01. Kafka 分区位移
对于Kafka中的分区而言,它的每条消息都有唯一的offset,用来表示消息在分区中对应的位置。偏移量从0开始,每个新消息的偏移量比前一个消息的偏移量大1。
每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、…、9。
02. Kafka 消费位移
对于kafka中的消费者而言,也有一个offset的概念,消费者端需要为每个它要读取的分区保存消费进度,即分区中当前最新消费消息的位置。该位置就被称为消费位移offset 。消费者需要定期地向 Kafka 提交自己的位置信息,这里的位移值通常是下一条待消费的消息的位置 offset +1。
消费位移(偏移量)是指消费者在消费分区中的消息时,记录的已经消费的消息的位移。消费者会定期地将已经消费的消息的位移提交到Kafka集群中,以便在下一次启动时从上次消费的位置继续消费。
每个消费者在消费消息的过程中必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(Consumer Offset)。注意,这和分区位移完全不是一个概念。“分区位移”表征的是分区内的消息位置,它是不变的,即一旦消息被成功写入到一个分区上,它的位移值就是固定的了。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。另外每个消费者有着自己的消费者位移。
03. kafka 消费位移的作用
消费者位移(偏移量)是指消费者在消费分区中的消息时,记录的已经消费的消息的位移。它的作用主要有以下几个方面:
① 消费者可以通过记录偏移量来实现断点续传。当消费者下线或者重启时,它可以通过记录的偏移量来恢复之前的消费状态,从而避免重复消费已经处理过的消息。
② Kafka 通过偏移量来保证消息的顺序性。在同一个分区中,消息的顺序是有序的,消费者可以通过记录偏移量来保证消费的顺序性。
③ Kafka 还可以通过偏移量来实现消息的回溯。消费者可以通过指定偏移量来重新消费之前的消息,这在某些场景下非常有用,比如重新处理之前出现的错误。
总之,Kafka 消息偏移量是非常重要的一个概念,它可以帮助消费者实现断点续传、保证消息的顺序性以及实现消息的回溯等功能。
04. Kafka 消费位移的提交
消费者可以通过订阅一个或多个主题来拉取消息。当消费者调用 poll() 方法时,它会从 Kafka 集群中拉取一批消息,这些消息会被缓存在消费者的本地缓存中,等待消费者进一步处理。在消费者处理完这批消息后,它可以再次调用 poll() 方法来拉取下一批消息。如果消费者在处理消息时发生了错误,那么这批消息将会被重新拉取,直到消费者成功地处理它们为止。
因此每次调用poll()方法,它总是会返回还没有被消费者读取过的记录,这意味着我们可以追踪哪些记录是被群组里的哪个消费者读取过的。要做到这一点,就需要记录上一次消费时的消费位移。并且这个消费位移必须做持久化保存,而不是单单保存在内存中,否则消费者重启之后就无法知晓之前的消费位移。再考虑一种情况,当有新的消费者加入时,那么必然会有再均衡的动作,对于同一分区而言,它可能在再均衡动作之后分配给新的消费者,如果不持久化保存消费位移,那么这个新的消费者也无法知晓之前的消费位移。
在旧消费者客户端中,消费位移是存储在 ZooKeeper 中的。而在新消费者客户端中,消费位移存储在Kafka内部的主题 __consumer_offsets 中。这里把将消费位移存储起来(持久化)的动作称为“提交”,消费者在消费完消息之后需要执行消费位移的提交。
05. kafka 消费位移的存储位置
消费者默认将 offset 保存在Kafka一个内置的 topic 中,该 topic 为 __consumer_offsets。
[root@master01 kafka01]# bin/kafka-topics.sh --zookeeper localhost:2183 --list
__consumer_offsets
消费者会向一个叫作 __consumer_offset 的内置主题发送消息,消息里包含每个分区的偏移量。如果消费者一直处于运行状态,那么偏移量就没有什么实际作用。但是,如果消费者发生崩溃或有新的消费者加入群组,则会触发再均衡。再均衡完成之后,每个消费者可能会被分配新的分区,而不是之前读取的那个。为了能够继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的位置继续读取消息。
消费 offset 案例:
① __consumer_offsets 为 Kafka 中的 topic,那就可以通过消费者进行消费。但是需要在配置文件 config/consumer.properties 中添加配置 exclude.internal.topics=false,默认是 true,表示不能消费系统主题。为了查看该系统主题数据,所以该参数修改为 false。
② 创建主题 haha
[root@master01 kafka01]# bin/kafka-topics.sh --zookeeper localhost:2183 --create --partitions 3 --replication-factor 2 --topic haha
Created topic test1.
③ 启动生产者生产数据:
[root@master01 kafka01]# bin/kafka-console-producer.sh --broker-list 10.65.132.2:9093 --topic haha
>hello,haha!
>你好,haha!
>
④ 启动消费者消费数据:
[root@master01 kafka01]# bin/kafka-console-consumer.sh --bootstrap-server 10.65.132.2:9093 --topic haha --group group-haha --from-beginning
hello,haha!
你好,haha!
⑤ 查看消费者消费主题__consumer_offsets:
[root@master01 kafka01]# bin/kafka-console-consumer.sh --bootstrap-server 10.65.132.2:9093 --topic __consumer_offsets --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
# key是[消费者组,消费的主题,消费的分区],value中已经消费的消息在当前分区的offset+1
[group-haha,haha,2]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1692000487851, expireTimestamp=None)
[group-haha,haha,1]::OffsetAndMetadata(offset=1, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1692000487851, expireTimestamp=None)
[group-haha,haha,0]::OffsetAndMetadata(offset=0, leaderEpoch=Optional.empty, metadata=, commitTimestamp=1692000487851, expireTimestamp=None)
06. Kafka 消费位移与消费者提交的位移
如下图,x 表示某一次拉取操作中此分区消息的最大偏移量,假设当前消费者已经消费了 x 位置的消息,那么我们就可以说消费者的消费位移为 x,不过当前消费者需要提交的消费位移并不是 x,而是 x+1,它表示下一条需要拉取的消息的位置。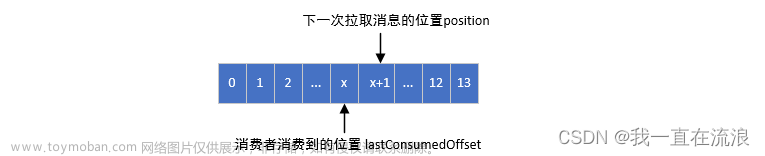
如果使用自动提交或不指定提交的偏移量,那么将默认提交poll()返回的最后一个位置之后的偏移量,即提交比客户端从poll()返回的最后一个位置大1的偏移量。在进行手动提交或需要提交特定的偏移量时,一定要记住这一点。
07. kafka 消费位移的提交时机
当前一次 poll() 操作所拉取的消息集为[x+2,x+7],x+2代表上一次提交的消费位移,说明已经完成了x+1之前(包括x+1在内)的所有消息的消费,x+5表示当前正在处理的位置。
① 如果最后一次提交的偏移量大于客户端处理的最后一条消息的偏移量,那么处于两个偏移量之间的消息就会丢失:
如图,如果拉取到消息之后就进行了位移提交,即提交了x+8,那么当前消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+8开始的。也就是说,x+5至x+7之间的消息并未能被消费,如此便发生了消息丢失的现象。
② 如果最后一次提交的偏移量小于客户端处理的最后一条消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理:
如图,如果消费完所有拉取到的消息之后才进行位移提交,那么当消费x+5的时候遇到了异常,在故障恢复之后,我们重新拉取的消息是从x+2开始的。也就是说,x+2至x+4之间的消息又重新消费了一遍,故而又发生了重复消费的现象。
08. Kafka 维护消费状态跟踪的方法
在Kafka中,消费者组可以通过消费者偏移量(consumer offset)来跟踪它们在分区中消费的消息。消费者偏移量是一个整数,表示消费者已经成功读取的消息的位置。当消费者读取消息时,它会将偏移量保存在内存中,以便在下一次读取消息时能够从正确的位置开始读取。
09. Kafka 消息交付语义
consumer端需要为每个它要读取的分区保存消费进度,即分区中当前最新消费消息的位置。该位置就被称为位移(offset)。consumer 需要定期地向 Kafka 提交自己的位置信息,实际上,这里的位移值通常是下一条待消费的消息的位置。假设consumer 已经读取了某个分区中的第N条消息,那么它应该提交的消息是第N+1条消息,这样下次 consumer 重启时会从第 N+1条消息开始消费。总而言之,offset 就是consumer端维护的位置信息。
offset 对于 consumer 非常重要,因为它是实现消息交付语义保证(message delivery semantic)的基石。常见的3种消息交付语义保证如下。文章来源:https://www.toymoban.com/news/detail-652079.html
- 最多一次 (at most once) 处理语义:消息可能丢失,但不会被重复处理。
- 最少一次 (at least once) 处理语义:消息不会丢失,但可能被处理多次。
- 精确一次 (exactly once) 处理语义:消息一定会被处理且只会被处理一次。
显然,若consumer在消息消费之前就提交位移,那么便可以实现 at most once 因为若consumer 在提交位移与消息消费之间崩溃,则 consumer 重启后会从新的 offset 位置开始消费,前面的那条消息就丢失了。相反地,若提交位移在消息消费之后,则可实现 at least once 语义。由于Kafka没有办法保证这两步操作可以在同一个事务中完成,因此 Kafka默认提供的就是 at least once的处理语义。好消息是Kafka社区已于0.11.0.0版本正式支持事务以及精确一次处理语义。文章来源地址https://www.toymoban.com/news/detail-652079.html
到了这里,关于分布式 - 消息队列Kafka:Kafka 消费者的消费位移的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!