0. 引言
前段时间生产上遇到了OOM问题,导致服务出现了短时间的不可用,还好处理及时,否则也将酿成大祸。OOM问题也是生产中比较重要的问题,所以本期我们针对OOM问题特别讲解,结合理论与实际案例来带大家彻底攻克OOM问题处理。
1. OOM问题产生的原因
1.1 JVM内存布局/内存模型/运行时数据区域
要解决问题,我们首先要清楚问题产生的原因。
OOM(Out Of Memory),即内存溢出,其问题表示java虚拟机在运行过程中,所占用的内存超过限制的内存大小了,导致没有多余的内存继续运行
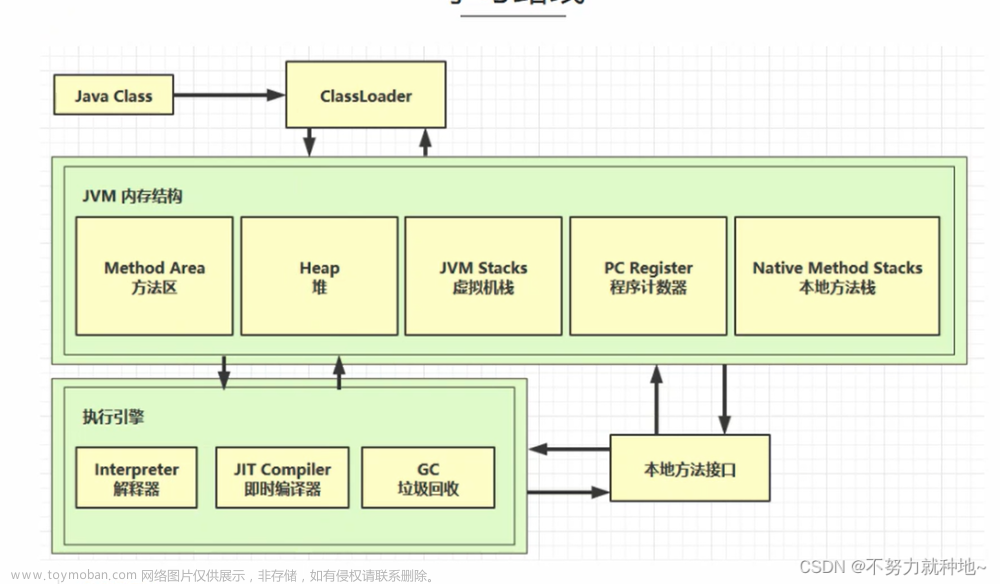
我们要弄清楚该问题,首先要先了解java程序运行时的内存布局,我们知道java程序是运行在JVM(java虚拟机)之上的。因此其运行时的内存布局也就是JVM的内存布局。
JVM的内存布局(运行时数据区域)一共分为5部分:
- 堆:用于存放程序运行时创建的对象或数组,是我们最常操作的内存区域。
- 栈:用于存放栈帧,每个方法都会创建自己的栈帧,栈帧中包括局部变量表、操作栈、动态链接、返回地址等信息,其中局部变量表里存放基本数据类型和堆中对象的引用
- 程序计数器:用来存放在一条指令所处的位置的,这里是不会发生内存溢出的,因此大家了解即可
- 本地方法栈:与栈的作用类似,只不过栈用于管理JVM方法的调用,而本地方法栈用于管理本地方法的调用,所谓本地方法就是底层的操作系统指令、C、C++方法等
- 方法区:每个线程共享的内存区域,用于存储已经被JVM加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据

1.2 常见OOM原因
我们解决OOM问题,一定要先理解JVM内存模型,如上所示,本地方法栈管理的是本地方法,相对固定,引起OOM的概率较低,而方法区存储类型信息、常量、静态变量、代码缓存之类的数据,能够出问题的无非在于静态变量数据是否过大、引入加载的class是否过多,这类问题发生的概率也比较小。计数器本身就是计数的作用,更不可能发生OOM
所以在运行时能产生OOM问题的基本就是堆和栈了,其中在实际运行中最常见的就是堆内存溢出,我们这次产生的问题也是堆内存溢出导致,堆内存溢出原因主要是以下几种:
(1)创建了一个超大对象,比较常见的是一个大数组,大集合
(2)对象引用没有释放,导致垃圾无法回收,产生内存泄漏,从而导致可用内存减少
(3)突然而来的高并发,导致流量飙升,资源占用迅速提升,服务器配置无法跟上实际使用
(4)重写finalize引发频繁GC,这个问题的典型案例是小米云的C++程序员重写finalize导致了线上OOM。在java里很少见
栈存储的是基础数据类型和堆对象的引用,这些数据理论上占用并不多,要达到内存溢出,那就是不断的叠加导致的这些数据暴增,《深入理解JAVA虚拟机》中给出的栈溢出的原因是线程请求的栈深度大于虚拟机允许的深度了,所谓的栈深度就是方法嵌套调用的次数,所以说的直白点就是嵌套循环调用次数太多,即考虑如下原因:
(1)是否有递归调用
(2)是否有大量循环或死循环
如何定位是堆内存溢出还是栈内存溢出?
在java中出现堆内存溢出,可以在报错异常java.lang.OutOfMemoryError后明显看到"java heap space"的提示,即堆空间;而栈溢出可以看到StackOverflowError错误,一般这类错误在我们开发测试时就能暴露出来,所以通过报错内容的文字描述即可知道溢出位置
1.3 其他导致OOM问题的原因及解决之法
除了上述说的堆栈导致的OOM问题,其实还有其他内存区域会导致OOM问题,只是相对来说更加少见,或者基本都能在开发测试中暴露出来,很少出现在线上环境,为了让大家有个全面的了解,我们也梳理出来
首先就方法区而言,上面已经讲解到,其原因就是:
(1)静态变量过大,这个原因实际上概率很小,因为创建的静态变量一般在开发时就会把控,基本不会太大。
(2)class加载多大,比如这个项目引入了超多的jar包,编译出超多的class文件,就会导致此类问题,这类问题的解决可以通过精简项目解决,如果实在都精简不了,因为class文件在jdk1.8之前是存储在永久代的,所以可以调大永久代空间,在JVM启动脚本添加如下参数:-XX:MaxPermSize,在jdk1.8之后使用元空间替换了永久代,所以可以调整如下参数:-XX:MaxMetaspaceSize
(3)class加载了多次,这种一般是启动异常,再重启下项目即可,如果重启完问题仍未解决考虑其他原因
其次就是本地方法栈出现OOM问题:
本地方法栈出现OOM问题,一般会报错Unable to create new native thread,即无法创建新本地方法线程。这个出现的原因是:
(1)本地方法线程数超过了最大线程数限制(操作系统最大线程数ulimit和内核线程数kernel.pid_max)
(2)本地方法栈内存不足
而这两个原因的解决一般也就是三个思路:
(1)增加机器配置
(2)堆栈内存占用过多,导致本地方法栈内存占用变小,将堆栈内存调小,或者排查堆栈占用是否异常,是否有偏高的情况
(3)程序中是否有线程未正常回收,导致线程数占用,这点排查可以根据下文讲解的排查思路进行。
2. 解决OOM问题思路
知道了OOM问题的原因,那么我就来看解决问题的思路,问题的具体案例多种多样,但是核心思路是不变的。
针对于栈内存溢出:一般通过日志找到报错的代码位置,针对性排查是否有循环调用、死循环的问题即可,
针对堆内存溢出:
(1)如果是调用量激增导致的内存不足,那么考虑增加机器或拓展内存资源
(2)机器资源充足,只是JVM分配的内存较小,考虑调大JVM内存,通过参数最大内存-Xmx 和最小内存-Xms
(2)如果是超大对象,那么考虑业务场景,是否需要查询如此大的对象,考虑分步查出
(3)如果是对象引用没有释放,就排查代码逻辑,查看是否有没有正常释放对象引用的地方,比如ThreadLocal没有正常remove,导致对象一致引用。
实际上大部分开发在掌握了详细的报错信息后,都能定位对应的代码位置,来排查到错误,而OOM问题让很多同学望而生畏的原因是,不知道怎么定位报错,不知道怎么查看报错信息。
下面我们就来讲解如何定位报错信息
3. 定位OOM报错
1、首先找到是哪个服务有问题,一般大型系统会部署预警提醒,根据预警信息找到对应服务器即可,小型系统没有部署预警的直接到服务器上逐一查看。如果你说你们是大型系统,又没有部署预警提醒的,那怎么排查? 方法根据反馈信息,一台一台服务器查吧,事后赶紧让运维把预警系统部署上。
2、定位到服务器后,到对应服务器上通过top指令,查看是哪个进程占用内存资源较高
这里为了模拟操作,我写了一个程序用来产生OOM问题,同时为了尽快模拟出OOM,我们将堆内存限定为200M,想要更快显示效果你可以限定的更小
java -jar -Xms200M -Xmx200M cpu_oom_demo-0.0.1-SNAPSHOT.jar
top指令可以看到内存占用情况,因为这里我限定了
200M,如果线上真实情况,可能会打到80%+
同时在日志中也会报错堆内存溢出


如果定位到是java进程导致,可以通过jps -l指令来查看所有正在运行的java进程

jps支持的参数
jps -q:查看所有运行的Java进程,但只显示进程号pid
jps -m:只显示传递给main方法的参数
jps -l:只显示运行程序主类的包名,或者运行程序jar包的完整路径
jps -v:单独显示JVM启动时,显式指定的参数
jps -V:显示主类名或者jar包名。
3、然后通过top -Hp 进程pid指令来查看是哪个线程占用的内存资源高,如果自定义了线程名了,可以通过此处打印的线程名就能定位到具体是哪块功能线程引起的问题,从而定位问题(这也是阿里java规范中要求自定义线程池,自定义线程名的重要性)
上述看到java程序的pid是1826,那么执行top -Hp 1826
看到从线程无法定位到业务功能

4、如果没有自定义线程名,或者根据线程名也看不出具体原因,那么就需要导出堆日志了,通过jmap指令导出堆日志,因为该指令执行期间会导致业务线程无法运行,所以在导出前我们要确保有其他节点顶着,同时将该节点从注册中心/负载均衡中下架(注意不能关闭服务,关闭后JVM日志就导不出来了),然后执行jmap
我们先导出进程中占用内存空间最大的前20的对象名,1826为进程ID
jmap -histo 1826 | head -20
可以看到是User对象的占用过高导致,这里如果这个对象你能够定位到具体的使用位置,或者说这个对象使用的地方并不多,那么次数就能根据这个信息定位到问题。比如这里是用户实体类占用过高,那理所当然考虑是不是对用户信息的访问高飙升,或者用户信息访问后没有正常释放,通过这些信息就可以进行辅助排查。但如果你调用这个对象的地方很多,那还不足以定位问题,我们还要进一步进行排查

5、这里如果服务是正常的调用,并且服务器资源还算可以,比如我这里出现了OOM,但实际服务器内存占用才22%。那么我们可以通过jps -lv将java进程中设置的JVM参数打印出来

可以看到这里因为设置了JVM内存为200M,如果资源允许将该内存调大即可。注意这里显示的是JVM启动时,显式指定的参数,如果没有查询到说明使用的都是JVM默认参数值。但如果调大后仍然有OOM问题并且理论调用量也不高,或者在承受范围的,那就是对象没有正常回收导致的了,我们继续排查
如果想要查询更多JVM运行时参数,可以通过jnifo指令
jinfo [option1] 进程pid
其中[option1]可选项如下:
:第一个参数不写,默认输出JVM的全部参数和系统属性。
-flag :输出与指定名称对应的所有参数,以及参数值。
-flag [+|-]:开启或者关闭与指定名称对应的参数。
-flag =:设置与指定名称对应参数的值。
-flags:输出JVM全部的参数。
-sysprops:输出JVM全部的系统属性。
jinfo -flags 2019

6、如果根据对象无法排查问题,我们还要进一步打印堆日志,堆日志导出指令
jmap -dump:format=b,file=文件名 进程pid
# eg 这里演示使用的自定义文件后缀,不影响分析,但建议按照规范使用.hprof
jmap -dump:format=b,file=/usr/local/oom.dump 1826

当然上述方法属于事后处理了,如果想要出现OOM问题时自动生成dump文件,可以在配置中开启
-XX:+HeapDumpOnOutOfMemoryError 参数表示当JVM发生OOM时,自动生成DUMP文件。
-XX:HeapDumpPath=${目录}参数表示生成DUMP文件的路径,也可以指定文件名称,例如:-XX:HeapDumpPath=${目录}/java_heapdump.hprof。如果不指定文件名,默认会在项目根目录下生成一个文件,文件名格式为:java_<pid>_<date>_<time>_heapDump.hprof。
7、将dump文件下载到本地,利用各类工具进行分析:
- (1)通过
jhat分析类内存占用情况(与jmap -histo指令效果类似)
执行分析工具占用内存为1024M
jhat -J-Xmx1024M oom.dump

jhat是jdk自带的一种虚拟机堆转储快照分析工具,只要安装了jdk就能执行,执行完毕后访问localhost:7000可查看分析结果,7000端口可以通过-port参数调整:
jhat -J-Xmx1024M -port 7001 oom.dump
分析成功后会出现server is ready
在页面最底下可以看到堆对象内存占用情况,也能显示JVM中的各类实例数量,加载的class等

其效果与之前用jmap -histo的效果类似,但是这里可以显示详细的内存占用数据

- (2)通过
mat工具分析(推荐)
mat是一个内存分析工具,如果使用的是eclipse作为开发工具,可以直接通过插件安装mat,因为我使用的是idea,所以单独安装下mat,mat工具的安装和使用参考我这篇文章:MAT工具安装
点击Open a Heap Dump打开之前导出的dump文件

这里选择Leak Suspects Report,重点分析内存泄漏问题

之后会产生一个内存泄漏的可能原因的分析报告,可根据实际情况参考

我们点击回Overview,选择Unreachable Objects Histogram查看可被回收的对象占用统计

和我们之前看到的类似,这个User对象就占用了100多M的内存,并且这些都还在内存里没有被回收,那么我们就要看是什么东西在引用这个对象,导致没有被回收掉。
这里我们可以再右键选择with incoming references,查看这个类被哪些类引用。(补充:with outgoing references表示这个类引用到了哪些类)

然后神奇的发现它的引用列表是空的,也就是说并没有被其他对象引用

那么既没有被引用,而本身占用又大,说明这个对象是直接返回的,那么可以定位到最外部层,比如Controller层,这时我们再去排查代码,就能发现问题所在了。
比如我这里的这个问题,找到controller中用到User的地方发现,有一个死循环再不停创建User,导致了内存溢出,那么问题的原因也就定位到了,再下面的解决就好办了。

4. 总结
OOM问题的实际原因各种各样,就像我们开发时遇到的空指针错误,导致的原因可能有很多,但是排查的思路却差不多,大家之所以对OOM问题避而远之,是因为不能直接看到报错的代码位置,这一点需要我们借助jhat,jmap,MAT等工具来实现。
但只要大家多操作,多积累经验,你会发现这个的排查也没有那么难,那么下期我们将结合实际的线上案例,来一起带大家推导OOM问题解决。文章来源:https://www.toymoban.com/news/detail-651473.html
5. 项目源码
https://gitee.com/wuhanxue/wu_study/tree/master/demo/cpu_oom_demo文章来源地址https://www.toymoban.com/news/detail-651473.html
到了这里,关于JVM:全面理解线上服务器内存溢出(OOM)问题处理方案(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!