地范围。
如果一个变量已经失效,而仍然使用他的引用,就会造成悬垂引用。而Rust的生命周期就是为了避免悬垂引用这个错误而设计的。
悬垂引用
来看下面的代码
fn main() {
let result;
{
let tmp = String::from("abc");
result = &tmp;
}
println!("{}", result);
}
上述代码会报错,这是因为result的生命周期在整个main内,但是tmp只是内部的一个局部变量,在print时,tmp已经失效可以认为是空的。
但是此时result仍然持有并想使用tmp的引用,因此引发了报错。来看一下报错内容:
error[E0597]: `tmp` does not live long enough
--> src\main.rs:6:18
|
5 | let tmp = String::from("abc");
| --- binding `tmp` declared here
6 | result = &tmp;
| ^^^^ borrowed value does not live long enough
7 | }
| - `tmp` dropped here while still borrowed
8 | println!("{}", result);
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
内容说的很直白,说的是result借用了一个获得还没自己长的变量。
我们来看看两个变量的生命周期(就是存活时间)
fn main() {
let result;-------------------------------+
{ |<-result的生命周期
let tmp = String::from("abc");-----+ |
result = &tmp; tmp的生命周期-> | |
}--------------------------------------+ |
println!("{}", result); |
}---------------------------------------------+
从上图可以直观的看到,result的存活范围(生命周期)大于tmp的生命周期。一个大的生命周期的变量借用了一个小的,所以才会导致了错误的发生。
我们只需要修改上述代码就可以使其正确
fn main() {
let result;
let tmp = String::from("abc");
result = &tmp;
println!("{}", result);
}
此时在调用print时,tmp的生命周期还没有结束,但是此时你也能发现result的生命周期其实还是大于tmp的,也就意味着
大周期借用小周期不一定会出错。但是在很多情况下,Rust还是认为这种情况存在风险,会在编译阶段就拒绝我们。
但是小周期借用大周期确实一定不会出错的(因为此时小周期会率先失效,而不会借用到一个失效的大周期对象)
函数生命周期声明
先来看一个函数,有一个需求,要求返回两个字符串中最长的那一个的借用。此时你会想这么写代码
fn get_greater(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
此时你觉着则个代码写得没问题,但是你却发现编译器报错了。你会发现错误如下:
error[E0106]: missing lifetime specifier
--> src\main.rs:9:37
|
9 | fn get_greater(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
什么意思呢,也就是说Rust期望你手动添加一个生命周期的声明。
在Rust眼里,这个代码会返回一个字符串的引用&str。而这个引用可能来自x或者y,或者是其他的地方。
这取决于你如何写函数内部的实现,此时的Rust编译器犯迷糊了因为他不知道&str的生命周期大概是多长。
是和x一样长?还是和y一样长?还是什么?如果是和x一样长,且x的生命周期大于y的,那么返回一个y的引用就可能会出现悬空指针。
看下面例子:
fn main() {
let result;
let s1 = String::from("abc"); //s1生命周期大
{
let s2 = String::from("abcd");//s2生命周期小
result = get_greater(s1.as_str(), s2.as_str()); //把小的引用赋给了大的
}
println!("{}", result); //此时s2已经销毁,result指针悬空
}
fn get_greater(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y //此时返回了小的那一个
}
}
上面的代码就产生了这种不安全的行为,归其原因在于我们可能会返回一个小的生命周期的借用给一个大的生命周期的变量。
而此时由于Rust并不清楚你的函数干了什么操作,所以推断不出返回值的借用的生命周期到底是大的还是小的。
所以此时Rust要求你对传入的参数的引用的生命周期加以限定,以保证返回值的生命周期是可以被Rust编译器推断的(没错,生命周期标注就是为了告诉Rust编译器你的返回值的生命周期是多大,从而让Rust能够检查出潜在的悬空指针错误)
生命周期标注符号使用’作为开头,例如
'a
'b
'abc
他么需要放在函数名后的尖括号里,表明这是一个生命周期标注变量
fn get_greater<'a>(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
然后你就需要为后续的引用标注上生命周期。其写法是在&后面加上生命周期标注变量再加类型
fn get_greater<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
我们来看上面的代码,定义了一个生命周期标注变量’a, 其中x生命周期的大小是’a, y也是。返回值也是。也就是说x,y,返回值有同样的生命周期。
你可能会疑惑这是啥意思,x和y显然可能不同。此时你可以认为‘a的大小就是x和y中最小的那一个(显然让一个小的强行拥有大的是错误的)。
所以上述代码的标注在告诉编译器两件事:
- 对函数内部,返回的引用必须要和x和y的生命周期相同,否则函数内部的实现有问题。
- 对于函数外部,返回的值是x和y生命周期中最小的那一个,所以在外部进行检查时,如果将这个小的赋给了大的,那么编译器可以直接预判报错。
看完上述的两点,你会发现加了生命周期并不改变程序的一分一毫,只是给编译器指明了一条检查你错误的道路。
我们再来看下面代码加深对这句话的理解:
fn main() {
let result;
let s1 = String::from("abc");
{
let s2 = String::from("abcd");
result = get_greater(s1.as_str(), s2.as_str());
}
println!("{}", result);
}
fn get_greater<'a>(x: &'a str, y: &str) -> &'a str {
if x.len() > y.len() {
x
} else {
y //此处会报错
}
}
上述代码只给x和返回值加上了生命周期的限制,也就是说返回值和x有一样的生命周期。
但是此时Rust编译器检查你的代码,发现了你逻辑上的漏洞,因为你返回了y,而y的生命周期并不是’a。所以此时在y处报错
fn main() {
let result;
let s1 = String::from("abc");
{
let s2 = String::from("abcd");
result = get_greater(s1.as_str(), s2.as_str()); //在此处报错
}
println!("{}", result);
}
fn get_greater<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
此时我们对函数加以修正,Rust编译器会发现,此时函数内部返回值都有‘a的生命周期。所以函数内部的逻辑是正确的。
那么此时Rust编译器就会开始对外对调用者进行检查了,由于函数指明了x和y有相同的生命周期。
但是其中一个生命周期过小(s2的过小),导致’a就是过小的这个生命周期('a就是s2)的生命周期。此时编译器检查了一遍后就发现(编译器只看函数名就知道返回值的生命周期了,不需要知道函数内部的实现细节,这就是为啥要标注生命周期,就是给编译器看的),返回值的生命周期小于它要赋给的变量的生命周期。
也就是开头的大周期变量借用小周期变量。所以此时果断报错。
综上可以看出一件事,生命周期的标注就是为了让Rust能够在编译时,对函数内检查你的逻辑上的错误,对外检查调用时是否会发生错误。所以这个标注只起到检查作用(伺候好编译器老爷 )
结构体的生命周期声明
在结构体和枚举中也有可能出现引用,此时我们就需要给每个引用标注一下生命周期了。
如下:
struct Test<'a>{
name: &'a String;
}
此时这个标注的含义就是,name这个生命周期至少要比结构体活得还要长。我们可以举一个反例,如下:
struct Test<'a>{
name: &'a String
}
fn main() {
let test;
{
let name = String::from("abc");
test = Test{
name: &name //此处会报错,说name生命周期太短
};
}
println!("{}",test.name);
}
此时Rust检查后发现了,name还没test活得长,所以果断报错。
主义在实现时实使用impl实现的时候也需要标注上生命周期,因为这个相当于是结构体名的一部分。
impl<'a> Test<'a>{
fn print_hello(&self) -> (){
}
}
Rust生命周期的自行推断
在某些情况下Rust可以自己推断出返回值的生命周期,主要按照如下的规则:
我们来看例子1:
fn test(s: &String) -> &String{
}
上面的代码就没有报错,这是因为Rust已经推断出了返回值的生命周期。
- 根据第一条规则,每个引用类型的参数都有自己的生命周期,于是s有一个生命周期
- 根据第二条规则,只有一个输入,于是这个输入的生命周期将会给于返回值
于是Rust推断出了返回值引用的生命周期,这是因为返回值的生命周期只可能来自于输入,因为函数内部的创建的对象,在返回引用时会造成悬垂引用(因为函数一结束,被引用的对象就失效了)。
再来看另一种情况
impl<'a> Test<'a>{
fn print_hello(&self, word: &String) -> &String{
word
}
}
上述情况也不会报错,理由如下:
- 根据第一条规则,每个引用类型的参数都有自己的生命周期,于是self和word有自己的生命周期
- 根据第三条原则,self的生命周期会被赋给word,和返回值,此时所有的参数的生命周期都已经推断出。
生命周期约束
对于生命周期标注来说,我们可以标注任意多的类别例如下面的这个式子:
fn test<'a, 'b>(s1: &'a String, s2: &'b String) -> &String{
s1
}
当然,上述的代码是错误的,因为编译器无法推断出返回值的生命周期。
我们稍作修改后就得到了这个:
fn test<'a, 'b>(s1: &'a String, s2: &'b String) -> &'a String{
s1
}
此时我们就得到了这个式子,就不报错了,如果我们突发奇想换一个式子呢?我们返回s2会如何
fn test<'a, 'b>(s1: &'a String, s2: &'b String) -> &'a String{
s2
}
此时编译器又报错了,因为编译器不知道s1和s2到底啥关系,返回的应该是’a的周期,但是实际返回的是’b的周期。
此时我们可以通过对生命周期的关系增加约束来达到解决问题的目的:
fn test<'a, 'b>(s1: &'a String, s2: &'b String) -> &'a String
where 'b: 'a //'b生命周期大于'a
{
s2
}
此时又不报错了,因为此时我们返回的是’b周期,而他比’a是要更大的。所以这个返回不会造成悬垂引用(因为返回的比’a要大,'a会造成的悬垂引用,'b不一定会造成)
静态生命周期
对于一些变量它的生命周期可能是整个程序的运行期间,于是可以使用’static这个特殊的标注来声明一个整个程序期间的生命周期。文章来源:https://www.toymoban.com/news/detail-651340.html
fn test(s: &'static str){
}
其中,常见的字符串字面值&str采用的就是’static类型的生命周期文章来源地址https://www.toymoban.com/news/detail-651340.html
到了这里,关于Rust语法:所有权&引用&生命周期的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!