定义
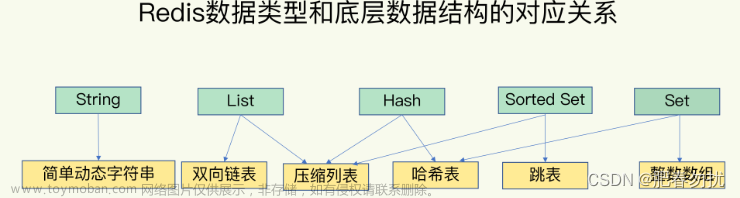
Redis中的数据结构,链表和压缩列表这两种数据结构是列表对象的底层实现方式。
当时考虑到链表的附加空间太大,节点的内存都是单独分配的,还会导致内存碎片化问题严重。
因此从Redis3.2开始,对列表的底层数据结构进行了改造,即使用quickList代替链表list和压缩列表ziplist
快速链表quickList实际上是ziplist和linkedlist的混合体,它将linkedlist按段切分,每一段使用ziplist来紧凑存储,多个ziplist之间使用双向指针串接起来。
每个节点的类型是quickListNode,一个quickListNode就是一个压缩列表ziplist,quickListNode的结构是这样的:
typedef struct quicklistNode {
struct quicklistNode *prev; //上一个node节点
struct quicklistNode *next; //下一个node
unsigned char *zl; //保存的数据 压缩前ziplist 压缩后压缩的数据
unsigned int sz; //ziplist 的大小
unsigned int count : 16; // 压缩列表中节点的数量
unsigned int encoding : 2; // 编码格式
// .....
} quicklistNode;
quickList的常用操作
插入
当插入一个数据时,就会有两种可能:
- 要么新建一个quickListNode,即一整个ziplist;
- 要么直接在ziplist中进行插入
同时插入的位置也有两种可能,要么在表头或表尾,要么在中间位置。
因此Redis结合以上因素,规定的插入操作
当插入位置是表头或表尾时:
- 当在表头或表尾插入数据时,如果数据没有超过规定的大小,那么就插入到表头或表尾节点的ziplist中。
- 如果要插入的数据的大小超过了限制,那么就会新创建一个quickListNode,即新创建一个压缩列表,然后插入到表尾或表尾
当插入的位置是中间时,还要考虑是在这个ziplist中的那个位置插入:
当插入的位置是ziplist的头部或尾部时:
- 当要插入的位置所在的ziplist能够继续放得下这个数据,那么就插入到这个ziplist中;
- 当要插入的位置所在的ziplist,如果继续存放该数据,那么就会超出单个ziplist的大小限制,如果此时这个ziplist相邻的ziplist能够放得下这个数据,就放到相邻的ziplist中。
- 如果当前的ziplist无法放得下这个数据,同时相邻的ziplist也无法放得下这个数据,那么就要新创建一个quickListNode,即一个新的ziplist。
当要插入的位置是ziplist的中间时,既不是ziplist的首尾位置:
- 如果当前的ziplist能够放得下这个数据,则进行插入
- 如果要当前的ziplist无法放得下这个数据,则会在指定的位置进行分裂,将此数据放下,前后溢出的数据就放在前后的ziplist中
查找
quicklist的查找操作就是遍历每个quickListNode,因为每个quickListNode有前后指针,所以可以进行查找操作。文章来源:https://www.toymoban.com/news/detail-652020.html
参考文章
Redis数据结构——快速列表(quicklist) - 随心所于 - 博客园文章来源地址https://www.toymoban.com/news/detail-652020.html
到了这里,关于Redis数据结构——快速列表quicklist、快表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!