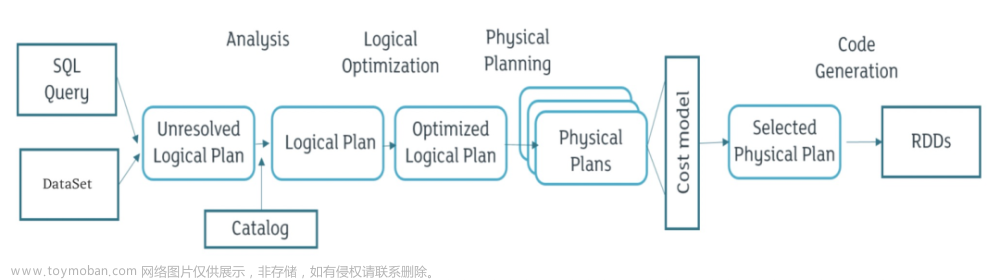
### 整体架构概述
Spark与Hadoop MapReduce的结构类似,Spark也采用Master-Worker结构。如果一个Spark集群由4个节点组成,即1个Master节点和3个Worker节点,那么在部署Standalone版本后,Spark部署的系统架构图如图2.1所示。简单来说,Master节点负责管理应用和任务,Worker节点负责执行任务。
### 具体功能
我们接下来先介绍Master节点和Worker节点的具体功能,然后介绍一些Spark系统中的基本概念,以及一些实现细节。
1.Master节点和Worker节点的职责如下所述。
Master节点上常驻Master进程。该进程负责管理全部的Worker节点,如将Spark任务分配给Worker节点,收集Worker节点上任务的运行信息,监控Worker节点的存活状态等。
Worker节点上常驻Worker进程。该进程除了与Master节点通信,还负责管理Spark任务的执行,如启动Executor来执行具体的Spark任务,监控任务运行状态等。
2.执行顺讯
启动Spark集群时,Master节点上会启动Master进程,每个Worker节点上会启动Worker进程。启动Spark集群后,接下来可以提交Spark应用到集群中执行,Master节点接收到应用后首先会通知Worker节点启动Executor,然后分配Spark计算任务(task)到Executor上执行,Executor接收到task后,为每个task启动1个线程来执行。
3.这里有几个概念需要解释一下。文章来源:https://www.toymoban.com/news/detail-651537.html
Spark application,即Sp文章来源地址https://www.toymoban.com/news/detail-651537.html
到了这里,关于谁能讲清楚Spark之Spark系统架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!