介绍
Excelize是一个纯Go编写的库,提供了一组功能,允许你向XLAM / XLSM / XLSX / XLTM / XLTX文件写入和读取。支持读取和写入由Microsoft Excel™ 2007及更高版本生成的电子表格文档。通过高度兼容性支持复杂组件,并提供了流式API,用于生成或从包含大量数据的工作表中读取数据。此库需要Go版本1.16或更高版本。可以使用Go的内置文档工具查看完整文档,也可以在go.dev和文档引用中在线查阅。
另外还有另外一个库:github.com/360EntSecGroup-Skylar/excelize/v2,不过它已经没了,或者说它和github.com/xuri/excelize/v2是一个东西,用法功能都完全一样。。。。
文档与源码
Github源码:https://github.com/qax-os/excelize
中文文档:https://xuri.me/excelize/zh-hans/
安装
go get github.com/xuri/excelize/v2
快速开始
创建 Excel 文档
package main
import (
"fmt"
"github.com/xuri/excelize/v2"
)
func main() {
f := excelize.NewFile()
defer func() {
if err := f.Close(); err != nil {
fmt.Println(err)
}
}()
// 创建一个工作表
index, err := f.NewSheet("Sheet2")
if err != nil {
fmt.Println(err)
return
}
// 设置单元格的值
f.SetCellValue("Sheet2", "A2", "Hello world.")
f.SetCellValue("Sheet1", "B2", 100)
// 设置工作簿的默认工作表
f.SetActiveSheet(index)
// 根据指定路径保存文件
if err := f.SaveAs("Book1.xlsx"); err != nil {
fmt.Println(err)
}
}
读取 Excel 文档
package main
import (
"fmt"
"github.com/xuri/excelize/v2""
)
func main() {
f, err := excelize.OpenFile("Book1.xlsx")
if err != nil {
fmt.Println(err)
return
}
// 获取工作表中指定单元格的值
cell, err := f.GetCellValue("Sheet1", "B2")
if err != nil {
fmt.Println(err)
return
}
// 获取 Sheet1 上所有单元格
rows, err := f.GetRows("Sheet1")
for _, row := range rows {
for _, colCell := range row {
fmt.Print(colCell, "\t")
}
fmt.Println()
}
}
打开数据流
OpenReader 从 io.Reader 读取数据流。、
创建一个简单的 HTTP 服务器接收上传的电子表格文档,向接收到的电子表格文档添加新工作表,并返回下载响应:
package main
import (
"fmt"
"net/http"
"github.com/xuri/excelize/v2""
)
func process(w http.ResponseWriter, req *http.Request) {
file, _, err := req.FormFile("file")
if err != nil {
fmt.Fprintf(w, err.Error())
return
}
defer file.Close()
f, err := excelize.OpenReader(file)
if err != nil {
fmt.Fprintf(w, err.Error())
return
}
f.NewSheet("NewSheet")
w.Header().Set("Content-Disposition", "attachment; filename=Book1.xlsx")
w.Header().Set("Content-Type", req.Header.Get("Content-Type"))
if _, err := f.WriteTo(w); err != nil {
fmt.Fprintf(w, err.Error())
}
return
}
func main() {
http.HandleFunc("/process", process)
http.ListenAndServe(":8090", nil)
}
流式写入
func (f *File) NewStreamWriter(sheet string) (*StreamWriter, error)
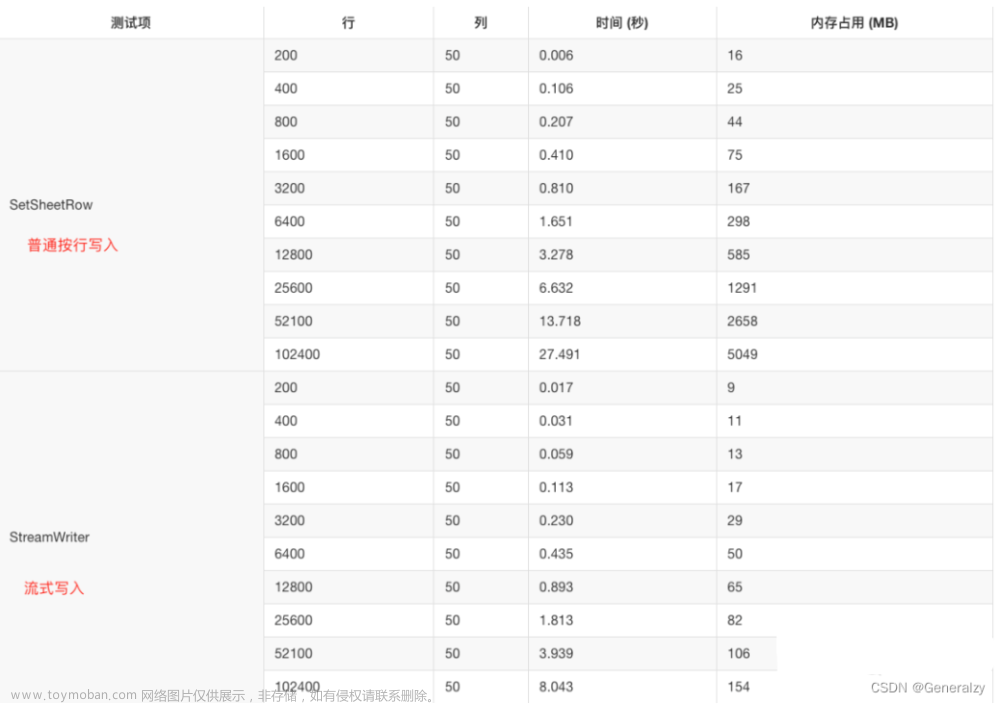
NewStreamWriter 通过给定的工作表名称返回流式写入器,用于向已存在的空白工作表写入大规模数据。请注意通过此方法按行向工作表写入数据后,必须调用 Flush 函数来结束流式写入过程,并需要确保所写入的行号是递增的,普通函数不能与流式函数混合使用在工作表中写入数据。写入过程中内存数据超过 16MB 时,流写入器将尝试使用磁盘上的临时文件来减少内存使用,此时您无法获取单元格值。例如,向工作表流式按行写入 102400 行 x 50 列带有样式的数据:
f := excelize.NewFile()
defer func() {
if err := f.Close(); err != nil {
fmt.Println(err)
}
}()
sw, err := f.NewStreamWriter("Sheet1")
if err != nil {
fmt.Println(err)
return
}
styleID, err := f.NewStyle(&excelize.Style{Font: &excelize.Font{Color: "777777"}})
if err != nil {
fmt.Println(err)
return
}
// 流式设置单元格的公式和值:
if err := sw.SetRow("A1",
[]interface{}{
excelize.Cell{StyleID: styleID, Value: "Data"},
[]excelize.RichTextRun{
{Text: "Rich ", Font: &excelize.Font{Color: "2354e8"}},
{Text: "Text", Font: &excelize.Font{Color: "e83723"}},
},
},
// 流式设置单元格的值和行样式:
excelize.RowOpts{Height: 45, Hidden: false}); err != nil {
fmt.Println(err)
return
}
for rowID := 2; rowID <= 102400; rowID++ {
row := make([]interface{}, 50)
for colID := 0; colID < 50; colID++ {
row[colID] = rand.Intn(640000)
}
cell, err := excelize.CoordinatesToCellName(1, rowID)
if err != nil {
fmt.Println(err)
break
}
if err := sw.SetRow(cell, row); err != nil {
fmt.Println(err)
break
}
}
if err := sw.Flush(); err != nil {
fmt.Println(err)
return
}
if err := f.SaveAs("Book1.xlsx"); err != nil {
fmt.Println(err)
}
SetRow 通过给定的起始坐标和指向数组类型“切片”的指针将数据按行流式写入工作表中。请注意,在设置行之后,必须调用 Flush 函数来结束流式写入过程,并需要确所保写入的行号是递增的。文章来源:https://www.toymoban.com/news/detail-652624.html
相关 Excel 开源类库性能对比
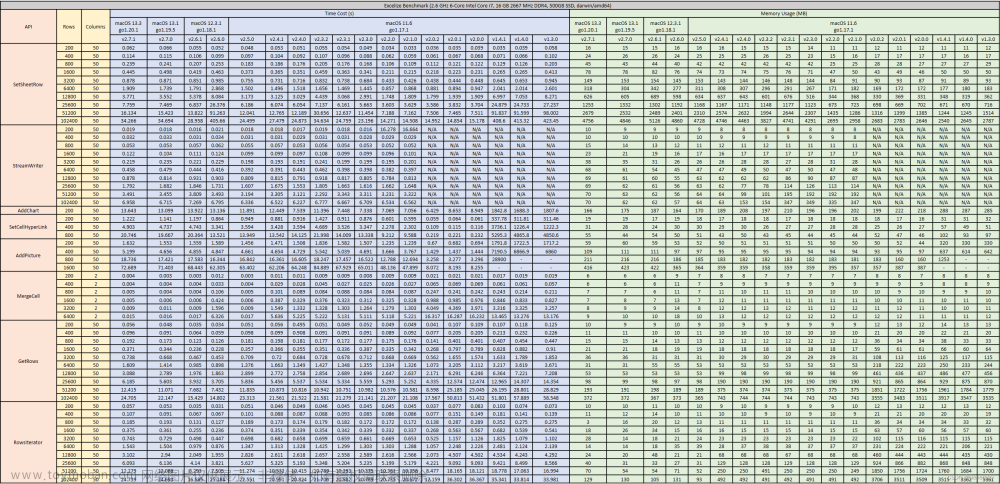
下图展示了 Go, Python, Java, PHP 和 NodeJS 语言中典型 Excel 开源基础库,基于普通个人计算机 (2.6 GHz 6-Core Intel Core i7, 16 GB 2667 MHz DDR4, 500GB SSD, macOS Monterey 12.3.1) 生成 50 列 102400 行纯文本单元格的性能表现。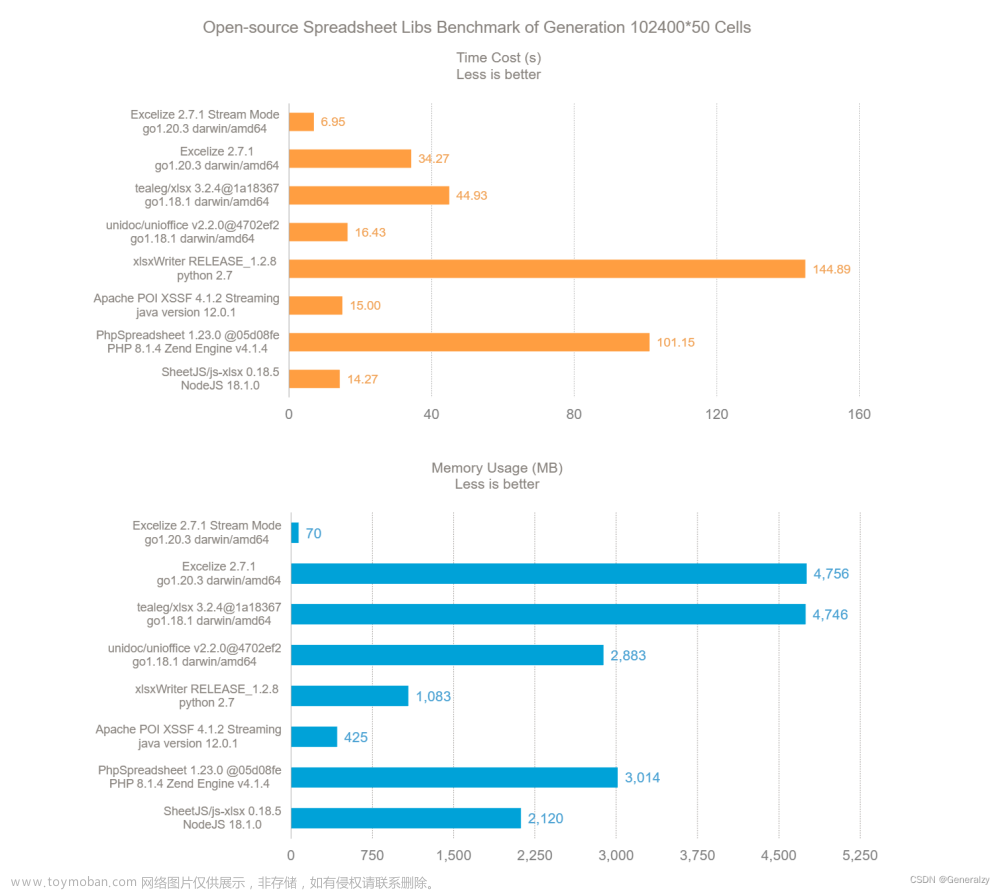
 文章来源地址https://www.toymoban.com/news/detail-652624.html
文章来源地址https://www.toymoban.com/news/detail-652624.html
到了这里,关于golang操作excel的高性能库——excelize/v2的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!