训练过程中发现,train loss一直下降,train acc一直上升;但是val loss、val acc却一直震荡。loss一会上一会下,但是总体趋势是向下的。
“loss震荡但验证集准确率总体下降” 如何解决?
测试集准确率这样震荡是正常的吗? - 李峰的回答 - 知乎
很多经验:loss问题汇总(不收敛、震荡、nan) - 飞狗的文章 - 知乎
训练过程中loss震荡特别严重,可能是什么问题? - 孤歌的回答 - 知乎
模型训练中出现NaN Loss的原因及解决方法_loss为nan的原因_there2belief的博客-CSDN博客
学习率和loss的关系?
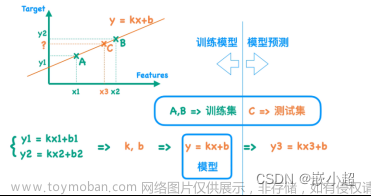
w1 = w0-学习率*梯度()
loss = |ypred-ytrue|
训练深度学习模型loss为nan的原因
http://t.csdn.cn/jfNpF
模型时遇到个问题:在大样本训练模型时候的loss为nan,尝试了各种方法也没有什么起色,最终一起分析了一番拟确定了原因,这边就分享下可能的原因可供分析调整~
原因
1.模型问题
- 网络结构设计问题
通过弱化场景,简化样本的方式去检查是否为网络的问题
- 损失函数设置不合理
- 激活函数选择不当
- 参数初始化问题
2.数据问题
-
数据需归一化
- 减均值
- 除方差
- 加入normalization(BN\L2 norm等)
- 数据标签不在[0, num_classes)范围内
- 训练样本存在脏数据
这个是和师弟最终确定的原因,因为在实际业务中的真实数据需要耗费较多的时间去处理,不像open dataset那样已经帮你处理的干干净净,所以如上述的方法一一检查过了还是没有成效的话,一定要好好地检查下数据。
3.训练问题
loss为nan的说明loss发散,这个时候需要考虑下梯度爆炸的可能,那么相应的解法方式如下:
- 调小学习率lr
- 调小batch size
- 加入gradient clipping
什么是loss发散?(Loss变为NaN怎么办?)
因为学习率过大的话,每次参数更新步子迈得太大,loss直接不往极小值点走了,结果越更新离极小值点越远。这就是所谓的loss发散。发散着发散着loss越来越大,就变为NaN了。
【算法】深度学习模型损失值loss不收敛,曲线震荡发散怎么办?_loss的发散问题_YaoYee_7的博客-CSDN博客
神经网络训练过程中先收敛,达到一个可观的性能后又发散了,loss曲线呈反"抛物线"型? - 知乎 文章来源:https://www.toymoban.com/news/detail-651625.html
Loss变为NaN怎么办?_loss: nan_OhMyJayce的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-651625.html
到了这里,关于【机器学习】验证集loss震荡(loss的其他问题) 训练深度学习模型loss为nan的原因的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!