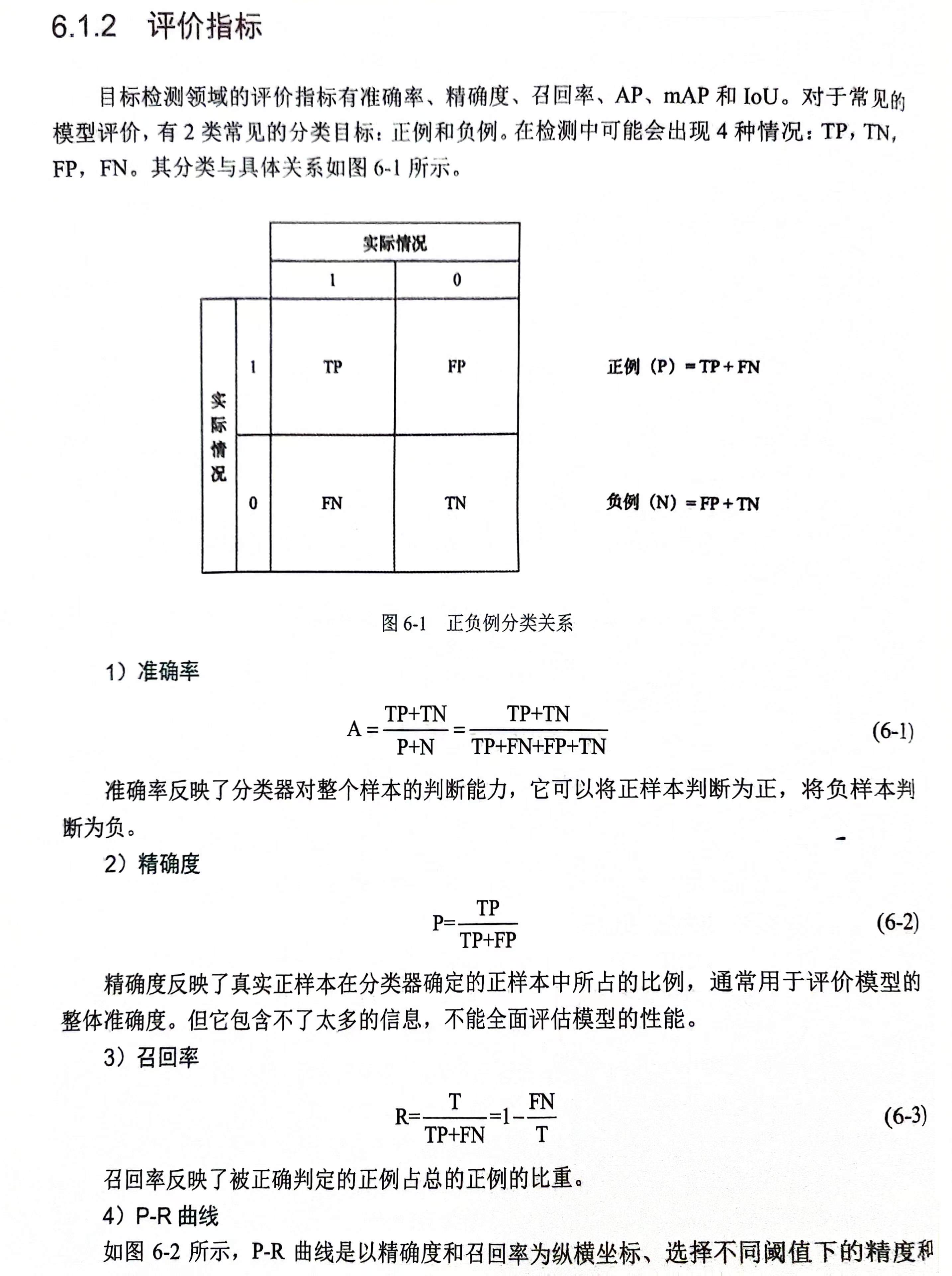
锚框的计算公式
假设原图的高为H,宽为W
详细公式推导

以同一个像素点为锚框,可以生成 (n个缩放 + m个宽高比 -1 )个锚框


计算锚框与真实框的IOU
def box_iou(boxes1,boxes2):
'''
:param boxes1: shape = (boxes1的数量,4)
:param boxes2: shape = (boxes2的数量,4)
:param areas1: boxes1中每个框的面积 ,shape = (boxes1的数量)
:param areas2: boxes2中每个框的面积 ,shape = (boxes2的数量)
:return:
'''
# 定义一个Lambda函数,输入boxes,内容是计算得到框的面积
box_area = lambda boxes:((boxes[:,2] - boxes[:0]) * (boxes[:3] - boxes[:0]))
# 计算面积
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# 计算交集 要把所有锚框的左上角坐标 与 真实框的所有左上角坐标 作比较,大的就是交集的左上角 ,加个None 可以让锚框与所有真实框作对比
inter_upperlefts = torch.max(boxes1[:,None,:2],boxes2[:,:2])
# 把所有锚框的右下角坐标 与 真实框的所有右下角坐标 作比较,小的就是交集的右下角坐标 ,加个None 可以让锚框与所有真实框作对比
inter_lowerrights = torch.min(boxes1[:,None,2:],boxes2[:,2:])
# 如果右下角-左上角有元素小于0,那就说明没有交集,clamp(min-0)会将每个元素与0比较,小于0的元素将会被替换成0
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0) # 得到w和h
inter_areas = inters[:,:,0] * inters[:,:,1] # 每个样本的 w*h
# 求锚框与真实框的并集
# 将所有锚框与真实框相加,他们会多出来一个交集的面积,所以要减一个交集的面积
union_areas = areas1[:,None] * areas2 - inter_areas
return inter_areas/union_areas
给训练集标注锚框
每个锚框包含的信息有:每个锚框的类别 和 偏移量。
偏移量指的是:真实边界相对于锚框的偏移量。
预测时:为每张图片生成多个锚框,预测所有锚框的类别和偏移量。
举例
假设有4个真实框 B1,B2,B3,B4。9个锚框A1,A2,A3,A4,A5,A6,A7,A8,A9。

如上,每个真实框都要与所有的锚框计算IOU,如X23,在第三列,拥有最大的IOU,如果该IOU大于阈值,那么第2个锚框的类别就是B3,分配完类别之后,第二个锚框和第3个真实框将不再参与,表现为上面的矩阵去掉第二行第三列。
标记类别和偏移量
给定锚框A和真实框B,中心坐标分别
为(xa , ya )和(xb , yb ),宽度分别为wa 和wb ,高度分别为ha 和hb ,可以将A的偏移量标记为:

def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset
补充:
训练集不是光使用标注的真实的框做标签来训练吗?为啥要锚框当做训练样本?
应该是扩大训练集的方式,如果只有一张图片,上面标注上了一个真实的框,那么就只有一个训练样本,如果生成一些锚框,根据真实的框,计算IOU,来给生成的锚框标记上相应的类别和与真实框的中心值偏移量,那么这些锚框也成为了训练样本。
lambda匿名函数
它可以用于简洁地定义一个单行的函数文章来源:https://www.toymoban.com/news/detail-651894.html
add = lambda x, y: x + y
print(add(2, 3)) # 输出结果为 5
torch.max(boxes1[:, None, :2], boxes2[:, :2])
import torch # 定义两个张量
boxes1 = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8]]) # 形状为(2, 4)
boxes2 = torch.tensor([[2, 3,4,5], [6, 7,8,9]])
print(boxes1.shape, boxes2.shape)
torch.Size([2, 4]) torch.Size([2, 4])文章来源地址https://www.toymoban.com/news/detail-651894.html
print(boxes1[:, None, :2])
print(boxes1[:, None, :2].shape)
tensor([[[1, 2]],
[[5, 6]]])
torch.Size([2, 1, 2]) 变成了两个通道,每个通道有个一行两列的元素
boxes2[:,:2]
tensor([[2, 3],
[6, 7]])
print(torch.max(boxes1[:, None, :2], boxes2[:, :2]))
torch.max(boxes1[:, None, :2], boxes2[:, :2]).shape
tensor([[[2, 3],
[6, 7]],
[[5, 6],
[6, 7]]])
torch.Size([2, 2, 2]) 变成两个通道,每个通道有两行,每行有两列的元素
print(torch.max(boxes1[:, :2], boxes2[:, :2]))
tensor([[2, 3],
[6, 7]])
到了这里,关于13.3 目标检测和边界框的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!