目前关于NL2SQL技术路线的发展主要包含以下几种:
- Seq2Seq方法:在深度学习的研究背景下,很多研究人员将Text-to-SQL看作一个类似神经机器翻译的任务,主要采取Seq2Seq的模型框架。基线模型Seq2Seq在加入Attention、Copying等机制后,能够在ATIS、GeoQuery数据集上达到84%的精确匹配,但是在WikiSQL数据集上只能达到23.3%的精确匹配,37.0%的执行正确率;在Spider数据集上则只能达到5~6%的精确匹配。
- 模板槽位填充方法:将SQL的生成过程分为多个子任务,每一个子任务负责预测一种语法现象中的列,该方法对于单表无嵌套效果好,并且生成的SQL可以保证语法正确,缺点是只能建模固定的SQL语法模板,对于有嵌套的SQL情况,无法对所有嵌套现象进行灵活处理。
- 中间表达方法:该方法为当前主流方法,以IRNet为代表,将SQL生成分为两步,第一步预测SQL语法骨干结构,第二步对前面的预测结果做列和值的补充。在后续的文章中将围绕此方法展开讲述我们的实践经验。
- 强化学习方法:,此方法以Seq2SQL为代表,每一步计算当前决策生成的SQL是否正确,本质上强化学习是基于交互产生的训练数据集的有监督学习,此法效果和翻译模型相似。
- 结合图网络的方法:此方法主要为解决多个表中有同名的列的时候,预测不准确的问题,以Global-GNN、RatSQL为代表,但是由于数据库之间并没有边相连接,所以此方法提升不大且模型消耗算力较大。
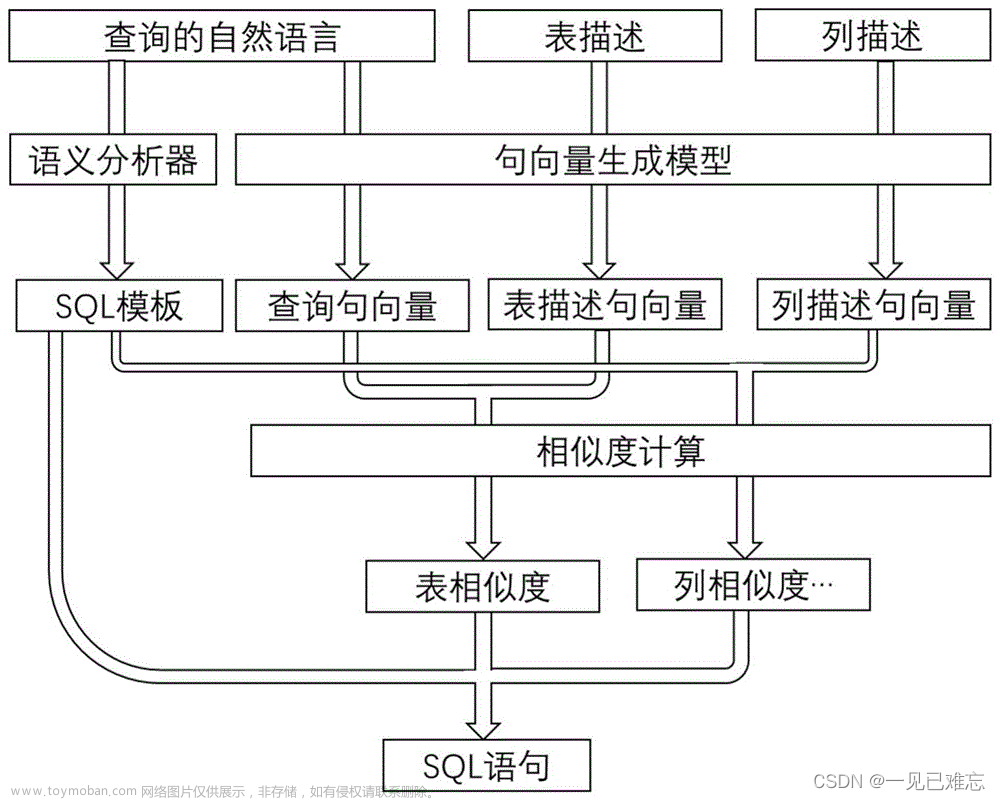
结合预训练模型、语义匹配的方法,该方法以表格内容作为预训练语料,结合语义匹配任务目标输入数据库Schema,从而选中需要的列,例如:BREIDGE、GRAPPA等。
语义解析 NL2SQL KBQA 直播PPT - 知乎
百分点科技:基于NL2SQL的问答技术与实践
【焦点】国调中心 刘金波:AI赋能,推动调度自动化技术进步——国网调控人工智能竞赛综述_会议主题_自动化_国调文章来源:https://www.toymoban.com/news/detail-652303.html
百分点认知智能实验室:基于NL2SQL的问答技术和实践__财经头条文章来源地址https://www.toymoban.com/news/detail-652303.html
到了这里,关于NLP-语义解析(Text2SQL):技术路线【Seq2Seq、模板槽位填充、中间表达、强化学习、图网络】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![NL2SQL进阶系列(2):DAIL-SQL、DB-GPT开源应用实践详解[Text2SQL]](https://imgs.yssmx.com/Uploads/2024/04/850157-1.jpeg)